









python基础第一周
1.语法基本知识
1.1 注释
1.单行注释
#+空格
2.多行注释
三个引号
- 注释是不会执行的
- 注释是对代码的解释说明,是让人看得
- 单行注释的快捷键/取消单行注释
Ctrl /, 可以一次选中多行,给其添加单行注释
下面展示一些内联代码片。
'''
单引号,双引号都可以
多行注释可以换行
'''
1.2 变量的定义和使用
变量:内存地址的别名,用来存储数据
变量的定义:变量名=数据
name = 'abc'
age = 18
// 定义布尔类型
result = True
1.3 数据类型
name = 'abc'
age = 18
//查看数据类型
print(type(name))

// 回车键表示结束,结果为字符串类型
name = input('请输入姓名:')
print('姓名为:%s'%name)
2.输出
// python中输出使用print函数
// 以下几种输出方式
print('aaa')
print(123)
print('ab',12)
print(1+2)
// 格式化输出,%s字符串,%d int,%f float
name = 'zp'
heignt = 180.5
print("我的名字是%s."%name)
print("我的身高是%.2f cm."%height)
//输出%,需加2个%;python3.6支持f-string,占位符{}
print(f"我的名字是{name},身高是{height}cm")
1.6 数据类型的转换
// 转换为int类型int(),转换为float类型flloat(),还原原来的数据类型eval()
pi = 3.14
num1 = int(pi)
num2 = eval(num1)
1.7 运算符
算数运算符
1. - * /
// 整除(求商)
% 取余数
** 指数,幂运算
()改变优先级
赋值运算符
= 等号右边的结果赋值给左边的变量
左边必须是变量
符合赋值运算符
+= c+=a ===> c = c + a
比较运算符
比较运算符的结果是 bool 类型, 即 True,或者是 False
== 判断是否相等, 相等是 True. 不相等是 False
!= 判断是否不相等, 不相等是 True, 相等 False
>
<
>=
<=
逻辑运算符
逻辑运算符可以连接连个表达式, 两个表达式共同的结果决定最终的结果是 True,还是 False
and 逻辑与, 连接的两个条件都必须为 True,结果为 True, 一假为假
如果第一个条件为 False,就不会再判断第二个条件
or 逻辑或, 连接的两个条件都为 False,结果为 False, 一真为真
如果第一个条件为 True,第二个条件就不会再判断了
not 逻辑非, 取反,原来是 True,变为 False,原来是 False,变为 True
PEP 8 规范
1 单行注释#后边应该有一个空格
2 代码文件的最后一行是空行
3 行内注释需要两个空格
2 if判断语句
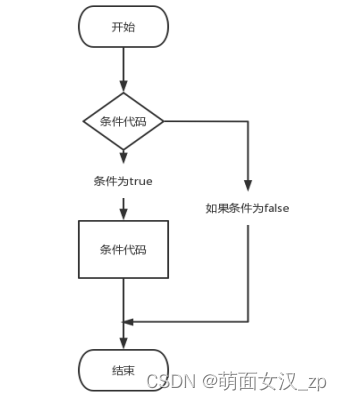
2.1 if判断的基本格式
if 判断条件:
判断条件为 True,会执行的代码
判断条件为 True,会执行的代码
…
顶格书写的代码,代表和 if 判断没有关系
在 python 中使用缩进,代替代码的层级关系, 在 if 语句的缩进内,属于 if 语句的代码块(多行代码的意思)
2.2 if else 结构
if 判断条件:
判断条件为 True,会执行的代码
判断条件为 True,会执行的代码
…
else:
判断条件为 False, 会执行的代码
判断条件为 False, 会执行的代码
…
if 和 else 只会执行其中的一个,
2.3 if elif 结构
if 判断条件1:
判断条件1成立,执行的代码
elif 判断条件2:
判断条件1不成立,判断条件2 成立,会执行的代码
else:
判断条件1和判断条件2都不成立,执行的代码
--------
if 判断条件1:
判断条件1成立执行的代码
if 判断条件2:
判断条件2 成立执行的代码
2.4 if 嵌套
if 判断条件1:
判断条件1 成立,会执行的代码
if 判断条件2:
判断条件1成立, 判断条件2成立执行的代码
else:
判断条件1成立, 判断条件2不成立执行的代码
else:
判断条件1不成立,会执行的代码
2.5 猜拳游戏
'''
猜拳游戏思路:
用户随机输入1(石头),2(剪刀),3(布)
电脑随机出拳(1,3)
平局-->用户 = 电脑
胜利-->(user == 1 and num == 2) or (user == 2 and num == 3) or (user == 3 and num == 1)
'''
# 导入随机数模块
import random
user = int(input("请输入要出的拳:1(石头),2(剪刀),3(布)"))
# 产生[a,b]之间的随机整数,包含a,b
num = random.randint(1, 3)
print("电脑出的拳%d" % num)
if user == num:
print("平局")
elif (user == 1 and num == 2) or (user == 2 and num == 3) or (user == 3 and num == 1) :
print("恭喜你,胜利了!!!")
else:
print("很抱歉,你输了!")
2.6 三目运算
if 判断条件1:
表达式1
else:
表达式2
判断条件成立,执行表达式 1, 条件不成立,执行表达式 2
变量 = 表达式1 if 判断条件 else 表达式2 # 推荐使用扁平化代码
变量最终存储的结构是:
判断条件成立,表达式1的值,
条件不成立,表达式2的值
3 循环
3.1 while
循环结构体
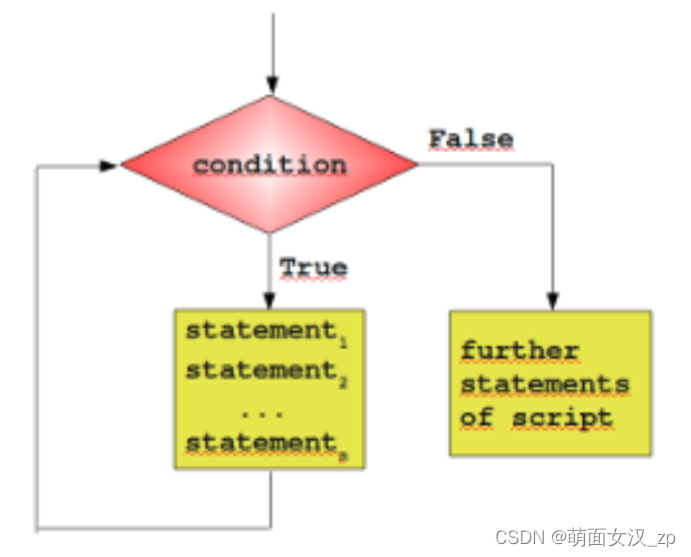 循环的基本语法
循环的基本语法
while 判断条件:
判断条件成立,执行的代码
判断条件成立,执行的代码
不在 while 的缩进内,代表和循环没有关系
while 和 if 的区别:
if 的代码块,条件成立,只会执行一次
while 的代码块,只要条件成立,就会一直执行
while True: # 无限循环
代码
死循环: 相当于是代码的 bug,错误
无限循环: 人为书写的,故意这样写的
循环嵌套
while 判断条件1:
代码1
while 判断条件2:
代码2
======
代码 1 执行一次,代码会执行多次
3.2 for循环遍历
for 变量 in 字符串:
代码
for 循环也称为 for 遍历,会将字符串中的字符全部取到
3.3 循环打印直角三角形
m = 5
for i in range(m):
# range(i)不包含i
for j in range(i+1):
# end=' ', 以空格分割
print("*", end=' ')
# 换行
print()
3.3 Break 和 continue
1. break 和 continue 是 python 两个关键字
2. break 和 continue 只能用在循环中
3. break 是终止循环的执行, 即循环代码遇到 break,就不再循环了
continue 是结束本次循环,继续下一次循环, 即本次循环剩下的代码不再执行,但会进行下一次循环
3.4 Break 和 continue
for x in xx:
if xxx:
xx # if 判断条件成立会执行
else:
xxx # if 判断条件不成立,会执行
else:
xxx # for 循环代码运行结束,但是不是被 break 终止的时候会执行
num = 76
1.使用代码的方法,求出这个数字的个位数和十位数
个位数: num % 10
十位数: num // 10
2.判断 if elif else
if 判断条件:
pass # 占位,空代码 让代码不报错
elif 判断条件:
pass
else:
pass
3.循环: 重复做一件事 while for
while 判断条件:
pass
for i in xxx:
pass
break 和 continue,
4 容器:字符串、列表、元组、字典
4.1 字符串
python中字符串的格式
1.字符串:单引号或多引号中的数据
2.定义:a = ‘abc’,b = “abc”
字符串的输出
// 1.格式化操作符
print('我的名字:%s' % name)
// 2.f-strings
f-strings 提供一种简洁易读的方式, 可以在字符串中包含 Python 表达式. f-strings 以字母 'f' 或 'F' 为前缀, 格式化字符串使用一对单引号、双引号、三单引号、三双引号.
name = '峰哥'
age = 33
format_string1 = f'我的名字是 {name}, 我的年龄是 {age}'
format_string2 = f"我的名字是 {name}, 我的年龄是 {age}"
format_string3 = F'''我的名字是 {name}, 我的年龄是 {age}'''
format_string4 = F"""我的名字是 {name}, 我的年龄是 {age}"""
format_string5 = f'3 + 5 = {3 + 5}'
字符串输入
input()获取的数据,都以字符串的方式进行保存,即使输入的是数字,那么也是以字符串方式保存
下标和切片
下标
即编号,字符串是字符的数组,可以索引取值
num = ‘abc’
print(num[0])切片
切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
切片的语法:[起始:结束:步长],不包括结束位
name = ‘abcdef’
print(name[0:3]) # 取 下标0~2 的字符
print(name[2:]) # 取 下标为2开始到最后的字符
字符串常见操作
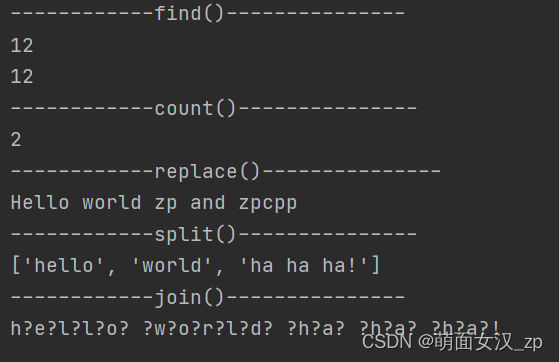
# 字符串mystr = 'hello world zp and zpcpp',以下是常见操作
# 1.find:检测字符串是否在字符串中,是->返回开始索引,否->返回-1
# 格式:mystr.find(str, start = 0, end = len(mystr))
mystr = 'hello world zp and zpcpp'
print(mystr.find('zp'))
print(mystr.find('zp' ,0 ,22))
# 2.index:方法同find(),不同点:如果str不在 mystr中会报一个异常
# 格式:mystr.index(str,start = 0,end = len(mystr))
# 3.count:返回str在mystr中出现的次数
# 格式:mystr.count(str,start = 0,end = len(mystr))
print(mystr.count('zp'))
# 4.replace:把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次.
# 格式:mystr.replace(str1, str2, count=mystr.count(str1))
print(mystr.replace('h', 'H'))
# 5.split:以 str 为分隔符切片 mystr,如果 maxsplit有指定值,则仅分隔 maxsplit+1 个子字符串
# 格式:mystr.split(str=" ", maxsplit)
mystr1 = 'hello world ha ha ha!'
print(mystr1.split(' ', 2))
# 6.join:将 mystr 插入到 str 中每个元素之间,构造出一个新的字符串
# 格式:mystr.join(str)
mystr2 = '?'
print(mystr2.join(mystr1))
运行结果
| 字符串常见操作 | 格式 |
|---|---|
| capitalize:把字符串的第一个字符大写 | mystr.capitalize() |
| title:把字符串的每个单词首字母大写 | mystr.title() |
| startswith:检查字符串是否以 str 开头, 是->True,否-> False | mystr.startswith(str) |
| endswith:检查字符串是否以str结束,是->True,否-> False | mystr.endswith(str) |
| lower:转换 mystr 中所有大写字符为小写 | mystr.lower() |
| upper:转换 mystr 中的小写字母为大写 | mystr.upper() |
| ljust:左对齐,并使用空格填充至长度 width 的新字符串 | mystr.ljust(width) |
| rjust:右对齐,并使用空格填充至长度 width 的新字符串 | mystr.rjust(width) |
| center: 居中,并使用空格填充至长度 width 的新字符串 | mystr.center(width) |
| lstrip:删除 mystr 左边的空白字符 | mystr.lstrip() |
| rstrip:删除 mystr 末尾的空白字符 | mystr.rstrip() |
| strip:删除 mystr 两端的空白字符 | mystr.strip() |
| rfind:类似find()函数,从右边开始查找. | mystr.rfind(str, start=0,end=len(mystr) ) |
| rindex:类似于 index(),从右边开始 | mystr.rindex( str, start=0,end=len(mystr)) |
| partition:把mystr以str分割成三部分,str前,str和str后 | mystr.partition(str) |
| rpartition:类似于 partition()函数,从右边开始 | mystr.rpartition(str) |
| splitlines:按照行分隔,返回一个包含各行作为元素的列表 | mystr.splitlines() |
| isalpha:如果 mystr 所有字符都是字母,是->True,否-> False | mystr.isalpha( |
| risdigit:如果 mystr 只包含数字 ,是->True,否-> False | mystr.isdigit() |
| isspace:如果 mystr 中只包含空格 ,是->True,否-> False | mystr.isspace() |
4.2 列表
列表的定义
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可
列表的定义
# 列表可以插入不同的数据类型
testList = [1, 'a']
print(testList[0])
print(testList[1])
列表的循环遍历
# 1.使用for循环
for test in testList:
print(test)
# 2.使用while循环
length = len(testList)
i = 0
while i < length:
print(testList[i])
i += 1
列表的相关操作
# 1.添加元素("增"append, extend, insert)
# append:向列表添加元素
# extend:将另一个集合中的元素逐一添加到列表中
# insert:insert(index, object) 在指定位置index前插入元素object
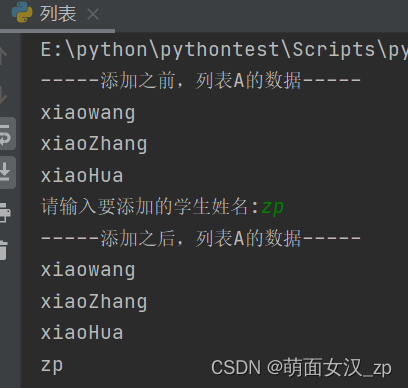
A = ['xiaowang', 'xiaoZhang', 'xiaoHua']
print('-----添加之前,列表A的数据-----')
for i in A:
print(i)
temp = input('请输入要添加的学生姓名:')
A.append(temp)
print("-----添加之后,列表A的数据-----")
for i in A:
print(i)
运行结果
# 2.修改元素(“改”)
# 通过下标,确定修改元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
A[1] = 'xiaoLu'
# 3.查找元素("查"in, not in, index, count)
# 即判断指定元素是否存在
# in, not in : 返回结果为布尔类型
# index和count与字符串中的用法相同
name_list = ['xiaoWang','xiaoZhang','xiaoHua']
find_name = input('请输入要查找的姓名:')
if find_name in name_list:
print('在字典中找到了相同的名字')
else:
print('没有找到')
# 4.删除元素("删"del, pop, remove)
# del:根据下标进行删除
# pop:删除最后一个元素
# remove:根据元素的值进行删除
movie_name = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
del movie_name[2]
# 5.排序(sort, reverse)
# sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
# reverse方法是将list逆置
a = [1, 4, 2, 3]
a.reverse()
a.sort()
a.sort(reverse = True)
列表的嵌套
一个列表的元素又是一个列表,即为列表的嵌套
school_names = [[‘北京大学’,‘清华大学’],
[‘南开大学’,‘天津大学’,‘天津师范大学’],
[‘山东大学’,‘中国海洋大学’]]
4.3 元组
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
创建元组
my_tuple = (‘et’,77,99.9)
# 1.访问元组
tuple1 = ('hello', 10, 3.14)
print(tuple1[0])
# 2.修改元组-->python中不允许修改元组的数据,且不能删除其中的元素
# 3.count, index
# index和count与字符串和列表中的用法相同
4.4 字典
字典格式:{key:value}
info = {‘name’:‘班长’, ‘id’:100, ‘sex’:‘f’, ‘address’:‘地球亚洲中国北京’}
字典和列表一样,也能够存储多个数据
字典中找某个元素时,是根据’名字’(就是冒号:前面的那个值,例如上面代码中的’name’、‘id’、‘sex’)
字典的每个元素由2部分组成,键:值。例如 ‘name’:‘班长’ ,'name’为键,'班长’为值
根据键访问值
# 1.根据键访问值
# 若访问不存在的键,则会报错
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
print(info['name'])
print(info['address'])
#不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还可以设置默认值
age = info.get('age') #'age'键不存在,所以age为None
type(age)
age = info.get('age', 18) # 若info中不存在'age'这个键,就返回默认值18
字典的常见操作1
# 1.查看元素
# 除了使用key查找数据,还可以使用get来获取数据
info = {'name':'吴彦祖','age':18}
print(info['age']) # 获取年龄
print(info['sex']) # 获取不存在的key,会发生异常
print(info.get('sex')) # 获取不存在的key,获取到空的内容,不会出现异常
# 2.修改元素
# 字典的每个元素中的数据是可以修改的,只要通过key找到,即可修改
info = {'name':'班长', 'id':100, 'sex':'f', 'address':'地球亚洲中国北京'}
new_id = input('请输入新的学号')
info['id'] = int(new_id)
print('修改之后的id为%d:'%info['id'])
# 3.添加元素
# 如果在使用 变量名['键'] = 数据 时,这个“键”在字典中,不存在,那么就会新增这个元素
# 4.删除元素
# del:删除指定的元素\删除整个字典
del info['name']
# clear:清空整个字典
info.clear()
字典的常见操作2
len():测量字典中,键值对的个数
keys:返回一个包含字典所有KEY的列表
values:返回一个包含字典所有value的列表
items:返回一个包含所有(键,值)元祖的列表
遍历
# 1.字符串遍历
a_str = 'hello zp'
for char in a_str:
print(char, end=' ')
# 2.列表遍历
a_list = [1, 2, 3, 4]
for num in a_list:
print(num, end=' ')
# 3.元组遍历
a_turple = (1, 2, 3, 4)
for num in a_turple:
print(num, end=' ')
# 4.字典遍历
# 4.1 key遍历
a_dict = {'name': 'zp', 'sex': '女'}
for key in a_dict.keys():
print(key)
# 4.2 value遍历
for value in a_dict.values():
print(value)
# 4.3 遍历字典的项(元素)
for item in a_dict.items():
print(item)
# 4.4 遍历字典key-value(键值对)
for key, value in a_dict.items():
print('key = %s, value = %s' % (key, value))
# 5.enumerate()
# 一般用在 for 循环,将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标.
chars = ['a', 'b', 'c', 'd']
for i, chr in enumerate(chars):
print(i, chr)
公共方法
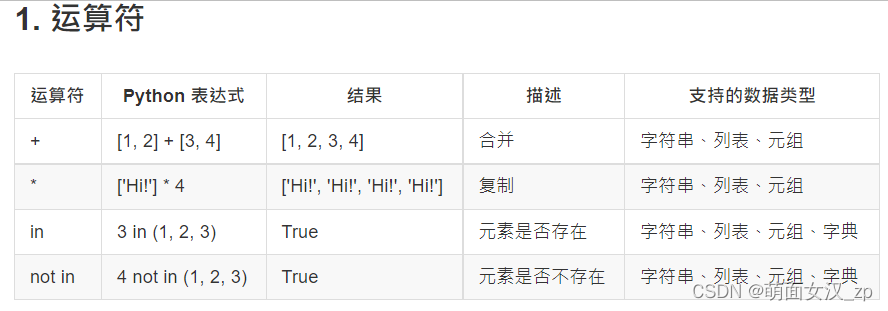
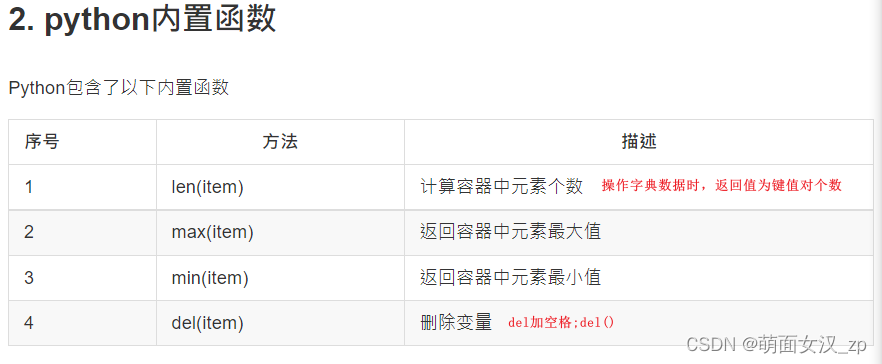
5 函数
5.1 函数的定义和调用
函数
具有独立功能的代码块组织为一个小模块,即为函数
定义函数
'''
1.函数定义格式
def 函数名():
代码
'''
调用函数
通过 函数名() 即可完成调用
每次调用函数时,函数都会从头开始执行,当这个函数中的代码执行完毕后,意味着调用结束了
每次调用函数时,函数都会从头开始执行,当这个函数中的代码执行完毕后,意味着调用结束了
# 1.定义和调用函数
def zp():
print('姓名:zp')
print('年龄:22')
zp()
help说明
利用help()可以查看函数相关说明
函数参数1
1.形参:定义时小括号中的参数,用来接收参数。
2.实参:调用时小括号中的参数,用来传递给函数。
# 1.定义带有参数的函数
def add1num(a, b):
c = a + b
print(c)
add1num(1, 2)
# 2.定义一个函数,完成前2个数完成加法运算,然后对第3个数,进行减法;然后调用这个函数
def sum1(a, b, c):
m = a + b
n = m - c
print(m)
print(n)
sum1(10, 20, 11)
函数参数2
1.缺省参数
在形参中默认有值的参数
调用函数时,缺省参数的值如果没有传入,则取默认值
带有默认值的参数一定要位于参数列表的最后面2.不定长参数
一个函数能处理比当初声明时更多的参数,声明时不会命名。
如果很多个值都是不定长参数,那么这种情况下,可以将缺省参数放到 *args的后面, 但如果有**kwargs的话,**kwargs必须是最后的
1. 缺省参数
# 下例会打印默认的age,如果age没有被传入,则取默认值
def num1(name, age=22):
# 打印任何传入的字符串
print("name: %s" % name)
print("age %d" % age)
# 调用num1函数
num1(name="miki") # 在函数执行过程中 age去默认值22
num1(age=9, name="miki")
2. 不定长参数
基本语法如下:
def functionname([formal_args,] *args, **kwargs):
"""函数_文档字符串"""
function_suite
return [expression]
def fun(a, b, *args, **kwargs):
print("a =%d" % a)
print("b =%d" % b)
print("args:")
print(args)
print("kwargs: ")
for key, value in kwargs.items():
print("key=%s" % value)
fun(1, 2, 3, 4, 5, m=6, n=7, p=8)
c = (3, 4, 5)
d = {"m": 6, "n": 7, "p": 8}
fun(1, 2, *c, **d)
fun(1, 2, c, d)
函数返回值1
定义:程序中函数完成一件事情后,最后给调用者的结果
想要在函数中把结果返回给调用者,需要在函数中使用return
加了星号(*)的变量args会存放所有未命名的变量参数,args为元组
而加**的变量kwargs会存放命名参数,即形如key=value的参数, kwargs为字典
# 1.带有返回值的函数
def add2num(a, b):
c = a + b
return c
# 2.保存函数的返回值
result = add2num(100, 98)
print(result)
函数返回值2
return除了能够将数据返回之外,还有一个隐藏的功能:结束函数
一个函数中可以有多个return语句,但是只要有一个return语句被执行到,那么这个函数就会结束了,因此后面的return没有什么用处
return后面可以是元组,列表、字典等,只要是能够存储多个数据的类型,就可以一次性返回多个数据
如果return后面有多个数据,那么默认是元组
函数的嵌套调用
函数嵌套调用–>一个函数里面又调用了另外一个函数
如果函数A中,调用了另外一个函数B,那么先把函数B中的任务都执行完毕之后才会回到上次 函数A执行的位置
局部变量
1.局部变量:即函数内部定义的变量。
只能在这个函数中使用,在函数的外部是不能使用的。
不同的函数可以定义相同名字的局部变量
2.局部变量的作用
为了临时保存数据需要在函数中定义变量来进行存储
当函数调用时,局部变量被创建,当函数调用完成后这个变量就不能够使用了
全局变量
1.什么是全局变量
在函数外边定义的变量叫做全局变量
一个变量,既能在一个函数中使用,也能在其他的函数中使用,这样的变量就是全局变量
能够在所有的函数中进行访问
2.全局变量和局部变量名字相同问题
当函数内出现局部变量和全局变量相同名字时,函数内部中的 变量名 = 数据 此时理解为定义了一个局部变量,而不是修改全局变量的值
3.修改全局变量
如果在函数中出现global 全局变量的名字 那么这个函数中即使出现和全局变量名相同的变量名 = 数据 也理解为对全局变量进行修改,而不是定义局部变量
如果在一个函数中需要对多个全局变量进行修改,那么可以使用global
多函数程序的基本使用流程
在实际开发过程中,一个程序往往由多个函数组成,并且多个函数共享某些数据,因此下面来总结下,多个函数中共享数据的几种方式
# 1. 使用全局变量
g_num = 0
def test1():
global g_num
# 将处理结果存储到全局变量g_num中,即修改全局变量的值
g_num = 100
print(g_num)
def test2():
# 通过获取全局变量g_num的值, 从而获取test1函数处理之后的结果
print(g_num)
test1()
test2()
# 2. 使用函数的返回值、参数
def test1():
return 50
def test2(num):
# 通过形参的方式保存传递过来的数据,就可以处理了
print(num)
result = test1()
test2(result)
# 3. 函数嵌套调用
def test1():
# 通过return将一个数据结果返回
return 20
def test2():
# 1. 先调用test1并且把结果返回来
result = test1()
# 2. 对result进行处理
print(result)
# 调用test2时,完成所有的处理
test2()
拆包、交换变量的值
1.拆包
需要拆的数据的个数要与变量的个数相同,否则程序会异常
除了对元组拆包之外,还可以对列表、字典等拆包
2.交换2个变量的值
# 1.对返回的数据直接拆包
def get_my_info():
high = 178
weight = 100
age = 18
return high, weight, age
my_high, my_weight, my_age = get_my_info()
print(my_high)
print(my_weight)
print(my_age)
引用
id()来判断两个变量是否为同一个值的引用
Python中函数参数是引用传递(注意不是值传递)
对于不可变类型,因变量不能修改,所以运算不会影响到变量自身
对于可变类型来说,函数体中的运算有可能会更改传入的参数变量
可变、不可变类型
可变类型与不可变类型是指:数据能够直接进行修改,如果能直接修改那么就是可变,否则是不可变
可变类型有: 列表、字典、集合
不可变类型有: 数字、字符串、元组
6 文件的操作
6.1 文件操作的介绍
** 1.什么是文件**
数据的各种存在形式
** 2.文件的作用**
把数据存储起来
6.2 文件的读写
1.写数据(write)
使用write()可以完成向文件写入数据
f = open('test.txt', 'w')
f.write('hello world, i am here!')
f.close()
2.读数据(read)
a.使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
b.如果用open打开文件时,如果使用的"r",那么可以省略,即只写 open(‘test.txt’)
f = open('test.txt', 'r')
content = f.read(5) # 最多读取5个数据
print(content)
print("-"*30) # 分割线,用来测试
content = f.read() # 从上次读取的位置继续读取剩下的所有的数据
print(content)
f.close()
3.读数据(readlines)
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
f = open('test.txt', 'r')
content = f.readlines()
print(type(content))
i=1
for temp in content:
print("%d:%s" % (i, temp))
i += 1
f.close()
4.读数据(readline)
5.文件备份
# 输入文件的名字,然后程序自动完成对文件进行备份
old_file_name = input("请输入要拷贝的文件名字:")
# 以读的方式打开文件
old_file = open(old_file_name, 'rb')
# 提取文件的后缀
file_flag_num = old_file_name.rfind('.')
if file_flag_num > 0:
file_flag = old_file_name[file_flag_num:]
# 组织新文件的名字
new_file_name = old_file_name[:file_flag_num] + '[复件]' + file_flag
# 创建新文件
new_file = open(new_file_name, 'wb')
# 把旧文件中的数据,一行一行的进行复制到新文件中
for live_content in old_file.readlines():
new_file.write(live_content)
# 关闭文件
old_file.close()
new_file.close()
6.3 文件的相关操作
python的os模块:对文件进行重命名、删除等一些操作
1. 文件重命名
rename(需要修改的文件名, 新的文件名)
import os
os.rename("毕业论文.txt", "毕业论文-最终版.txt")
2. 删除文件
remove()可以完成对文件的删除操作
remove(待删除的文件名)
import os
os.remove("毕业论文.txt")
3. 创建文件夹
import os
os.mkdir("张三")
4. 获取当前目录
import os
os.getcwd()
5. 改变默认目录
import os
os.chdir("../")
6. 获取目录列表
import os
os.listdir("./")
7. 删除文件夹
import os
os.rmdir("张三")
8.批量修改文件名
import os
fun_flag = 1
folder_name = './filr'
# 获取指定路径的所有文件名字
dir_list = os.listdir(folder_name)
# 遍历输出所有文件名字
for name in dir_list:
print(name)
if fun_flag == 1:
new_name = '[zp]_' + name
elif fun_flag == 2:
num = len('[zp]_')
new_name = name[num:]
print(new_name)
os.rename('./filr' + name, './filr' + new_name)















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











