







文章目录
1、NoSQL数据库简介(非关系型数据库)
1.1在web2.0时代出现了大量用户上网,出现了两个压力
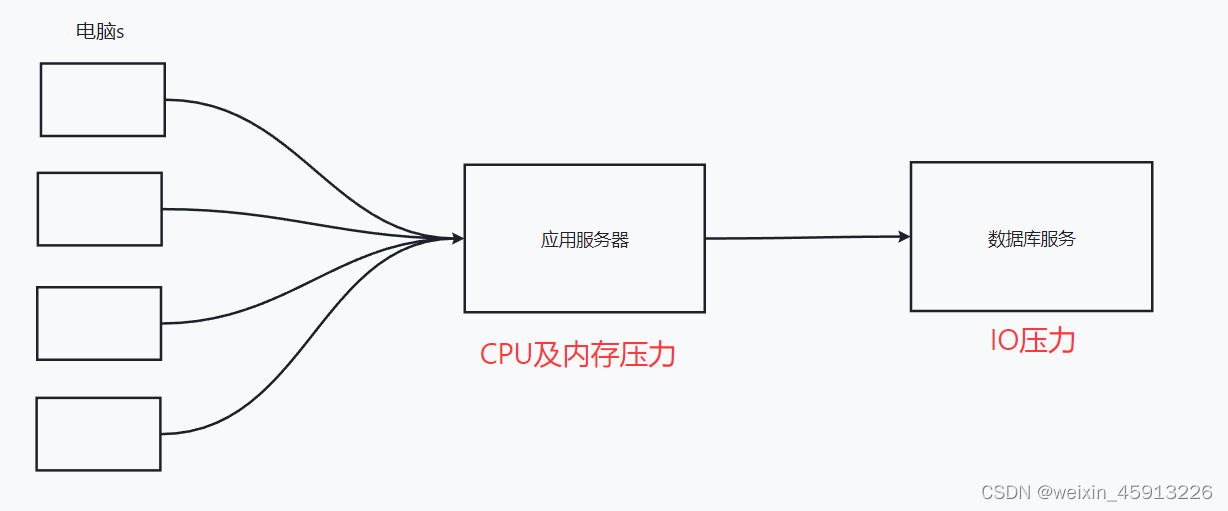
1.1.1解决CPU及内存压力和IO压力:
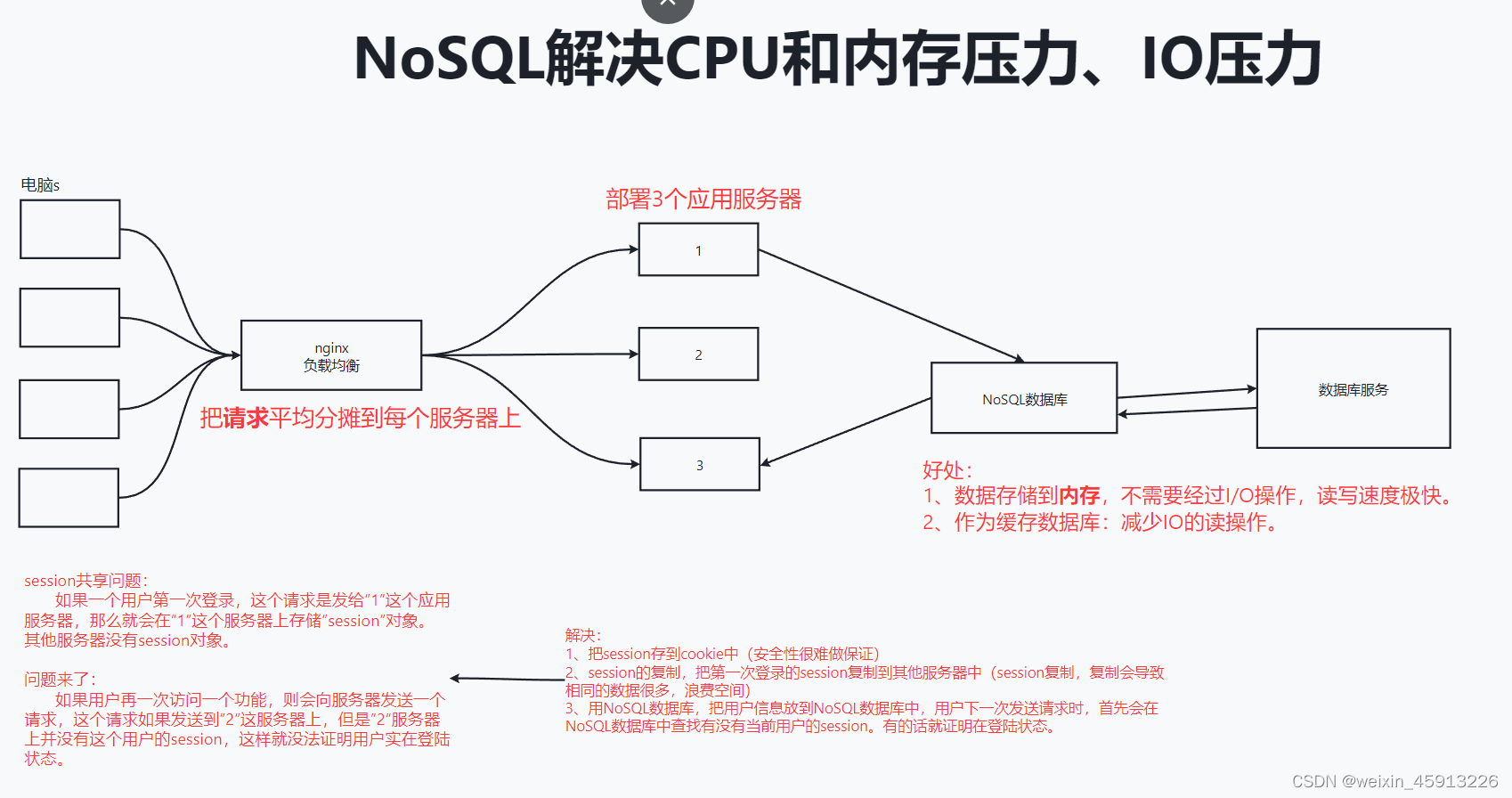
1.2NoSQL简单概述
1.2.1NoSQL数据库概述
- 不支持SQL标准
- 不支持ACID。即事务的四大特性原子性、一致性、隔离性、持久性
- 远超SQL的性能
1.2.2NoSQL使用场景
- 对数据高并发的读写(电商里的秒杀场景)
- 海量数据的读写
- 对数据的高扩展性
1.2.3NoSQL不适用场景
- 需要事务的支持
- 基于SQL的结构化查询存储,处理复杂的关系。
1.2.4有哪些NoSQL数据库
- Memcache(缺点不支持数据的持久化,数据不能存储到硬盘中)
- Redis (支持数据的持久化、支持多种数据结构list\set\hash\zset)
- mongoDB(文档型数据库、存储的数据类型更加的多样化)
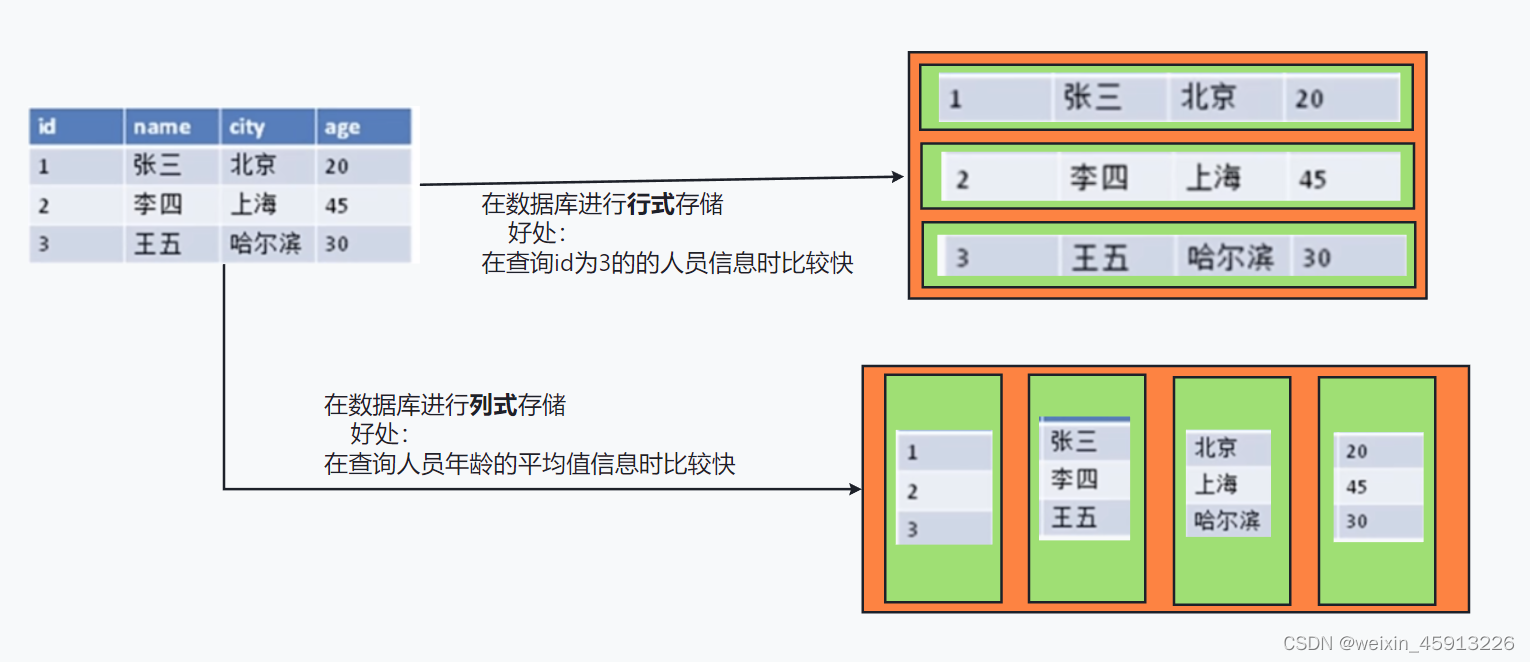
1.3行列式存储数据库(大数据时代)
2、Redis安装
2.1使用宝塔傻瓜式安装
2.2Redis启动
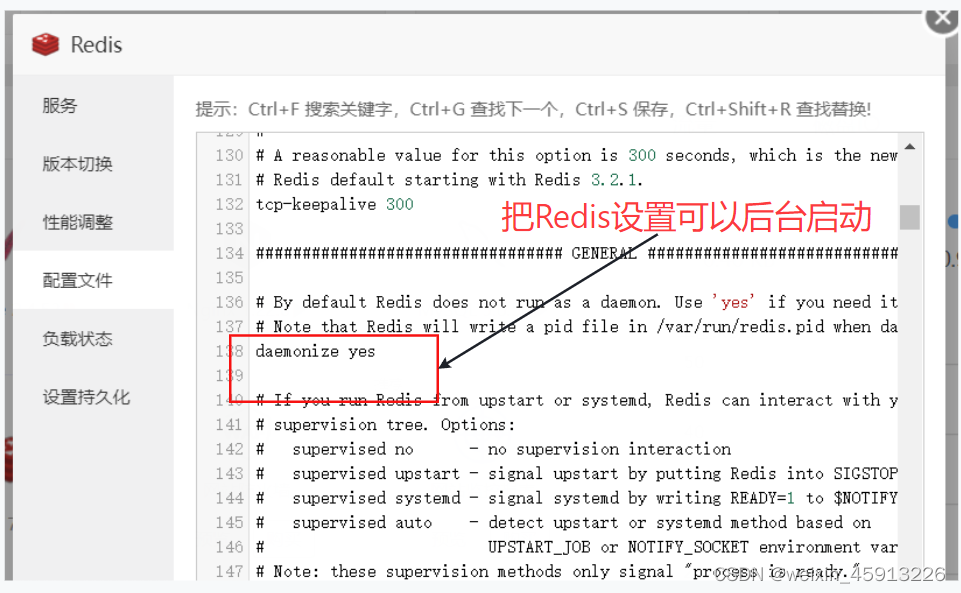
- ps -ef | grep redis //查看redis启动后的进程
- reids-server redis.conf //启动redis服务
- redis-cli //设置可以用客户端终端访问
- auth 123456 //输入密码
- 127.0.0.1:6379> ping //测试验证一下
2.3Redis关闭
- 第一:用宝塔关闭(简单)
- 第二:单实例关闭:redis-cli shutdown
- 第三:可以进入终端后关闭

- 第四:知道redis进程号后用kill命令杀掉redis进程
3、Redis相关知识介绍
3.1Redis是单线程+多路IO复用技术(可以实现多线程的效果)
- 如下图描述:单线程+多路IO复用
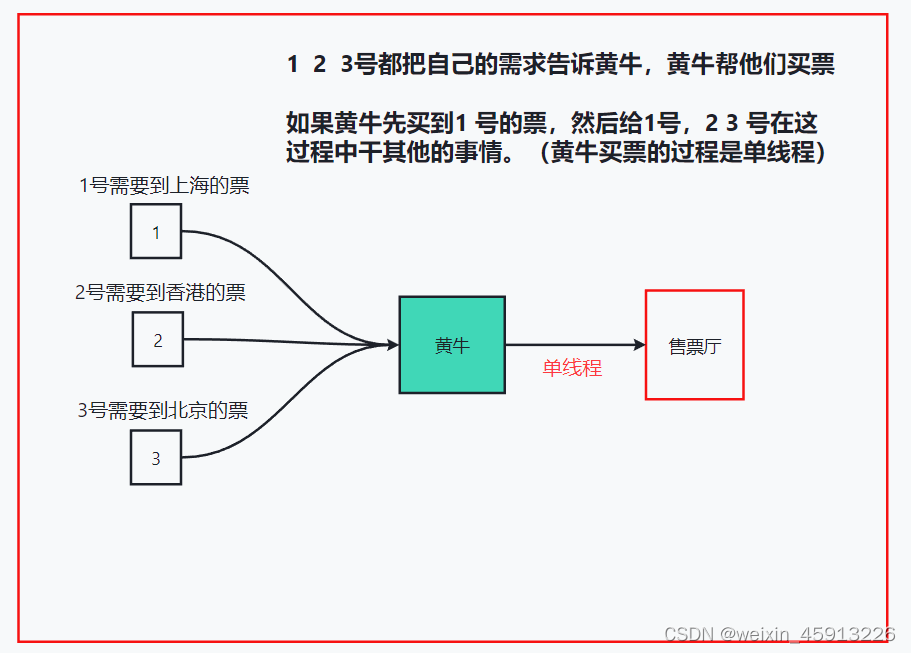
- Redis读取是原子操作,因为在黄牛和售票厅之间是单线程的,不像多线程里面需要加锁
3.2Redis中常用5大基本数据类型
(1)Redis键(key)
- keys * :查看当前库中的所有key
- set :设置key-value
- exists key1 :判断key1是否存在——返回1:存在,2:不存在
- type key2 :查看key2所对应值的类型
- del key2 :删除key2
- unlink key2 :删除key2(它会先返回消息说已经删掉了key2,其实还没有删除,真正的删除是在以后慢慢删除,异步删除)
- expire key1 10 :设置过期时间,为key1设置10秒后过期
- ttl key1:查看key1是否已经过期——返回: -1:永不过期,-2:已经过期
- select :切换库(Redis一共有16个库,默认用0号库)
- dbsize :查看当前数据库的key的数量
- flushdb:清空当前库
- flushall :通杀全部库
(2)字符串String
- String类型是二进制安全的。意味着Redis的String可任意包含任何数据。比如jpg图片,或者序列化对象,通俗点,只要你的内容能用字符串表示,我们都能存到Redis去。
- String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以达到512MB。
- 关于String的命令:
- set:添加key—value (设置相同key的数据会把前面的覆盖掉)
- get:取值
- append:将指定的value追加到原来值的末尾
- strlen:获取指定值的长度;
- setnx:当库中没有对应的key时,设置key-value才能成功。(以防覆盖原来的);
- incr key:将key中存储的数值加1,如果为空,则新增值1;
- decr key:将key中存储的数值减1;
- incrby/decrby key 步长:给数值加减指定的数。
- mset :同时设置多个key-value(不保证原子性)
- mget :同时获取多个key分别对应的值(不保证原子性)
- msetnx:同时设置多个key-value,但是key不能和之前有重复,如果有一个重复则这次设置的key-value都失败;(体现原子性)
- getrange key 起始位置 结束位置:获取key对应值的
- setrange key 起始位置 value : 用value覆盖掉从起始位置开始的值
- setex key 过期时间 value 设置key-value时设置过期时间;
- getset key1 value:设置新的key1-value;同时输出原来的key1对应的value
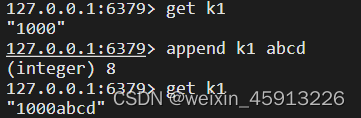
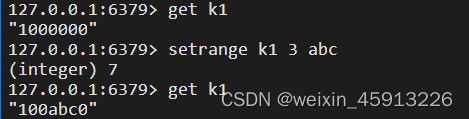
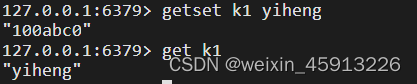
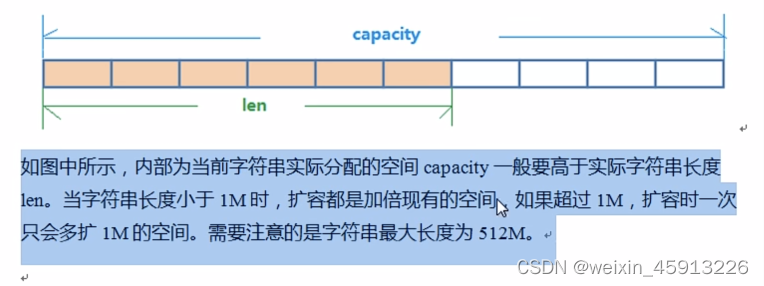
- String的数据结构:
- String的内部结构为简单的动态字符串(Simple Dynamic String),是可以修改的字符串(Java的字符串是不可变的),其内部结构类似于Java中的ArrayList,可以伸缩。
(3)列表(List)
- List是简单的字符串列表,里面存储的都是一个一个的字符串;
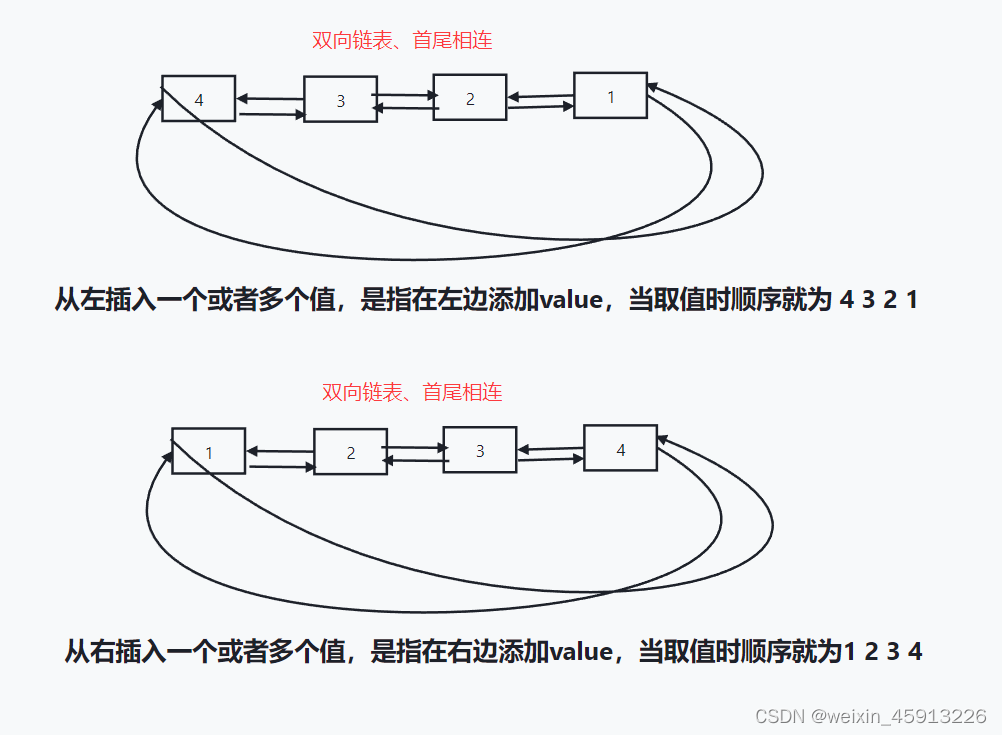
- List底层实现为一个循环的双向链表,对两端的操作时它性能很高,当需要通过下标操作中间件时性能较差。
- 常用命令:
- lpush/rpush key value1 value2 value3:从左/右边边放入多个值;
- lrange key1 start stop: 按照索引下标获取元素(从左到右)
如:lrange key1 0 -1: 从左到右取出所有元素,0代表第一个位置,因为是链表List底层是双向链表,所以-1代表左后一个位置。- lpop/rpop key count: 从key对应的链表的左边或者从右边取出count个值; 每取出一个值该链表少一个值;
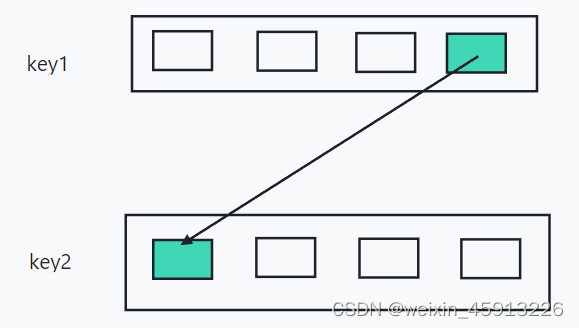
- rpoplpush key1 key2 :把key1最右边的一个value放到key2最左边去。
- lindex key index :按照索引下标获得元素;
- linsert key before value newvalue: 在旧的值的后面插入一个新的值;
- lrem key N value11:从左边到右边删除N个一样的value;
- lset key index value :将key对应列表中下标为index的值替换为value
- List列表数据结构:
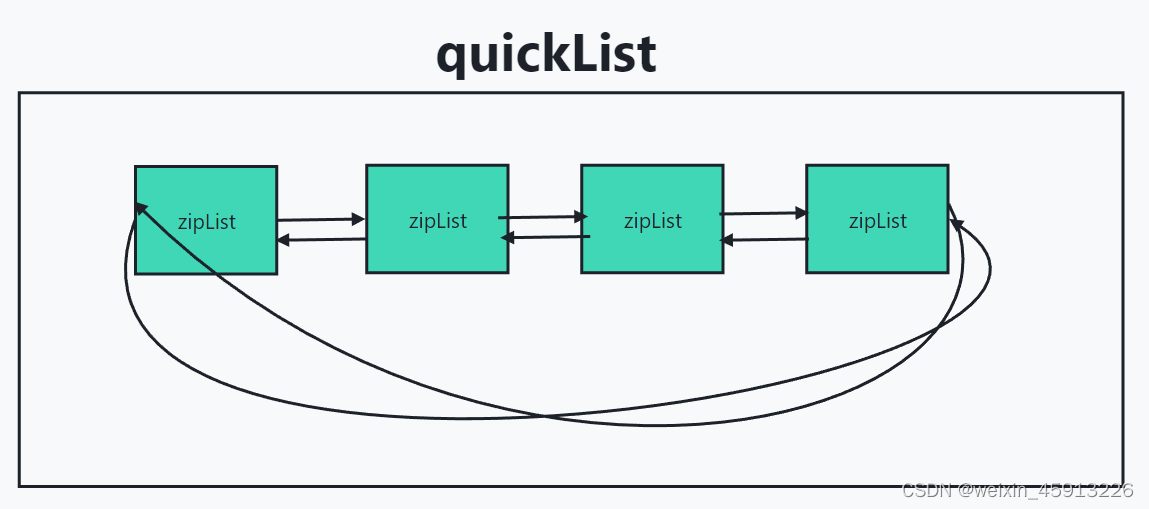
- List会在数据量较少时寻找一块连续的空间,结构为zipList.也就是压缩列表。只有数据量比较多时才会改成多个zipList首尾相连的quickList(链表实现)
- 使用普通链表,如果存放的只是int型数据,还需要在两边加上指针(prev,next),极大浪费空间。
(4)集合(Set)
- Redis Set和List的功能不同在于List可以有重复项,而Set没有重复项。Set可以自动排重
- Redis Set集合内提供了查看一个成员是否在Set中的接口,而List当中就没有这样的就功能。
- Redis Set是String类型的无序集合,底层就是一个值为null的hash表,所以添加删除查找复杂度都是O(1).
- 常用命令:


- Redis Set数据结构:
- Set数据结构是dict字典,字典就是哈希表实现;
- Java中HashSet就用HashMap实现,只不过所有的value指向同一个对象。
- Redis的set结构也是一样,它内部也使用hash结构,所有的value都指向同一个内部的值。
(5)哈希(hash)
- Redis hash的由来:Redis hash是一张String类型的field和value的映射表,hash特别适合存储对象,类似于Java中的Map<String,Object>.


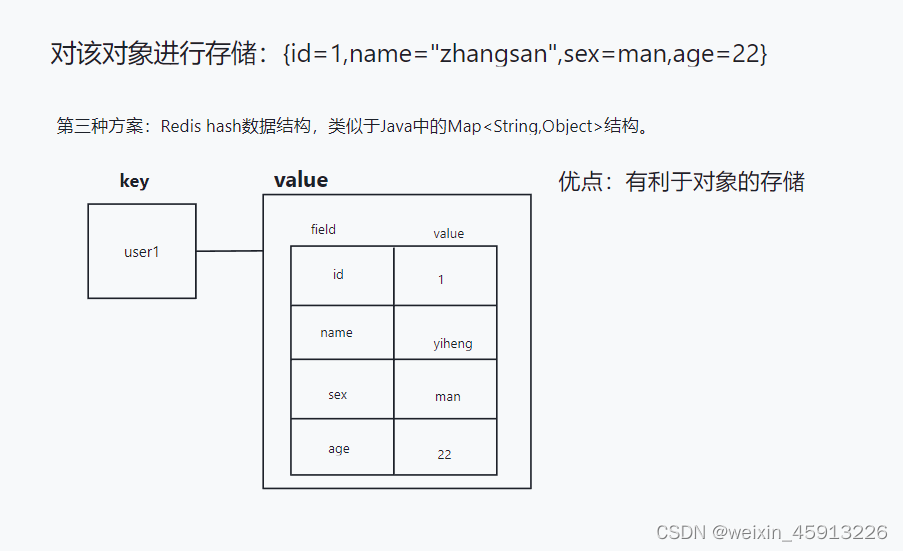
- hash常用命令:

- hash数据结构:
hash类型对应的数据类型是2种:zipList(压缩列表),hashTable(哈希表)。当field-value长度较短并且个数较少时,使用zipList,否则使用hashTable。
(6)有序集合(ZSet)
- 简介:Redis有序集合Zset与普通集合Set很类似,没有一个重复元素的字符串集合。
- 不同之处在于Zset的每个成员有关联一个评分,该评分(score),集合中的成员按照自己关联的评分高低排先后顺序。集合成员是唯一的,但是成员关联的评分可以相同。
- Zset的元素是有序的,而且没有重复项。
- 常用命令:


- 案例:利用Zset实现一个文章访问量排行榜。
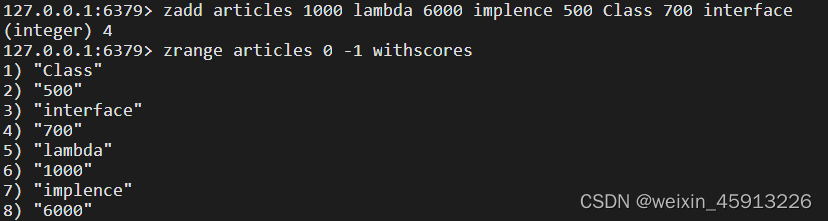
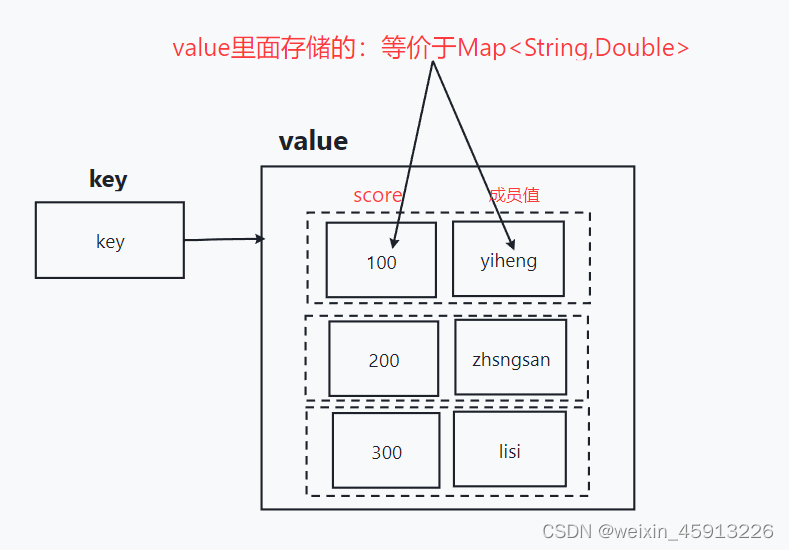
- Zset数据结构:
- Zset数据结构很特殊,一方面,value内部等价于Java中的Map<String,Double>
- 另一方面,类似于TreeSet,内部的元素会按照权重score来排名,还可以用过score范围来获取范围内的元素。
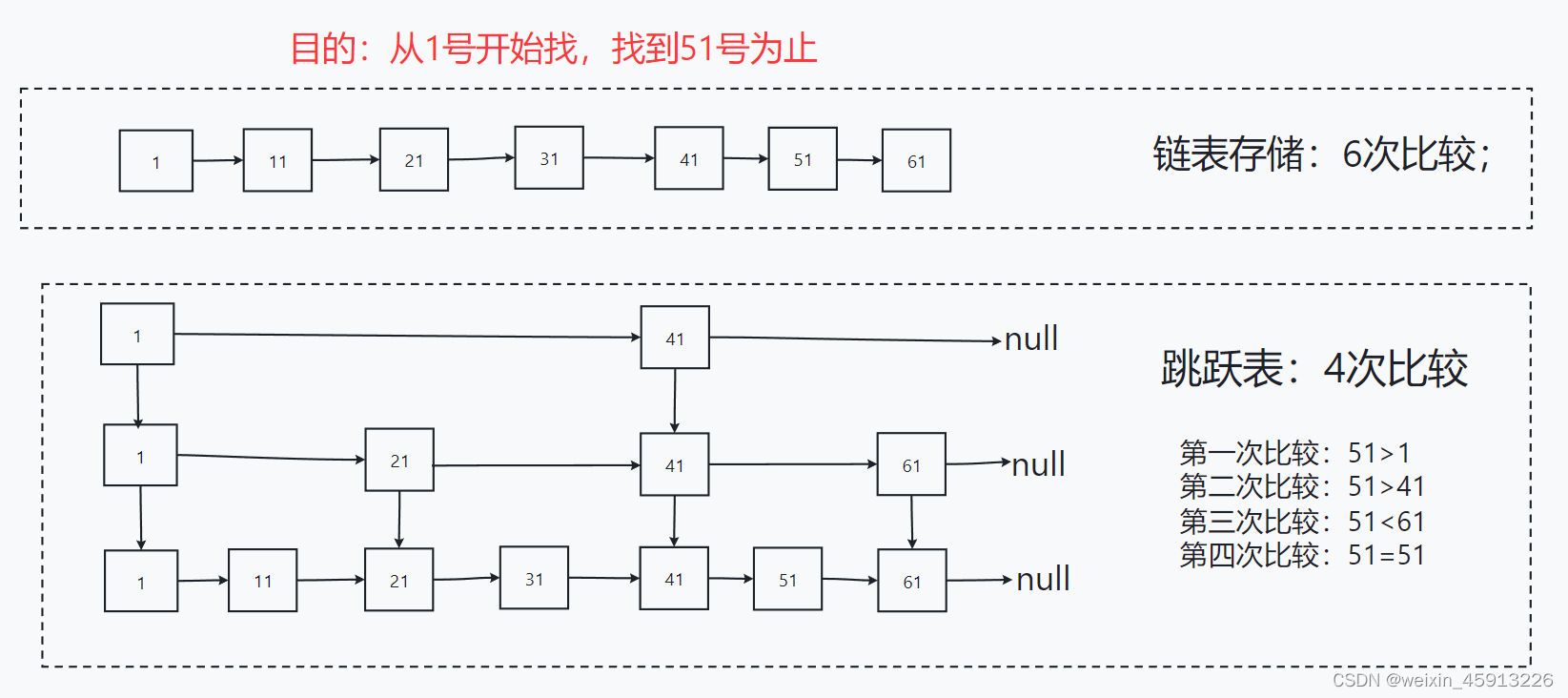
- Zset底层使用了两个数据结构。
(1)hash,hash的作用是的作用是关联元素的值与score,保证元素的唯一性,可任通过value找到相应的score值。
(2)跳跃表(跳表),跳跃表的目的:在于给元素value排序,根据score来查找元素。
例如:

4、Redis配置文件讲解
4.1
5、Redis的发布和订阅
5.1什么时发布和订阅?
- Redis发布和订阅是一种通信模式:发送者发送消息,订阅者接收消息
- Redis客户端可以订阅任意数量的频道。
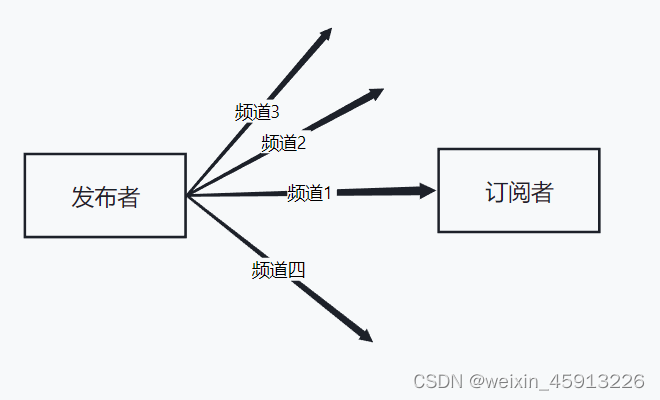
5.2Redis的发布与订阅。
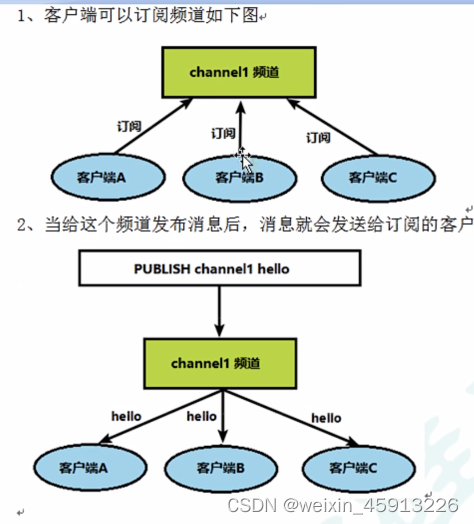
5.3发布与订阅的命令实现。
- 打开一台客户端订阅频道1、2;
- SUBSCRIBE channel1 chanel2————订阅频道1 和频道2
- 打开另一台客户端分别向频道1和频道2发送“nihao”;
- publish channel1 nihao ————向频道1发送“nihao”
- publish channel2 nihao————向频道2发送“nihao”
6. Redis新数据类型
6.1Bitmaps:新数据类型
(1)Redis提供了Bitmaps这个数据类型可以实现对位操作:
- Bitmaps本身不是数据类型,实际上它就是字符串(相当于字符类型和字符串的差别)。
- Bitmaps可以被想象成一个以bit(位)为单位的数组(这个数组中只能存“0”或者“1”,如果存默认数组里面全是0),数组的下标叫做偏移量(offset)
- 基本命令:
- setbit key offset value :往一个key对应的数组(以位为单位的数组)中的offset(偏移量)的这个位置存一个值,value值只能为“0”或“1”;
- getbit key offset:取出该offset(偏移量)对应的值
- bitcount key :统计key对应的Bitmaps中为“1”的个数。
- bitcount key start end bit :以bit为单位在start和end中有多少个“1”;
- bitcount key start end byte :以byte为单位在start和end中有多少个“1”;
- bitop and(or/not/xor) destkey key[key…],对多个Bitmaps求,and(交集)、or(并集)、not(非)、xor(异或)操作,并将结果保存在目标Bitmaps(deskey)中。
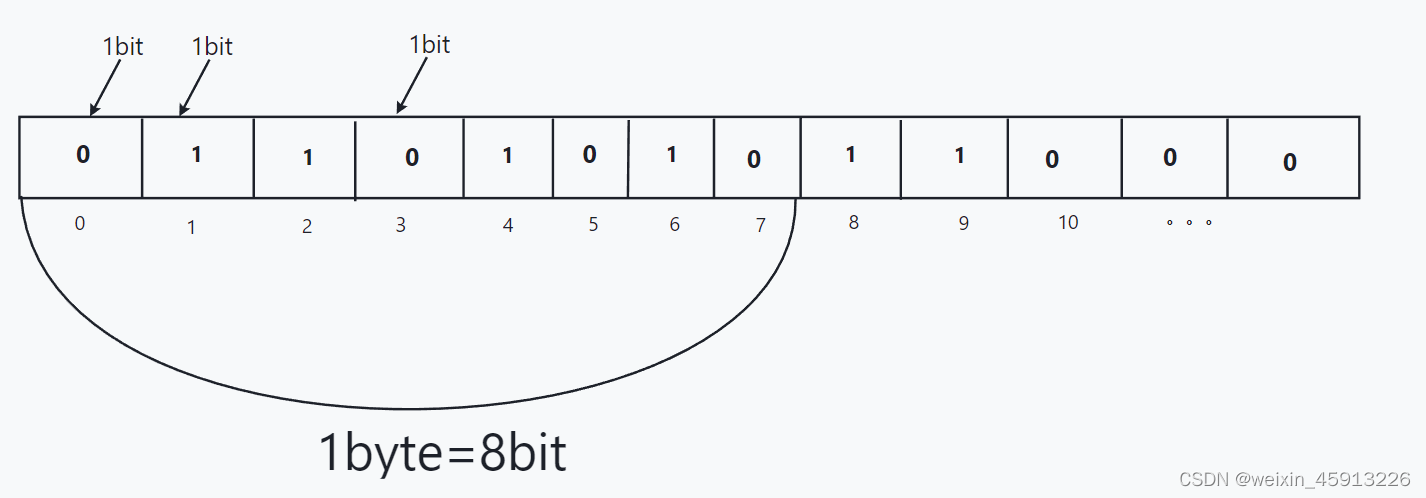
- 举例1:一个班的有10位同学,学号分别为1 2 3 4 5 6 7 8 9 10,如果他们看了青年大学习就用”1”表示,如果没看就用“0”表示;把他们的学号作为offset(偏移量),value就是“0”或者“1”;

- 举例2:统计一个有1亿用户数量的网站的某一天的活跃用户数量,若1亿用户里有5000万用户活跃。
方案一:用集合Set存储活跃用户的id,每个人的id占64位,那么存储id总共花费:64bit x 5000万=32亿bit
方案二:用Bitmaps记录每一位用户是否活跃,那么花费:1bit x 1亿=1亿bit
结论:很明显当活跃用户多时,方案二很好;但是活跃用户少时,方案一好;
- Bitmaps用来表示一个团体的人做一件事,哪些人做了,哪些人没做很合适(或者像统计一个网站的活跃用户有哪些)。比如一个班看青年大学习,有一部分同学看了,一部分同学还没看,怎么记录看了的同学?就把看了的同学的学号作为偏移量或者数组下标,以1作为value存到Bitmaps中。
6.2HyperLogLog:新数据类型
- 主要用来解决基数运算。什么是基数?就是像一个集合中去了重复项之后的总的个数。
- 如:统计一个网站今天有多少个ip地址访问过。
解决像这样的问题有很多种解决方案:
- 方案一:如果数据存储在Mysql中,使用distinct count统计不重复的值;
- 方案二:使用Redis中的hash、set、bitmaps、这些结构都能处理
- 为什么不用这些结构:因为以上数据结构如果对于大的数据集,将要浪费大量空间,不切实际。
- 方案三:使用hyperLogLog来统计
- HyperLogLog是用来统计基数的算法。
- 优点:HyperLogLog计算基数所需的空间是固定大小的,并且很小。
- HyperLogLog算法,不像Zset、hash这些数据结构内部的算法,后者在统计量很大的数据集时占用空间也会很大,不划算。
- HyperLogLog只会根据输入的元素计算出基数,而不会像Zset、hash存储元素。
- 基本命令:
- pfadd key value[values]:把value添加,并不是存储起来,而是用来计算基数
- pfcount key :计算基数;
6.3Geospatial
Geo:Geographic:地理学的
spatial:空间的
- Redis3.2增加了地理信息类型的支持,该类型的元素就是二维坐标。经度和纬度。(经度范围:-180_180;维度范围:-85_85)
- 基本命令:
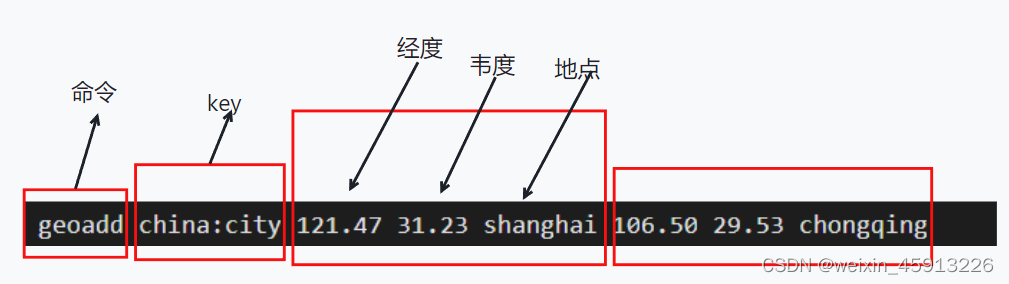
- 添加多个个地点
- geopos key shanghai:取一个地点的经纬度:
- geodist key member1 member2 [m米/km千米/ft英尺/mi英里]:得到两个地点之间的直线距离
- georadius key 经度 维度 半径 [m/km/ft/mi] 以一个经纬度为中心,得到周围半径以内的距离的地点有哪些。

7、 jedis连接Redis
8、Redis_jedis实例
8.1做一个手机验证码功能:
简介:
- 生成随机6位数验证码,把这个验证码存在Redis中,然后再把这个数发送个用户;
- 生成的验证码2分钟失效,并且一天内只能生成3次验证码。
- 用户输入收到的验证码,并且输入
- 把用户输入的验证码与Redis中调出的验证码做等价判断。
package com.yiheng.jedis;
import redis.clients.jedis.Jedis;
import java.util.Random;
import java.util.Scanner;
//案例需求:
//输入手机号之后,我们点击一下,能够获取随机6位的验证码。
public class PhoneCode {
public static void main(String[] args) {
//1、用户点击获取验证码后:向Redis保存生成的验证码,并且向用户发送该验证码;
int i = verifyCode("18728089510");
if(i==1){
//达到了获取3次的界限
System.out. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









