






背景
实验室的服务器被劫持了,重装了系统。中间探索了很多东西,记录一下。
题目中校内的主要限制在于:
- 镜像网站的选择,用的浙江大学镜像站
- 系统重装操作依赖管设备的老师
- 可能存在联网权限问题
- 需要装 zjunet 来联外网
文章目录
1. 备份
重装时只需要重写系统盘,也就是本身硬盘上的系统分区。不会动数据盘。
师姐先见之明,conda环境全部安装在挂载的数据盘上,实验数据最后也全部挪过去了。
这里需要查看数据盘叫什么,挂载到哪。
# 查看硬盘详情,可以看到数据盘叫什么
$ fdisk -l
# 可以查看挂载情况,比如我的数据盘/dev/sdb1挂载在/data文件夹下
$ df -h
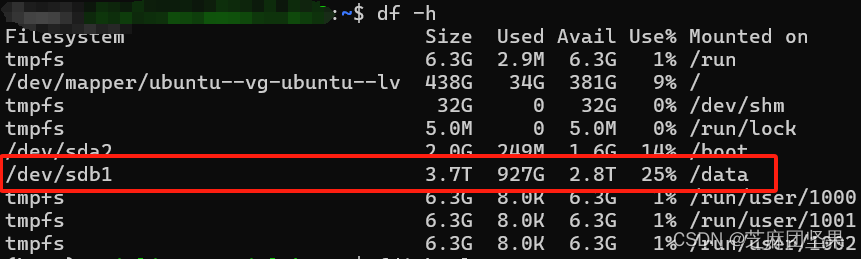
备注:这里本应该把数据盘unmount一下,但我忘了,后续倒也没影响。注意重装的时候别把系统装到数据盘(交给有经验的设备老师或前辈就没事)。
ChatGPT建议我备份一大堆东西,后来发现倒也不需要。备份好数据就可以去找管设备的老师重装了。
2. 启动盘制作
系统架构是4张3090,x86_64。所选是Ubuntu 22.04系统。
这里可能需要考虑和CUDA Toolkit的适配。比如我之前需要用CUDA Toolkit 11.6,但没有Ubuntu 22.04的CUDA Toolkit 11.6,只有Ubuntu 20.04的,后来解决方法是硬装,也能跑,但应该不建议。
下载地址:Ubuntu官网,下载下来的文件名是ubuntu-22.04.4-live-server-amd64.iso
启动盘制作工具:rufus,这个是按手头电脑的操作系统选的,我在win系统制作启动盘,推荐的多的是这个。不用安装,即开即用。
我使用的是4.5版本,参数配置如图:
- 设备选择的是插入的U盘
- 引导类型选“镜像文件”,然后选择前面下下来的ubuntu iso
- 其他设置保持默认
- 点击开始。
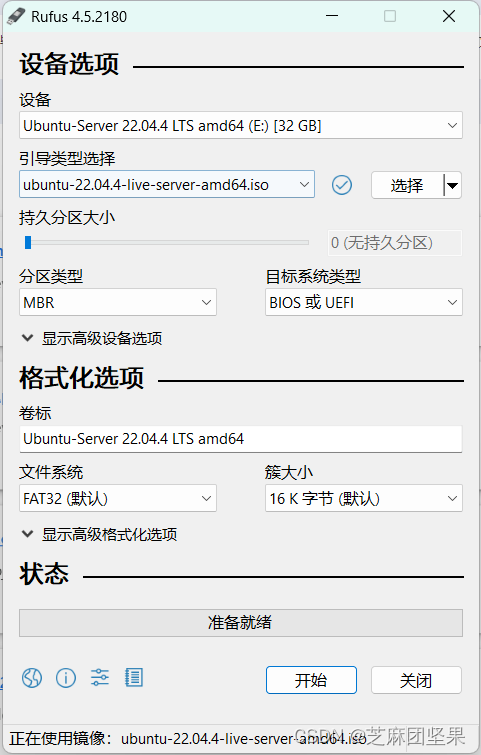
制作完成后,状态条会全绿,字样仍然是“准备就绪”没改,没事的。
拿着启动盘去找管设备老师吧。
3. 重装系统
设备老师带着去机房,找到要重装的一组卡,插入启动盘(U盘),关机,从启动盘启动…所有都等着老师操作就好。下面只记一点学到的东西。
过程中需要配置服务器ip、子网、服务器名、用户和密码。设置ssh登录(启用)和公钥登录(关闭)。用户只是个新user不是root,root要后期启用。老师建议不要开启ssh连接root的权限,要用root就从普通用户su过去,避免被攻击。
至此结束,其他都回去自己捣鼓。
4 启用root用户
参考:新安装的linux/ubuntu,root用户的设置步骤
5 修改ssh服务默认端口
参考:linux下ssh使用除了22的其它端口来连接远程服务器
6. 联网
Step1:配置dns。
- 配置dns:修改
/etc/systemd/resolved.conf文件,DNS=写入老师给的dns地址。 - 重启服务:
systemctl restart systemd-resolved
systemctl enable systemd-resolved
注意不需要修改
/etc/resolv.conf的nameserver
Step2:修改镜像源
按照浙大镜像站的指导进行:ZJU Mirror Ubuntu
这里提到需要选择Ubuntu版本,可以执行lsb_release -a查看。这里可以确认我装的是22.04 jammy。
$ lsb_release -a
Output:
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.4 LTS
Release: 22.04
Codename: jammy
Step3: 更新系统
至此,应该可以正常执行
sudo apt update && sudo apt upgrade
如果仍然报错如图所示Failed to fetch,那么询问设备老师打开联网权限。有可能老师设置连校网都连不上。
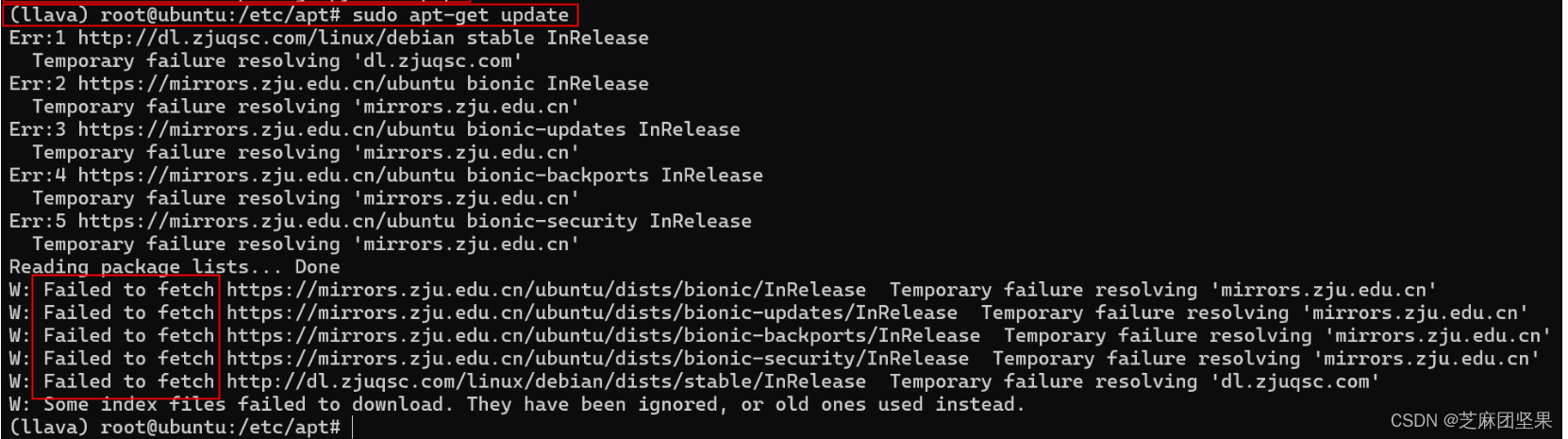
如果提示“Pending kernel upgrade… Newer kernel available… Restarting the system to load the new kerne will not be handled automatically, so you should consider rebooting.”,那就reboot一下。重启快则3分钟慢则一小时,可以通过ssh连接试探是否重启完毕。
Step4: 下载安装xl2tpd
$ apt-get install xl2tpd
如果提示“E:Unable to Locate Package ”,说明前面某一步没配好。
Step5: 下载安装zjunet
参考 浙江大学校园网 Ubuntu有线网上网详解 和 Github: QSCTech/zjunet
7 安装nvidia driver和cuda toolkit
这一块我研究了很多,先说最终方案,再说中间绕了哪些路。
总共要安装三个东西:Nvidia driver,CUDA,CUDA toolkit。
- 其中,在安装Nvidia driver时,CUDA已经捆绑安装,也就是
nvidia-smi查询到的CUDA显示。 - CUDA toolkit是运行时环境,可以安装很多版本,通过修改环境变量来选取当前项目适用的运行时环境,通过
nvcc -V查询是哪个版本。此外,在安装CUDA Toolkit时,还可以选择是否捆绑安装NVIDIA Graphics Drivers显卡驱动。我这里建议不捆绑,因为会修改之前装好的driver。- 在只使用torch的情况下,不需要安装CUDA Toolkit和cuDNN,只需要显卡驱动,conda或者pip会为我们安排好一切。但如果要加入一些第三方依赖,还是要额外装个CUDA Toolkit的。(参考:【PyTorch】n卡驱动、CUDA Toolkit、cuDNN全解安装教程)
7.1 安装nvidia driver
一行命令直接安装默认适合的驱动,至此结束。
# 安装
$ sudo ubuntu-drivers autoinstall
# 重启
$ sudo reboot
# 查看driver是否正常安装
$ nvidia-smi
此时安装的版本和ubuntu-drivers devices查询的推荐版本是一致的。
绕路 1:确定驱动版本
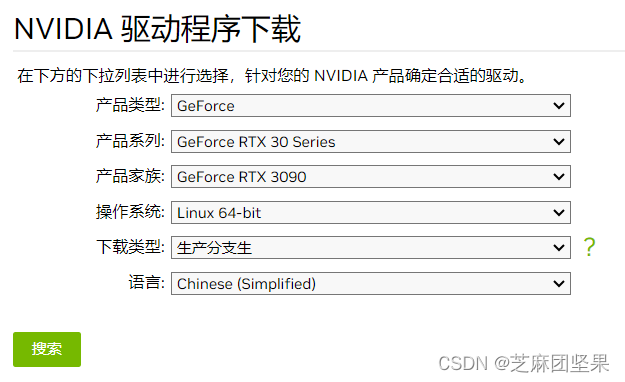
网上教程有两种说法,一是去nvidia官网查找适合的驱动,二是通过ubuntu-drivers devices命令,查询推荐版本。我的两个版本不一致。
- nvidia官网查找如图所示,我查到的是2024/04/25新发布的550.78版本。

- 通过
ubuntu-drivers devices命令,查询输出如下。查询得到的最高版本也就只有535。
$ ubuntu-drivers devices
ERROR:root:aplay command not found
== /sys/devices/xxxxxxxxxxx ==
modalias : xxxxxxxx
vendor : NVIDIA Corporation
model : xxxxxxxx [GeForce RTX 3090]
driver : nvidia-driver-535-server - distro non-free
driver : nvidia-driver-545-open - distro non-free
driver : nvidia-driver-470 - distro non-free
driver : nvidia-driver-545 - distro non-free
driver : nvidia-driver-535 - distro non-free recommended
driver : nvidia-driver-535-open - distro non-free
driver : nvidia-driver-535-server-open - distro non-free
driver : nvidia-driver-470-server - distro non-free
driver : xserver-xorg-video-nouveau - distro free builtin
最终选择系统默认,也就是535。
这里不用手动指定版本,sudo ubuntu-drivers autoinstall的默认安装就是recommended的版本。
7.2 安装cuda toolkit
跟随nvidia官方教程的指令,每个CUDA版本都有自己对应的安装指南。
CUDA Toolkit版本的选择,在我看来有2个关键因素:
-
不能高于
nvidia-smi的查询结果,比如我的查出来是CUDA 12.2,那么我的CUDA toolkit不能高于12.2。

-
和pytorch版本相关。比如,服务器重装前用的是11.6,那我现在还得装11.6,不然可能不支持之前配好的conda环境里的pytorch。11.6<12.2,是满足第一条件的。
那么,CUDA toolkit版本需要和driver version匹配吗?
- 要的,CUDA toolkit安装的官方文档提供了查询。
- 但好像只要保证CUDA toolkit版本小于CUDA,就不太会有这个问题。
- 与此同时,官方文档要求的其他一些东西,我没有满足但也没事。比如显卡算力和CUDA版本的匹配(3090卡应该匹配8.6的算力,对应的CUDA版本是11.4)我没有满足,重装前后跑着都没事。比如Ubuntu 22.04其实没有CUDA toolkit 11.6的安装包,我硬装了也没事。
安装步骤:
Step1:在nvidia官方教程的指令查到需要的CUDA toolkit版本,比如我用的CUDA Toolkit 11.6.0CUDA Toolkit 11.6.0。
Step2:按架构实际情况勾选选项。我这里选的是Runtime(local),这个会和后续环境变量配置有关,我提供的是Runtime(local)的环境变量配置方案。
这里可以发现,没有支持Ubuntu 22.04的,我又真的可能需要,怎么办呢?我就装了个适用20.04的,倒也正常跑了。

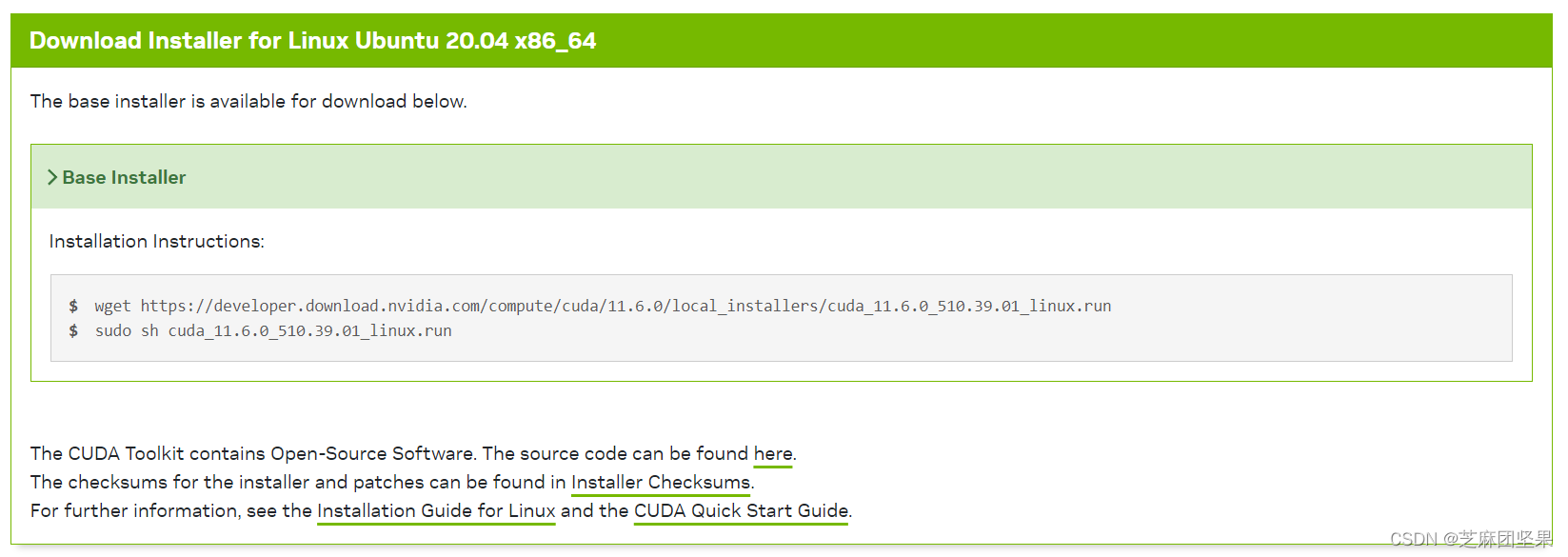
Step3:输入命令,跟着提示一路装。
安装过程注意:
- 安装过程中出现是否安装显卡驱动的提醒,我们已经装过了,别装。如果安装了,会覆盖之前Sec 6.1装的版本,降级。
- 如果你希望存在多个CUDA Toolkit版本,安装过程中提示“是否添加符号链接”,为了不影响现有的CUDA环境,选择否:
Do you want to install a symbolic link at /usr/local/cuda?
Step4:设置环境变量
装好了后还需要修改.bashrc文件,加入环境变量。
# 之前在Sec 4中,通过`su`指令切换到root用户后,路径还在初始user下,也就是`/home/user`。
# 这里要先切换到root用户的目录,才能找到root用户的`.bashrc`文件。
$ cd ~
$ vim .bashrc
加两行:
# 如果前面添加了符号链接symbolic link,如下:
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
# 如果没有添加,则直接定到cuda版本目录,如下:
export PATH=/usr/local/cuda-11.6/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.6/lib64:$LD_LIBRARY_PATH
之后多版本的CUDA Toolkit就是通过.bashrc文件的这两行环境变量来切换。安装过程同上。
如果希望各个用户直接不互相影响,则把环境变量写入各个user的.bashrc
这时候可以查看安装的CUDA Toolkit了。
$ nvcc -V
Output:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Fri_Dec_17_18:16:03_PST_2021
Cuda compilation tools, release 11.6, V11.6.55
Build cuda_11.6.r11.6/compiler.30794723_0
nvcc的输出结果和环境变量的设置是对应的,可以和nvidia-smi的输出不一致,原因如前所述。
如果安装了另一份CUDA Toolkit,比如12.2,并把环境变量改到了cuda-12.2,则nvcc输出为12.2。多版本安装配置参考:【Linux】在一台机器上同时安装多个版本的CUDA(切换CUDA版本)
如果新用户nvcc没有输出,此时不一定是没装CUDA Toolkit,首先检查
.bashrc文件中有没有配好环境变量。
绕路1:默认的apt install
在安装完driver后,如果直接查询nvcc -V,提示可以通过apt install nvidia-cuda-toolkit安装。ChatGPT 4.0也是这么建议的。
这么安装可以吗?可以的,也能用。有什么缺点呢?
- 配环境变量的时候要额外注意。此时安装路径不是
/usr/local,而是/usr/lib。 - 不方便多版本管理。如果要安装别的版本,必定通过官网教程,安装在
/usr/local下。后期维护会需要记两个路径。 - 无法安装想要的版本。比如执行后我的机子上装的是11.5版本。
因此不建议。
绕路2:确定版本
经验来看,只要装了之后能跑,cuda toolkit的版本是否和nvidia driver对应,是否和nvidia-smi的CUDA版本对应,是否匹配Ubuntu版本都不是问题。也有可能因为最终起作用的是pytorch里的cudatoolkit,这里没有细究。
总结一些版本不匹配的情况
在本次安装过程中,有不少不按文档执行的配置。记录如下,供后续查看:
- GeForce 3090 对应nvidia driver推荐版本550,实际安装535
- GeForce 3090 对应算力8.6,对应CUDA 11.4,实际安装CUDA 12.2
- 推荐CUDA Toolkit和CUDA kernel版本对应,即应该装CUDA Toolkit 12.2,实际安装11.6和12.1
- CUDA Toolkit 11.6 只有Ubuntu 20.04系统安装包,实际安装在了Ubuntu 22.04系统上。
8 挂载数据盘
8.1 mount
$ mkdir /data
# 我们的数据盘分区是sdb1
$ mount /dev/sdb1 /data
# 查询数据盘的UUID,并写入设置到/etc/fstab,使得服务器启动自动挂载
$ blkid
$ vim /etc/fstab
8.2 conda环境恢复
挂载后直接可使用原本的annaconda环境(原本就安装在数据盘上)
8.3 新建user并绑定原有用户文件夹
# 新建用户,绑定已有文件夹,设置密码
$ sudo useradd -d /data/user user
$ sudo passwd user
# 修改用户权限,使得可以修改文件夹
$ sudo chown user /data/user
# 修改shell,使得可以执行.bashrc
$ sudo chsh -s /bin/bash user
# 查看设置情况
$ grep user /etc/passwd
9 附带解决的其他问题
之前给师弟开的账号,shell启动时不会自动执行source .bashrc。
解决方法是给复制了一份.profile,里面包含了自动执行命令。















 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









