







淘宝买了一块 Tesla K80,1300多大洋,只因硬件参数挺诱人。我简单说一下使用这张卡的一点挫折,希望对想买的同学有帮助。
- 电源要求额定700w以上,要不然带不动,我最开始用的一台dell工作站,635w额定电源,点不亮!
- 这块卡发热量挺大,且没有风扇,适合放服务器,散热会好些
- 这块卡自带双路,可以直通到 2 台虚拟机中,官方说法是双GPU设计

- 官方资料 https://www.nvidia.com/en-gb/data-center/tesla-k80/
按常规设置新建虚拟机,添加PCI设备,如下图
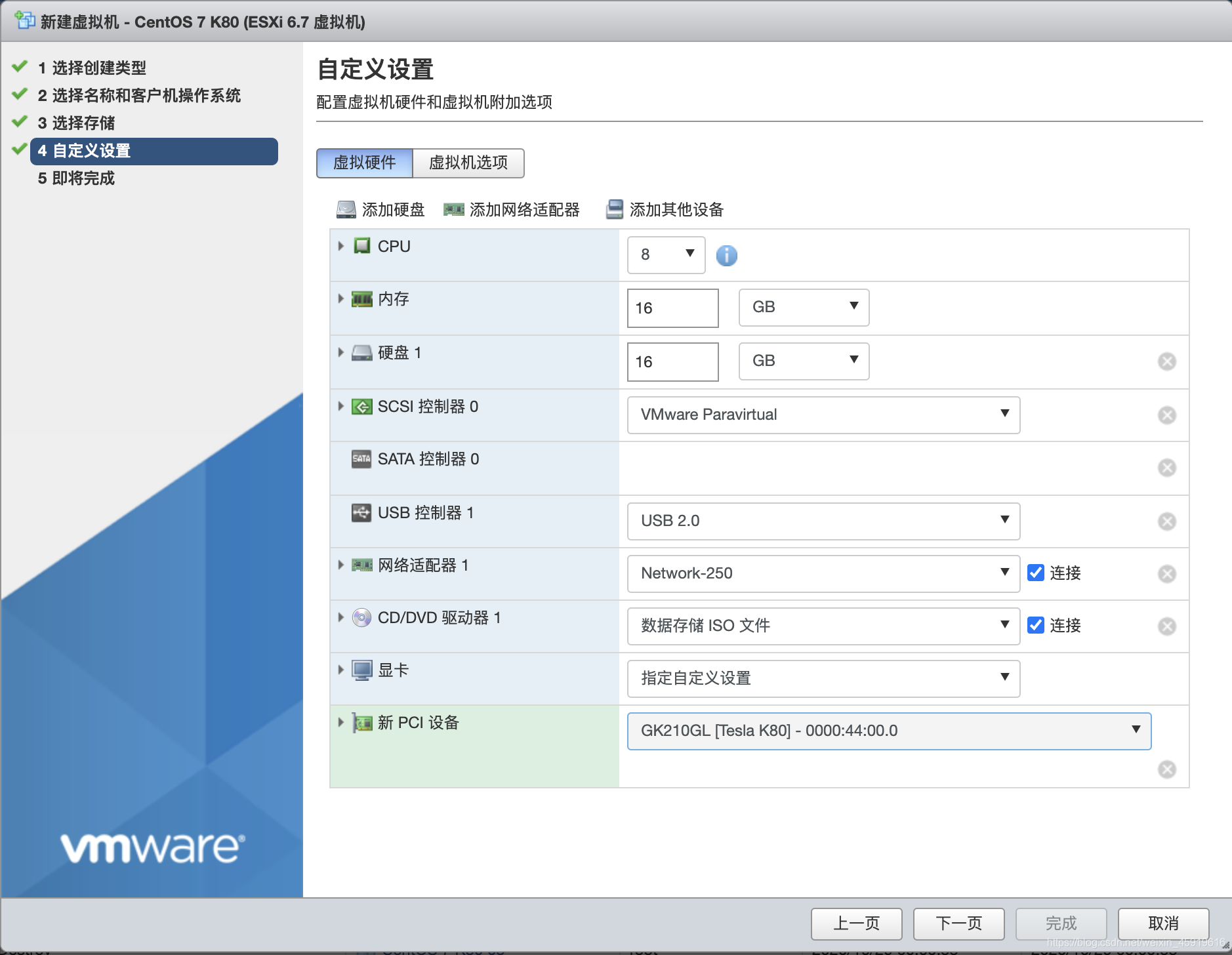
坑1:无法打开虚拟机 CentOS 7 K80 的电源。内存设置无效: 内存预留 (sched.mem.min) 应该等于内存大小 (16384)。 单击此处了解更多详细信息。
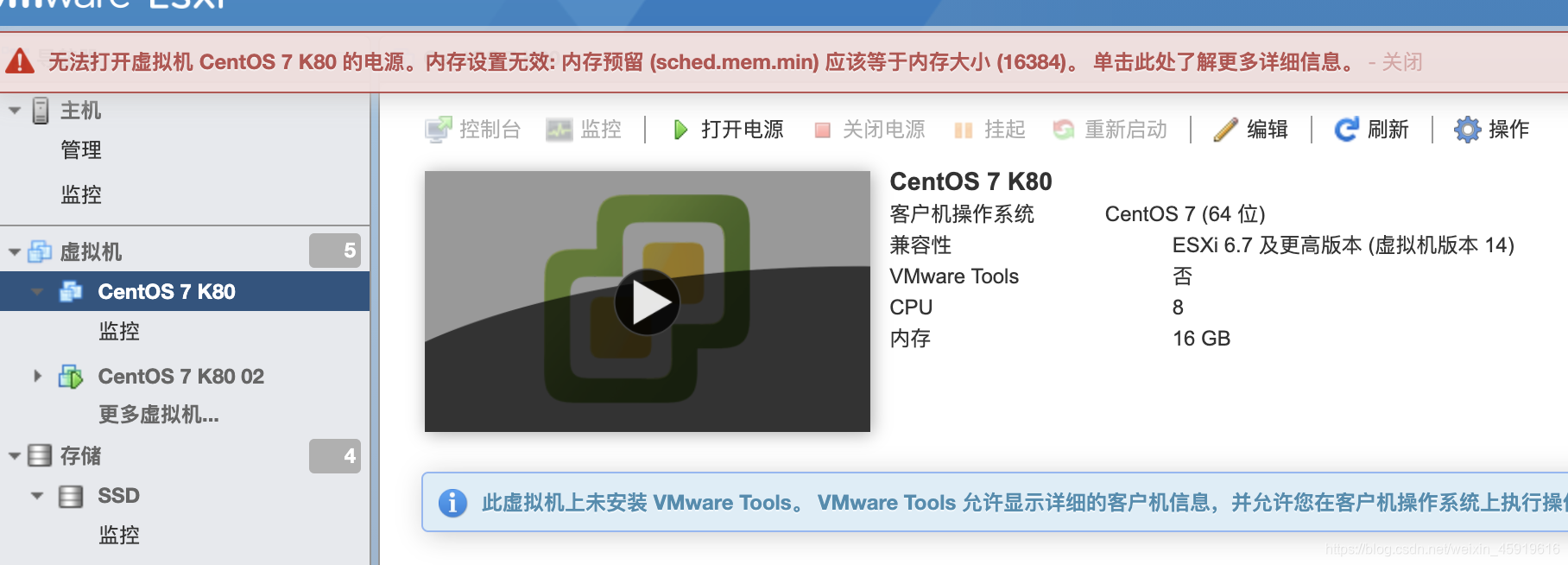
解决方法:打勾☑️ 预留所有客户机内存(全部锁定)即可
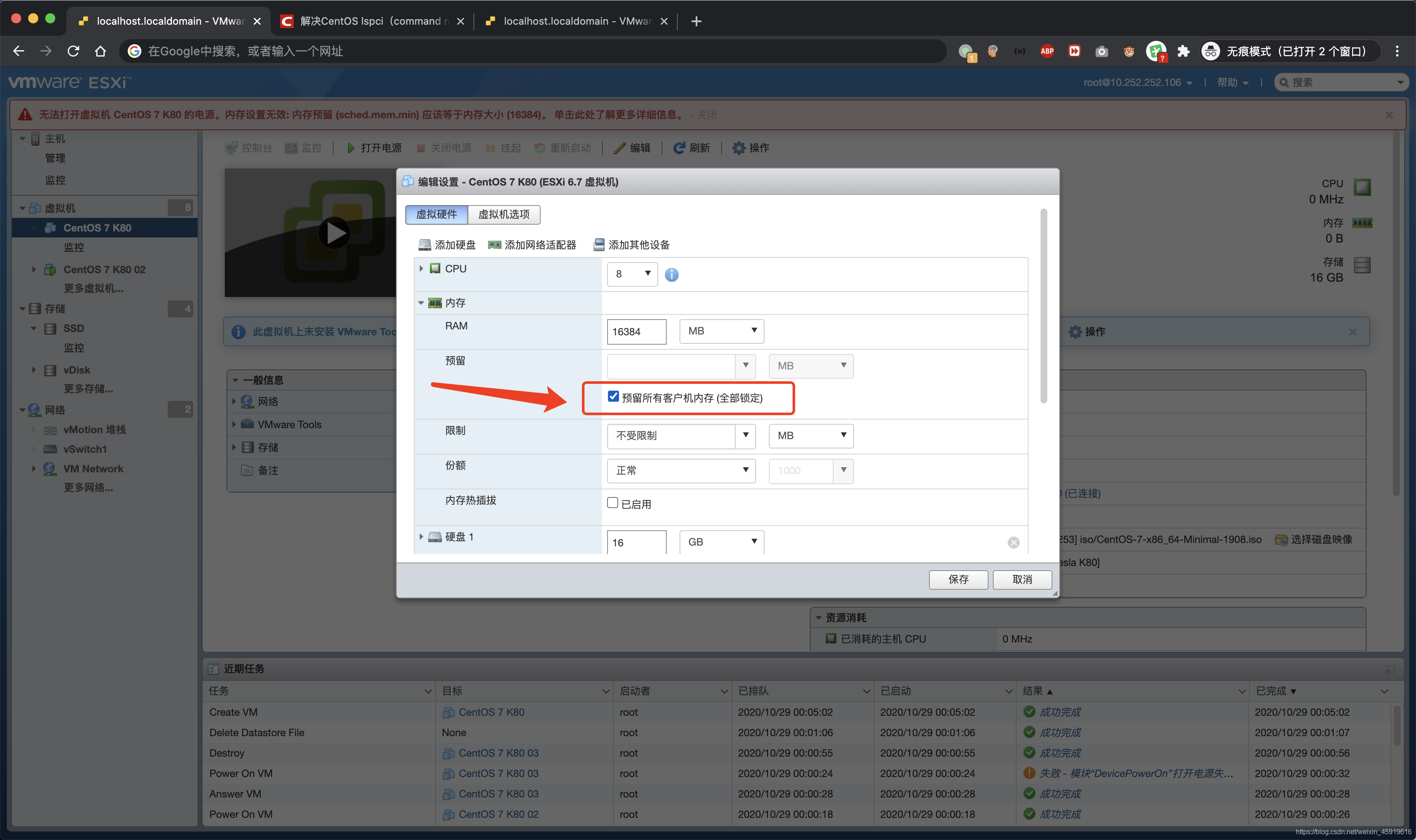
坑2:无法打开虚拟机 CentOS 7 K80 的电源。模块“DevicePowerOn”打开电源失败。 单击此处了解更多详细信息。
这个问题折腾了我一阵子,有几个地方要改:
- 物理机 (Dell R710) BIOS 中启用大于4G的内存映射 (Memory Mapped IO >4GB),这里就不弄图了,搜一下吧
- 编辑虚拟机 - 虚拟机选项 - 引导选项 - 固件 - EFI (默认为 BIOS)
- 编辑虚拟机 - 虚拟机选项 - 高级 - 配置参数 - 编辑配置... -- 点2次左上角的 [添加参数],此时会在列表的尾部会出现 2 条显示为 “单击以编辑键” 条目,如图:
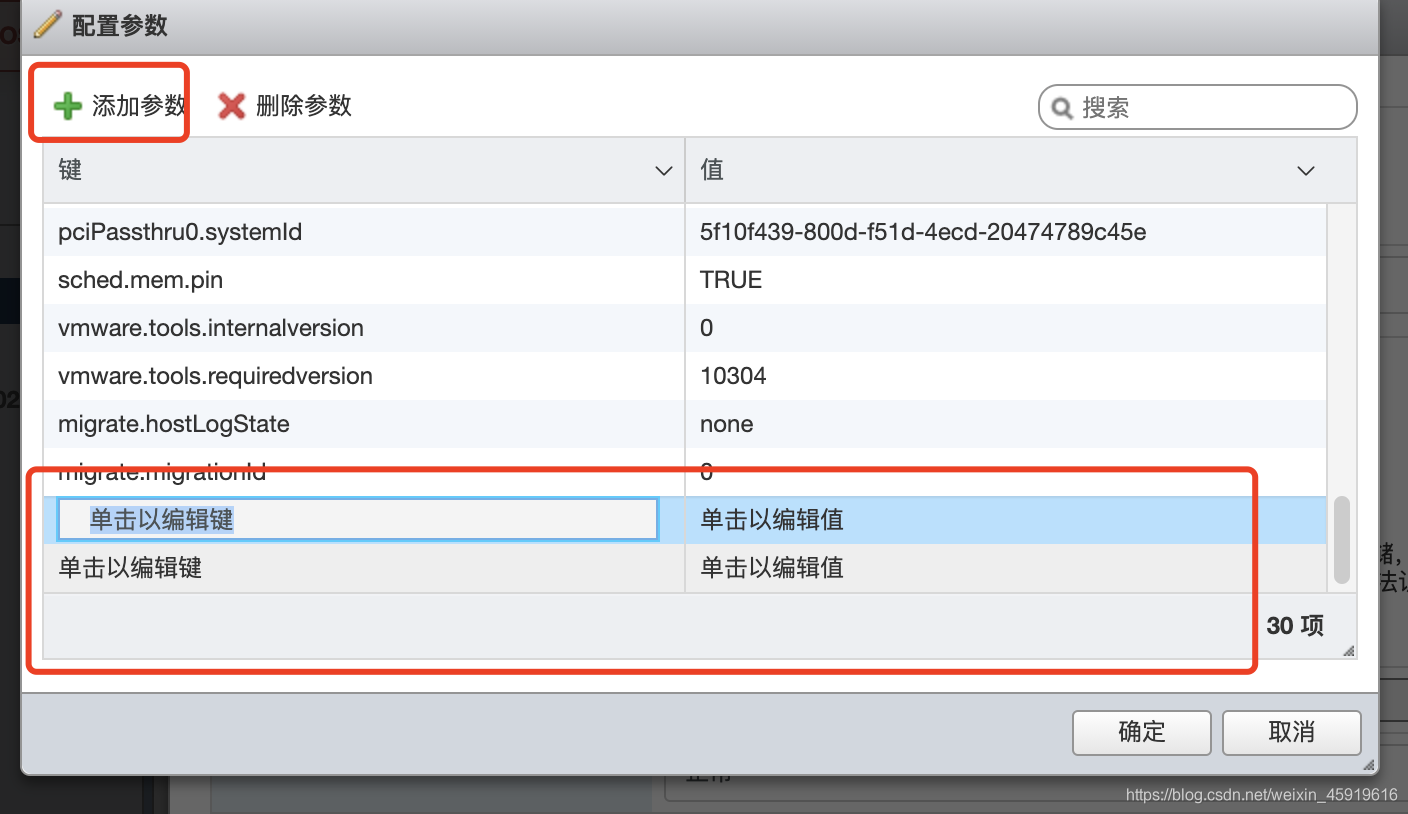
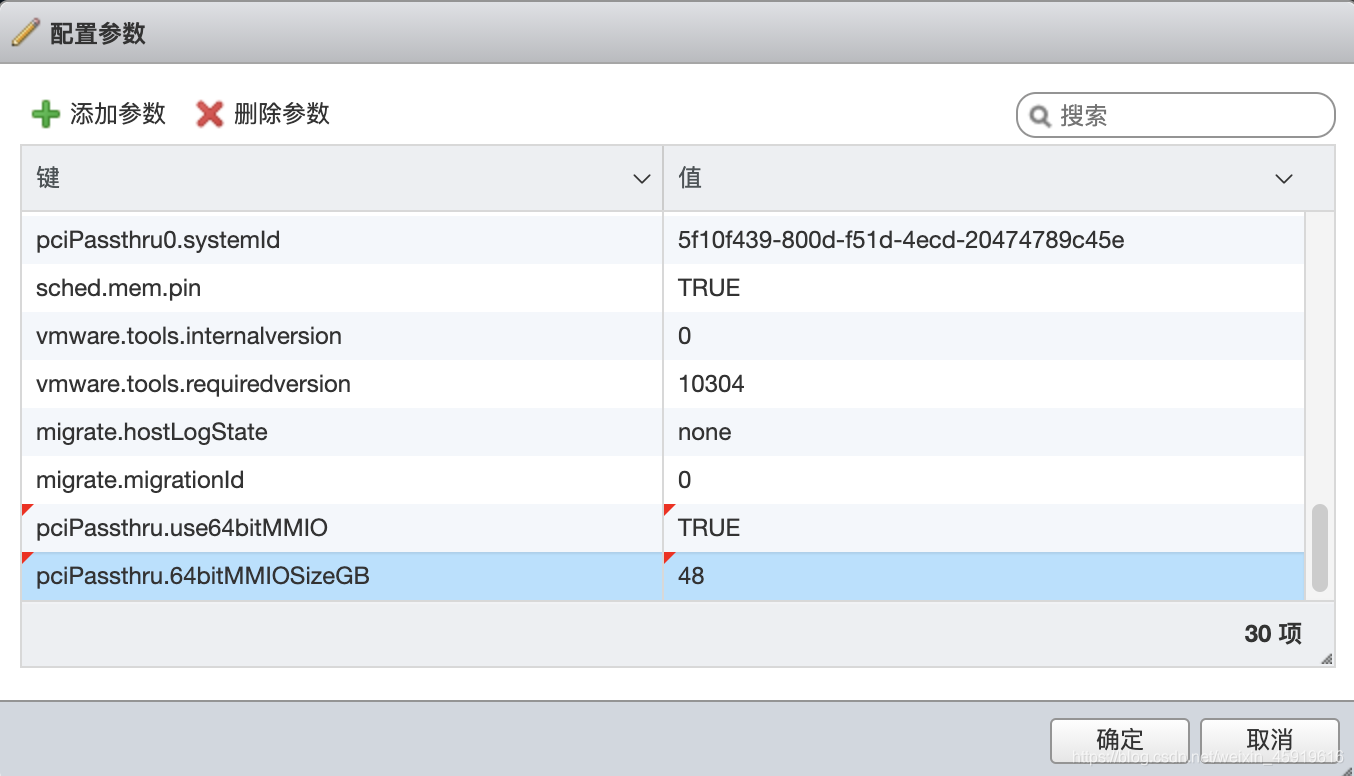
- 配置 pciPassthru.use64bitMMIO 健值为 TRUE
- 配置 pciPassthru.64bitMMIOSizeGB 键值为 48 ,这里的数值需要用GPU内存进行计算,我大致理解为 直通GPU的内存乘以四,我的卡为 双路12G ,映射一路,12*4 = 48,所以这里我写了48,如果理解有误,请大家联系我更正。
- 以上配置参考来源于 https://octo.vmware.com/enable-compute-accelerators-vsphere-6-5-machine-learning-hpc-workloads/
- 配好后像这样
坑3(2021.02.02 遇上):配置文件中缺少 pciPassthru0.id 条目。

虚拟机被删除、重新注册、恢复快照之后遇上此问题。解决办法是:编辑虚拟机 -> 删除直通设备 -> 保存 -> 编辑虚拟机->添加直通设备->保存!删掉后一定要先保存,如果删掉后马上添加,此问题继续存在!
经过以上配置,成功配置Nvidia Tesla K80 的直通
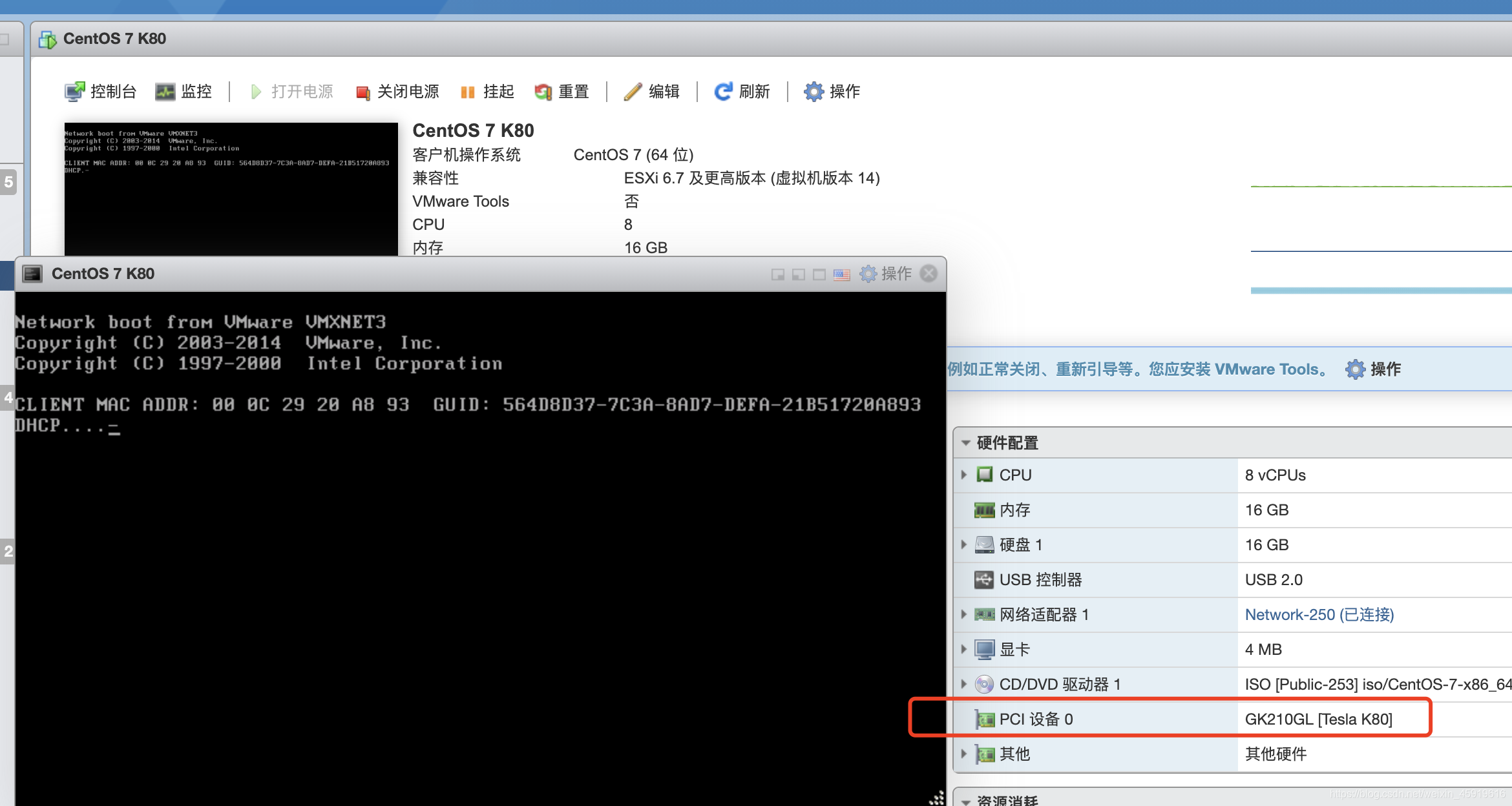
单路 GPU 跑 CUDA 的两个示例程序,结果如下
[root@K80-01 deviceQuery]# ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla K80"
CUDA Driver Version / Runtime Version 10.2 / 10.2
CUDA Capability Major/Minor version number: 3.7
Total amount of global memory: 11441 MBytes (11996954624 bytes)
(13) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA Cores
GPU Max Clock rate: 824 MHz (0.82 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 11 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.2, NumDevs = 1
Result = PASS
[root@K80-01 deviceQuery]# cd ..
[root@K80-01 1_Utilities]# cd bandwidthTest/
[root@K80-01 bandwidthTest]# ls
bandwidthTest.cu Makefile NsightEclipse.xml readme.txt
[root@K80-01 bandwidthTest]# make
/usr/local/cuda/bin/nvcc -ccbin g++ -I../../common/inc -m64 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_75,code=compute_75 -o bandwidthTest.o -c bandwidthTest.cu
/usr/local/cuda/bin/nvcc -ccbin g++ -m64 -gencode arch=compute_30,code=sm_30 -gencode arch=compute_35,code=sm_35 -gencode arch=compute_37,code=sm_37 -gencode arch=compute_50,code=sm_50 -gencode arch=compute_52,code=sm_52 -gencode arch=compute_60,code=sm_60 -gencode arch=compute_61,code=sm_61 -gencode arch=compute_70,code=sm_70 -gencode arch=compute_75,code=sm_75 -gencode arch=compute_75,code=compute_75 -o bandwidthTest bandwidthTest.o
mkdir -p ../../bin/x86_64/linux/release
cp bandwidthTest ../../bin/x86_64/linux/release
[root@K80-01 bandwidthTest]#
[root@K80-01 bandwidthTest]# ./bandwidthTest
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: Tesla K80
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 9.9
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 11.3
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(GB/s)
32000000 157.8
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.


















 5258
5258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











