






论文题目:Rethinking Visual Prompting for Multimodal Large Language Models with External Knowledge
论文链接:https://arxiv.org/abs/2407.04681
一、引言
文章提出了一种新的视觉提示方法,旨在将细粒度的外部知识(来自实例分割和OCR模型的信息)直接嵌入到多模态大型语言模型(MLLMs)中,以增强其对图像中细粒度或局部化视觉元素的理解能力。
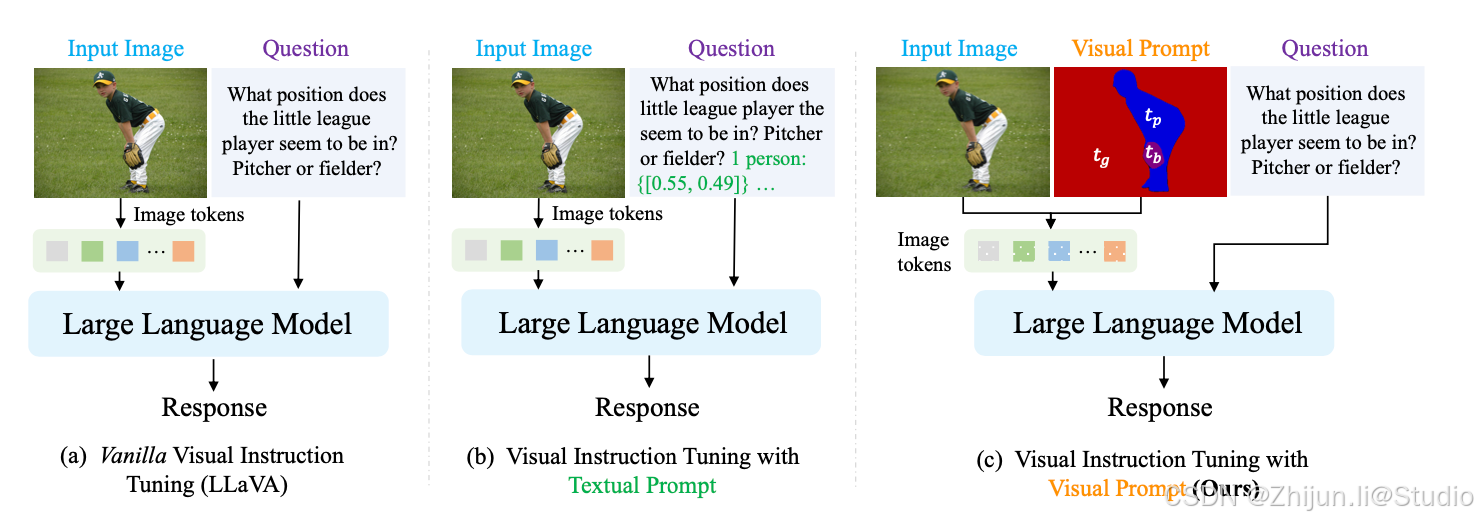
二、方法描述
1.生成辅助视觉提示
输入图像:给定一张输入图像
I
∈
R
3
×
H
×
W
I \in \mathbb{R}^{3 \times H \times W}
I∈R3×H×W
全景分割:使用预训练的全景分割模型
f
seg
(
I
)
f_{\text{seg}}(I)
fseg(I) 生成一组掩码区域及其对应的类别标签
{
M
j
,
C
j
}
j
=
1
N
s
\{M_j, C_j\}_{j=1}^{N_s}
{Mj,Cj}j=1Ns,其中 $ N_s $ 是检测到的掩码区域数量。
OCR检测:使用预训练的OCR模型
f
ocr
(
I
)
f_{\text{ocr}}(I)
focr(I) 生成一组OCR边界框及其对应的文字
{
B
j
,
T
j
}
j
=
1
N
o
\{B_j, T_j\}_{j=1}^{N_o}
{Bj,Tj}j=1No,其中
N
o
N_o
No 是检测到的OCR边界框数量。
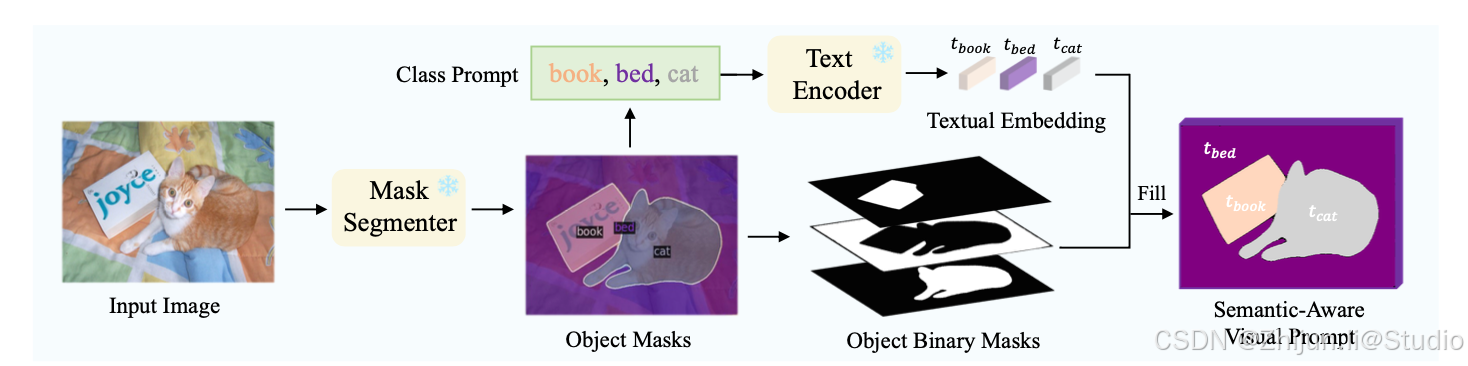
2.生成文本嵌入
对于每个检测到的类别
C
j
C_j
Cj 和OCR文本
T
j
T_j
Tj,使用预训练的文本编码器
f
text
f_{\text{text}}
ftext 生成文本嵌入:
T s = { t 1 , … , t N s } = { f text ( C 1 ) , … , f text ( C N s ) } T_s = \{t_1, \dots, t_{N_s}\} = \{f_{\text{text}}(C_1), \dots, f_{\text{text}}(C_{N_s})\} Ts={t1,…,tNs}={ftext(C1),…,ftext(CNs)}
T o = { t ^ 1 , … , t ^ N o } = { f text ( T 1 ) , … , f text ( T N o ) } T_o = \{\hat{t}_1, \dots, \hat{t}_{N_o}\} = \{f_{\text{text}}(T_1), \dots, f_{\text{text}}(T_{N_o})\} To={t^1,…,t^No}={ftext(T1),…,ftext(TNo)}
其中 t i ∈ R 1 × d t_i \in \mathbb{R}^{1 \times d} ti∈R1×d 和 t ^ i ∈ R 1 × d \hat{t}_i \in \mathbb{R}^{1 \times d} t^i∈R1×d 分别表示第 i i i 个类别和OCR文本的嵌入向量, d d d 是嵌入维度。
3.构建像素级视觉提示
初始化一个零张量
P
∈
R
H
×
W
×
d
P \in \mathbb{R}^{H \times W \times d}
P∈RH×W×d,然后根据检测到的类别和OCR文本填充该张量:
P j , k = { t u if ( j , k ) ∈ M u P j , k otherwise ∀ u ∈ { 1 , … , N s } P_{j,k} = \begin{cases} t_u & \text{if } (j, k) \in M_u \\ P_{j,k} & \text{otherwise} \end{cases} \quad \forall u \in \{1, \dots, N_s\} Pj,k={tuPj,kif (j,k)∈Muotherwise∀u∈{1,…,Ns}
P j , k = P j , k + { t ^ v if ( j , k ) ∈ B v 0 otherwise ∀ v ∈ { 1 , … , N o } P_{j,k} = P_{j,k} + \begin{cases} \hat{t}_v & \text{if } (j, k) \in B_v \\ 0 & \text{otherwise} \end{cases} \quad \forall v \in \{1, \dots, N_o\} Pj,k=Pj,k+{t^v0if (j,k)∈Bvotherwise∀v∈{1,…,No}
注意,对于某些区域,如果分割模型预测的类别置信度较低或OCR模型未能检测到任何文本,将这些区域保留为零值。对于同时被两种模型占用的区域,我们简单地将文本嵌入相加。
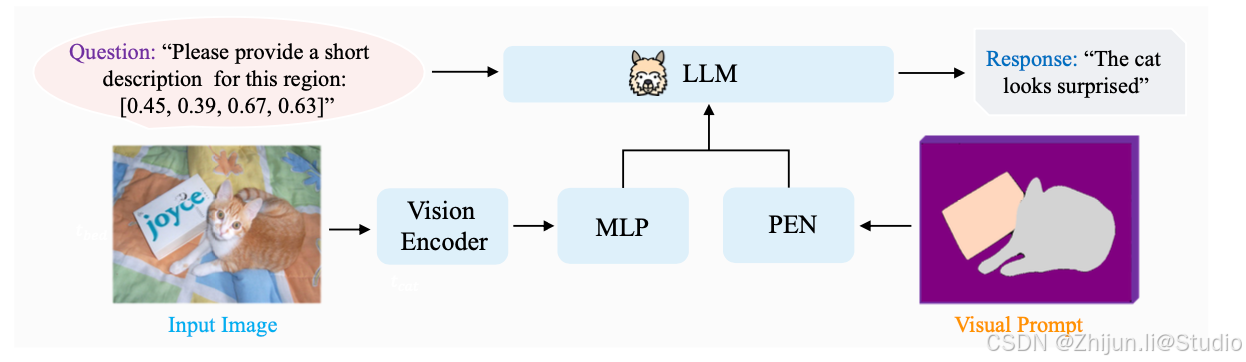
4.视觉提示融合
(1)图像特征提取
使用图像编码器
f
img
f_{\text{img}}
fimg 和MLP投影器
f
MLP
f_{\text{MLP}}
fMLP 生成图像特征
F
v
=
f
MLP
(
f
img
(
I
)
)
F_v = f_{\text{MLP}}(f_{\text{img}}(I))
Fv=fMLP(fimg(I))
其中 F v ∈ R N v × d v F_v \in \mathbb{R}^{N_v \times d_v} Fv∈RNv×dv, N v N_v Nv 和 d v d_v dv 分别表示图像特征的数量和嵌入维度。
(2)提示嵌入网络
使用提示嵌入网络(PEN)
f
PEN
f_{\text{PEN}}
fPEN 处理辅助视觉提示
P
P
P,生成处理后的提示特征
F
p
=
f
PEN
(
P
)
F_p = f_{\text{PEN}}(P)
Fp=fPEN(P)
对于提示嵌入网络,使用三个卷积层,每两个卷积层之间插入一个ReLU激活层,主要用于对齐图像特征和辅助视觉提示的特征空间和空间尺寸。
(3)特征融合
考虑两种方式将图像特征和提示特征进行融合:
- 特征拼接:将图像特征和提示特征拼接在一起,然后通过一个线性层映射回原来的特征维度
F
^
v
=
f
(
Concat
(
F
v
,
F
p
)
)
\hat{F}_v = f(\text{Concat}(F_v, F_p))
F^v=f(Concat(Fv,Fp))
其中 f f f 是一个线性层,用于将嵌入从 R N v × 2 d v \mathbb{R}^{N_v \times 2d_v} RNv×2dv 映射回 R N v × d v \mathbb{R}^{N_v \times d_v} RNv×dv,以保持图像特征的数量不变。 - 特征相加:直接将图像特征和提示特征相加 F ^ v = F v + F p \hat{F}_v = F_v + F_p F^v=Fv+Fp
这两种方式都以像素级的方式操作,有助于模型更好地理解外部知识与原始视觉特征之间的对应关系,从而更准确地识别复杂场景中的细节对象。
三、实验细节
1. 实验设置
视觉编码器:使用SigLIP-384px作为视觉编码器。
语言解码器:使用Phi-2-2.7B和Vicuna-7B作为语言解码器。
多模态投影器:采用两层MLP作为多模态投影器。
OCR和分割模型:使用OpenSeed进行全景分割,PaddleOCRv2进行OCR检测,UAE-Large-V1提取文本嵌入。
训练数据:在LLaVA-Instruct-150K数据集上进行微调,使用LoRA进行低秩适应(LAF),训练1个epoch,学习率为2e-4,批大小为256,使用32块V100 32GB GPU。
LoRA设置:LoRA秩设为128,超参数α设为256。
2. 评估基准
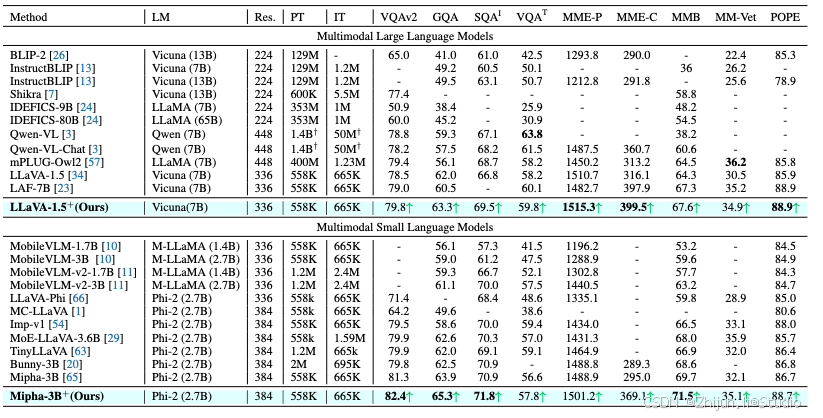
基准测试:使用9个流行的多模态基准测试来评估模型性能,包括VQA-v2、GQA、ScienceQA-IMG、TextVQA、MME感知、MME认知、MM-Bench、MM-Vet和POPE。
3. 对比模型
基线模型:包括Mipha-3B、LLaVA-1.5、InstructBLIP、Shikra-13B、IDEFICS-80/9B、Qwen-VL等。
小规模模型:包括MobileVLM、LLaVA-Phi、MC-LLaVA、Imp-v1、MoE-LLaVA-3.6B、TinyLLaVA、Bunny等。
4. 实验结果
不同视觉提示方式:比较了四种不同的提示方式:标准文本提示、LAF(LoRA增强微调)、特征拼接和特征相加。结果显示,特征相加的效果最好。
不同视觉编码器:比较了CLIP和SigLIP作为视觉编码器的效果,发现SigLIP表现更好。
是否引入OCR信息:引入OCR信息可以显著提升模型在文本相关任务上的性能,如TextVQA和MM-Vet。
不同预训练文本编码器:比较了CLIP和UAE作为文本编码器的效果,发现UAE表现更好。
是否使用对象检测器或分割模型:比较了GroundingDINO和OpenSeed的效果,发现OpenSeed由于其细粒度的掩码区域,表现更好。
是否使用视觉提示进行微调:使用视觉提示进行微调的模型在多个基准测试上显著优于未使用视觉提示的模型。
主实验结果:作者的模型在7个基准测试上超过了现有的70亿和130亿参数的模型,且在某些情况下甚至超过了更大规模的模型。特别地,基于LLaVA-1.5框架,作者的方法在所有基准测试上带来了显著且一致的改进,尤其是在细粒度理解方面表现出色。
四、总结
文章的方法依赖于零样本的OCR以及全景分割模型,如果该模型在某些领域效果一般,则会影响下游任务的效果;但是本文的思路是值得借鉴的,可以特定的微调一个分割/OCR模型来完成下游任务。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











