






Introduction:收纳技术相关的 Data Structure、Algorithm、Design Pattern等总结!
文章目录
Algorithm
复杂度
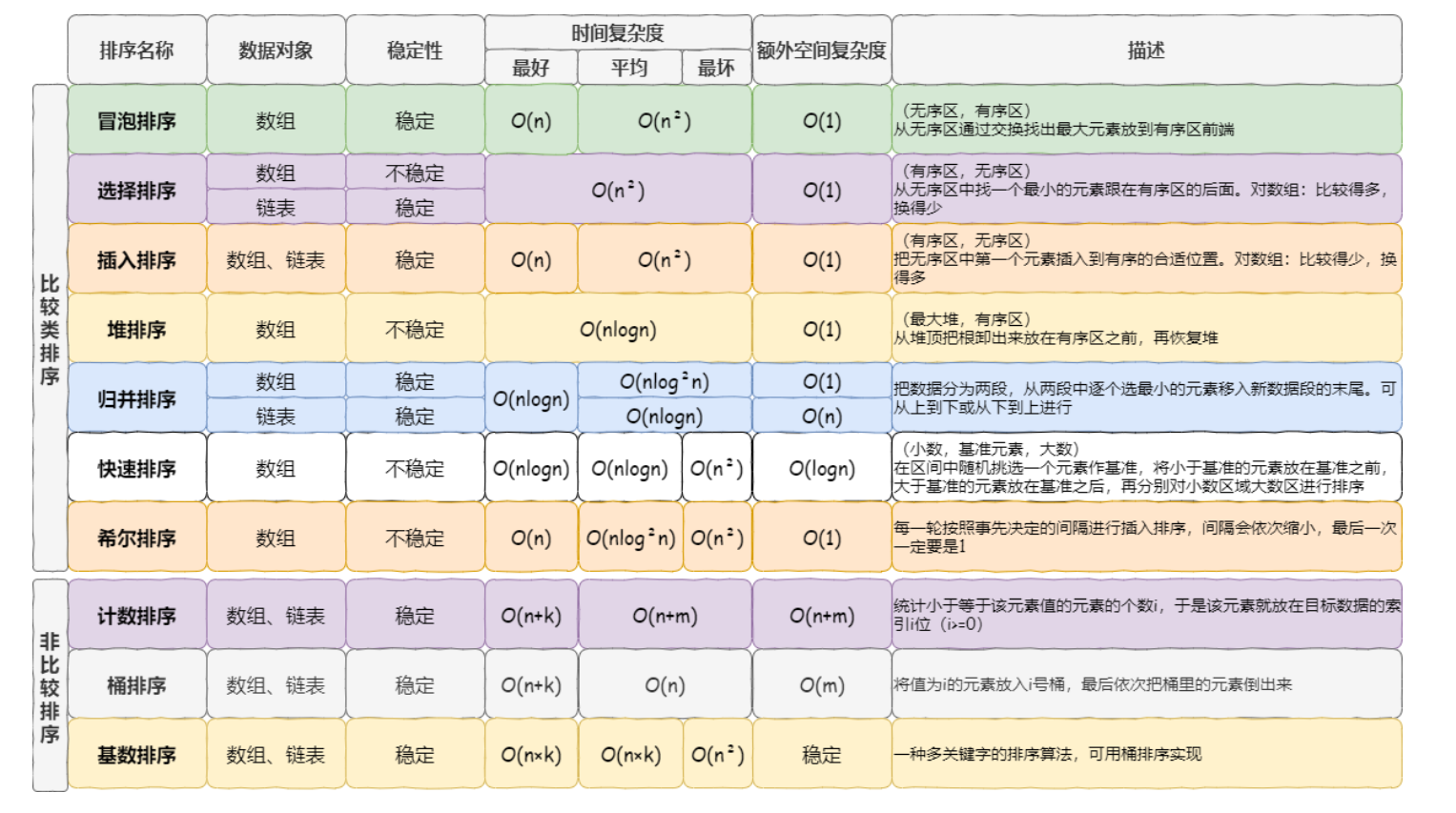
相关概念
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律
- **空间复杂度:**是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数
时间复杂度与时间效率:O(1) < O(log2N) < O(n) < O(N * log2N) < O(N2) < O(N3) < 2N < 3N < N!
一般来说,前四个效率比较高,中间两个差强人意,后三个比较差(只要N比较大,这个算法就动不了了)。
常数阶
int sum = 0,n = 100; //执行一次
sum = (1+n)*n/2; //执行一次
System.out.println (sum); //执行一次
上面算法的运行的次数的函数为 f(n)=3,根据推导大 O 阶的规则 1,我们需要将常数 3 改为 1,则这个算法的时间复杂度为 O(1)。如果 sum=(1+n)*n/2 这条语句再执行 10 遍,因为这与问题大小 n 的值并没有关系,所以这个算法的时间复杂度仍旧是 O(1),我们可以称之为常数阶。
线性阶
线性阶主要要分析循环结构的运行情况,如下所示:
for (int i = 0; i < n; i++) {
//时间复杂度为O(1)的算法
...
}
上面算法循环体中的代码执行了n次,因此时间复杂度为O(n)。
对数阶
接着看如下代码:
int number = 1;
while (number < n) {
number = number * 2;
//时间复杂度为O(1)的算法
...
}
可以看出上面的代码,随着 number 每次乘以 2 后,都会越来越接近 n,当 number 不小于 n 时就会退出循环。假设循环的次数为 X,则由 2^x=n 得出 x=log₂n,因此得出这个算法的时间复杂度为 O(logn)。
平方阶
下面的代码是循环嵌套:
for (int i = 0; i < n; i++) { for(int j = 0; j < n; i++) { //复杂度为O(1)的算法 ... }}
内层循环的时间复杂度在讲到线性阶时就已经得知是O(n),现在经过外层循环n次,那么这段算法的时间复杂度则为O(n²)。
算法思想
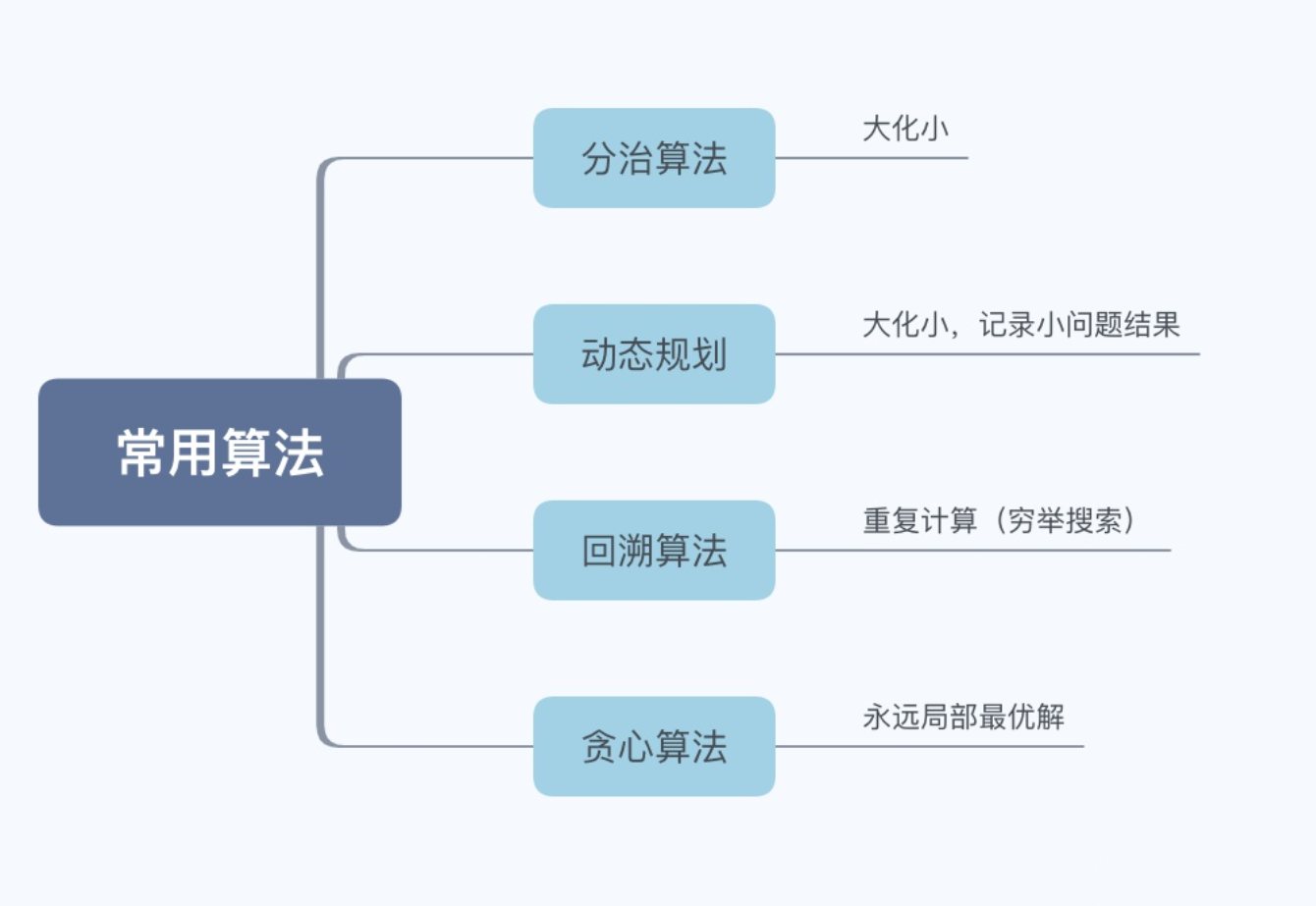
分治(Divide and Conquer)
分治算法思想很大程度上是基于递归的,也比较适合用递归来实现。顾名思义,分而治之。一般分为以下三个过程:
- 分解:将原问题分解成一系列子问题
- 解决:递归求解各个子问题,若子问题足够小,则直接求解
- 合并:将子问题的结果合并成原问题
比较经典的应用就是归并排序 (Merge Sort) 以及快速排序 (Quick Sort) 等。我们来从归并排序理解分治思想,归并排序就是将待排序数组不断二分为规模更小的子问题处理,再将处理好的子问题合并起来。
贪心(Greedy)
贪心算法是动态规划算法的一个子集,可以更高效解决一部分更特殊的问题。实际上,用贪心算法解决问题的思路,并不总能给出最优解。因为它在每一步的决策中,选择目前最优策略,不考虑全局是不是最优。
贪心算法+双指针求解
- 给一个孩子的饼干应当尽量小并且能满足孩子,大的留来满足胃口大的孩子
- 因为胃口小的孩子最容易得到满足,所以优先满足胃口小的孩子需求
- 按照从小到大的顺序使用饼干尝试是否可满足某个孩子
- 当饼干 j >= 胃口 i 时,饼干满足胃口,更新满足的孩子数并移动指针
i++ j++ res++ - 当饼干 j < 胃口 i 时,饼干不能满足胃口,需要换大的
j++
回溯(Backtracking)
使用回溯法进行求解,回溯是一种通过穷举所有可能情况来找到所有解的算法。如果一个候选解最后被发现并不是可行解,回溯算法会舍弃它,并在前面的一些步骤做出一些修改,并重新尝试找到可行解。究其本质,其实就是枚举。
- 如果没有更多的数字需要被输入,说明当前的组合已经产生
- 如果还有数字需要被输入:
- 遍历下一个数字所对应的所有映射的字母
- 将当前的字母添加到组合最后,也就是
str + tmp[r]
动态规划(Dynamic Programming)
虽然动态规划的最终版本 (降维再去维) 大都不是递归,但解题的过程还是离开不递归的。新手可能会觉得动态规划思想接受起来比较难,确实,动态规划求解问题的过程不太符合人类常规的思维方式,我们需要切换成机器思维。使用动态规划思想解题,首先要明确动态规划的三要素。动态规划三要素:
重叠子问题:切换机器思维,自底向上思考最优子结构:子问题的最优解能够推出原问题的优解状态转移方程:dp[n] = dp[n-1] + dp[n-2]
算法模板
递归模板
public void recur(int level, int param) {
// terminator
if (level > MAX_LEVEL) {
// process result
return;
}
// process current logic
process(level, param);
// drill down
recur(level + 1, newParam);
// restore current status
}
List转树形结构
- 方案一:两层循环实现建树
- 方案二:使用递归方法建树
public class TreeNode {
private String id;
private String parentId;
private String name;
private List<TreeNode> children;
/**
* 方案一:两层循环实现建树
*
* @param treeNodes 传入的树节点列表
* @return
*/
public static List<TreeNode> bulid(List<TreeNode> treeNodes) {
List<TreeNode> trees = new ArrayList<>();
for (TreeNode treeNode : treeNodes) {
if ("0".equals(treeNode.getParentId())) {
trees.add(treeNode);
}
for (TreeNode it : treeNodes) {
if (it.getParentId() == treeNode.getId()) {
if (treeNode.getChildren() == null) {
treeNode.setChildren(new ArrayList<TreeNode>());
}
treeNode.getChildren().add(it);
}
}
}
return trees;
}
/**
* 方案二:使用递归方法建树
*
* @param treeNodes
* @return
*/
public static List<TreeNode> buildByRecursive(List<TreeNode> treeNodes) {
List<TreeNode> trees = new ArrayList<>();
for (TreeNode treeNode : treeNodes) {
if ("0".equals(treeNode.getParentId())) {
trees.add(findChildren(treeNode, treeNodes));
}
}
return trees;
}
/**
* 递归查找子节点
*
* @param treeNodes
* @return
*/
private static TreeNode findChildren(TreeNode treeNode, List<TreeNode> treeNodes) {
for (TreeNode it : treeNodes) {
if (treeNode.getId().equals(it.getParentId())) {
if (treeNode.getChildren() == null) {
treeNode.setChildren(new ArrayList<>());
}
treeNode.getChildren().add(findChildren(it, treeNodes));
}
}
return treeNode;
}
}
回溯模板
DFS模板
BFS模板
查找算法
顺序查找
就是一个一个依次查找。
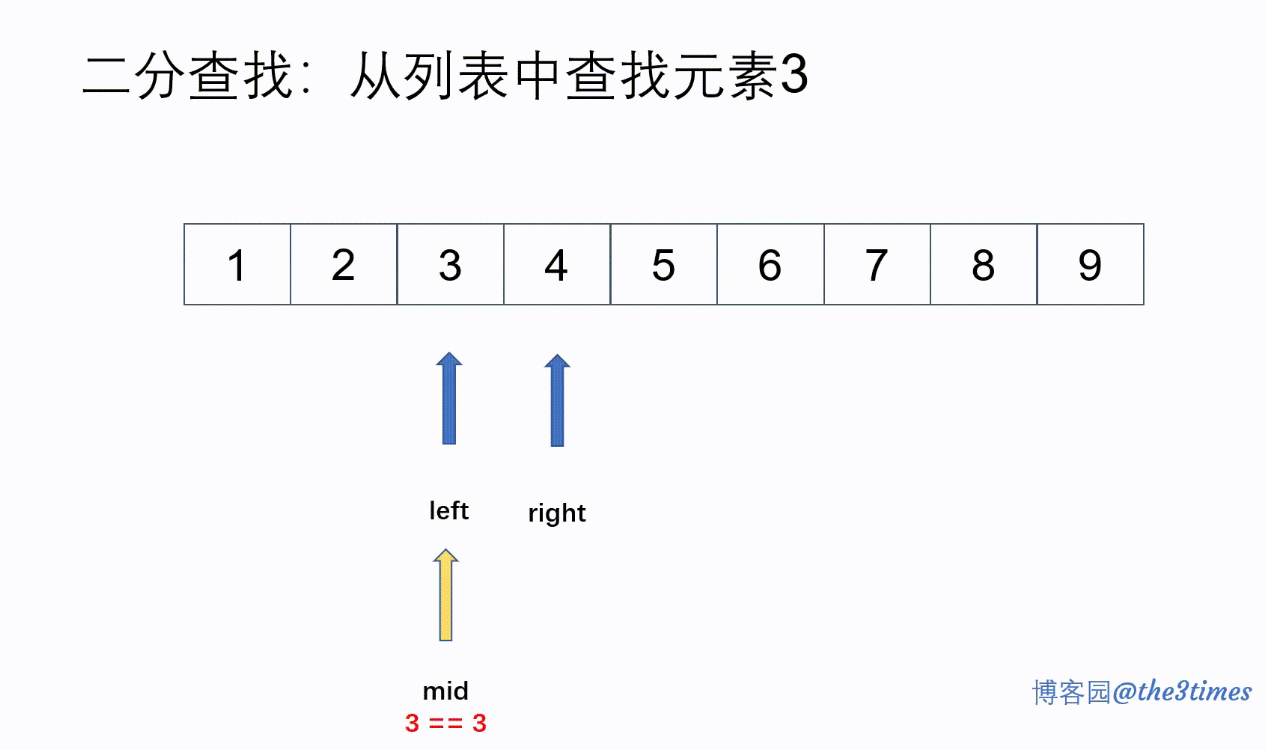
二分查找
二分查找又叫折半查找,从有序列表的初始候选区li[0:n]开始,通过对待查找的值与候选区中间值的比较,可以使候选区减少一半。如果待查值小于候选区中间值,则只需比较中间值左边的元素,减半查找范围。依次类推依次减半。
- 二分查找的前提:列表有序
- 二分查找的有点:查找速度快
- 二分查找的时间复杂度为:O(logn)
JAVA代码如下:
/**
* 执行递归二分查找,返回第一次出现该值的位置
*
* @param array 已排序的数组
* @param start 开始位置,如:0
* @param end 结束位置,如:array.length-1
* @param findValue 需要找的值
* @return 值在数组中的位置,从0开始。找不到返回-1
*/
public static int searchRecursive(int[] array, int start, int end, int findValue) {
// 如果数组为空,直接返回-1,即查找失败
if (array == null) {
return -1;
}
if (start <= end) {
// 中间位置
int middle = (start + end) / 1;
// 中值
int middleValue = array[middle];
if (findValue == middleValue) {
// 等于中值直接返回
return middle;
} else if (findValue < middleValue) {
// 小于中值时在中值前面找
return searchRecursive(array, start, middle - 1, findValue);
} else {
// 大于中值在中值后面找
return searchRecursive(array, middle + 1, end, findValue);
}
} else {
// 返回-1,即查找失败
return -1;
}
}
/**
* 循环二分查找,返回第一次出现该值的位置
*
* @param array 已排序的数组
* @param findValue 需要找的值
* @return 值在数组中的位置,从0开始。找不到返回-1
*/
public static int searchLoop(int[] array, int findValue) {
// 如果数组为空,直接返回-1,即查找失败
if (array == null) {
return -1;
}
// 起始位置
int start = 0;
// 结束位置
int end = array.length - 1;
while (start <= end) {
// 中间位置
int middle = (start + end) / 2;
// 中值
int middleValue = array[middle];
if (findValue == middleValue) {
// 等于中值直接返回
return middle;
} else if (findValue < middleValue) {
// 小于中值时在中值前面找
end = middle - 1;
} else {
// 大于中值在中值后面找
start = middle + 1;
}
}
// 返回-1,即查找失败
return -1;
}
插值查找
插值查找算法类似于二分查找,不同的是插值查找每次从自适应mid处开始查找。将折半查找中的求mid索引的公式,low表示左边索引left,high表示右边索引right,key就是前面我们讲的findVal。

注意事项
- 对于数据量较大,关键字分布比较均匀的查找表来说,采用插值查找,速度较快
- 关键字分布不均匀的情况下,该方法不一定比折半查找要好
/**
* 插值查找
*
* @param arr 已排序的数组
* @param left 开始位置,如:0
* @param right 结束位置,如:array.length-1
* @param findValue
* @return
*/
public static int insertValueSearch(int[] arr, int left, int right, int findValue) {
//注意:findVal < arr[0] 和 findVal > arr[arr.length - 1] 必须需要, 否则我们得到的 mid 可能越界
if (left > right || findValue < arr[0] || findValue > arr[arr.length - 1]) {
return -1;
}
// 求出mid, 自适应
int mid = left + (right - left) * (findValue - arr[left]) / (arr[right] - arr[left]);
int midValue = arr[mid];
if (findValue > midValue) {
// 向右递归
return insertValueSearch(arr, mid + 1, right, findValue);
} else if (findValue < midValue) {
// 向左递归
return insertValueSearch(arr, left, mid - 1, findValue);
} else {
return mid;
}
}
斐波那契查找
黄金分割点是指把一条线段分割为两部分,使其中一部分与全长之比等于另一部分与这部分之比。取其前三位数字的近似值是0.618。由于按此比例设计的造型十分美丽,因此称为黄金分割,也称为中外比。这是一个神奇的数字,会带来意向不大的效果。斐波那契数列{1, 1,2, 3, 5, 8, 13,21, 34, 55 }发现斐波那契数列的两个相邻数的比例,无限接近黄金分割值0.618。
斐波那契查找原理与前两种相似,仅仅改变了中间结点(mid)的位置,mid不再是中间或插值得到,而是位于黄金分割点附近,即mid=low+F(k-1)-1(F代表斐波那契数列),如下图所示:

JAVA代码如下:
/**
* 因为后面我们mid=low+F(k-1)-1,需要使用到斐波那契数列,因此我们需要先获取到一个斐波那契数列
* <p>
* 非递归方法得到一个斐波那契数列
*
* @return
*/
private static int[] getFibonacci() {
int[] fibonacci = new int[20];
fibonacci[0] = 1;
fibonacci[1] = 1;
for (int i = 2; i < fibonacci.length; i++) {
fibonacci[i] = fibonacci[i - 1] + fibonacci[i - 2];
}
return fibonacci;
}
/**
* 编写斐波那契查找算法
* <p>
* 使用非递归的方式编写算法
*
* @param arr 数组
* @param findValue 我们需要查找的关键码(值)
* @return 返回对应的下标,如果没有-1
*/
public static int fibonacciSearch(int[] arr, int findValue) {
int low = 0;
int high = arr.length - 1;
int k = 0;// 表示斐波那契分割数值的下标
int mid = 0;// 存放mid值
int[] fibonacci = getFibonacci();// 获取到斐波那契数列
// 获取到斐波那契分割数值的下标
while (high > fibonacci[k] - 1) {
k++;
}
// 因为 fibonacci[k] 值可能大于 arr 的 长度,因此我们需要使用Arrays类,构造一个新的数组
int[] temp = Arrays.copyOf(arr, fibonacci[k]);
// 实际上需求使用arr数组最后的数填充 temp
for (int i = high + 1; i < temp.length; i++) {
temp[i] = arr[high];
}
// 使用while来循环处理,找到我们的数 findValue
while (low <= high) {
mid = low + fibonacci[k] - 1;
if (findValue < temp[mid]) {
high = mid - 1;
k--;
} else if (findValue > temp[mid]) {
low = mid + 1;
k++;
} else {
return Math.min(mid, high);
}
}
return -1;
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











