






阅读须知
本文主要意义是为了方便对CNN有个最直观的理解,知道这个玩意到底是干嘛的。文章本体是UP自己自学深度学习这块的时候做的笔记,内容均为网上收录。发在这里的原因是因为,也许有很多像UP一样不理解了就完全学不了的人存在,为了这些人能粗略地了解一下CNN于是发了出来。网上很多教程可以说是非常严谨了,要公式有公式要出典有出典,但就是看不懂...所以本文会涉及到很多UP自己的理解,如果有一定的错误还望指出。
以下正文
本文主要参考https://zhuanlan.zhihu.com/p/27908027
CNN的作用为特征提取器,用于提取给定数据内的某个特征。
以识别图片的方式理解CNN,比如,创建一个CNN识别一张图片是X还是O的模型。我们最开始输入了

一个栗子
作为输入数据,让程序去学习X的特征。于是第二次再输入该图的时候,机器知道了,这个就是X。
但是第三次,我们输入的不是这张图,而是

四个栗子
机器此时就无法再识别出该图到底是不是X了。因为机器只学过第一张图,所以模型无法整理出通用特征。用机器学习的话来说就模型复杂度低,学习样本不够,这种时候被称为欠拟合。(原文是欠拟合,但也有说过拟合的)
为了解决这个问题,只用第一张图作为学习样本很明显是不太够的。毕竟人类也不一定一次就总结出某个第一次见到的事物的特征。比如我到现在都没搞清楚一些日语词的用法,只能通过每次听到这个词在什么语境下使用,一点点自己总结这个词到底是什么意思。机器需要做相同的事情。
这里提到一点,对于数码图片,在人眼里是各种波长的光组成的一张图片,但是在机器层面,是下图这样的

不一样的X
当然,这只是一个例子,图中-1代表黑色,1代表白色,用这种1与-1的行列来表述一张黑白图片。
当机器想用如上两张图来总结规律时,他们是实际在做的事情是,找到这两张图里通用的特征。比如这两张图虽然对应的行列结构不一样,但是存在一致的地方,比如

我们一样耶^^
这些被框框框住的区域仍然是相同的,因此依然可以用来辅助机器识别图片到底是不是X。
(小想法,从某种层面上来说,机器学习是赋予机器一种模糊判断的能力。从一个到一类的转变。)
但是上图框框有一个是3x3,两个是2x2,尽可能保持特征为同样行列的矩阵的话会更好处理。于是,从上图这俩例子来说,机器提炼出了如下的三种特征。从行列的角度来说如下

随机挑选几名幸运特征
这种被提取出来的特征被称为卷积核,一般是3x3或者5x5大小。
接下来说一说机器学习里一直说来说去的卷积到底是什么意思。
当机器提取了如上的三种特征之后,他要做的下一步事情,是拿这三个特征行列,去和图片里的每一处3x3乘一遍,
在这里三个特征行列我们先称为特征行列1,特征行列2和特征行列3.
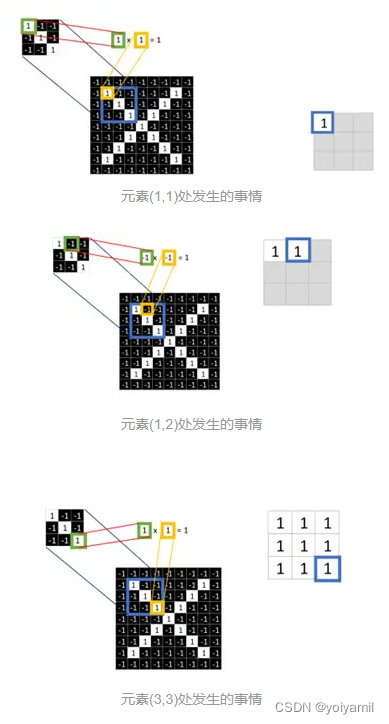
最终得到另一个3x3行列,

当当~
再将这个3x3行列的9个元素的平均值写在最中间的位置。

这个位置对应的数字
这意味着,在蓝框框中心的这个位置的3X3行列,每一个元素与特征行列1的特征值分别相乘之后,平均值为1.
这里只是当蓝框框在这个位置时候和特征行列1相乘的一个例子,我们在之前也说了,需要拿特征行列与该图片中的每一处3x3都要乘一遍,于是我们要把蓝框框再挪一挪。对了,这个蓝框框称为窗口。
蓝框框最开始应该在这个位置。

把整个图片扫描一遍
当算完这个蓝框框之后,会继续向右移动。如果我们设置步长stride=1的话,则会变成

右走一步(注意,这里可以有重叠区域,比如第二列)
当移动到最右边之后,我们得去第二行,于是向下移动一个步长stride=1,则会变成

向下走一步
当我们用这种方式把整个图上所有的地方都计算了一遍之后,这张图变成了这样

注意这里少了2行2列,为什么呢?
这张图称为特征图feature map
注意哈,这张图不再是最开始黑白图的那个9x9行列了,而变成了7x7。这是很容易理解的,毕竟原本黑白那张图的(1,1)元素为中心的蓝框框是不存在的。
同样的,这张图只是对特征行列1进行了计算,还有特征行列2和3,所以我们还要进行两次同样的计算,并最终得到

是不是看着还挺炫酷的
这么三个特征行列。至此,特征图计算完毕了。
接下来来介绍另外两个概念。
当我们获得如上三张特征图之后,还是觉得数据量太大,计算机处理起来太麻烦。那能不能再简化一点的。
可以。
这里有一个新的方法,使用relu函数。这个函数的功能是保留行列中大于等于零的数字,且将小于零的数直接改写为0。(因为在特征图里,数字越接近1则表示相关性越高,越接近-1则相关性越低,故为了方便计算,将小于0的略去)

这里对应关系比较简单,我就只放一张图在这里了
最终将左图完全改写成如下形式

其实没啥区别,就是小于0的因为关系不大,就让他们都等于0得了
这一层叫做非线性激活层,relu函数是一种常用的非线性激活函数
现在我们这张图上小于0的元素因为相关性太低都被清理掉了。数据一下少了很多。那能不能再降低一下数据量呢?
还是可以的。
比方说,我们依然可以用之前那种窗口的方式,然后选取窗口内的最大值,填到一个新的行列里去

红框框区域内发生的事情
在红框框区域中,最大值是1.00,于是便将这个1.00填入新行列的(1,1)位置。然后,窗口红框框一般不会重复选择数据,因此下一个位置选这里

第二个红框框区域发生的事情
当红框框框在最右边单独的列时,我们将被框住的空白视为0即可。

这种填补的行为被称为填充(padding),有很多种方法和模式
因此在这个位置输出的最大值应为0.33。当对整张图都进行了一遍取最大值之后,这张图变成了这样。

9X9到4X4了,芜湖
这种处理方法,被称为池化(pooling)
相应的,这一层被称为池化层,这种取最大值的方法叫做最大池化,还有一种取平均值的方法叫做平均池化。池化这种处理方式的特征为,一定程度保留数据特征的前提下,减少参数和计算量(数据的长宽),通道数不变。

这是一个长224,宽224,64个通道的数据组的例子
------------------------------------------------------------------------------------------------------------
注意,接下来的部分为全连接层,这一部分我把网上快翻遍了都没找到几个好理解的。因此只能硬着头皮理解了一番之后整理了一下自己的理解。可能有错,注意甄别。
------------------------------------------------------------------------------------------------------------
当数据处理到这里时,可以继续重复之前的这几种层再来一遍,

层层套娃
或者进入另一种处理方式

光翼展开(bushi
把上一步得到池化之后的三个行列一维展开,就是按照从左往右从上往下的方式改写成一列,这一列将作为全连接层的输入层,然后把输入层的所有元素都与隐层相连

这里太复杂了,我就画个示意图在这里,要是有不懂得我也可以把图片做个完整版出来
而隐层,则是人为放了一个具有n个元素(或者说神经元)的一列行列。里面的每个元素可以视作一个多项式,每个多项式都不同,这样才可以更好地拟合数据分布。[1](如果隐层神经元都一样的话,那输入层的数字输入哪个神经元都没区别)隐层未必只有一层,可以有很多层,但是太多太少都不好。这块要依靠经验来。
至于输出层,需要分成几类,就设置输出层有几个神经元就行。比如说分类X或者O,就是两类,所以就放两个神经元。
所以整个流程就是,输入层的每个数字都分别与隐层的每个神经元算一算,得到各自的结果,然后把这个结果稍加处理之后分别再次发到输出层的两个神经元上,最终输出层的两个神经元各自会得到一个数字,把这两个数字用softmax函数处理了之后,最终会分别获得两种分类的概率。比方说40%概率是X,60%概率是O这样。(softmax函数的作用是使预测结果值为大于等于0的基础上,再使预测结果概率之和为1[2])
输入层是输入数据的特征,隐藏层是特征是否满足某n个条件(可视为),输出层则是与该结果的符合程度。
至此,CNN就先告一段落。
[1] https://zhuanlan.zhihu.com/p/33841176
[2]https://blog.csdn.net/lz_peter/article/details/84574716 作者:Setsunal_ https://www.bilibili.com/read/cv20632670 出处:bilibili















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









