






OpenCompass 简介
上海人工智能实验室科学家团队于2024.01.30正式发布了大模型开源开放评测体系 “司南” (OpenCompass2.0),用于为大语言模型、多模态模型等提供一站式评测服务。OpenCompass 平台广泛支持超过 100 种HuggingFace和 API 模型,融合了 100 多个数据集,包含约 40 万个问题,用以从八个维度评估模型。其高效的分布式评估系统能够快速且全面地评估十亿级规模的模型。该平台适应多种评估方法,包括零样本、少样本和思维链评估,并且具有高度可扩展的模块化设计,便于轻松添加新模型、数据集或自定义任务策略。此外,OpenCompass包括强大的实验管理和报告工具,用于详细跟踪和实时结果展示。工作流程如下图所示:
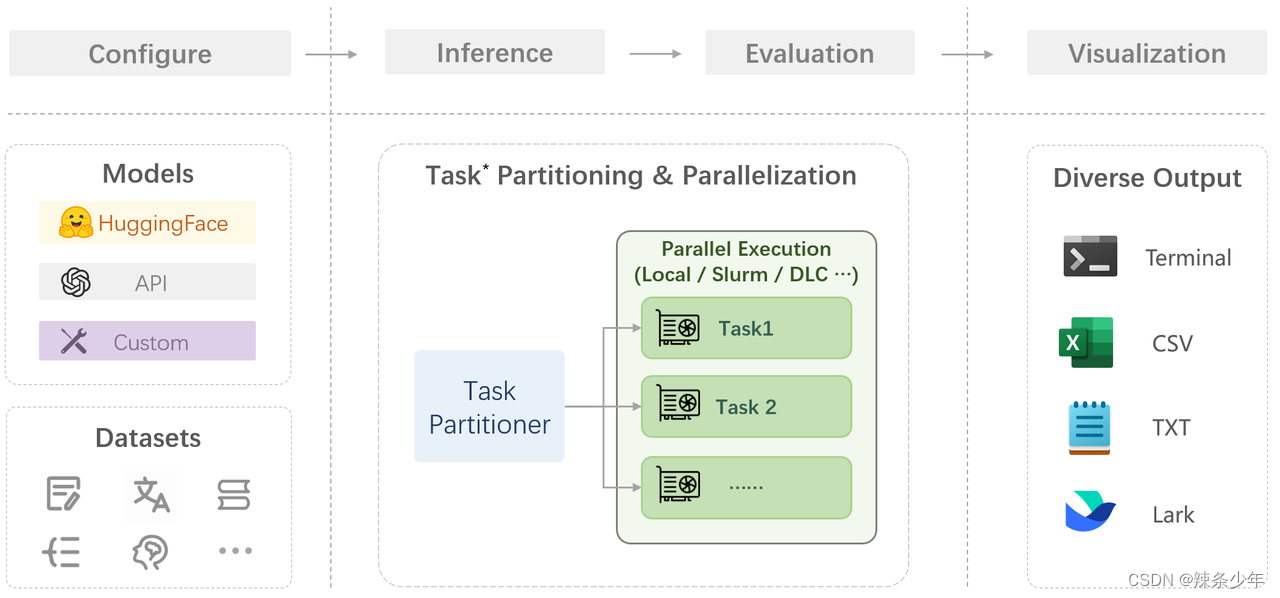
在 OpenCompass 中评估一个模型通常包括以下几个阶段:配置 -> 推理 -> 评估 -> 可视化。
配置:这是整个工作流的起点。您需要配置整个评估过程,选择要评估的模型和数据集。此外,还可以选择评估策略、计算后端等,并定义显示结果的方式。
推理与评估:在这个阶段,OpenCompass 将会开始对模型和数据集进行并行推理和评估。推理阶段主要是让模型从数据集产生输出,而评估阶段则是衡量这些输出与标准答案的匹配程度。这两个过程会被拆分为多个同时运行的“任务”以提高效率,但请注意,如果计算资源有限,这种策略可能会使评测变得更慢。
可视化:评估完成后,OpenCompass 将结果整理成易读的表格,并将其保存为 CSV 和 TXT 文件。
下面演示书生浦语InternLM2-Chat-1.8B在 C-Eval 基准任务上的性能评估。
配置环境
创建虚拟环境并激活
conda create -n opencompass python=3.10
conda activate opencompass
从源码安装opencompass
git clone -b 0.2.4 https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
安装依赖包
pip install -r requirements.txt
pip install protobuf
准备C-Eval数据
下载并解压评测数据集C-Eval到 /root/opencompass/data/ 处
查看支持的数据集和模型
列出所有跟 InternLM 及 C-Eval 相关的配置
python tools/list_configs.py internlm ceval
通过以下命令评测 InternLM2-Chat-1.8B 模型在 C-Eval 数据集上的性能。由于 OpenCompass 默认并行启动评估过程,我们可以在第一次运行时以 --debug 模式启动评估,并检查是否存在问题。在 --debug 模式下,任务将按顺序执行,并实时打印输出。
python run.py --datasets ceval_gen --hf-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-path /share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 1024 --max-out-len 16 --batch-size 2 --num-gpus 1 --debug
评测完成后,将会看到:
















 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









