






课程链接:XTuner 大模型单卡低成本微调实战_哔哩哔哩_bilibili
本次课主要学习的是大模型微调的基础知识以及微调工具框架XTuner的基本信息。
微调(Finetune)包含两种常用的范式,分别是增量预训练微调和指令跟随微调。增量预训练使用文章、书籍、代码等训练数据,旨在让基座模型学会某个垂类领域的新知识,微调的结果是所谓的“垂类基座模型”。指令跟随的训练数据则是高质量的对话(问答)数据,旨在让模型学会根据人类的指令进行回答和对话。

下面针对指令跟随微调,解释一下训练数据的基本构成和使用方式。 原始的对话数据需要改写为标准格式,并添加对话模板,便于LLM区分System提示、用户输入和模型输出这些不同的字段。

不同的模型会有不同的对话模板格式,但是本质上都是对System提示、用户输入和模型输出做出区分。
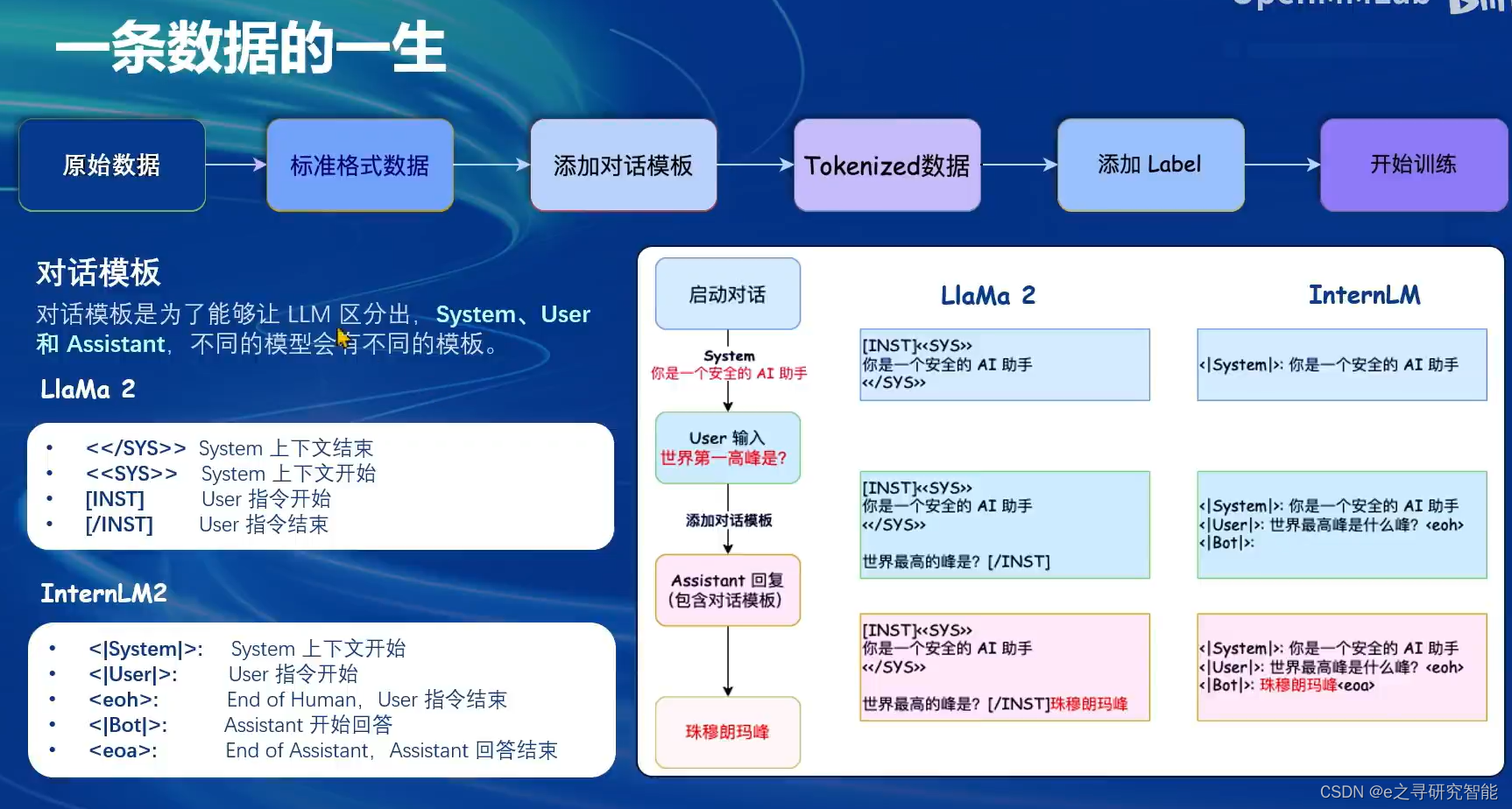
那么,为了评估模型的效果, 需要对比模型的输出和预先准备好的label。

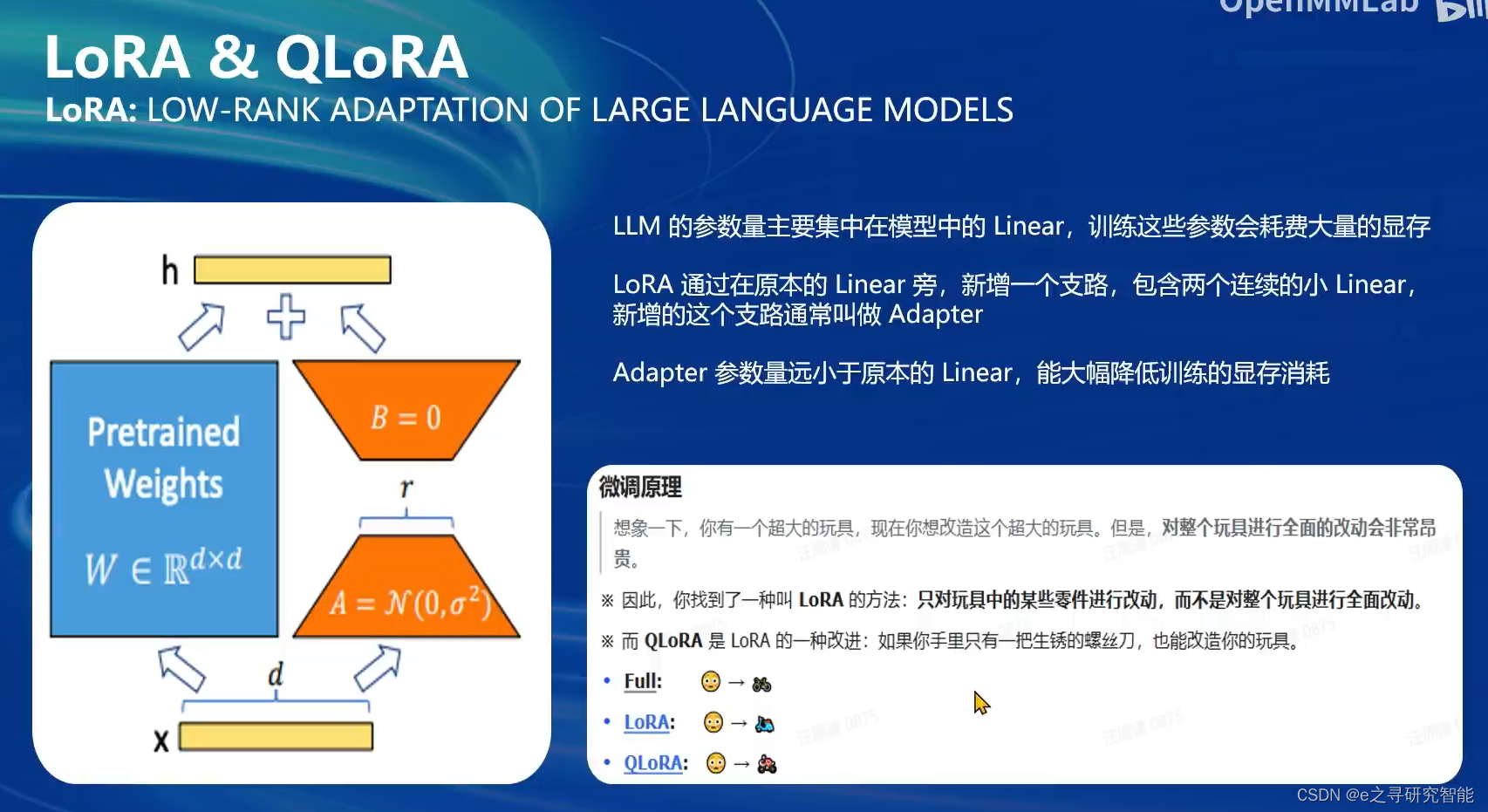
本次实践中采用的微调方式是LoRA/QLoRA,它并不是直接更新原有大模型的权重参数(区别于全量微调),而是在原本的模型基础上新建一个旁侧支路,称为adapter,这个支路的参数数量远小于原模型。微调的过程就是训练这个adapter的参数,因此相比于全量微调,大大节约了显存和运算量。
介绍了微调的基本概念之后,有必要了解本次实践用到的微调工具:XTuner。
XTuner是一个高效、灵活的轻量化大模型微调工具库。它支持在8GB显存下微调7B参数模型,也支持多节点微调更大规模的模型。它可以实现训练加速、deepspeed兼容,支持多种LLM,以及LoRA/QLoRA/全量微调等方式。

之后,即将在实践环节学习使用XTuner做QLoRA微调的基本方法。















 1851
1851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









