






这是一篇2018年发表在CVPR上的论文,作者机构是University of Illinois at Urbana-Champaign(UIUC)和Adobe Research。
网络框架如下:
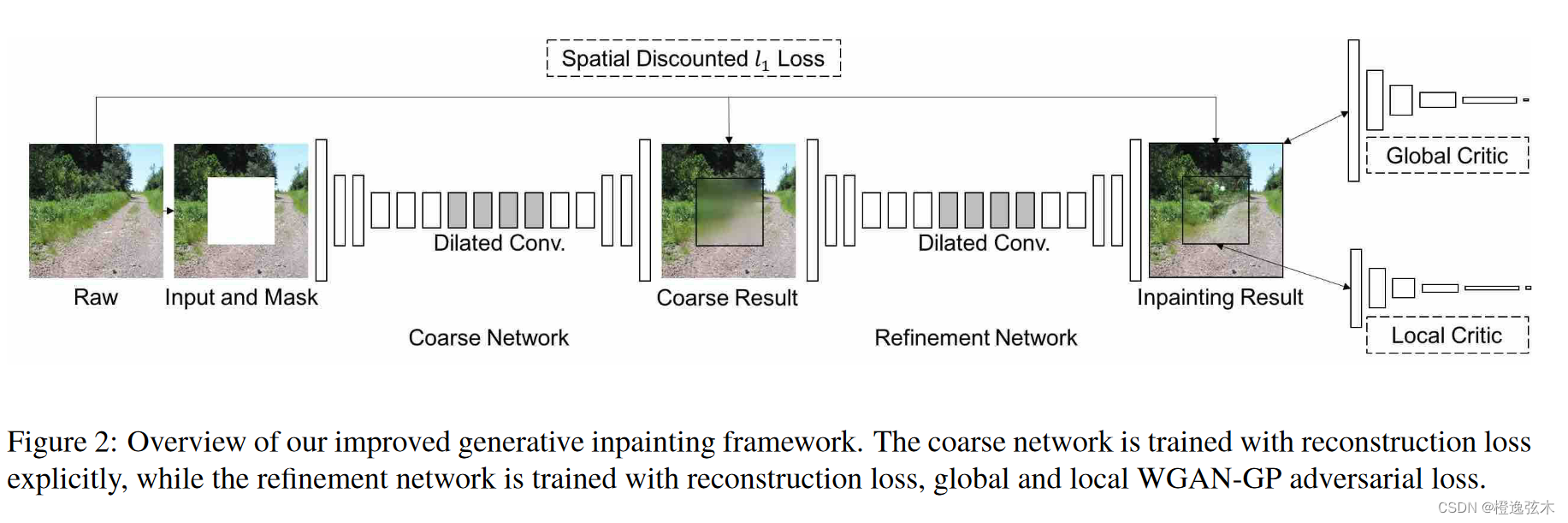
先用Coarse network进行粗略的修复,再用Refinement network进行精细的修复。其中Refinement network用到了contextual attention layer。
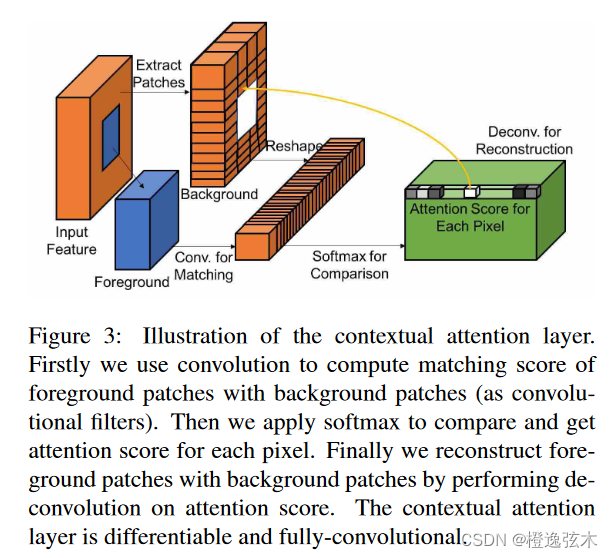
主要方法是将非缺失区域reshape成卷积核,对缺失区域进行卷积,计算出匹配分数,再进行softmax。得到每个像素的attention score后,再进行反卷积,得到修复后的图像。
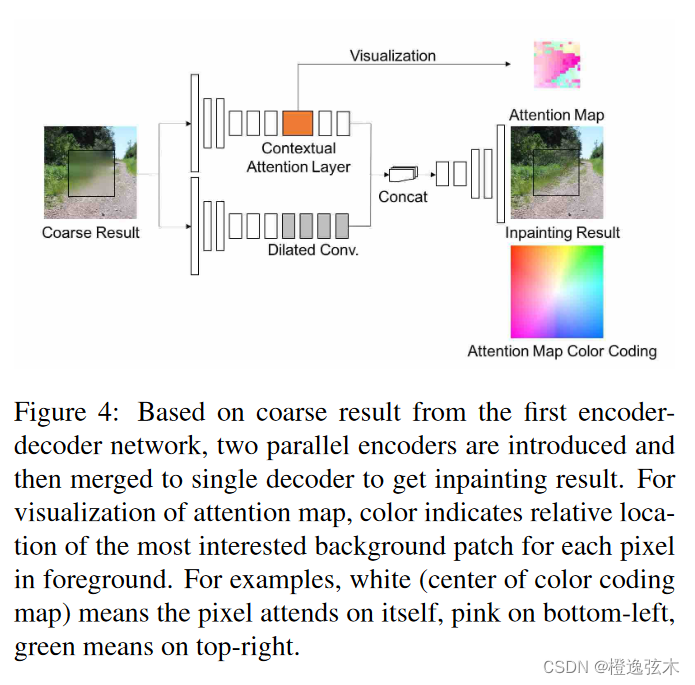
Refinement Network由两个网络拼接而成,上层通过contextual attention layer来生成相应的attention map,在attention map color coding中,白色代表关注该区域本身,粉色代表关注像素左下角的部分,绿色代表关注像素右上角的部分。下层是一个Dialated conv层,这个编码器与coarse network里的一样。
参考文献:















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









