







发现问题
我是一个初学者,在编写一个分解质因数的代码时,学习到了 Miller-Rabin素数测试算法 和 Pollard-Rho算法 这两个算法。试着编写了一段代码(下称C1),运行后效果还不错,但感觉好像哪里不对或者还可以优化,于是在网上搜索。最后在百度百科上看到了一段代码(下称C2),同样使用了上述两个算法。
运行C2后发现,大多数情况下,运行速度差不多。但发现一个数字a,C2的运行时间比C1慢很多。难道我写的算法更优?
数字a为11段1/7的循环节:142857142857142857142857142857142857142857142857142857142857142857
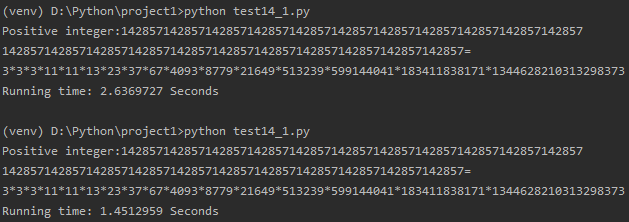
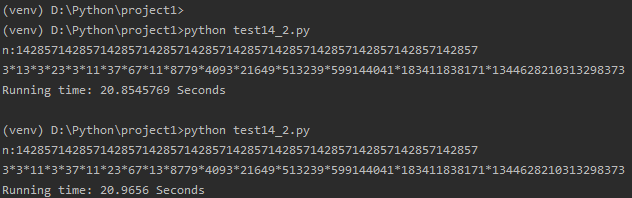
尝试分析
之后的尝试中,又发现1个数字b,会使得C1陷入死循环。分步解析后得出结论是,卡在了 find(n) 函数上。然后发现最可笑的是输入4无法得出因子2。那应该是我的算法错了吧?
再去理解了一遍 Pollard-Rho算法 ,发现是因为我定义的 find(n) 函数中使用随机函数 f(x)=x^2+a 无法解出因子2,既然如此,加上一个判定即可解决。
数字b为11段(1/7的循环节+111111):253968253968253968253968253968253968253968253968253968253968253968
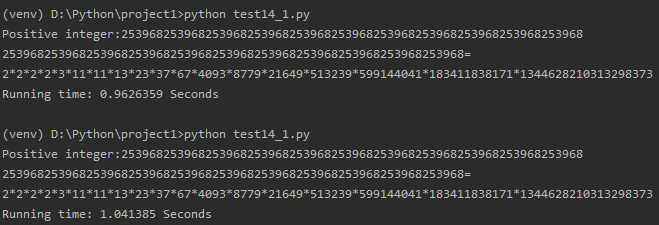
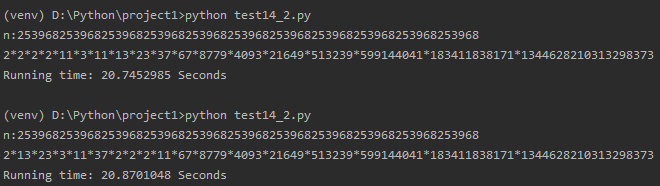
最后
修复后尝试了一些大数,发现C1确实比C2要快。但我还是不敢确定C1的算法是否正确,还望有人可以指正。
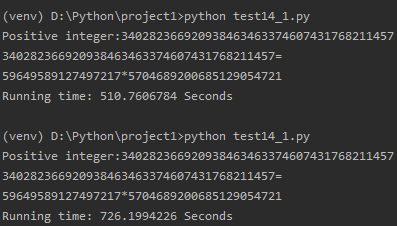
最后尝试一下数字c,算了好久还以为又死循环了,最后C1都运行了2次了C2还没出结果,无奈ctrl+c。看来对于这种大因子的合数分解,这个算法似乎并不好用。
数字c为费马数2^128+1:340282366920938463463374607431768211457
我的代码(C1)
import math
import random
import time
start = time.perf_counter()
# 判断输入是否为素数
def prime(n):
if n in {
2, 3, 5, 7, 11}:
return True
if n % 2 == 0 or n % 3 == 0 or n % 5 == 0 or n % 7 == 0 or n % 11 == 0:
return False
t = 0
u = n - 1
while u % 2 == 0:
t += 1
u //= 2
a = random.randint(2, n - 1)
r = pow(a, u, n)
if r != 1:
while t >< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









