







PostgreSQL笔记
文章目录
wsl 下安装
在 WSL (ie 上安装 PostgreSQL。Ubuntu) :
打开 WSL 终端 (即。Ubuntu) 。
更新 Ubuntu 包:sudo apt update
更新该包后,使用以下命令安装 PostgreSQL(和 -contrib 包,其中包含一些有用的实用程序):sudo apt install postgresql postgresql-contrib
确认安装并获取版本号:psql --version
安装 PostgreSQL 后,需要知道以下 3 个命令:
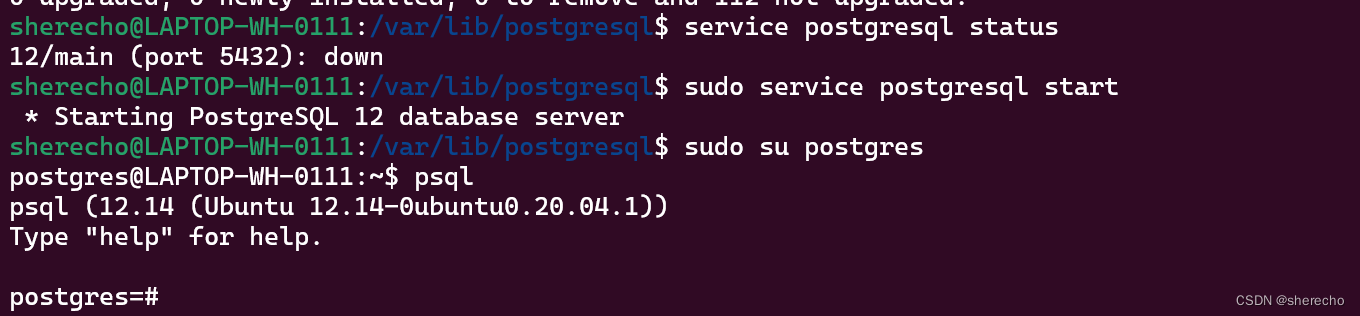
sudo service postgresql status 用于检查数据库的状态。
sudo service postgresql start 用于开始运行数据库。
sudo service postgresql stop 用于停止运行数据库。
要实际使用 PostgreSQL,你必须先登录创建的Linux账号postgres:
sudo su postgres
登陆后,可以看到当前的用户名(postgres)已经发生变化.
通过默认的工具psql登录数据库,通过\q命令退出数据库。
服务器端配置
报错:bash: psql: command not found…
```bash
#用vim打开.bashrc文件
vim ~/.bashrc
#导入相关环境变量
export PATH=$PATH:/usr/local/postgresql/bin
export PGHOME=/usr/local/postgresql
export PGDATA=~/pgdata
#最后一行
报错
psql: FATAL: role [User] does not exist
这是因为 psql 默认是连接的当前用户名的数据库,字面意思就是当前用户名的数据库不存在,当然,PostgreSQL 默认会创建有三个数据库
postgres
template0
template1
psql
访问数据库
运行PostgreSQL交互的终端程序psql,它允许你交互地输入、编辑、执行SQL命令。
例如访问mydb数据库
psql mydb
psql程序有一些不属于 SQL 命令的内部命令。它们以反斜杠 ""开头。比如,你可以用下面的命令获取各 种PostgreSQL SQL命令的帮助语法:
mydb=> \h
要退出psql,键入:
mydb=> \q
psql -h 服务器 -U 用户名 -d 数据库 -p 端口地址 // -U 是大写
psql -h <hostname or ip> -p <port> [dbname] [username]
psql -p 5439 -d tpch_1G
可以在psql里连换行符一起键入这些东西。psql 可以识别该命令直到分号才结束。
例如:
CREATE TABLE weather (
city varchar(80),
temp_lo int, -- low temperature
temp_hi int, -- high temperature
prcp real, -- precipitation
date date
);
explain analyse
explain analyse select p_partkey from part where p_partkey = ps_partkey;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=9379.00..43962.04 rows=800000 width=4) (actual time=49.273..342.739 rows=800000 loops=1)
Hash Cond: (partsupp.ps_partkey = part.p_partkey)
-> Seq Scan on partsupp (cost=0.00..25451.00 rows=800000 width=4) (actual time=0.035..101.641 rows=800000 loops=1)
-> Hash (cost=6097.00..6097.00 rows=200000 width=4) (actual time=48.230..48.231 rows=200000 loops=1)
Buckets: 131072 Batches: 4 Memory Usage: 2786kB
-> Seq Scan on part (cost=0.00..6097.00 rows=200000 width=4) (actual time=0.015..24.490 rows=200000 loops=1)
Planning Time: 2.343 ms
Execution Time: 359.950 ms
可以看出上述语句包含Hash join 的操作:
先对part表进行了扫描,
PostgreSQL中的扫描类型
在查询中对表的扫描计划大概有如下几种:
Seq Scan
Index Scan
Bitmap Heap Scan
Index Only Scan
知乎描述
1)对于Seq Scan很好理解,就是按照表的记录的排列顺序从头到尾依次检索扫描,每次扫描要取到所有的记录。这也是最简单最基础的扫表方式,扫描的代价比较大;
2)对于Index Scan,我们也很熟悉,对于给定的查询,我们先扫描一遍索引,从索引中找到符合要求的记录的位置(指针),再定位到表中具体的Page去取。等于是两次I/O,先走索引,再走取表记录,不同于全表扫描的是只取所需数据对应的Page,I/O量较小;
Hash join
filter
explain analyse select p_partkey from part where p_type like '%BRASS';
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Seq Scan on part (cost=0.00..6597.00 rows=41354 width=4) (actual time=0.048..38.539 rows=40058 loops=1)
Filter: ((p_type)::text ~~ '%BRASS'::text)
Rows Removed by Filter: 159942
Planning Time: 1.120 ms
Execution Time: 39.748 ms
aggregate
详解PostgreSQL聚合函数: 精准统计数据,提升效率 附代码示例
测试案例
select
s_acctbal,
s_name,
n_name,
p_partkey,
p_mfgr,
s_address,
s_phone,
s_comment
from
part,
supplier,
partsupp,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 15
and p_type like '%BRASS'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'EUROPE'
and ps_supplycost = (
select
min(ps_supplycost)
from
partsupp,
supplier,
nation,
region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'EUROPE'
)
order by
s_acctbal desc,
n_name,
s_name,
p_partkey;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
--
Sort (cost=71051.88..71051.88 rows=1 width=270) (actual time=336.359..336.383 rows=460 loops=1)
Sort Key: supplier.s_acctbal DESC, nation.n_name, supplier.s_name, part.p_partkey
Sort Method: quicksort Memory: 150kB
-> Hash Join (cost=38326.96..71051.87 rows=1 width=270) (actual time=262.955..336.045 rows=460 loops=1)
Hash Cond: ((part.p_partkey = partsupp.ps_partkey) AND ((SubPlan 1) = partsupp.ps_supplycost))
-> Seq Scan on part (cost=0.00..7097.00 rows=827 width=30) (actual time=0.093..34.639 rows=747 loops=1)
Filter: (((p_type)::text ~~ '%BRASS'::text) AND (p_size = 15))
Rows Removed by Filter: 199253
-> Hash (cost=30457.96..30457.96 rows=160000 width=250) (actual time=259.632..259.635 rows=158960 loops=1)
Buckets: 16384 Batches: 16 Memory Usage: 2187kB
-> Hash Join (cost=406.96..30457.96 rows=160000 width=250) (actual time=2.984..190.978 rows=158960 loops=1)
Hash Cond: (partsupp.ps_suppkey = supplier.s_suppkey)
-> Seq Scan on partsupp (cost=0.00..25451.00 rows=800000 width=14) (actual time=0.003..74.241 rows=800000 loops=1)
-> Hash (cost=381.96..381.96 rows=2000 width=244) (actual time=2.969..2.971 rows=1987 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 409kB
-> Hash Join (cost=2.46..381.96 rows=2000 width=244) (actual time=0.040..2.358 rows=1987 loops=1)
Hash Cond: (supplier.s_nationkey = nation.n_nationkey)
-> Seq Scan on supplier (cost=0.00..322.00 rows=10000 width=144) (actual time=0.003..1.055 rows=10000 loops=1)
-> Hash (cost=2.40..2.40 rows=5 width=108) (actual time=0.029..0.031 rows=5 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Hash Join (cost=1.07..2.40 rows=5 width=108) (actual time=0.023..0.028 rows=5 loops=1)
Hash Cond: (nation.n_regionkey = region.r_regionkey)
-> Seq Scan on nation (cost=0.00..1.25 rows=25 width=112) (actual time=0.004..0.006 rows=25 loops=1)
-> Hash (cost=1.06..1.06 rows=1 width=4) (actual time=0.009..0.010 rows=1 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on region (cost=0.00..1.06 rows=1 width=4) (actual time=0.005..0.006 rows=1 loops=1)
Filter: (r_name = 'EUROPE'::bpchar)
Rows Removed by Filter: 4
SubPlan 1
-> Aggregate (cost=48.70..48.71 rows=1 width=32) (actual time=0.018..0.018 rows=1 loops=1207)
-> Nested Loop (cost=0.85..48.70 rows=1 width=6) (actual time=0.012..0.017 rows=1 loops=1207)
Join Filter: (nation_1.n_regionkey = region_1.r_regionkey)
Rows Removed by Join Filter: 3
-> Seq Scan on region region_1 (cost=0.00..1.06 rows=1 width=4) (actual time=0.001..0.001 rows=1 loops=1207)
Filter: (r_name = 'EUROPE'::bpchar)
Rows Removed by Filter: 4
-> Nested Loop (cost=0.85..47.58 rows=4 width=10) (actual time=0.007..0.015 rows=4 loops=1207)
-> Nested Loop (cost=0.71..46.96 rows=4 width=10) (actual time=0.005..0.011 rows=4 loops=1207)
-> Index Scan using partsupp_pkey on partsupp partsupp_1 (cost=0.42..13.75 rows=4 width=10) (actual time=0.003..0.004 rows=4 loops=1207
)
Index Cond: (part.p_partkey = ps_partkey)
-> Index Scan using supplier_pkey on supplier supplier_1 (cost=0.29..8.30 rows=1 width=8) (actual time=0.001..0.001 rows=1 loops=4828)
Index Cond: (s_suppkey = partsupp_1.ps_suppkey)
-> Index Scan using nation_pkey on nation nation_1 (cost=0.14..0.16 rows=1 width=8) (actual time=0.001..0.001 rows=1 loops=4828)
Index Cond: (n_nationkey = supplier_1.s_nationkey)
Planning Time: 1.634 ms
Execution Time: 336.552 ms
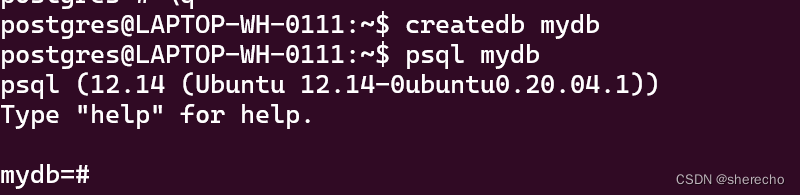
创建删除数据库
createdb mydb
如果您不想再使用数据库,可以将其删除。例如,如果您是数据库的所有者(创建者),则可以使用以下命令销毁它:mydb
dropdb mydb
访问数据库
创建数据库后,可以通过以下方式访问它:
运行称为 psql 的 PostgreSQL 交互式终端程序,它允许您以交互方式输入、编辑和执行 SQL 命令。
使用现有的图形前端工具(如 pgAdmin)或支持 ODBC 或 JDBC 的办公套件来创建和操作数据库。本教程不介绍这些可能性。
创建角色
CREATE ROLE sherecho CREATEROLE;
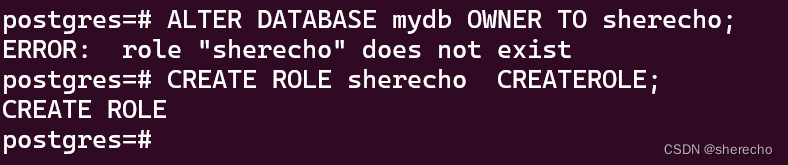
此时还没有登陆权限:
授权登录
alter role "sherecho" with login;
更改数据库所有者
alter database mydb owner to sherecho;
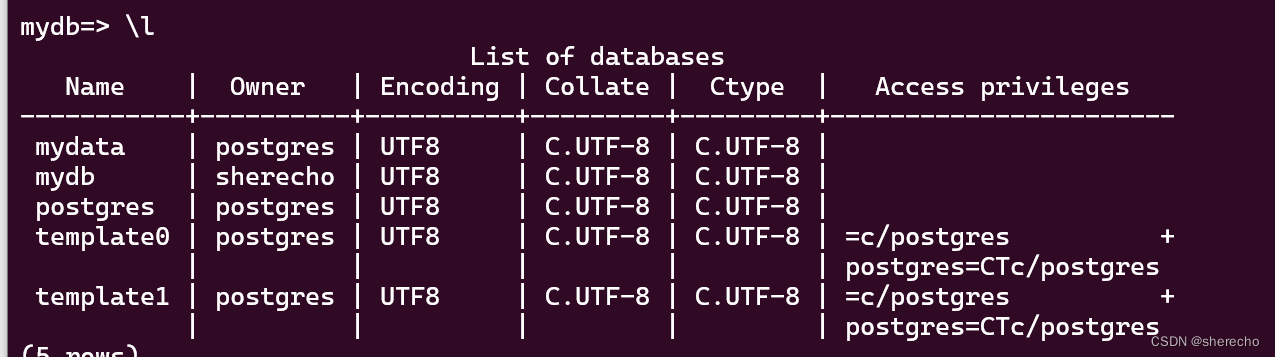
查看端口下的数据库
psql -p 5433 -l
删除数据表
要在 PostgreSQL 中删除表,可以使用 DROP TABLE 命令。请按照以下步骤操作:
DROP TABLE customer;
DROP FOREIGN TABLE customer;















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









