






model的运作已经分析完毕,接下来回到train文件继续进行查看

可以看到下一行代码我们初始化了一个optimizer,采用的是Adam的方法进行优化传播
接下来的一行调用了model.compile方法,用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准。可以看到代码中将optimizer设置为了Adam,接着查看loss损失函数的设置,config.py中设置configs.loss = “RetinaNetLoss”,而loss = {“RetinaNetLoss”:RetinaNetLoss},所以寻找RetinaNetLoss这个类。发现在losses.py中

可以看到这个类继承了tf.losses.Loss,在init方法中其初始化了两个损失计算类RetinaNetClassificationLoss和RetinaNetBoxLoss分别用来计算回归和分类问题
查看分类损失的损失函数RetinaNetClassificationLoss,可以看到其使用了cross_entropy这个交叉熵损失函数。其中tf.where()返回一个布尔张量中真值的位置。对于非布尔型张量,非0的元素都判为True。tf.where还有一个用法:tf.where(input, a,b),其中a,b均为尺寸一致的tensor,实现a中对应input中true的位置的元素值不变,其余元素由b中对应位置元素替换。

查看回归的损失函数RetinaNetBoxLoss,tf.reduce_sum()作用是按一定方式计算张量中元素之和,axis可以为负数,此时表示倒数第axis个维度

最后查看call方法,其实就是调用上述两个loss方法进行计算,进行相加返回
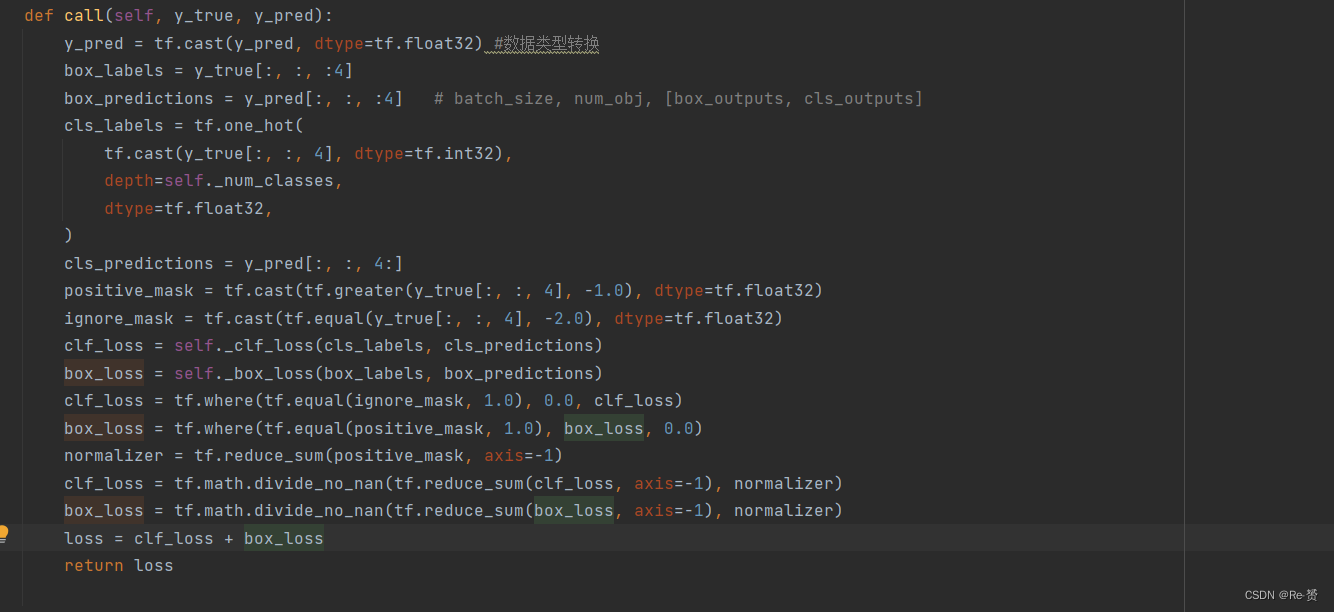
进行debug调试一下,可以看到y_pred的数值应该是之前call函数的返回值,而y_true的值应该是我们的标签值

tf.cast进行数据类型转换,转换为tf.float32
box_labels和box_predictions分别从总的特征向量中取出前4个(也就是回归任务对应的特征向量)

tf.one_hot()函数是将input转化为one-hot类型数据输出
one_hot(indices, depth, on_value=None, off_value=None, axis=None, dtype=None, name=None)
indices表示输入的多个数值,通常是矩阵形式;
depth表示输出的尺寸。
由于one-hot类型数据长度为depth位,其中只用一位数字表示原输入数据,这里的on_value就是这个数字,默认值为1,one-hot数据的其他位用off_value表示,默认值为0。
通过这个函数,我们原本一维的向量维度变为了80维,与特征向量相符合,同时取出原本总向量的后80维,作为分类任务的特征向量

进行loss计算后我们得到了损失值,都是1 * 9441的向量

最后进行loss的相加,tf.reduce_sum()作用是按一定方式计算张量中元素之和,axis指定按哪个维度进行加和,默认将所有元素进行加和。之后分类和回归的loss都变为一维的Tensor,将两者相加返回。















 4388
4388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









