






mmdetection是一个非常方便的目标检测框架,所以有必要阅读一下源码帮助我们理解其运行流程
首先来观察一下它的结构目录(这是我从TinyPerson源码下载的mmdetection,可能与原版有些不同,但流程是一样的)
我们的train函数是放在tools文件夹下的,所以我们从这里开始看起
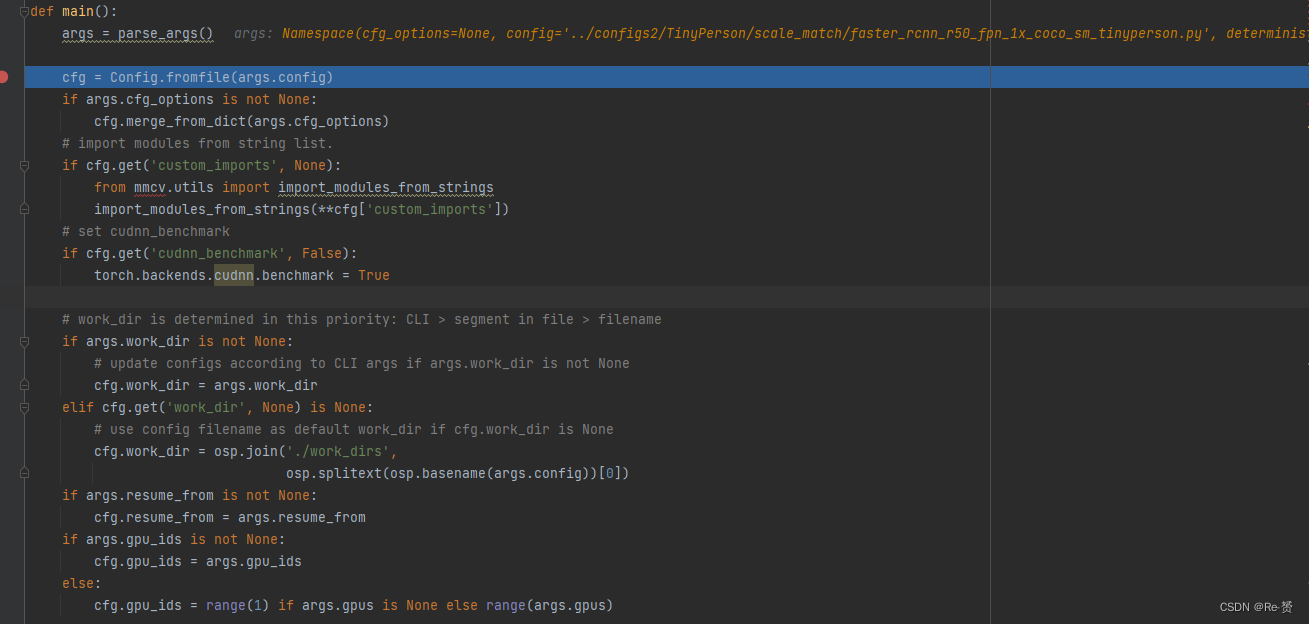
可以看到,main函数首先读取了配置文件,并将其保存为了Config类型
args = parse_args()
cfg = Config.fromfile(args.config)
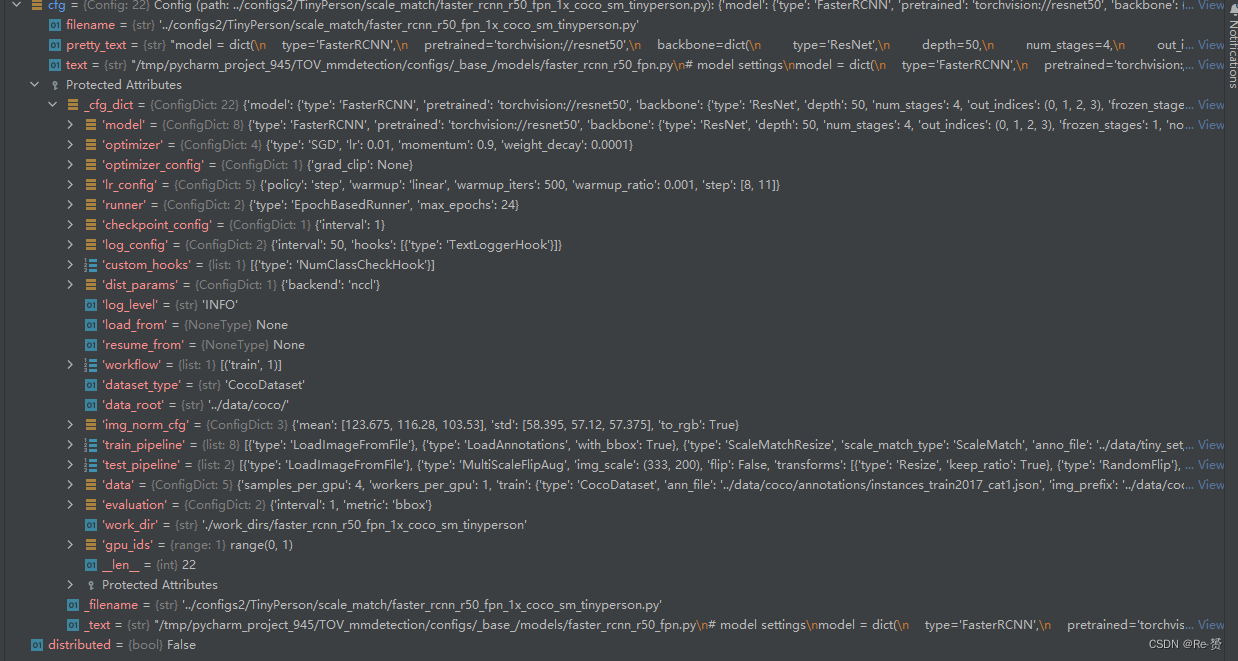
紧接着的许多行代码是对cfg的预处理,包含了custom_imports,cudnn_benchmark,work_dir,resume_from等属性的配置,这里不过多解释,来看cfg经过所有处理后的样子,这里面包含了所有的配置信息
在处理好cfg的信息之后,代码初始化元数据字典meta并记录一些重要信息,例如环境信息和种子(seed),最后得到的meta信息如下

在准备工作做好后,来到了第一个重要的函数,初始化模型的函数
model = build_detector(
cfg.model,
train_cfg=cfg.get('train_cfg'),
test_cfg=cfg.get('test_cfg'))
来看一下传入的参数,cfg.model的配置如下,这是一个字典类型

而train_cfg和test_cfg的配置也同样是字典的类型

进入这个函数进行查看,发现其位于TOV_mmdetection/mmdet/models/builder.py文件中
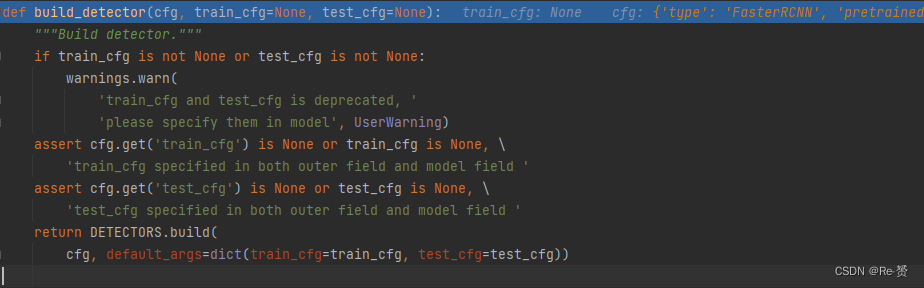
在一系列的assert之后我们可以看到代码来到
DETECTORS.build(
cfg, default_args=dict(train_cfg=train_cfg, test_cfg=test_cfg))
进入build函数查看:
def build(self, *args, **kwargs):
return self.build_func(*args, **kwargs, registry=self)
而build_func的参数所绑定的函数是build_model_from_cfg,具体定义如下
def build_model_from_cfg(cfg, registry, default_args=None):
if isinstance(cfg, list):
modules = [
build_from_cfg(cfg_, registry, default_args) for cfg_ in cfg
]
return Sequential(*modules)
else:
return build_from_cfg(cfg, registry, default_args)
MODELS = Registry('model', build_func=build_model_from_cfg)
很显然我们最终要寻找的构建函数是build_from_cfg函数
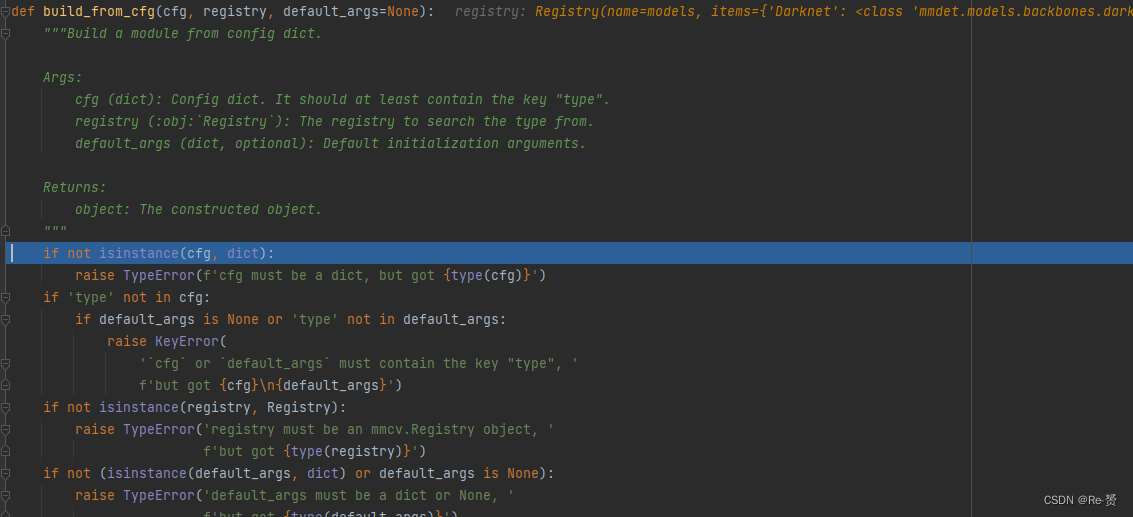
这段代码的重要部分是,我们这里的obj_type的值是一个str
obj_type = args.pop('type')
if isinstance(obj_type, str):
obj_cls = registry.get(obj_type)
if obj_cls is None:
raise KeyError(
f'{obj_type} is not in the {registry.name} registry')
elif inspect.isclass(obj_type):
obj_cls = obj_type
else:
raise TypeError(
f'type must be a str or valid type, but got {type(obj_type)}')
try:
return obj_cls(**args)
except Exception as e:
# Normal TypeError does not print class name.
raise type(e)(f'{obj_cls.__name__}: {e}')
代码首先从 args 字典中弹出键为 'type' 的值,并将其赋给变量 obj_type。然后,根据 obj_type 的类型进行不同的处理:
如果 obj_type 是字符串类型(str),则尝试从注册表(registry)中获取对应的类(obj_cls)。如果在注册表中找不到对应的类,则抛出 KeyError 异常,提示该类型不在注册表中。
如果 obj_type 是类类型(class),则将其赋给变量 obj_cls。
如果 obj_type 不是字符串类型或类类型,则抛出 TypeError 异常,提示类型必须是字符串或有效的类类型。

在这里我们可以看到obj_cls是FasterRcnn的类,所以接下来要初始化FasterRcnn这个具体的实现类,这个实现类的定义在TOV_mmdetection/mmdet/models/detectors/faster_rcnn.py下
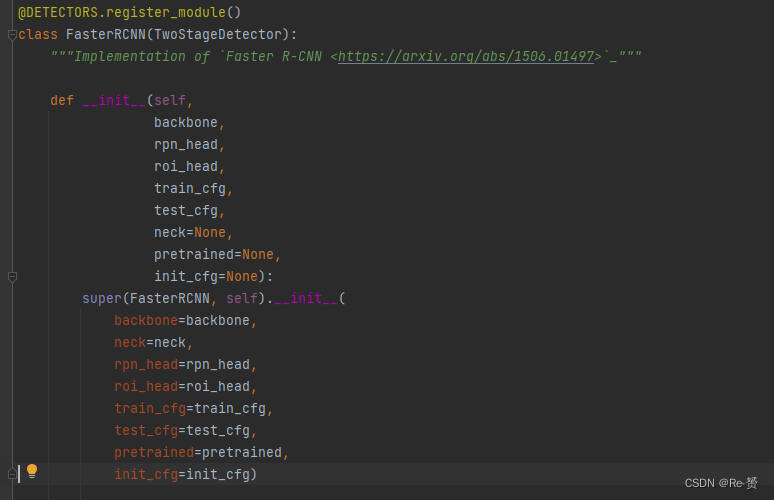
但我们可以看到其中并没有太多的代码,因为其继承了TwoStageDetector这个类,大部分都代码在这个类中实现,下面来看看这个类
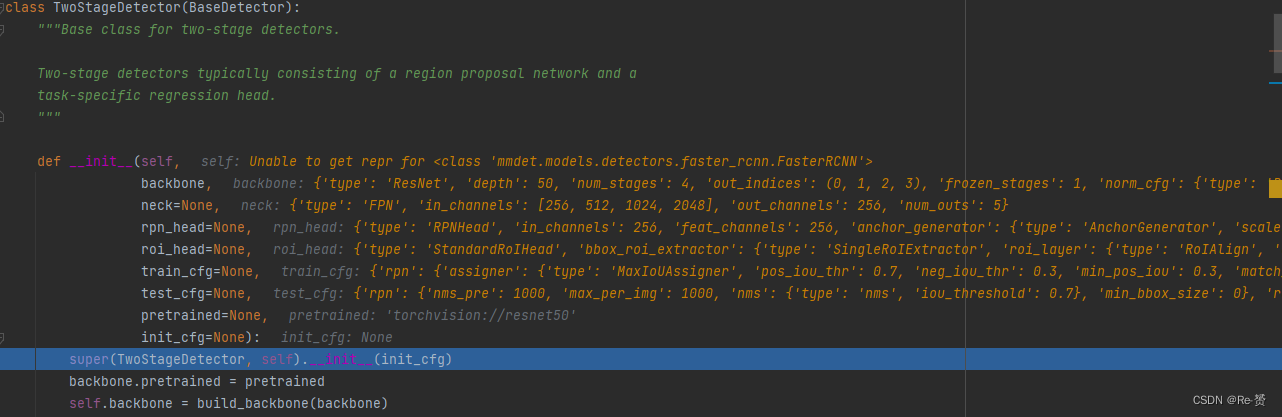
可以看到,代码按照backbone,neck,rpn_head,roi_head,train_cfg,test_cfg的顺序构建每一个部分

具体的实例化(也就是从字典对应到相应的类)是放在了self中,可以看到运行到最后每一个类的初始化已经完成

到此为止,model的初始化已经完成,我们得到了FasterRcnn的模型,回到train函数当中。

在模型初始化结束后,我们要进行数据集的加载,代码集中在:
datasets = [build_dataset(cfg.data.train)]
进入build_dataset这个函数,查看传入的参数

在经过一系列判断后我们来到了
dataset = build_from_cfg(cfg, DATASETS, default_args)
这个函数我们在上一个部分的model构建中已经见到过,运行流程是一样的,最后会来到
return obj_cls(**args)
此时的obj_cls与model构建不一样,变成了CocoDataset类型

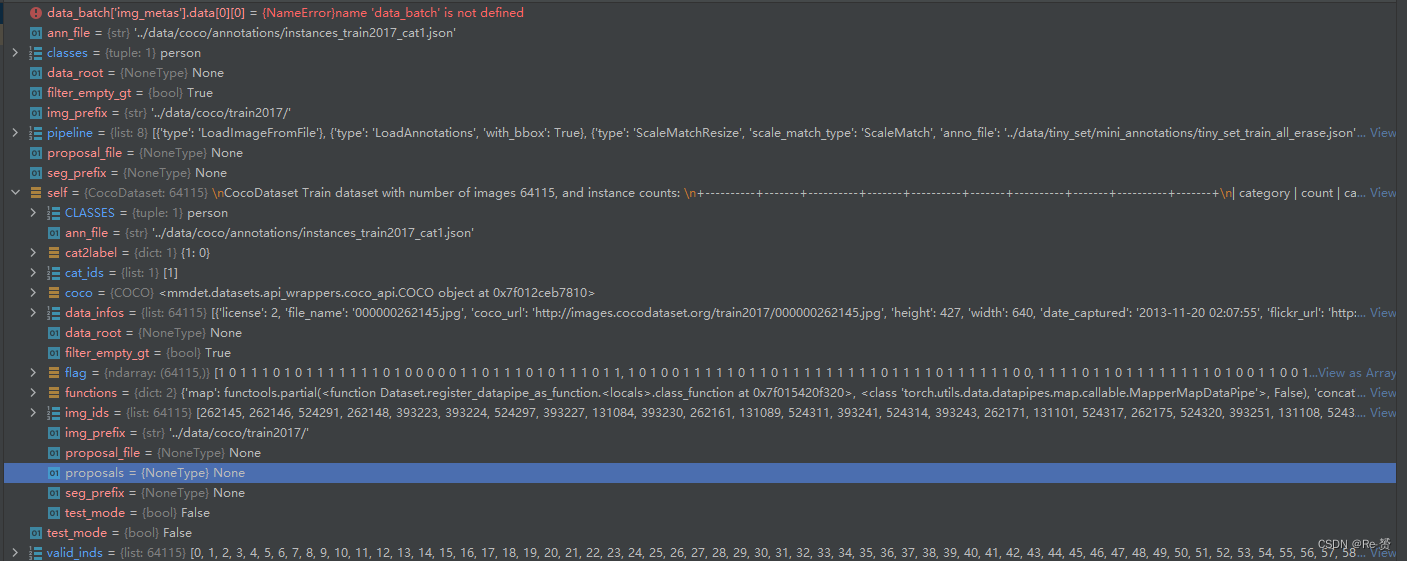
往下看,首先进入了CustomDataset这个类,这是一个基类。CocoDataset继承了它
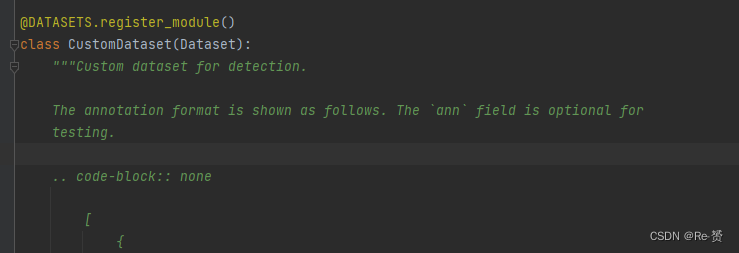
ann_file:注释文件的路径,其中包含图像的标注信息。
pipeline:数据处理的流程,通常是一系列的数据转换操作,如缩放、裁剪、标准化等。
classes:类别列表,指定数据集中的类别名称。如果未指定,则默认为 None。
data_root:数据集的根目录,用于拼接文件路径。
img_prefix:图像文件的前缀路径。
seg_prefix:分割标注文件的前缀路径。
proposal_file:候选区域文件的路径,用于目标检测任务。
test_mode:是否处于测试模式。默认为 False。
filter_empty_gt:是否过滤掉没有标注信息的图像。默认为 True。
紧接着加载了注释文件
self.data_infos = self.load_annotations(self.ann_file)
实际上调用的是mmcv.load
def load_annotations(self, ann_file):
"""Load annotation from annotation file."""
return mmcv.load(ann_file)
mmcv.load 是 mmcv 库中的一个实用函数,可以用来加载不同文件格式的数据。它的具体行为取决于输入文件的扩展名,它可以加载各种类型的数据,例如图像、视频、文本等。当调用 mmcv.load(ann_file) 时,它会根据文件扩展名自动选择适当的加载方法,并返回加载后的数据。在上述代码中,ann_file 是注释文件的路径,通过调用 mmcv.load(ann_file) 来加载注释文件的内容。

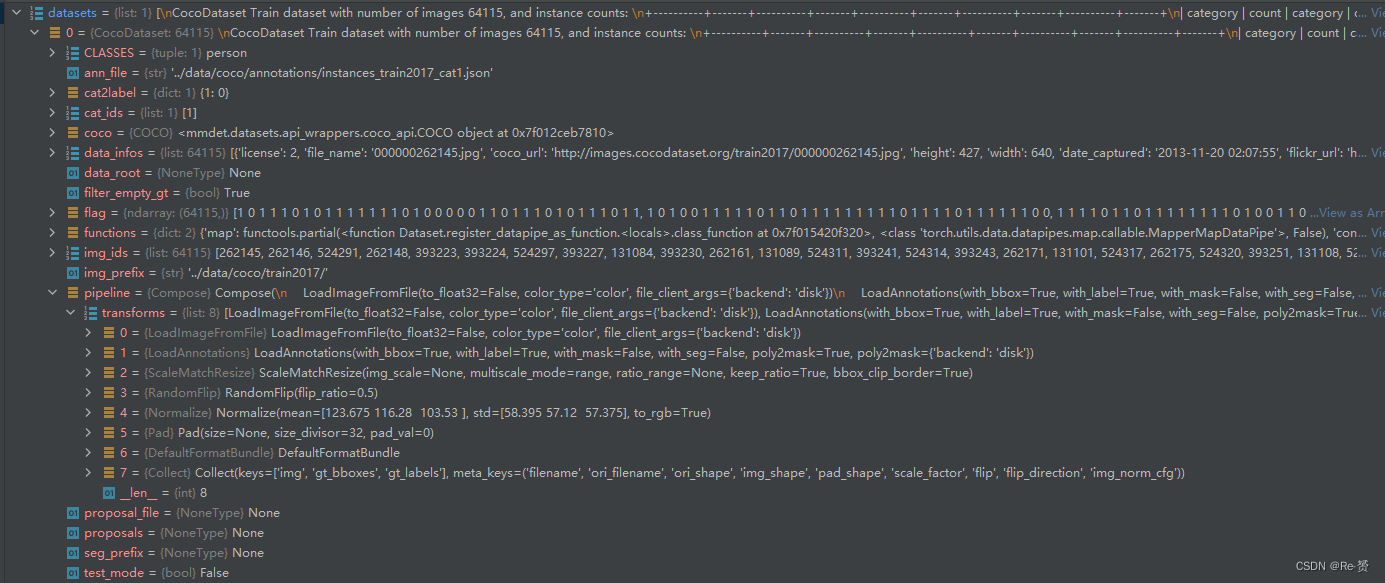
在加载了注释信息之后,代码处理了proposal_file有关的东西。最后,将数据处理的流程定义为 Compose(pipeline),初始化了pipeline 中的类。
self.pipeline = Compose(pipeline)
至此,dataset的初始化完成
在数据集的初始化完成后,代码最后初始化了checkpoin
if cfg.checkpoint_config is not None:
# save mmdet version, config file content and class names in
# checkpoints as meta data
cfg.checkpoint_config.meta = dict(
mmdet_version=__version__ + get_git_hash()[:7],
CLASSES=datasets[0].CLASSES)
所有的初始化结束后,我们就要开始train代码
train_detector(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
meta=meta)
来看train_detector的定义

函数开始首先构建data_loaders,在循环中,通过遍历 dataset 列表,为每个数据集创建一个数据加载器
data_loaders = [
build_dataloader(
ds,
cfg.data.samples_per_gpu,
cfg.data.workers_per_gpu,
# cfg.gpus will be ignored if distributed
len(cfg.gpu_ids),
dist=distributed,
seed=cfg.seed, **d_kwargs) for ds in dataset
]
ds:数据集对象,即当前的数据集。
cfg.data.samples_per_gpu:每个 GPU 上的样本数量。
cfg.data.workers_per_gpu:每个 GPU 上的数据加载器线程数。
len(cfg.gpu_ids):GPU 的数量。如果使用分布式训练,此参数将被忽略。
dist=distributed:是否启用分布式训练。如果为 True,则数据加载器将以分布式模式创建。
seed=cfg.seed:数据加载器的随机种子。
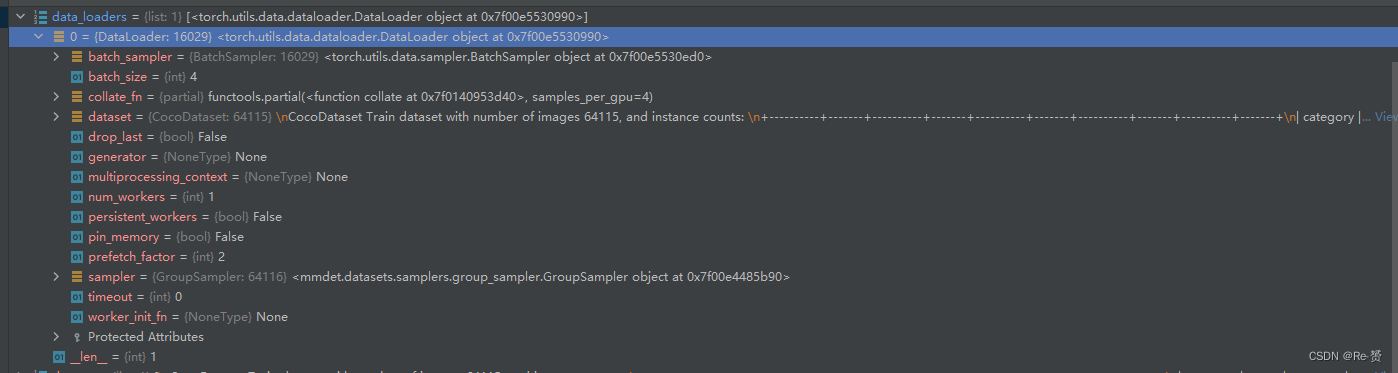
接下来,如果程序没有采用分布式,则通过 model.cuda(cfg.gpu_ids[0]) 将模型移动到指定的 GPU(cfg.gpu_ids[0])。然后,使用 device_ids=cfg.gpu_ids 将模型复制到所有指定的 GPU 上。
model = MMDataParallel(
model.cuda(cfg.gpu_ids[0]), device_ids=cfg.gpu_ids)
MMDataParallel 是 mmdetection 库中的一个类,用于实现模型的数据并行操作。它可以自动将数据分配到不同的 GPU 上,并在每个 GPU 上运行模型的正向传播和反向传播过程。这样可以加快模型的训练速度,特别是对于大型模型和大规模数据集。
接下来是optimizer的构建,我们选用了SGD的方法
optimizer = build_optimizer(model, cfg.optimizer)
build_optimizer 是 mmdetection 库中的一个函数,用于根据配置文件中的设置构建优化器。它接受两个参数:模型对象 model 和优化器的配置字典 cfg.optimizer。通过调用 build_optimizer 函数,可以根据配置文件中的设置创建一个用于优化模型的优化器。该优化器可以根据配置文件中定义的优化算法、学习率、权重衰减等参数进行配置。

runner = build_runner(
cfg.runner,
default_args=dict(
model=model,
optimizer=optimizer,
work_dir=cfg.work_dir,
logger=logger,
meta=meta))
build_runner 是 mmdetection 库中的一个函数,用于根据配置文件中的设置构建训练器。它接受两个参数:训练器的配置字典 cfg.runner 和默认参数 default_args。通过调用 build_runner 函数,可以根据配置文件中的设置创建一个用于训练模型的训练器。
fp16_cfg = cfg.get('fp16', None)
if fp16_cfg is not None:
optimizer_config = Fp16OptimizerHook(
**cfg.optimizer_config, **fp16_cfg, distributed=distributed)
elif distributed and 'type' not in cfg.optimizer_config:
optimizer_config = OptimizerHook(**cfg.optimizer_config)
else:
optimizer_config = cfg.optimizer_config
得到的 optimizer_config 对象将用于在训练过程中对优化器进行配置,包括学习率、权重衰减等参数的设置。根据配置的不同,可能会使用混合精度优化器(FP16)或普通优化器,并根据分布式训练模式进行相应的配置。
runner.register_training_hooks(cfg.lr_config, optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
注册训练过程中的各种钩子函数(hooks)到训练器(runner)中。
具体作用如下:
cfg.lr_config 是学习率配置对象,用于控制学习率的调整策略。
optimizer_config 是优化器配置对象,用于配置优化器的参数。
cfg.checkpoint_config 是模型保存配置对象,用于配置模型保存的相关参数。
cfg.log_config 是日志记录配置对象,用于配置训练过程中的日志记录设置。
cfg.get('momentum_config', None) 是动量(momentum)配置对象,可选参数,用于配置优化器中的动量参数。
通过调用 runner.register_training_hooks 方法,将上述配置对象作为参数传入,训练器将根据这些配置注册相应的钩子函数到训练过程中。这些钩子函数会在训练的不同阶段被调用,执行特定的操作,例如学习率调整、模型保存、日志记录等。
if validate:
# Support batch_size > 1 in validation
val_samples_per_gpu = cfg.data.val.pop('samples_per_gpu', 1)
if val_samples_per_gpu > 1:
# Replace 'ImageToTensor' to 'DefaultFormatBundle'
cfg.data.val.pipeline = replace_ImageToTensor(
cfg.data.val.pipeline)
val_dataset = build_dataset(cfg.data.val, dict(test_mode=cfg.data.val.pop('test_mode', True)))
val_dataloader = build_dataloader(
val_dataset,
samples_per_gpu=val_samples_per_gpu,
workers_per_gpu=cfg.data.workers_per_gpu,
dist=distributed,
shuffle=False if cfg.data.get("shuffle", None) is None else cfg.data.shuffle) # add by hui
eval_cfg = cfg.get('evaluation', {})
eval_cfg['by_epoch'] = cfg.runner['type'] != 'IterBasedRunner'
eval_hook = DistEvalHook if distributed else EvalHook
runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
在训练过程中注册验证(evaluation)的相关操作,构建验证数据集对象 val_dataset,根据配置文件中的相关参数进行配置
if cfg.resume_from:
runner.resume(cfg.resume_from)
elif cfg.load_from:
runner.load_checkpoint(cfg.load_from)
用于根据配置文件中的设置来恢复训练过程或加载预训练模型
最后代码来到了,开始模型的训练
runner.run(data_loaders, cfg.workflow)
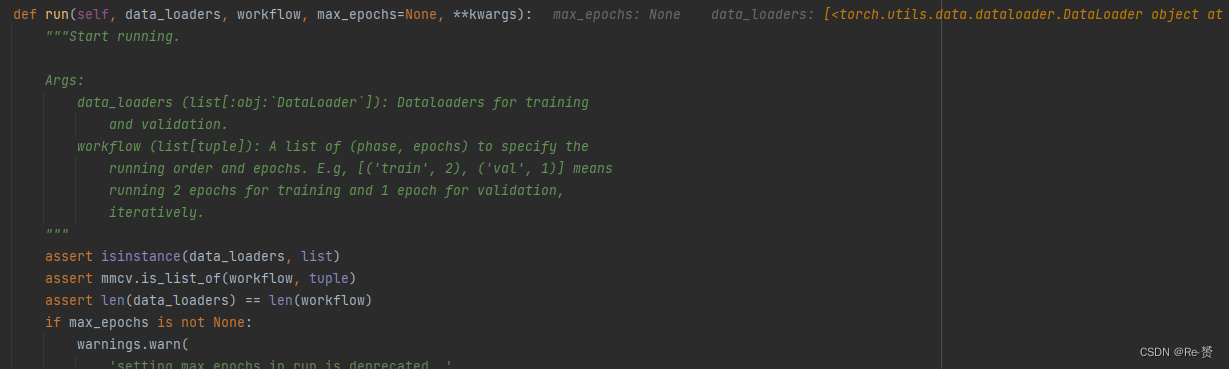
这个函数位于epoch_based_runner.py中,是mmdetection自带的
while self.epoch < self._max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
if isinstance(mode, str): # self.train()
if not hasattr(self, mode):
raise ValueError(
f'runner has no method named "{mode}" to run an '
'epoch')
epoch_runner = getattr(self, mode)
else:
raise TypeError(
'mode in workflow must be a str, but got {}'.format(
type(mode)))
for _ in range(epochs):
if mode == 'train' and self.epoch >= self._max_epochs:
break
epoch_runner(data_loaders[i], **kwargs)
最为重要的是epoch_runner这个函数
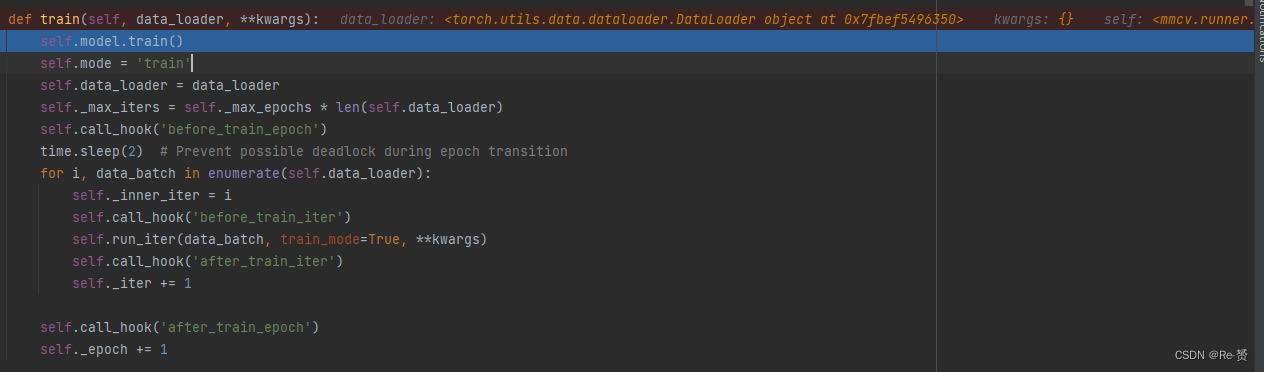
调用self.call_hook('before_train_epoch'),在训练周期开始前执行钩子函数(hook)。
通过time.sleep(2)来防止在训练周期转换期间可能出现的死锁情况。
遍历数据加载器self.data_loader中的每个数据批次,使用enumerate函数迭代,并记录当前的迭代次数。
在每个训练迭代前后调用相应的钩子函数:
self.call_hook('before_train_iter'):在每个训练迭代开始前执行钩子函数。
self.run_iter(data_batch, train_mode=True, **kwargs):运行训练迭代,对输入的数据批次进行训练操作。
self.call_hook('after_train_iter'):在每个训练迭代结束后执行钩子函数。
更新迭代次数self._iter。
调用self.call_hook('after_train_epoch'),在训练周期结束后执行钩子函数。
更新周期数self._epoch。
而具体的训练迭代代码是run_iter:
def run_iter(self, data_batch, train_mode, **kwargs):
if self.batch_processor is not None:
outputs = self.batch_processor(
self.model, data_batch, train_mode=train_mode, **kwargs)
elif train_mode:
outputs = self.model.train_step(data_batch, self.optimizer,
**kwargs)
else:
outputs = self.model.val_step(data_batch, self.optimizer, **kwargs)
if not isinstance(outputs, dict):
raise TypeError('"batch_processor()" or "model.train_step()"'
'and "model.val_step()" must return a dict')
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'], outputs['num_samples'])
self.outputs = outputs
因为我们现在运行的是train代码,所以会执行如下语句,位于data_parallel.py
outputs = self.model.train_step(data_batch, self.optimizer,
**kwargs)

在这个方法中,首先进行了一些检查,确保只在单个 GPU 上进行训练。然后,通过调用 scatter 方法将输入数据和关键字参数在多个 GPU 上分发。接下来,调用 self.module.train_step 方法,在每个 GPU 上执行训练步骤。














 4176
4176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









