






文章目录
Relation Networks for Object Detection
Abstract
虽然多年来人们一直相信对象之间的modeling relations会有助于目标识别,但在深度学习时代尚未找到这一想法有效的证据。本研究提出了一个object relation module。它通过对象的外观特征和几何特征之间的相互作用同时处理一组对象,从而可以对它们的关系进行建模。模块轻量且原地计算,不需要额外的监督,并且可以轻松嵌入到现有的网络中
1. Introduction
近年来,使用深度卷积神经网络(CNN)进行目标检测取得了显著进展。最先进的目标检测方法大多遵循region based 的范式。给定一组稀疏的region proposals,对每个proposals进行对象分类和边界框回归。然后,应用一种heuristic and hand crafted的后处理步骤,非最大值抑制(NMS),以消除重复检测结果。
在深度学习时代,关于利用对象关系进行检测学习的显著进展尚未出现。大多数方法仍然侧重于单独识别对象。其中一个原因是对象之间的关系很难建模。对象位于任意图像位置,具有不同的尺度,属于不同的类别,
我们的方法受到在自然语言处理领域中注意力模块的成功启发。注意力模块可以通过从一组元素聚合信息(或特征)来影响单个元素。注意力模块可以建模元素之间的依赖关系,而无需对它们的位置和特征分布进行过多假设。
在这项工作中,我们首次提出了一种适用于目标检测的改进注意力模块。与之前的模块相比,最明显的区别是原始元素是objects,这些objects具有二维的空间布局,并且在尺度和纵横比方面存在变化。因此,所提出的模块将原始的注意力权重扩展为两个部分:original weight和新的geometric weight。后者用于建模对象之间的空间关系,并且只考虑它们之间的相对几何关系,从而使模块具有平移不变性。
该模块被称为对object relation module。它与注意力模块具有相同的优势。它可以接受可变数量的输入,可以并行运行。因此,它可以作为一个基本的构建模块,在任何架构中都可以灵活使用。从原理上讲,我们的方法与大多数基于CNN的目标检测方法有根本的区别,并且可以相互补充。它利用了一个新的维度:一组对象同时进行处理、推理和相互影响,而不是单独进行识别。
2. Related Works
略过
3. Object Relation Module
我们首先回顾一种基本的注意力模块,称为“Scaled Dot-Product Attention,输入包含维度为dk的queries和keys,以及维度为dv的values。query与所有key之间进行点积运算,以获得它们的相似性。然后应用softmax函数来获得values的权重。给定一个query q,所有key(打包成矩阵K)和value(打包成V),输出值是输入值的加权平均值。

现在我们描述object relation计算。假设一个object 由其geometric feature fG和 appearance feature fA组成。在这项工作中,fG只是一个四维的对象边界框,而fA根据任务的需要而定。给定输入的对象集合{(fnA,fnG)}Nn=1,对于第n个对象,整个对象集合的关系特征fR(n)计算如下:
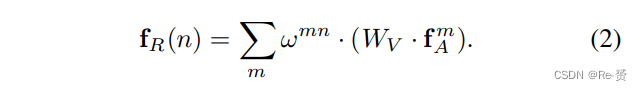
输出是其他对象的appearance features的加权和,通过WV进行线性变换(对应于公式(1)中的值V)。关系权重ωmn表示其他对象的影响。它的计算方式如下:
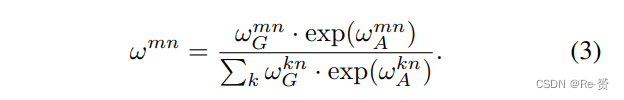
appearance features ωmnA通过点积计算,与公式(1)中的计算方式类似:

WK和WQ都是矩阵,在公式(1)中扮演类似于K和Q的角色。它们将原始特征fmA和fnA投影到子空间中,以衡量它们的匹配程度。投影后的特征维度为dk。
Geometry weight的计算方式如下:
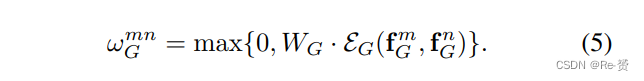
计算几何权重有两个步骤:
首先,将两个对象的geometry features嵌入到一个高维表示中,表示为EG。为了使其对平移和尺度变换具有不变性,使用了一个四维的相对geometry features,如下所示:
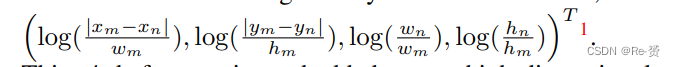
把这个4维特征嵌入到一个高维表示中,该方法计算了不同波长的余弦和正弦函数。嵌入后的特征维度为dg。
第二步,通过WG将embedded feature转换为一个标量权重,并进行零修剪,作为ReLU非线性操作。零修剪操作将关系限制在具有特定几何关系的对象之间。
几何权重公式(5)在注意力权重公式(3)中的使用使得我们的方法与基本的注意力公式(1)有所区别。为了验证公式(5)的有效性,我们还尝试了另外两个更简单的变种。第一个称为"none",它不使用几何权重公式(5),在公式(3)中,ωmnG是一个常数1.0。第二个称为"unary",具体而言,fG以与fA相同的方式被嵌入到一个高维度空间中,并与fA相加形成新的appearance feature。然后,计算注意力权重与"none"方法相同。
对象关系模块总共聚合了Nr个关系特征,并通过加法来增强输入对象的appearance feature:

使用Concat(·)来聚合多个关系特征,为了匹配通道维度,每个WrV的输出通道被设置为输入特征fmA的维度的1/Nr。
object relation module 公式(6)的算法如算法1所示。它可以使用基本的操作符很容易地实现:

公式(2)中的每个 relation function由四个矩阵(WK、WQ、WG、WV)参数化,总共有4Nr个参数。设输入特征fA的维度为df。参数的数量为:

根据算法1,计算复杂度为:
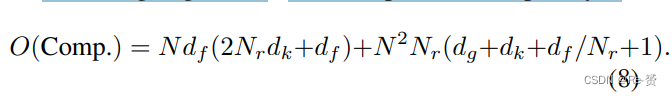
典型的参数值为Nr = 16,dk = 64,dg = 64。一般来说,N和df通常在几百的数量级上。当应用于现代目标检测器时,整体计算开销较低。
4. Relation Networks For Object Detection
4.1. Review of Object Detection Pipeline
本研究符合基于region based的目标检测范式。在所有以前的工作中,都使用了一个包含四个步骤的流程,如下所总结。
第一步生成完整图像特征。从输入图像中,一个深度卷积主干网络提取完整分辨率的卷积特征(通常比输入图像分辨率小16倍)
第二步生成regional features。从卷积特征和一组稀疏的region proposals 中,通过RoI池化层提取特征。
第三步进行实例识别。从每个proposal’s regional features,一个头网络预测了提议属于某个特定对象类别的概率,并通过回归对提议的边界框进行细化。
最后一步进行重复项去除。由于每个对象只应被检测一次,同一个对象上的重复检测结果应该被删除。
在这项工作中,所提出的对象关系模块用于最后两个步骤。我们展示了它如何增强实例识别(第4.2节)并学习去除重复项(第4.3节)。
4.2. Relation for Instance Recognition
给定第nth个proposal的RoI池化特征,我们使用两个维度为1024的全连接层。然后通过线性层进行实例分类和边界框回归。这个过程可以总结为:

object relation module可以在不改变特征维度的情况下转换所有proposals的1024维特征。因此,它可以在公式(9)中的任何一个全连接层之后使用任意次数。增强的2fc+RM(RM代表关系模块)并可总结为:

在公式(10)中,r1和r2表示关系模块重复的次数。需要注意的是,关系模块还需要所有proposals’的边界框作为输入。为了清晰起见,此处忽略了这种表示法。
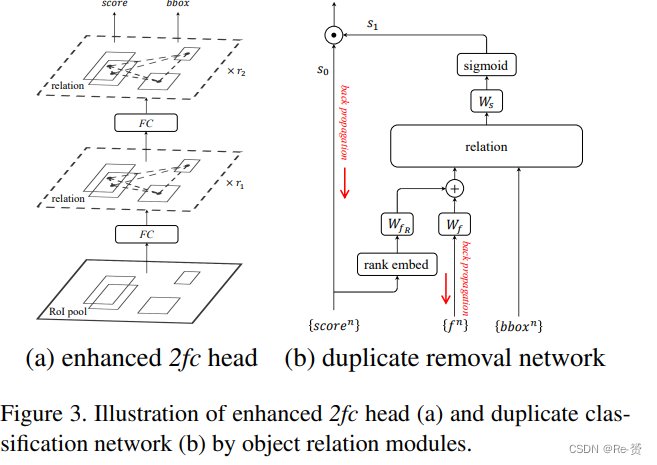
4.3. Relation for Duplicate Removal
略过
5. Experiments
略过
6. Conclusions
The comprehensive ablation experiments suggest that the relation modules have learnt information between objects that is missing when learning is performed on individual objects. Nevertheless, it is not clear what is learnt in the relation module, especially when multiple ones are stacked.
Towards understanding, we investigate the (only) relation module in the {r1, r2} = {1, 0} head in Table 1©. Figure 4 show some representative examples with high relation weights. The left example suggests that several objects overlapping on the same ground truth (bicycle) contribute to the centering object. The right example suggests that the person contributes to the glove. While these examples are intuitive, our understanding of how relation module worksis preliminary and left as future work.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









