






最近在尝试flinkCDC3.0的pipeline功能同步数据至doris以备实时数仓的开发,总结几点,新功能很方便,通过配置文件的方式可以采集多个表,不用单独写一个一个的flinkSQL配置,而且可以动态监控表创建、字段变更、数据变更等,非常的方便。美中不足的是目前不支持application方式提交,且检查点重启配置,任务执行日志监控等相对于比较的模糊。可能是我太菜还不会配置,话不多说,来看看我遇到的最大一个坑。
与其说是一个坑,倒不如说是我们的业务开发和cdc3.0的问题不兼容导致。我在用flinkCDC3.0配置文件的方式,监控mysql表的binlog日志,然后动态生成doris表,然后动态刷新实时数据,其中mysql有个表的有一个status字段,其类型是TINYINT(1)类型,按照不成文的规范来说,这个类型的字段只用来存储0和1,但是我们的业务开发存储了(1,2,3,4)等数字,但是flinkCDC3.0字段映射是将 TINYINT(1) 类型默认转成了boolean类型,导致将所有大于一的数据全部转为了1,这就导致status的很多状态获取不到,那相应的doris表也被建成了boolean类型,status就只有0和1的枚举。导致数据查询where过滤的时候,滤掉了很多数据。
映射关系图
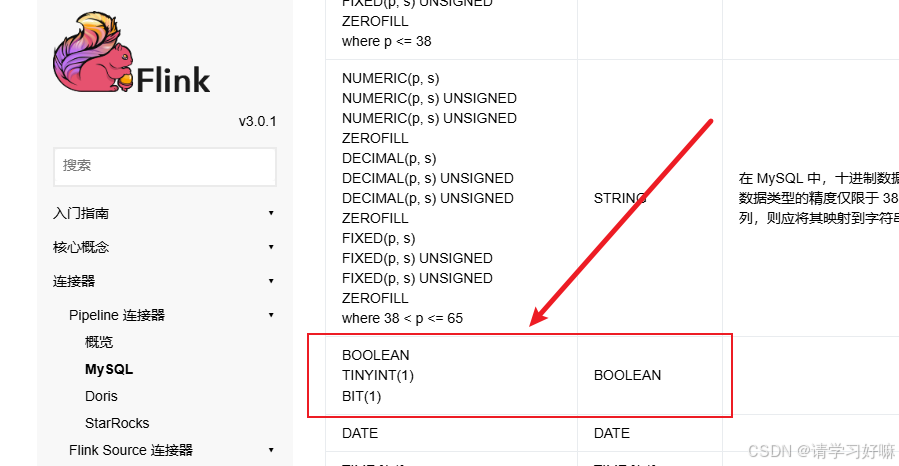
解决方法:修改flinkCDC3.0的源码,将TINYINT(1)类型转换修改过来
1、拉取git代码:GitHub - apache/flink-cdc: Flink CDC is a streaming data integration tool
2、找到flink-cdc-connect模块下的子模块flink-cdc-pipeline-connector-mysql,在Utils包下找到
MySqlTypeUtils类,将136行case TINYINT:这个case修改一下
return column.length() == 1 ? DataTypes.BOOLEAN() : DataTypes.TINYINT();
//替换为下面这行
return DataTypes.TINYINT();3、maven重新打包编译flink-cdc-connect模块l
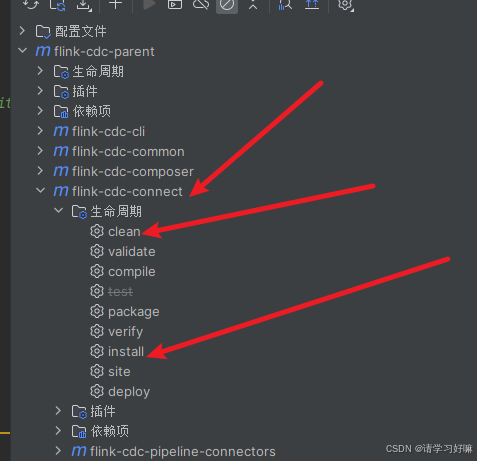
4、在flink-cdc-connect的taget目录下找到jar包:
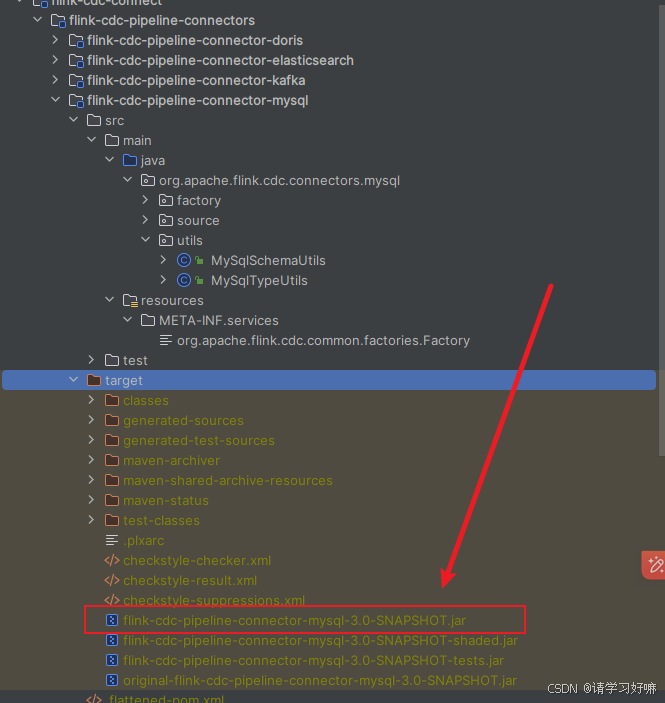
5、上传到服务器的cdc3.0安装目录的lib下,将原有pipeline-mysql jar包删除或者备份,然后把这个改名 由此解决
mv flink-cdc-pipeline-connector-mysql-SNAPSHOT-3.0.0.jar flink-cdc-pipeline-connector-mysql-3.0.0.jar

















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









