







目录
前言
趁着五一没啥事情,花两天把lab2A写一下…还是老样子,希望能读者能有自己的 思路构建后,再来看本篇会更有收获。gitee地址也放在末尾。
5.10更新: 本来做lab2a以为积累了些信心…结果又被lab2b劝退回来做2a了,因为2b其实是基于2a的,2a的测试只有三个,导致有些代码看似通过了,其实陷阱很大。而且在lab2a中我也没用到很多的函数,便又花了四五个小时重推了一边代码…。
一、学习背景
lab2主要为分为A,B,C 分别是raft的领导选举,状态机日志复制,以及持久化实现,具体难度等我把全部做完再来比较吧,也希望自己能坚持下去…。做实验之前一定要把论文的第1、2节看完,对共识算法,以及raft的引入有个大概的认知。以及论文的第5节看完,这是实验的实现思路,当然只看论文估计也很难理解这里给出额外笔者在b站上找的理解视频或者辅助学习链接。
以及lab的Introduction一定要多看,上面给了很多的hint算是比较全了,以及代码测试时如何进行的,也都是在其中都有。
二、实验引入
因为做这个实验的时候总是会代入上一个实验MapReduce实验,因为目标都是实现一个框架,但是实际做的时候发现还是很多不同的。例如这个实验其实某个进入函数去make这个raft节点,不像lab1的worker之类,而是直接在测试代码里进行make。
对于2A中调用的测试func分别为TestInitialElection2A、TestReElection2A、TestManyElections2A。而仔细看这三者方法的话会发现其中有一个共同点。那就都调用了make_config方法。而这个方法也就是我们构造出raft节点的方法。值得一提的是,测试代码里面会调用raft.go中的getState方法,判断你当前的任期和是否是领导人。具体方法应该具体根据自己的结构体实现。知道方法是怎么引入后,接下来就来实现我们的raft.go。
func (rf *Raft) GetState() (int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
var term int
var isleader bool
// Your code here (2A).
term = rf.currentTerm
//fmt.Println("the peer[", rf.me, "] state is:", rf.state)
if rf.state == Leader {
isleader = true
} else {
isleader = false
}
return term, isleader
}
三、结构体实现
3.1 State的定义
对于大致的结构体其实论文中的表格以及给的很清楚了,我们只需要补充部分细节。
对于server应有的状态:

由此我们可以在raft中定义如上几个变量(对于表格中的字段的个人理解,以注释方式写在代码中了)。
先定义一些枚举常量:
// Status 节点的角色
type Status int
// VoteState 投票的状态 2A
type VoteState int
// AppendEntriesState 追加日志的状态 2A 2B
type AppendEntriesState int
// HeartBeatTimeout 定义一个全局心跳超时时间
var HeartBeatTimeout = 120 * time.Millisecond
// 枚举节点的类型:跟随者、竞选者、领导者
const (
Follower Status = iota
Candidate
Leader
)
const (
Normal VoteState = iota //投票过程正常
Killed //Raft节点已终止
Expire //投票(消息\竞选者)过期
Voted //本Term内已经投过票
)
const (
AppNormal AppendEntriesState = iota // 追加正常
AppOutOfDate // 追加过时
AppKilled // Raft程序终止
AppRepeat // 追加重复 (2B
AppCommited // 追加的日志已经提交 (2B
Mismatch // 追加不匹配 (2B
)
接着就是表格中raft
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
// 所有的servers拥有的变量:
currentTerm int // 记录当前的任期
votedFor int // 记录当前的任期把票投给了谁
logs []LogEntry // 日志条目数组,包含了状态机要执行的指令集,以及收到领导时的任期号
// 所有的servers经常修改的:
// 正常情况下commitIndex与lastApplied应该是一样的,但是如果有一个新的提交,并且还未应用的话last应该要更小些
commitIndex int // 状态机中已知的被提交的日志条目的索引值(初始化为0,持续递增)
lastApplied int // 最后一个被追加到状态机日志的索引值
// leader拥有的可见变量,用来管理他的follower(leader经常修改的)
// nextIndex与matchIndex初始化长度应该为len(peers),Leader对于每个Follower都记录他的nextIndex和matchIndex
// nextIndex指的是下一个的appendEntries要从哪里开始
// matchIndex指的是已知的某follower的log与leader的log最大匹配到第几个Index,已经apply
nextIndex []int // 对于每一个server,需要发送给他下一个日志条目的索引值(初始化为leader日志index+1,那么范围就对标len)
matchIndex []int // 对于每一个server,已经复制给该server的最后日志条目下标
// 由自己追加的:
status Status // 该节点是什么角色(状态)
overtime time.Duration // 设置超时时间,200-400ms
timer *time.Ticker // 每个节点中的计时器
applyChan chan ApplyMsg // 日志都是存在这里client取(2B)
}
其中最后三个虽然没有提到,但是对于raft整个领导人选举来说这些字段应是较好理解的。而对于peers,me其实就是整个框架所拥有的rf节点总数,me代表的就是自身节点在raft中的下标。这部分在Introduction中也有具体提到。(所以Introduction也要认真的看)
3.2 AppendEntries RPC的定义
从严格意义上说这个可能算是2b的内容,因为是日志增量同步,但是对于leader选举后的心跳建立来讲,这又属于2a,固在此一起定义了。

// AppendEntriesArgs 由leader复制log条目,也可以当做是心跳连接,注释中的rf为leader节点
type AppendEntriesArgs struct {
Term int // leader的任期
LeaderId int // leader自身的ID
PrevLogIndex int // 预计要从哪里追加的index,因此每次要比当前的len(logs)多1 args初始化为:rf.nextIndex[i] - 1
PrevLogTerm int // 追加新的日志的任期号(这边传的应该都是当前leader的任期号 args初始化为:rf.currentTerm
Entries []LogEntry // 预计存储的日志(为空时就是心跳连接)
LeaderCommit int // leader的commit index指的是最后一个被大多数机器都复制的日志Index
}
type AppendEntriesReply struct {
Term int // leader的term可能是过时的,此时收到的Term用于更新他自己
Success bool // 如果follower与Args中的PreLogIndex/PreLogTerm都匹配才会接过去新的日志(追加),不匹配直接返回false
AppState AppendEntriesState // 追加状态
}
3.3 RequestVote RPC的定义

// RequestVoteArgs
// example RequestVote RPC arguments structure.
// field names must start with capital letters!
//
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int // 需要竞选的人的任期
CandidateId int // 需要竞选的人的Id
LastLogIndex int // 竞选人日志条目最后索引
LastLogTerm int // 候选人最后日志条目的任期号
}
// RequestVoteReply
// example RequestVote RPC reply structure.
// field names must start with capital letters!
// 如果竞选者任期比自己的任期还短,那就不投票,返回false
// 如果当前节点的votedFor为空,且竞选者的日志条目跟收到者的一样新则把票投给该竞选者
//
type RequestVoteReply struct {
// Your data here (2A).
Term int // 投票方的term,如果竞选者比自己还低就改为这个
VoteGranted bool // 是否投票给了该竞选人
VoteState VoteState // 投票状态
}
四、领导选举
在经历完成代码的之后,我觉得对于实现领导选举还是要多看看几遍文章前方的可视化过程。很多细节,可能在实际代码调试输出记录的时候才会知晓。对于我来说,我认为领导选举要注意的细节应该主要是来自于定时器对状态机影响。你需要考虑什么时候定时器需要重来,且重新来过之后对于每个节点的状态是个怎么样的改变。
4.1初始化raft节点
这部分就是比较常规的初始化了,直接上代码:
// Make
// the service or tester wants to create a Raft server. the ports
// of all the Raft servers (including this one) are in peers[]. this
// server's port is peers[me]. all the servers' peers[] arrays
// have the same order. persister is a place for this server to
// save its persistent state, and also initially holds the most
// recent saved state, if any. applyCh is a channel on which the
// tester or service expects Raft to send ApplyMsg messages.
// Make() must return quickly, so it should start goroutines
// for any long-running work.
//
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (2A, 2B, 2C).
// 对应论文中的初始化
rf.applyChan = applyCh //2B
rf.currentTerm = 0
rf.votedFor = -1
rf.logs = make([]LogEntry, 0)
rf.commitIndex = 0
rf.lastApplied = 0
rf.nextIndex = make([]int, len(peers))
rf.matchIndex = make([]int, len(peers))
rf.status = Follower
rf.overtime = time.Duration(150+rand.Intn(200)) * time.Millisecond // 随机产生150-350ms
rf.timer = time.NewTicker(rf.overtime)
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
//fmt.Printf("[ Make-func-rf(%v) ]: %v\n", rf.me, rf.overtime)
// start ticker goroutine to start elections
go rf.ticker()
return rf
}
4.2 Ticker(建立主体的心跳)
初始化的时候给每个timer设了一个overtime,并通过select监听,时间一过就根据其当前节点的status去进行选举/日志同步。
// raft的ticker(心脏)
// The ticker go routine starts a new election if this peer hasn't received
// heartsbeats recently.
func (rf *Raft) ticker() {
for rf.killed() == false {
// Your code here to check if a leader election should
// be started and to randomize sleeping time using
// 当定时器结束进行超时选举
select {
case <-rf.timer.C:
if rf.killed() {
return
}
rf.mu.Lock()
// 根据自身的status进行一次ticker
switch rf.status {
// follower变成竞选者
case Follower:
rf.status = Candidate
fallthrough
case Candidate:
// 初始化自身的任期、并把票投给自己
rf.currentTerm += 1
rf.votedFor = rf.me
votedNums := 1 // 统计自身的票数
// 每轮选举开始时,重新设置选举超时
rf.overtime = time.Duration(150+rand.Intn(200)) * time.Millisecond // 随机产生200-400ms
rf.timer.Reset(rf.overtime)
// 对自身以外的节点进行选举
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
voteArgs := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: len(rf.logs) - 1,
LastLogTerm: 0,
}
if len(rf.logs) > 0 {
voteArgs.LastLogTerm = rf.logs[len(rf.logs)-1].Term
}
voteReply := RequestVoteReply{}
go rf.sendRequestVote(i, &voteArgs, &voteReply, &votedNums)
}
case Leader:
// 进行心跳/日志同步
appendNums := 1 // 对于正确返回的节点数量
rf.timer.Reset(HeartBeatTimeout)
// 构造msg
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
appendEntriesArgs := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: 0,
PrevLogTerm: 0,
Entries: nil,
LeaderCommit: rf.commitIndex,
}
appendEntriesReply := AppendEntriesReply{}
//fmt.Printf("[ ticker(%v) ] : send a election to %v\n", rf.me, i)
go rf.sendAppendEntries(i, &appendEntriesArgs, &appendEntriesReply, &appendNums)
}
}
rf.mu.Unlock()
}
}
}
因为多看几遍领导选主,其实是可以发现。虽然是小概率事件,但是你可能会有多个timer的过期时间是相等的。那么就代表最后会有多个竞选者,这就会导致了可能最后情况会是票数一致,无法选出领导人。那么在可视化的动图里他其实选择的是重新进行一次选举,因为是小概率事件。
4.3投票RPC实现
对于这一部分其实论文也有具体的提到。

- 首先竞选者的任期必须,大于自己的任期。否则返回false。因为在出先网络分区时,可能两个分区分别产生了两个leader。那么我们认为应该是任期长的leader拥有的数据更完整。(在可视化中也有)。因此第二条就是,投票成功的前提的是,你自己的票要没投过给别人,且竞选者的日志状态要和你的一致。
- 还有一个要注意的点是当前rf节点发送到别的rf的节点的RPC框架中已经给出,为sendRequestVote方法。
如果原本自身是follower的话那么如果超时,就变成竞选者。对每个节点发送RPC投票请求。
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply, voteNums *int) bool {
if rf.killed() {
return false
}
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
for !ok {
// 失败重传
if rf.killed() {
return false
}
ok = rf.peers[server].Call("Raft.RequestVote", args, reply)
}
rf.mu.Lock()
defer rf.mu.Unlock()
//fmt.Printf("[ sendRequestVote(%v) ] : send a election to %v\n", rf.me, server)
// 由于网络分区,请求投票的人的term的比自己的还小,不给予投票
if args.Term < rf.currentTerm {
return false
}
// 对reply的返回情况进行分支处理
switch reply.VoteState {
// 消息过期有两种情况:
// 1.是本身的term过期了比节点的还小
// 2.是节点日志的条目落后于节点了
case Expire:
{
rf.status = Follower
rf.timer.Reset(rf.overtime)
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.votedFor = -1
}
}
case Normal, Voted:
//根据是否同意投票,收集选票数量
if reply.VoteGranted && reply.Term == rf.currentTerm && *voteNums <= (len(rf.peers)/2) {
*voteNums++
}
// 票数超过一半
if *voteNums >= (len(rf.peers)/2)+1 {
*voteNums = 0
// 本身就是leader在网络分区中更具有话语权的leader
if rf.status == Leader {
return ok
}
// 本身不是leader,那么需要初始化nextIndex数组
rf.status = Leader
rf.nextIndex = make([]int, len(rf.peers))
for i, _ := range rf.nextIndex {
rf.nextIndex[i] = len(rf.logs) + 1
}
rf.timer.Reset(HeartBeatTimeout)
//fmt.Printf("[ sendRequestVote-func-rf(%v) ] be a leader\n", rf.me)
}
case Killed:
return false
}
return ok
}
这边实现中要注意的一个点时,就是在本节开头强调的,你要注意的是你的状态要在什么时候进行重置。个人认为这个点应该在解耦合的时候,也就是在投票rpc的时候进行。因为当进行rpc的时候,基本情况下是谁先拉到多数票谁就有机会更早的成为leader。 那么就可以在你拉票的时候进行状态重置。因为先成为竞选者,先把自己的term就加一那么在一开始任期相同情况下该竞选者就会把其他raft进行重置。这一部分可以自己多进行打印输出。
// RequestVote
// example RequestVote RPC handler.
// 个人认为定时刷新的地方应该是别的节点与当前节点在数据上不冲突时就要刷新
// 因为如果不是数据冲突那么定时相当于防止自身去选举的一个心跳
// 如果是因为数据冲突,那么这个节点不用刷新定时是为了当前整个raft能尽快有个正确的leader
//
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
//defer fmt.Printf("[ func-RequestVote-rf(%+v) ] : return %v\n", rf.me, reply)
rf.mu.Lock()
defer rf.mu.Unlock()
// 当前节点crash
if rf.killed() {
reply.VoteState = Killed
reply.Term = -1
reply.VoteGranted = false
return
}
//reason: 出现网络分区,该竞选者已经OutOfDate(过时)
if args.Term < rf.currentTerm {
reply.VoteState = Expire
reply.Term = rf.currentTerm
reply.VoteGranted = false
return
}
if args.Term > rf.currentTerm {
// 重置自身的状态
rf.status = Follower
rf.currentTerm = args.Term
rf.votedFor = -1
}
//fmt.Printf("[ func-RequestVote-rf(%+v) ] : rf.voted: %v\n", rf.me, rf.votedFor)
// 此时比自己任期小的都已经把票还原
if rf.votedFor == -1 {
currentLogIndex := len(rf.logs) - 1
currentLogTerm := 0
// 如果currentLogIndex下标不是-1就把term赋值过来
if currentLogIndex >= 0 {
currentLogTerm = rf.logs[currentLogIndex].Term
}
// If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)
// 论文里的第二个匹配条件,当前peer要符合arg两个参数的预期
if args.LastLogIndex < currentLogIndex || args.LastLogTerm < currentLogTerm {
reply.VoteState = Expire
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
// 给票数,并且返回true
rf.votedFor = args.CandidateId
reply.VoteState = Normal
reply.Term = rf.currentTerm
reply.VoteGranted = true
rf.timer.Reset(rf.overtime)
//fmt.Printf("[ func-RequestVote-rf(%v) ] : voted rf[%v]\n", rf.me, rf.votedFor)
} else { // 只剩下任期相同,但是票已经给了,此时存在两种情况
reply.VoteState = Voted
reply.VoteGranted = false
// 1、当前的节点是来自同一轮,不同竞选者的,但是票数已经给了(又或者它本身自己就是竞选者)
if rf.votedFor != args.CandidateId {
// 告诉reply票已经没了返回false
return
} else { // 2. 当前的节点票已经给了同一个人了,但是由于sleep等网络原因,又发送了一次请求
// 重置自身状态
rf.status = Follower
}
rf.timer.Reset(rf.overtime)
}
return
}
也因此个人认为定时刷新的地方应该是别的节点与当前节点在数据上不冲突时就要刷新。因为如果不是数据冲突那么定时相当于防止自身去选举的一个心跳如果是因为数据冲突,那么这个节点不用刷新定时是为了当前整个raft能尽快有个正确的leader。
以及还有一个点就是在Kill里面也要进行Stop计时。
func (rf *Raft) Kill() {
atomic.StoreInt32(&rf.dead, 1)
// Your code here, if desired.
rf.mu.Lock()
rf.timer.Stop()
rf.mu.Unlock()
}
五、日志增量/心跳建立
5.1 心跳/日志增量RPC实现
同日志发送的RPC,其实不实现,统一留到lab2b也行。这里不实现也只是再test1报一个简单的warning。
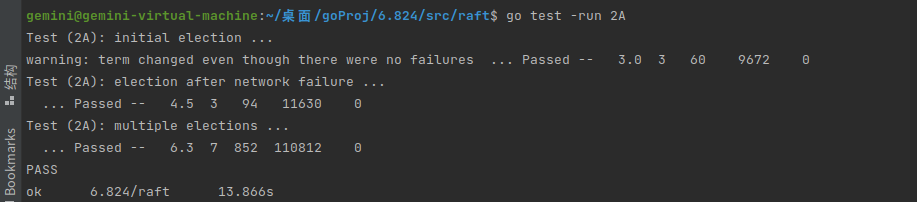
而对于消除这个warning其实严格意义上来讲只能算是重新发送一个ticker与个节点建立心跳,使得leader在不发生故障的情况下能够连任。
而这一部分实现也与前面相似,并逻辑并前面简单些。
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply, appendNums *int) bool {
if rf.killed() {
return false
}
// paper中5.3节第一段末尾提到,如果append失败应该不断的retries ,直到这个log成功的被store
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
for !ok {
if rf.killed() {
return false
}
ok = rf.peers[server].Call("Raft.AppendEntries", args, reply)
}
// 必须在加在这里否则加载前面retry时进入时,RPC也需要一个锁,但是又获取不到,因为锁已经被加上了
rf.mu.Lock()
defer rf.mu.Unlock()
// 对reply的返回状态进行分支
switch reply.AppState {
// 目标节点crash
case AppKilled:
{
return false
}
// 目标节点正常返回
case AppNormal:
{
// 2A的test目的是让Leader能不能连续任期,所以2A只需要对节点初始化然后返回就好
return true
}
//If AppendEntries RPC received from new leader: convert to follower(paper - 5.2)
//reason: 出现网络分区,该Leader已经OutOfDate(过时)
case AppOutOfDate:
// 该节点变成追随者,并重置rf状态
rf.status = Follower
rf.votedFor = -1
rf.timer.Reset(rf.overtime)
rf.currentTerm = reply.Term
}
return ok
}
// AppendEntries 建立心跳、同步日志RPC
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// 节点crash
if rf.killed() {
reply.AppState = AppKilled
reply.Term = -1
reply.Success = false
return
}
// 出现网络分区,args的任期,比当前raft的任期还小,说明args之前所在的分区已经OutOfDate
if args.Term < rf.currentTerm {
reply.AppState = AppOutOfDate
reply.Term = rf.currentTerm
reply.Success = false
return
}
// 对当前的rf进行ticker重置
rf.currentTerm = args.Term
rf.votedFor = args.LeaderId
rf.status = Follower
rf.timer.Reset(rf.overtime)
// 对返回的reply进行赋值
reply.AppState = AppNormal
reply.Term = rf.currentTerm
reply.Success = true
return
}
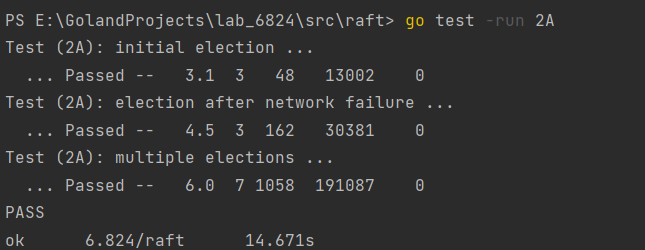
5.2 Test情况
allpast
六、DeBug杂谈
因为lab2b这次的lab2a也算是做了两次了。而第二次的写代码包括debug总共花了4、5个小时。我想后面一次做的快应该是因为debug日志可能相比lab1更格式化、或者说是更清晰了。在这里我推荐在lab2中的debug可以采用
[ 函数名字+自身节点id]+想要输出的结果。
fmt.Printf("[ func-RequestVote-rf(%+v) ] : rf.voted: %v\n", rf.me, rf.votedFor)
类似于这种的方式、并且在某个完整逻辑分割处进行分割。这样总体的结果也会比较清晰。
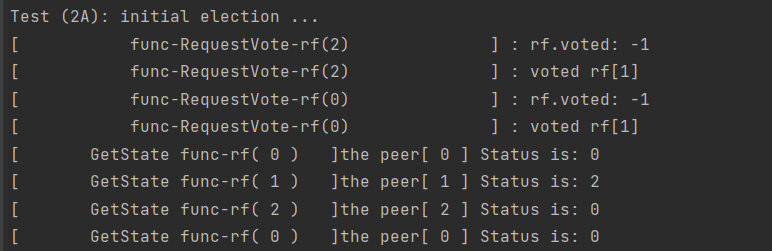
这种做法也是lab2b debug试出来的(早上9点debug到晚上两点…实在忍不住了回来重推了lab1 orz…)。实际上确实对lab1的pass速度比第一次没有格式化的方式确实快了很多。当然你也可以根据官方的debug指北或者是util中的Dprint找到自己合适的debug方式。
对于本次lab2a 的话只要保证在三个test中选举流程保证有一个leader,并且通过日志发现符合自己的选举预期,基本都能过。我自己的bug在test2 的故障test中,在sendRequestVote中的lock上到retries后面,导致上了锁后继续获取锁,导致了死锁。通过每个函数的日志打印也很快的发现了
。
总结
在经历lab1的适应后对于lab2A还是较简单的,但是对于test中其实并不能test出你代码的漏洞,就像我之前没把票数之前一轮清0。照样是通过了所有test。但是做lab2b的时候就非常痛苦,导致我来做了第二次lab2a。而且c、d也是基于前两次lab 还是应该要多在关键的地方如RPC的时候多打印下自己节点情况,最重要的是完成自己预期的实现。如有不足,欢迎指正。
gitee地址,如果觉得有帮助可以帮忙给个star~,以及如果后续Lab对此lab有进行修改,请参考master最新分支。
















 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











