






开始
官方的文档写的实在是少,走了不少弯路,特此记录下来,供需要的人做个参考吧。
步骤
创建maven工程
注意这里是创建空工程,不是下面那个maven,那个试了半天没成功过。
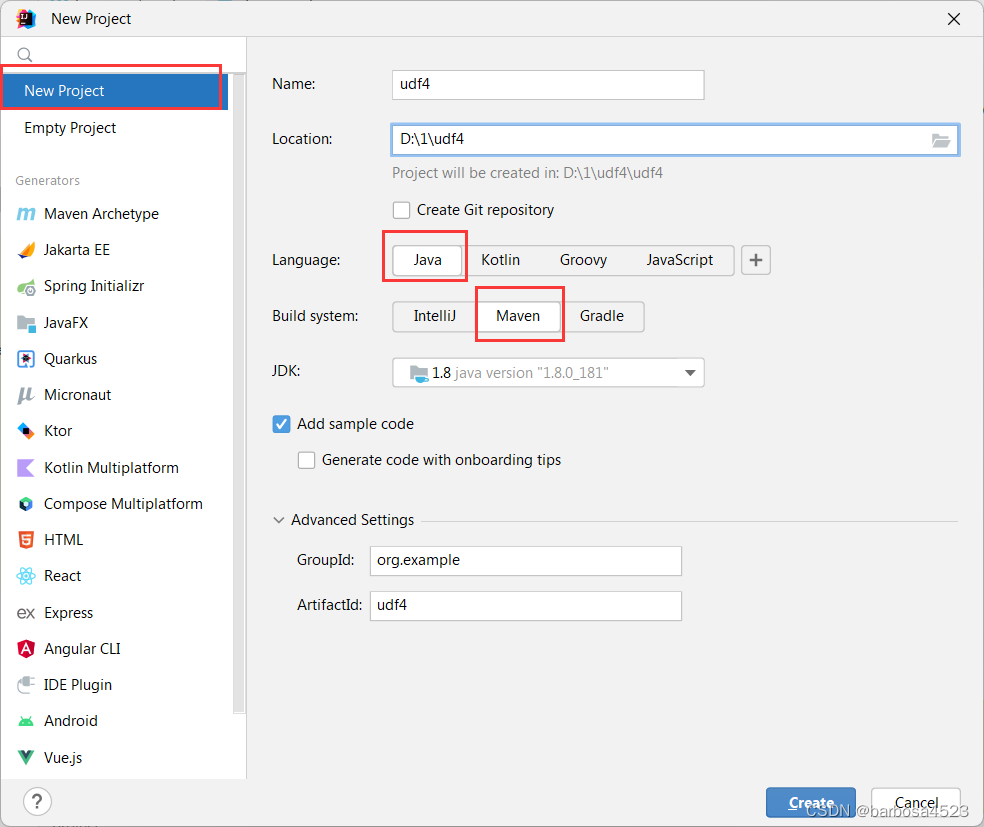
点create
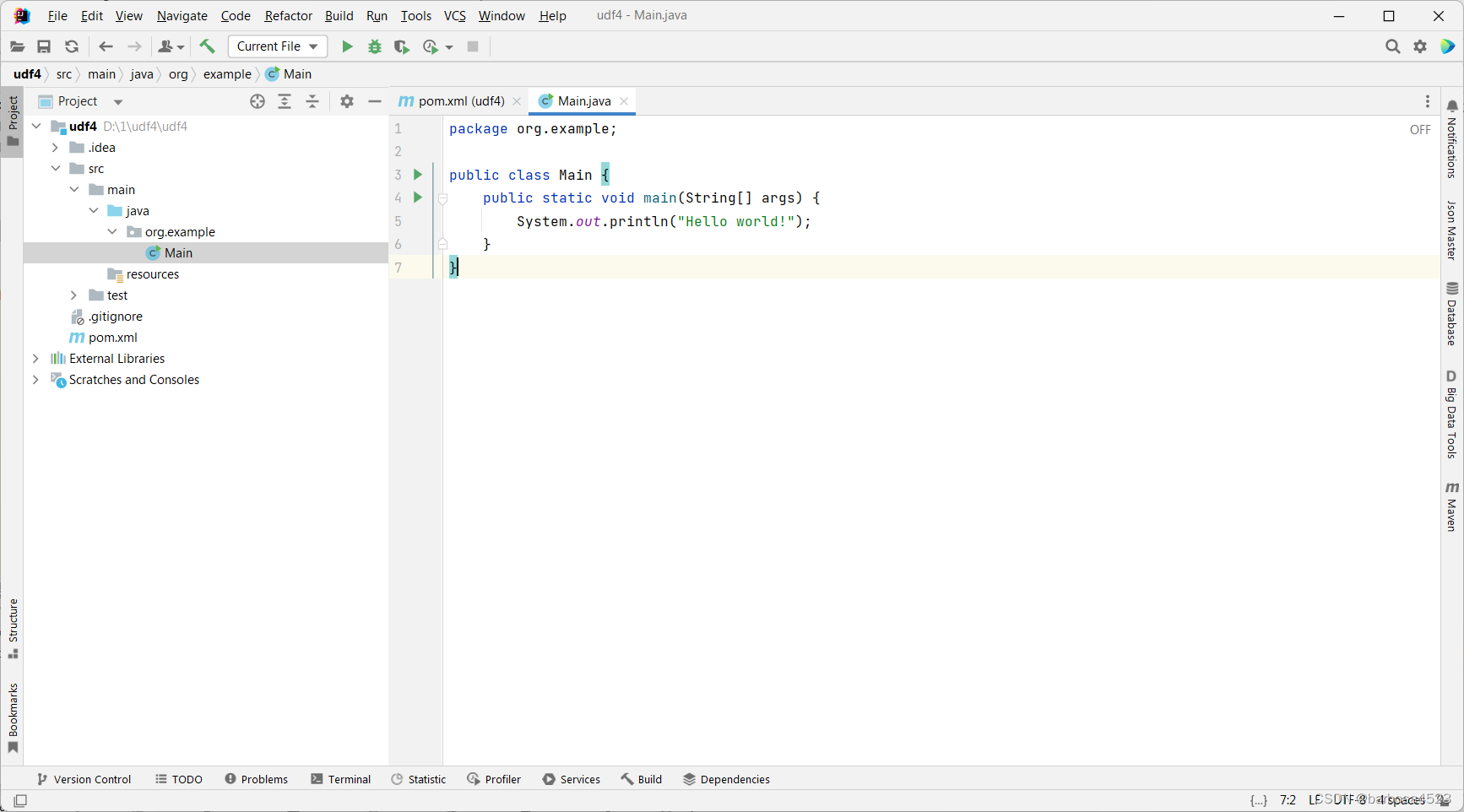
然后删掉这个main,自己创建一个类,起名qdmxUDF
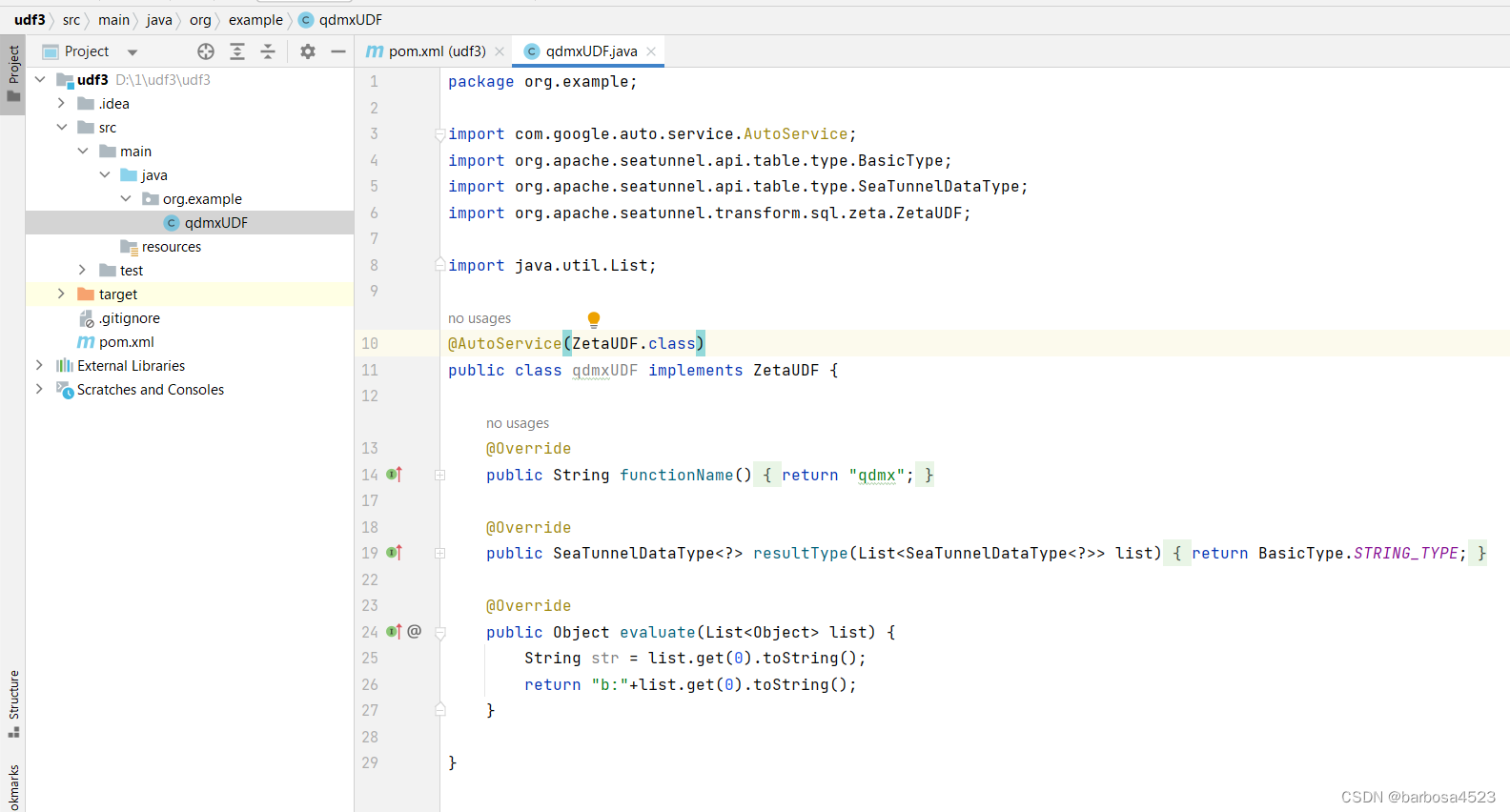
代码如下:
package org.example;
import com.google.auto.service.AutoService;
import org.apache.seatunnel.api.table.type.BasicType;
import org.apache.seatunnel.api.table.type.SeaTunnelDataType;
import org.apache.seatunnel.transform.sql.zeta.ZetaUDF;
import java.util.List;
@AutoService(ZetaUDF.class)
public class qdmxUDF implements ZetaUDF {
@Override
public String functionName() {
return "qdmx";
}
@Override
public SeaTunnelDataType<?> resultType(List<SeaTunnelDataType<?>> list) {
return BasicType.STRING_TYPE;
}
@Override
public Object evaluate(List<Object> list) {
String str = list.get(0).toString();
return "b:"+list.get(0).toString();
}
}
pom.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>udf3</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.seatunnel</groupId>
<artifactId>seatunnel-transforms-v2</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.seatunnel</groupId>
<artifactId>seatunnel-api</artifactId>
<version>2.3.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.0.1</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-site-plugin</artifactId>
<version>3.7</version>
<dependencies>
<dependency>
<groupId>org.apache.maven.doxia</groupId>
<artifactId>doxia-site-renderer</artifactId>
<version>1.8</version>
</dependency>
</dependencies>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>com.google.auto.service</groupId>
<artifactId>auto-service</artifactId>
<version>1.1.1</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>
</build>
</project>
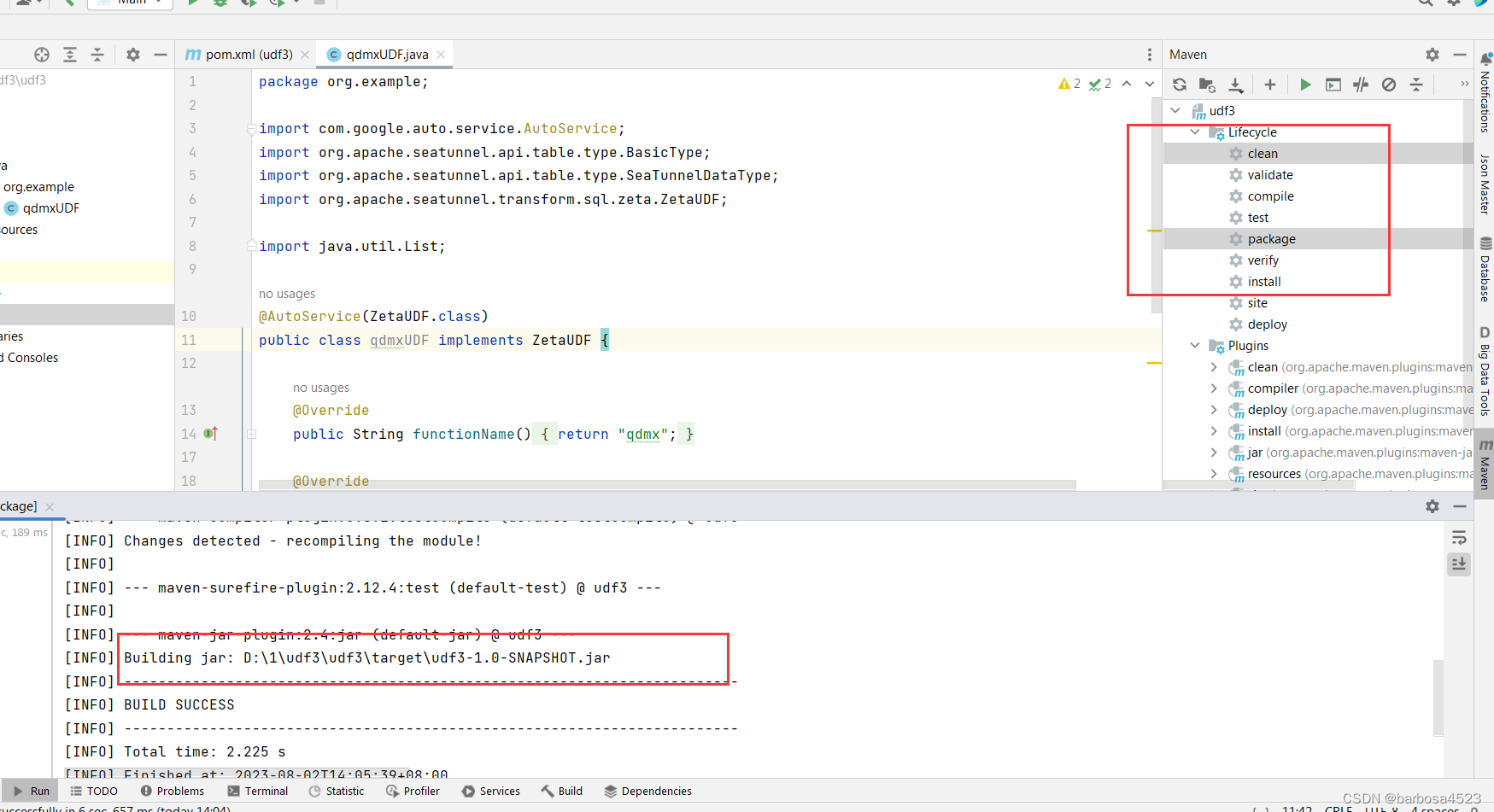
然后打包:
seatunnel 测试
seatunnel环境
下载
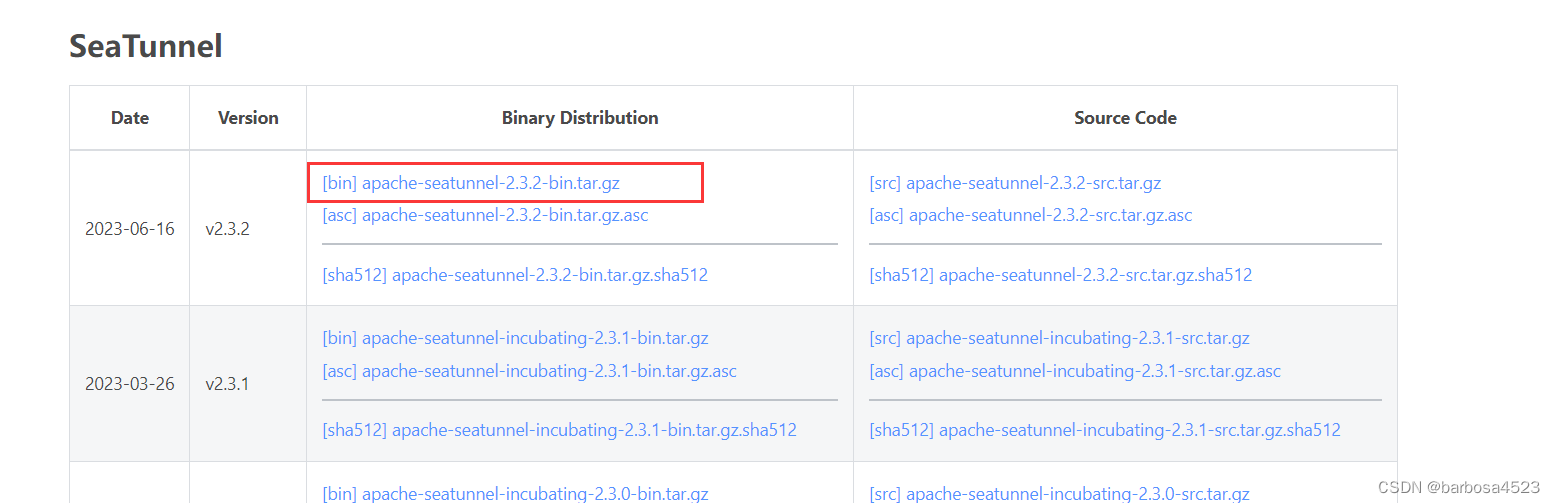
解压到/opt/
tar xzvf /路径/apache-seatunnel-2.3.2-bin.tar.gz
mv apache-seatunnel-2.3.2 /opt
创建job目录
cd /opt/apache-seatunnel-2.3.2
mkdir job
clickhouse测试表
附上ck测试表ddl
CREATE TABLE default.tt1
(
`id` Int8,
`name` String
)
ENGINE = MergeTree
ORDER BY id
表数据:
select * from tt1
| id | name |
|---|---|
| 1 | tom |
| 2 | jeff |
上传各种jar
将刚才打包的jar,上传到lib目录下,此目录和job同级。
另外还需要下载connector插件,请到connector自行下载。
附上我的seatunnel目录树
├── bin
│ ├── install-plugin.sh
│ ├── seatunnel-cluster.sh
│ ├── seatunnel.sh
│ ├── start-seatunnel-flink-13-connector-v2.sh
│ ├── start-seatunnel-flink-15-connector-v2.sh
│ ├── start-seatunnel-spark-2-connector-v2.sh
│ ├── start-seatunnel-spark-3-connector-v2.sh
│ └── stop-seatunnel-cluster.sh
├── config
│ ├── hazelcast-client.yaml
│ ├── hazelcast.yaml
│ ├── jvm_client_options
│ ├── jvm_options
│ ├── log4j2_client.properties
│ ├── log4j2.properties
│ ├── plugin_config
│ ├── seatunnel-env.sh
│ ├── seatunnel.yaml
│ ├── v2.batch.config.template
│ └── v2.streaming.conf.template
├── connectors
│ ├── plugin-mapping.properties
│ └── seatunnel
│ ├── connector-cdc-mysql-2.3.2.jar
│ ├── connector-clickhouse-2.3.2.jar
│ ├── connector-console-2.3.2.jar
│ ├── connector-doris-2.3.2.jar
│ ├── connector-fake-2.3.2.jar
│ ├── connector-file-local-2.3.2.jar
│ └── connector-jdbc-2.3.2.jar
├── DISCLAIMER
├── job
│ └── ck2_local.conf
├── lib
│ ├── seatunnel-hadoop3-3.1.4-uber-2.3.2-optional.jar
│ ├── seatunnel-transforms-v2.jar
│ └── udf3-1.0-SNAPSHOT.jar
├── LICENSE
├── licenses
│ ├── LICENSE-asm.txt
│ ├── LICENSE-avro.txt
│ ├── LICENSE-connons-math.txt
│ ├── LICENSE-javax-annootation-api.txt
│ ├── LICENSE-orc.txt
│ ├── LICENSE-parquet-format.txt
│ ├── LICENSE-parquet-mr.txt
│ ├── LICENSE-protobuf.txt
│ ├── LICENSE-scala.txt
│ ├── LICENSE-sjf4j.txt
│ ├── LICENSE-xz.txt
│ └── LICENSE-yetus.txt
├── logs
│ ├── seatunnel-engine-server.log
│ └── seatunnel-server.out
├── mvnw
├── mvnw.cmd
├── NOTICE
├── plugins
│ └── README.md
├── README.md
└── starter
├── logging
│ ├── jcl-over-slf4j-1.7.25.jar
│ ├── log4j-api-2.17.1.jar
│ ├── log4j-core-2.17.1.jar
│ ├── log4j-slf4j-impl-2.17.1.jar
│ └── slf4j-api-1.7.25.jar
├── seatunnel-flink-13-starter.jar
├── seatunnel-flink-15-starter.jar
├── seatunnel-spark-2-starter.jar
├── seatunnel-spark-3-starter.jar
└── seatunnel-starter.jar
运行测试任务
在job目录下创建测试任务
vim ck2_local.conf
-- 填入以下内容,请根据实际情况修改
env {
execution.parallelism = 1
job.mode = "BATCH"
}
source {
Clickhouse {
host = "192.168.9.103:8123"
database = "default"
username = "root"
password = "1234567"
sql = "select id, name from default.tt1 "
result_table_name = "fake"
}
}
transform {
Sql {
source_table_name = "fake"
result_table_name = "fake1"
query = "select id, qdmx(name) as name from fake"
}
}
sink {
LocalFile {
source_table_name = "fake1"
path = "/root/c2"
file_format = "text"
field_delimiter = "\t"
row_delimiter = "\n"
custom_filename = true
}
}
保存,退出。
运行测试任务,在seatunnel目录下执行:
[root@localhost seatunnel-2.3.2]# ./bin/seatunnel.sh --config job/ck2_local.conf -m local
在/root/c2目录下,看到输出文件:
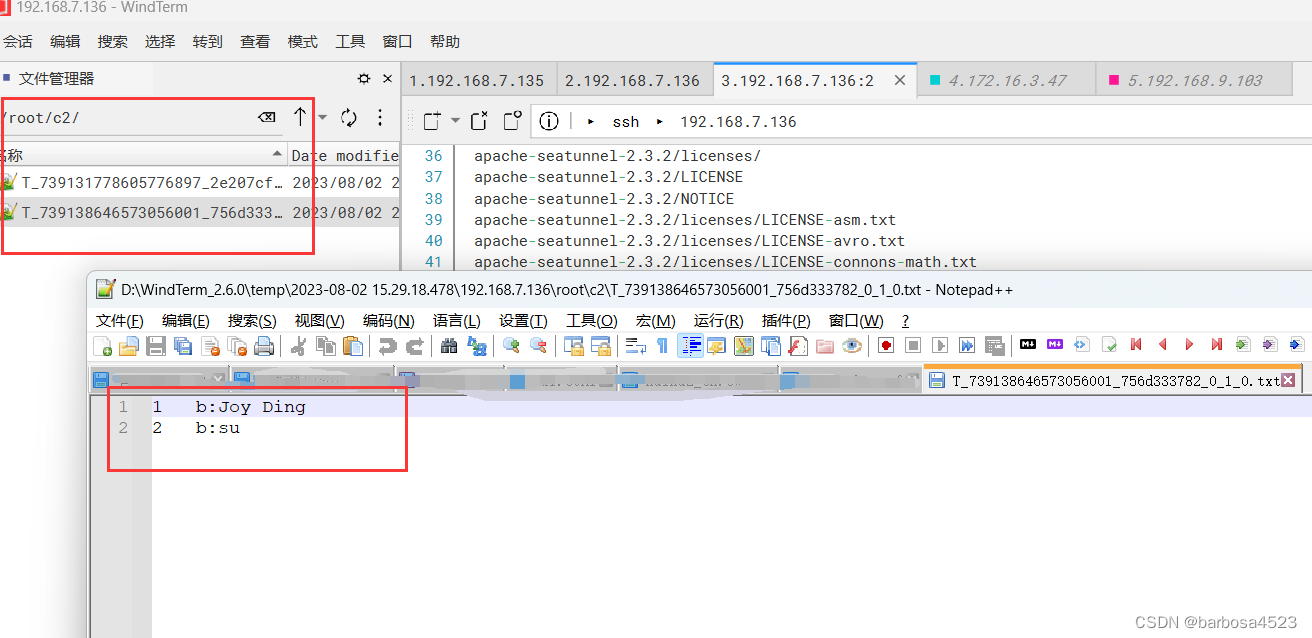
齐活。















 746
746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









