









四、Scikit-learn的应用(创建用户分类)
4.1 实验介绍
实验准备
请到04 finding_segments文件目录下开始实验。
项目背景
在这个项目中,你将分析一个数据集的内在结构,这个数据集包含很多客户针对不同类型产品的年度采购额(用金额表示)。这个项目的任务之一是如何最好地描述一个批发商不同种类顾客之间的差异。这样做将能够使得批发商能够更好的组织他们的物流服务以满足每个客户的需求。
这个项目的数据集能够在UCI机器学习信息库中找到.因为这个项目的目的,分析将不会包括’Channel’和’Region’这两个特征——重点集中在6个记录的客户购买的产品类别上。
4.2 导入数据
运行下面的的代码单元以载入整个客户数据集和一些这个项目需要的Python库。如果你的数据集载入成功,你将看到后面输出数据集的大小。
# 引入项目需要的库
import numpy as np
import pandas as pd
import visuals as vs
import matplotlib as mpl
# 可以对DataFrame使用display()函数
from IPython.display import display
# 设置以inline的形式显示matplotlib绘制的图片(在notebook中显示更美观)
%matplotlib inline
# 设置matplotlib中文显示
mpl.rcParams['font.family'] = 'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
# 载入整个客户集
try:
data = pd.read_csv('customers.csv')
data.drop(['Region','Channel'], axis=1, inplace=True)
print('批发客户数据集有 {} 个样本,每个样本有 {} 个特征。'.format(*data.shape))
except:
print('数据集无法加载,数据集丢失了吗?')
批发客户数据集有 440 个样本,每个样本有 6 个特征。
4.3 分析数据
分析数据
在这部分,你将开始分析数据,通过可视化和代码来理解每一个特征和其他特征的联系。你会看到关于数据集的统计描述,考虑每一个属性的相关性,然后从数据集中选择若干个样本数据点,你将在整个项目中一直跟踪研究这几个数据点。
运行下面的代码单元给出数据集的一个统计描述。注意这个数据集包含了6个重要的产品类型:
- ’Fresh’ - 果蔬
- ’Milk’ - 牛奶
- ’Grocery’ - 杂货
- ’Frozen’ - 冷冻食品
- ’Detergents_Paper’ - 卫生用品
- ’Delicatessen’ - 熟食
想一下这里每一个类型代表你会购买什么样的产品。
# 显示数据集的一个描述
display(data.describe())
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NFPpx68J-1627009147239)(四、Scikit-learn的应用(创建用户分类)].assets/ML_04_01.png)
选择样本
为了对客户有一个更好的了解,并且了解代表他们的数据将会在这个分析过程中如何变换。最好是选择几个样本数据点,并且更为详细地分析它们。在下面的代码单元中,选择三个索引加入到索引列表indices中,这三个索引代表你要追踪的客户。我们建议你不断尝试,直到找到三个明显不同的客户。
# TODO:从数据集中选择三个你希望抽样的数据点的索引
indices = [29,23,333]
print(data.index)
# 为选择的样本建立一个DataFrame
samples = pd.DataFrame(data.loc[indices], columns=data.keys()).reset_index(drop=True)
print('选择批发客户数据集的样本:')
display(samples)
benchmark = data.mean()
z = ((samples-benchmark)/benchmark)
z.columns = ['果蔬','牛奶','杂货','冷冻食品','卫生用品','熟食']
z.plot.bar(figsize=(10,4))

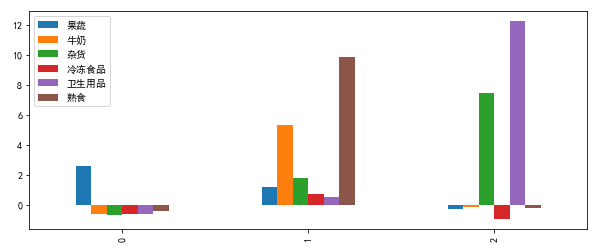
考虑你上面选择的客户的每一种产品类型的总花费和数据集的统计描述。
- 第一个客户很可能是餐厅。
- 果蔬
Fresh产品进货数量超多,高于这类产品的75%分位数 - 其他类型的货品则很少,低于这些类型产品的中位数
- 果蔬
- 第二个客户很可能是超市。
- 每一类货品进货数量都超过中位数,而且较为平均
- 第三个客户很有可能是杂货店。
- 杂货
Grocery和卫生用品Detergents_Paper产品进货数量超多,高于这两类产品的75%分位数。
- 杂货
4.4 特征相关性
特征相关性
一个有趣的想法是,考虑这六个类别中的一个(或者多个)产品类别,是否对于理解客户的购买行为具有实际的相关性。也就是说,当用户购买了一定数量的某一类产品,我们是否能够确定他们必然会成比例地购买另一种类的产品。
通过简单地使用监督学习的算法,我们能够通过在移除某一个特征的数据子集上构建一个有监督的回归学习器,然后判断这个模型对于移除特征的预测得分,通过这种方法我们能检验上面的假设。
在下面的代码单元中,实现以下的功能:
-
使用
DataFrame.drop()函数移除数据集中你选择的不需要的特征,并将移除后的结果赋值给new_data。 -
使用
sklearn.cross_validation.train_test_split()将数据集分割成训练集和测试集。
- 使用移除的特征作为你的目标标签。设置
test_size为0.25并设置一个random_state。
- 使用移除的特征作为你的目标标签。设置
-
导入一个决策树回归器,设置一个
random_state,然后用训练集训练它。 -
使用回归器的
score()函数输出模型在测试集上的预测得分。
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import r2_score
test_feature = 'Fresh'
new_data = pd.DataFrame(data)
label_data = new_data[test_feature]
new_data.drop([test_feature],axis=1,inplace=True)
X_train, X_test, y_train, y_test = train_test_split(
new_data, label_data, test_size=0.25, random_state=1)
regressor = DecisionTreeRegressor(random_state=1)
regressor.fit(X_train,y_train)
pred = regressor.predict(X_test)
score = r2_score(y_test,pred)
print(score)
结果:-0.9233736592978437
可视化特征分布
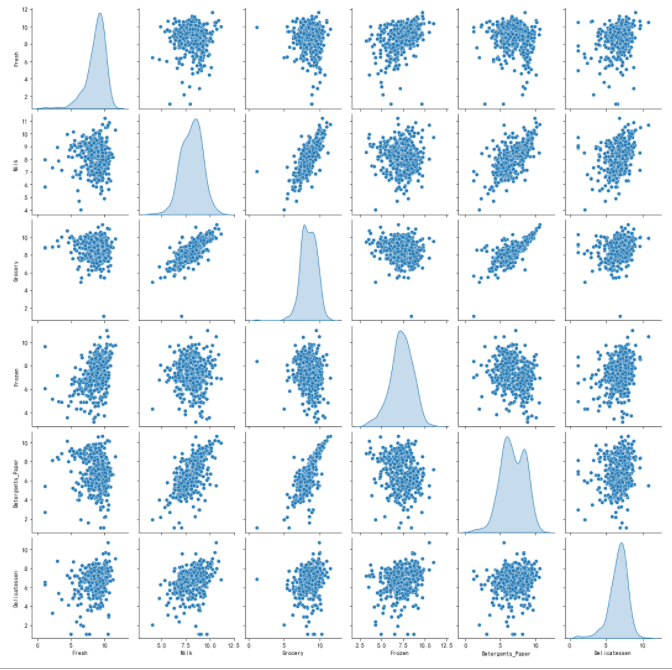
为了能够对这个数据集有一个更好的理解,我们可以对数据集中的每一个产品特征构建一个散布矩阵(scatter matrix)。如果你发现你在上面尝试预测的特征对于区分一个特定的用户来说是必须的,那么这个特征和其它的特征可能不会在下面的散射矩阵中显示任何关系。相反的,如果你认为这个特征对于识别一个特定的客户是没有作用的,那么通过散布矩阵可以看出在这个数据特征和其它特征中有关联性。运行下面的代码以创建一个散布矩阵。
# 对于数据中的每一对特征构造一个散布矩阵
pd.plotting.scatter_matrix(data,alpha=0.3,figsize=(14,8),diagonal='kde');
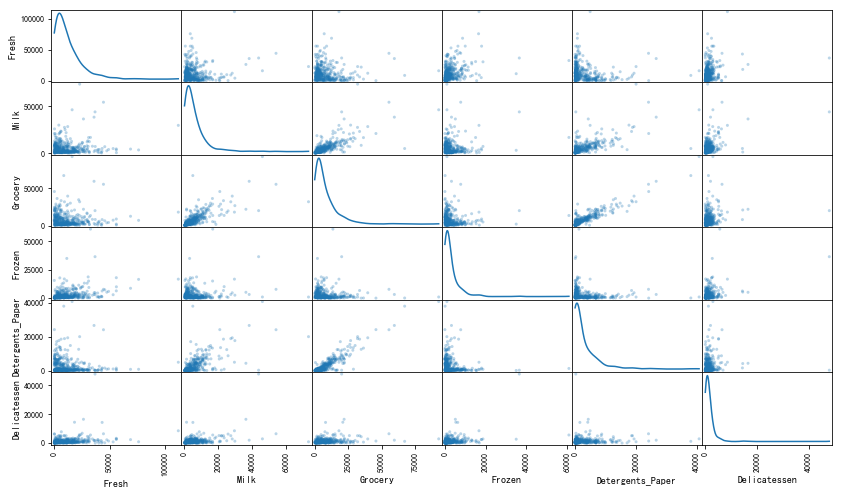
# 对于数据中的每一对特征构造一个散布矩阵
import seaborn as sns
sns.pairplot(data,diag_kind='kde')
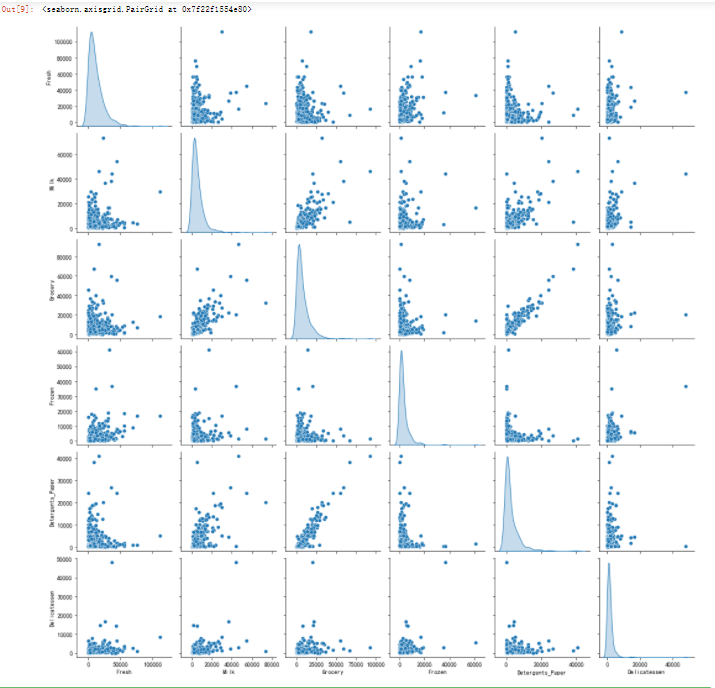
Detergents_Paper、Grocery和Milk相互之间呈现出一定的相关性。- 这个结果验证了之前尝试测试的特征
Fresh和其他特征之间无明显的相关性。 - 所有的特征均呈现正偏态分布,大多数的数据点位于25%分位数以下。
数据预处理
在这个部分,您将通过在数据上做一个合适的缩放,并检测异常点(你可以选择性移除)将数据预处理成一个更好的代表客户的形式。预处理数据是保证你在分析中能够得到显著且有意义的结果的重要环节。
特征缩放
如果数据不是正态分布的,尤其是数据的平均数和中位数相差很大的时候(表示数据非常歪斜)。这时候通常用一个非线性的缩放是很合适的, — 尤其是对于金融数据。
一种实现这个缩放的方法是使用 Box-Cox 变换,这个方法能够计算出能够最佳减小数据倾斜的指数变换方法。一个比较简单的并且在大多数情况下都适用的方法是使用自然对数。
在下面的代码单元中,需要实现以下功能:
- 使用
np.log()函数在数据data上做一个对数缩放,然后将它的副本(不改变原始data的值)赋值给log_data。 - 使用
np.log()函数在样本数据samples上做一个对数缩放,然后将它的副本赋值给log_samples。
import copy
# TODO:使用自然对数缩放数据
log_data = np.log(copy.copy(data))
# TODO:使用自然对数缩放样本数据
log_samples = np.log(copy.copy(samples))
# 为每一对新产生的特征制作一个散射矩阵
pd.plotting.scatter_matrix(log_data,alpha=0.3,figsize=(14,8),diagonal='kde');
sns.pairplot(log_data,diag_kind='kde')
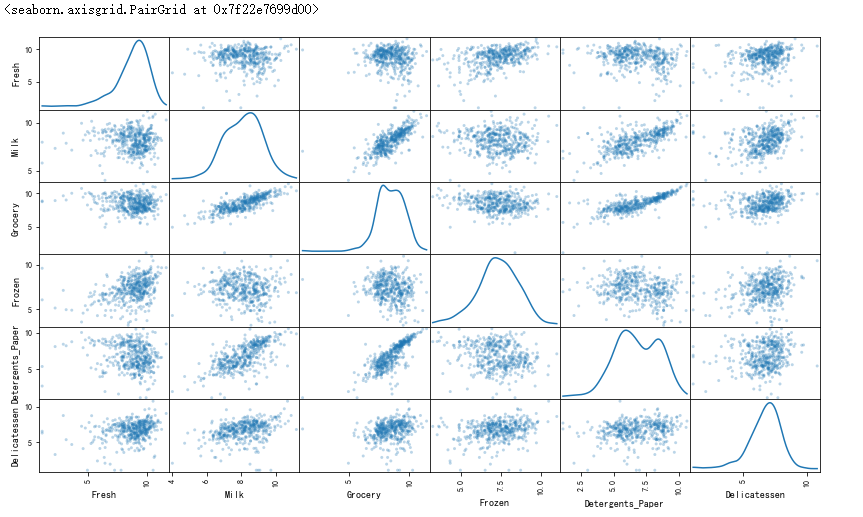
观察
在使用了一个自然对数的缩放之后,数据的各个特征会显得更加的正态分布。对于任意的你以前发现有相关关系的特征对,观察他们的相关关系是否还是存在的(并且尝试观察,他们的相关关系相比原来是变强了还是变弱了)。
运行下面的代码以观察样本数据在进行了自然对数转换之后如何改变了。
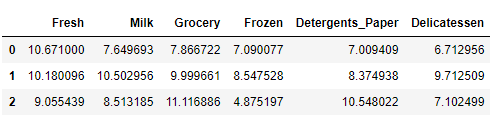
# 展示经过对数变换后的样本数据
display(log_samples)
异常值检测
对于任何的分析,在数据预处理的过程中检测数据中的异常值都是非常重要的一步。异常值的出现会使得把这些值考虑进去后结果出现倾斜。这里有很多关于怎样定义什么是数据集中的异常值的经验法则。
这里我们将使用Tukey的定义异常值的方法:一个异常阶(outlier step)被定义成1.5倍的四分位距(interquartile range,IQR)。
一个数据点如果某个特征包含在该特征的IQR之外的特征,那么该数据点被认定为异常点。
在下面的代码单元中,需要完成下面的功能:
- 将指定特征的25th分位点的值分配给
Q1。使用np.percentile()来完成这个功能。 - 将指定特征的75th分位点的值分配给
Q3。同样的,使用np.percentile()来完成这个功能。 - 将指定特征的异常阶的计算结果赋值给
step。 - 选择性地通过将索引添加到
outliers列表中,以移除异常值。
**注意:**如果你选择移除异常值,请保证你选择的样本点不在这些移除的点当中!
一旦你完成了这些功能,数据集将存储在good_data中。
# 对于每一个特征,找到值异常高或者是异常低的数据点
for feature in log_data.keys():
# TODO: 计算给定特征的Q1 (数据的25%分位点)
Q1 = np.percentile(log_data[feature],25)
# TODO: 计算给定特征的Q3 (数据的75%分位点)
Q3 = np.percentile(log_data[feature],75)
# TODO: 使用四分位计算异常阶 (1.5倍的四分位距)
step = 1.5 * (Q3 - Q1)
# 现实异常点
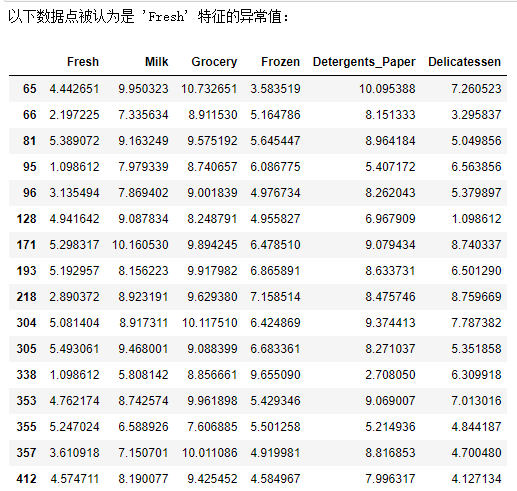
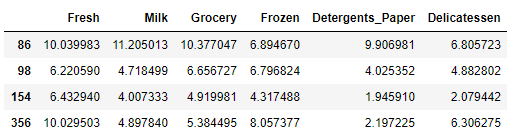
print("以下数据点被认为是 '{}' 特征的异常值:".format(feature))
inliers = (log_data[feature] >= Q1 - step) & (log_data[feature] <= Q3 + step)
outliers_data = log_data[~inliers]
display(outliers_data)
# 可选:选择你希望移除的数据点的索引
outliers = [38, 57, 65, 66, 75, 81, 86, 95, 96, 98, 109, 128, 137, 142, 145,
154, 161, 171, 175, 183, 184, 187, 193, 203, 218, 233, 264, 285,
289, 304, 305, 325, 338, 343, 353, 355, 356, 357, 412, 420, 429,
439]
# 如果选择了的话,移除异常点
good_data = log_data.drop(log_data.index[outliers]).reset_index(drop=True)
以下数据点被认为是 ‘Fresh’ 特征的异常值:
以下数据点被认为是 ‘Milk’ 特征的异常值:
以下数据点被认为是 ‘Grocery’ 特征的异常值:

以下数据点被认为是 ‘Frozen’ 特征的异常值:
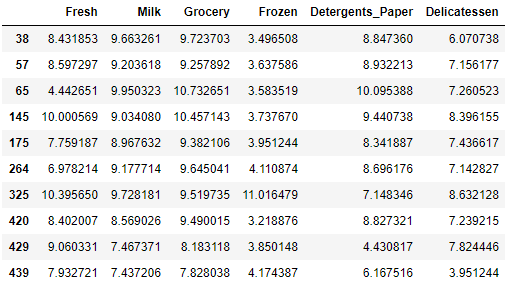
以下数据点被认为是 ‘Detergents_Paper’ 特征的异常值:

以下数据点被认为是 ‘Delicatessen’ 特征的异常值:
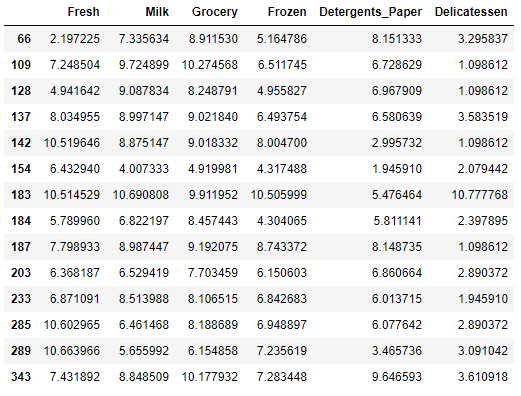
import matplotlib.pyplot as plt
z0 = (log_data - log_data.median())/(log_data.quantile(.75) - log_data.quantile(.25))
z1 = z0[(z0<=-2).any(axis=1)|(z0>=2).any(axis=1)]
z1.plot(figsize=(15,5),kind='bar')
plt.axhline(2, linewidth=0.2,color='k')
plt.axhline(-2, linewidth=0.2,color='k')
print(list(z1.index))

特征转换
在这个部分中你将使用主成分分析(PCA)来分析批发商客户数据的内在结构。由于使用PCA在一个数据集上会计算出最大化方差的维度,我们将找出哪一个特征组合能够最好的描绘客户。
主成分分析(PCA)
既然数据被缩放到一个更加正态分布的范围中并且我们也移除了需要移除的异常点,我们现在就能够在good_data上使用PCA算法以发现数据的哪一个维度能够最大化特征的方差。
除了找到这些维度,PCA也将报告每一个维度的_解释方差比(explained variance ratio)_–这个数据有多少方差能够用这个单独的维度来解释。
注意PCA的一个组成部分(维度)能够被看做这个空间中的一个新的“特征”,但是它是原来数据中的特征构成的。
在下面的代码单元中,将要实现下面的功能:
- 导入
sklearn.decomposition.PCA并且将good_data用PCA()函数并且使用6个维度进行拟合后的结果保存到pca中。 - 使用
pca.transform()函数将log_samples进行转换,并将结果存储到pca_samples中。
from sklearn.decomposition import PCA
# TODO: 通过在 good_data 上使用 PCA(),将其转换成和当前特征数一样多的维度
pca = PCA(n_components=6)
pca.fit(good_data)
# TODO: 使用上面的PCA拟合将变换施加在log_samples上
pca_samples = pca.transform(log_samples)
# 生产PCA的结果图
pca_results = vs.pca_results(good_data, pca)
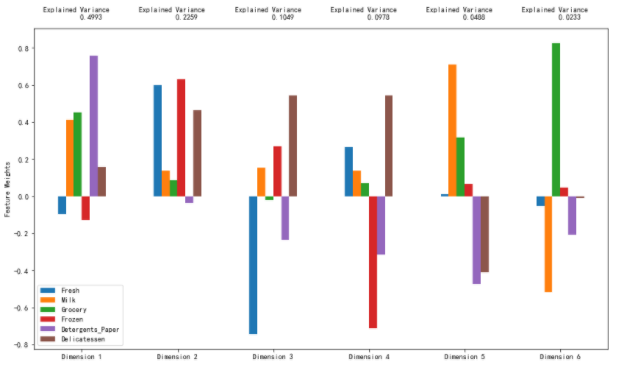
观察
运行下面的代码,查看经过对数转换的样本数据在进行一个6个维度的主成分分析(PCA)之后会如何改变。观察样本数据的前四个维度的数值。考虑这和你初始对样本点的解释是否一致
# 展示经过PCA转换的sample log-data
display(pd.DataFrame(np.round(pca_samples,4),columns=pca_results.index.values))

降维
当使用主成分分析的时候,一个主要的目的是减少数据的维度,这实际上降低了问题的复杂度。当然降维也是需要一定代价的:更少的维度能够表示的数据中的总方差更少。
因为这个,_累计解释方差比(cumulative explained variance ratio)_对于我们确定这个问题需要多少维度非常重要。另外,如果大部分的方差都能够通过两个或者是三个维度进行表示的话,降维之后的数据能够被可视化。
在下面的代码单元中,将实现下面的功能:
- 将
good_data用两个维度的PCA进行拟合,并将结果存储到pca中去。 - 使用
pca.transform将good_data进行转换,并将结果存储在reduced_data中。 - 使用
pca.transform将log_samples进行转换,并将结果存储在pca_samples中。
# TODO:通过在good data上进行PCA,将其转换成两个维度
pca = PCA(n_components=2)
pca.fit(good_data)
# TODO:使用上面训练的PCA将good data进行转换
reduced_data = pca.transform(good_data)
# TODO:使用上面训练的PCA将log_samples进行转换
pca_samples = pca.transform(log_samples)
# 为降维后的数据创建一个DataFrame
reduced_data = pd.DataFrame(reduced_data, columns = ['Dimension 1', 'Dimension 2'])
观察
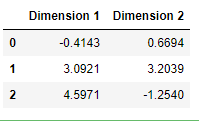
运行以下代码观察当仅仅使用两个维度进行PCA转换后,这个对数样本数据将怎样变化。观察这里的结果与一个使用六个维度的PCA转换相比较时,前两维的数值是保持不变的。
# 展示经过两个维度的PCA转换之后的样本log-data
display(pd.DataFrame(np.round(pca_samples, 4), columns = ['Dimension 1', 'Dimension 2']))
4.5 机器学习聚类算法
聚类
在这个部分,你讲选择使用K-Means聚类算法或者是高斯混合模型聚类算法以发现数据中隐藏的客户分类。然后,你将从簇中恢复一些特定的关键数据点,通过将它们转换回原始的维度和规模,从而理解他们的含义。
创建聚类
针对不同情况,有些问题你需要的聚类数目可能是已知的。但是在聚类数目不作为一个 先验 知道的情况下,我们并不能够保证某个聚类的数目对这个数据是最优的,因为我们对于数据的结构(如果存在的话)是不清楚的。但是,我们可以通过计算每一个簇中点的 轮廓系数 来衡量聚类的质量。数据点的轮廓系数衡量了它与分配给他的簇的相似度,这个值范围在-1(不相似)到1(相似)。平均 轮廓系数为我们提供了一种简单地度量聚类质量的方法。
在接下来的代码单元中,将实现下列功能:
- 在
reduced_data上使用一个聚类算法,并将结果赋值到clusterer。 - 使用
clusterer.predict()函数预测reduced_data中的每一个点的簇,并将结果赋值到preds。 - 使用算法的某个属性值找到聚类中心,并将它们赋值到
centers。 - 预测
pca_samples中的每一个样本点的类别并将结果赋值到sample_preds。 - 导入
sklearn.metrics.silhouette_score包并计算reduced_data相对于preds的轮廓系数。 - 将轮廓系数赋值给
score并输出结果。
from sklearn.mixture import GaussianMixture
from sklearn.metrics import silhouette_score
# TODO: 在降维后的数据上使用您选择的聚类算法
for i in [2]:
clusterer = GaussianMixture(n_components=i,random_state=3)
clusterer.fit(reduced_data)
# TODO: 预测每一个点的簇
preds = clusterer.predict(reduced_data)
# TODO: 找到聚类的中心点
centers = clusterer.means_
# TODO: 预测在每一个转换后的样本点的类
sample_preds = clusterer.predict(pca_samples)
# TODO: 计算选择的类别的平均轮廓系数 (mean silhouette coefficient)
score = silhouette_score(reduced_data, preds)
print(i,score)
2 0.446753526944537
聚类可视化
一旦你选好了通过上面的评价函数得到的算法的最佳聚类数目,你就能够通过使用下面的代码块可视化来得到的结果。作为实验,你可以试着调整你的聚类算法的聚类的数量来看一下不同的可视化结果。但是你提供的最终的可视化图像必须和你选择的最优聚类数目一致。
# 从已有的实现中展示聚类的结果
vs.cluster_results(reduced_data, preds, centers, pca_samples)
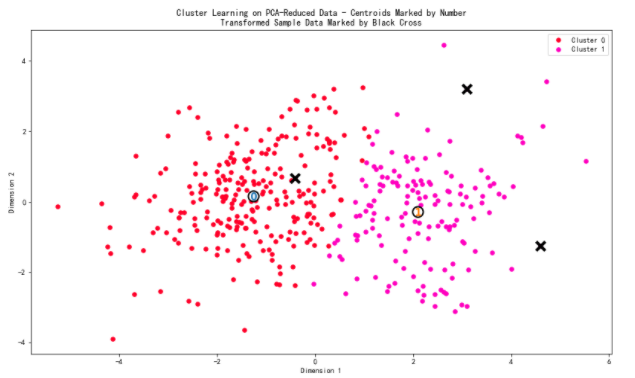
数据恢复
上面的可视化图像中提供的每一个聚类都有一个中心点。
这些中心(或者叫平均点)并不是数据中真实存在的点,但是是所有预测在这个簇中的数据点的 平均 。
对于创建客户分类的问题,一个簇的中心对应于 那个分类的平均用户 。因为这个数据现在进行了降维并缩放到一定的范围,我们可以通过施加一个反向的转换恢复这个这个点所代表的用户的花费。
在下面的代码单元中,将实现下列的功能:
- 使用
pca.inverse_transform()函数将centers反向转换,并将结果存储在log_centers中。 - 使用
np.log()的反函数np.exp反向转换log_centers并将结果存储到true_centers中。
# TODO:反向转换中心点
log_centers = pca.inverse_transform(centers)
# TODO:对中心点做指数转换
true_centers = np.exp(log_centers)
# 显示真实的中心点
segments = ['Segment {}'.format(i) for i in range(0,len(centers))]
true_centers = pd.DataFrame(np.round(true_centers), columns = data.keys())
true_centers.index = segments
display(true_centers)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BcBlJUsM-1627009147253)(四、Scikit-learn的应用(创建用户分类)].assets/ML_04_20.png)
一个被分到 'Cluster X' 的客户最好被用 'Segment X' 中的特征集来标识的企业类型表示。
运行下面的代码单元以找到每一个样本点被预测到哪一个簇中去。
# 显示预测结果
for i, pred in enumerate(sample_preds):
print('Sample point {} predicted to be in Cluster {}'.format(i,pred))

- 首先,你要考虑不同组的客户 客户分类,针对不同的派送策略受到的影响会有什么不同。
- 其次,你要考虑到,每一个客户都被打上了标签(客户属于哪一个分类)可以给客户数据提供一个多一个特征。
- 最后,你会把客户分类与一个数据中的隐藏变量做比较,看一下这个分类是否辨识了特定的关系。
















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











