







系列文章目录
机器学习——scikit-learn库学习、应用
机器学习——最小二乘法拟合曲线、正则化
机器学习——使用朴素贝叶斯分类器实现垃圾邮件检测(python代码+数据集)
文章目录
前言
Scikit-learn是一个支持有监督和无监督学习的开源机器学习库。它还为模型拟合、数据预处理、模型选择和评估以及许多其他实用程序提供了各种工具。Scikit-learn的功能主要被分为六大部分:分类,回归,聚类,数据降维,模型选择和数据预处理。
1、分类:支持向量机(SVM),逻辑回归,随机森林,最近邻,决策树等。
2、回归:支持向量回归(SVR),弹性网络(Elastic Net),最小角回归(LARS ),贝叶斯回归等
3、聚类:K-均值聚类,谱聚类,均值偏移,分层聚类等
4、数据降维:使用主成分分析(PCA)、非负矩阵分解(NMF)或特征选择等降维技术来减少要考虑的随机变量的个数,其主要应用场景包括可视化处理和效率提升。
5、模型选择:是指对于给定参数和模型的比较、验证和选择,其主要目的是通过参数调整来提升精度。目前Scikit-learn实现的模块包括:pipeline(流水线),grid_search(网格搜索),cross_validation( 交叉验证),metrics(度量),learning_curve(学习曲线)
6、数据预处理:数据预处理
7、辅助工具:exceptions(异常和警告)、dataset(自带数据集)、utils、sklearn.base
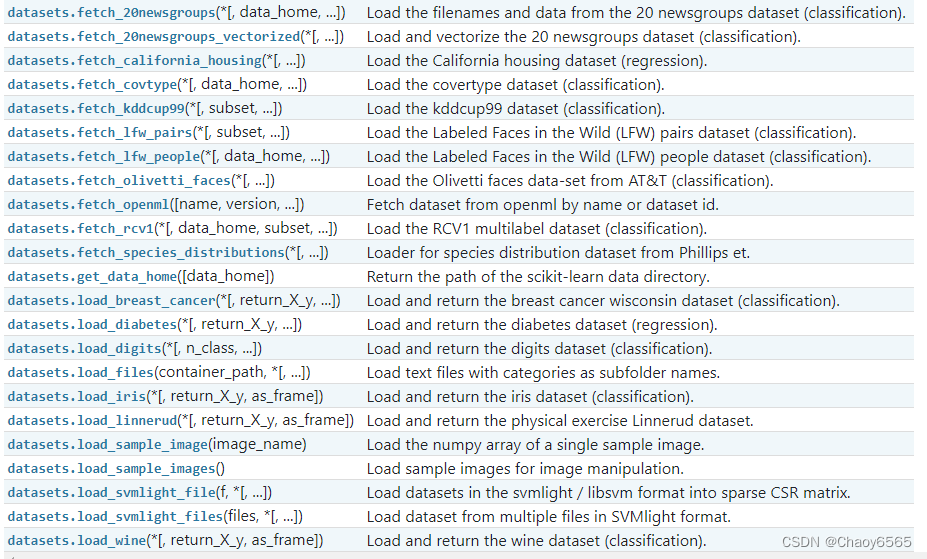
一、datasets获得数据集
1、Loaders
汇总如下:
sklearn官网:https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
相关函数代码
from sklearn import datasets
loaded_data = datasets.load_boston()# 用哪个数据集直接把后面的函数替换了就行
# 获取特征与对应的目标值
data_X = loaded_data.data
data_Y = loaded_data.target
2、sklearn生成数据
汇总如下:
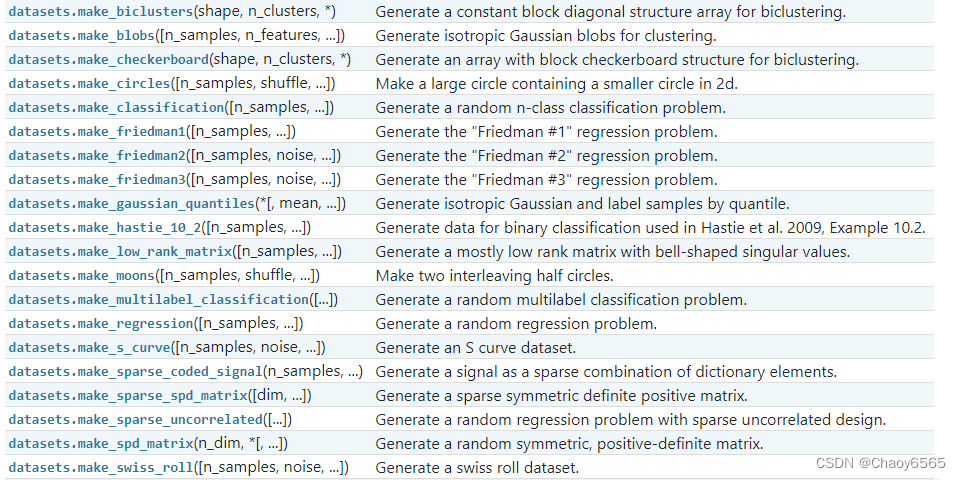
from sklearn import datasets
X, y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=10)
常用参数:
n_samples:样本数
n_features:每个样本的特征数
n_informative :有效信息,信息特征的数量,即用于构建用于生成输出的线性模型的特征的数量。
n_redundant:冗余信息,informative特征的随机线性组合
n_repeated :重复信息,随机提取n_informative和n_redundant 特征
n_targets:回归目标的输出
bias:基本线性模型中的偏差项
noise:生成结果的噪声
二、训练集与测试集的划分
训练集和测试集的概念就不多说了。
相关库和函数:
from sklearn.model_selection import train_test_split
X_train,X_test, y_train, y_test = train_test_split(
train_data,
train_target,
test_size=0.3,
random_state=0
)
相关参数:
1、train_data:进行划分的样本的特征集合
2、train_target:进行划分的样本的标签集合
3、test_size:在0-1之间时,表示测试样本占比;是整数的话,就代表测试样本的数量。
4、random_state:随机数的种子。
假设random_state = 1,其他参数一样的情况下,重复试验的时候随机数组是一样的。
但填0或不填,每次都不一样。
随机数的产生取决于种子:
种子不同,产生不同的随机数;
种子相同,即使实例不同也产生相同的随机数。
三、scikit-learn常用模型
相关函数:
model.fit(X_train, y_train) # 用于模型训练
model.predict(X_test) # 用于模型预测
model.get_params() # 获得模型参数
model.score(X_test, y_test) # 进行模型打分
1、线性回归
使用最小二乘法实现
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=1)
参数:
1、fit_intercept:是否计算截距。
2、normalize:当其为False时,该参数将被忽略。 当其为True时,则按照一定规律归一化。
3、copy_X:是否对X数组进行复制。
4、n_jobs:指定线程数
2、逻辑回归
用于计算概率,logistic回归是一种广义线性回归。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty='l2',dual=False,C=1.0,n_jobs=1,random_state=20)
参数:
1、penalty:使用指定正则化项,可以指定为’l1’或者’l2’,L1正则化可以抵抗共线性,还会起到特征选择的作用,不重要的特征系数将会变为0;L2正则化一般不会将系数变为0,但会将不重要的特征系数变的很小,起到避免过拟合的作用。
2、C:正则化强度取反,值越小正则化强度越大
3、n_jobs: 指定线程数
4、random_state:随机数生成器
3、朴素贝叶斯
以贝叶斯定理为基础,分类模型。
import sklearn.naive_bayes as bayes
# 伯努利分布的朴素贝叶斯
model = bayes.BernoulliNB(alpha=1.0,binarize=0.0,fit_prior=True,class_prior=None)
# 高斯分布的朴素贝叶斯
model = bayes.GaussianNB()
参数:
1、alpha:平滑参数
2、fit_prior:是否要学习类的先验概率;false-使用统一的先验概率
3、class_prior:是否指定类的先验概率;若指定则不能根据参数调整
4、binarize:二值化的阈值。
4、决策树
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(
criterion='entropy',
max_depth=None,min_samples_split=2,
min_samples_leaf=1,max_features=None
)
参数:
1、criterion:采用gini还是entropy进行特征选择
2、max_depth:树的最大深度
3、min_samples_split:内部节点分裂所需要的最小样本数量
4、min_samples_leaf:叶子节点所需要的最小样本数量
5、max_features:寻找最优分割点时的最大特征数
5、随机森林
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(oob_score=True)
参数:
1、n_estimators:森林中树的数量,默认是10棵,如果资源足够可以多设置一些。
2、max_features:寻找最优分隔的最大特征数,默认是"auto"。
3、max_ depth:树的最大深度。
4、min_ samples_split:树中一个节点所需要用来分裂的最少样本数,默认是2。
5、min_ samples_leaf:树中每个叶子节点所需要的最少的样本数。
6、SVM(支持向量机)
from sklearn.svm import SVC
model = SVC(C = 1,kernel='linear')
参数为:
1、C:误差项的惩罚系数
2、kernel:核函数,默认:rbf(高斯核函数),可选择的对象为:‘linear’,‘poly’,‘sigmoid’,‘precomputed’。
7、KNN(K-近邻算法)
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=5,n_jobs=1)
参数:
1、n_neighbors: 使用邻居的数目
2、n_jobs:线程数
8、adaboost
adaboost是一种由弱分类器构成的强分类器
from sklearn.ensemble import AdaBoostClassifier
AdaBoostClassifier(n_estimators=100,learning_rate=0.1)
参数:
1、n_estimators: 弱分类器的数量
2、learning_rate:学习率
9、总代码
https://download.csdn.net/download/weixin_45464524/87391688
四、Loss曲线、K折交叉验证、验证曲线
1、Loss曲线
学习曲线主要反应的是学习的一个过程,常用的表示方法是训练集的loss和测试集的loss与训练量之间的关系。
from sklearn.model_selection import learning_curve
learning_curve(
estimator,
X, y,
train_sizes=array([0.1, 0.325, 0.55, 0.775, 1. ]),
cv=None,
scoring=None,
exploit_incremental_learning=False,
n_jobs=1,
pre_dispatch='all',
verbose=0
)
参数:
1、estimator:用于预测的模型
2、X:预测的特征数据
3、y:预测结果
4、train_sizes:训练样本相对的或绝对的数字,这些量的样本将会生成learning curve,当其为[0.1, 0.325, 0.55, 0.775, 1. ]时代表使用10%训练集训练,32.5%训练集训练,55%训练集训练,77.5%训练集训练100%训练集训练时的分数。
5、cv:交叉验证生成器或可迭代的次数
6、scoring:调用的方法
代码:
# 学习曲线模块
from sklearn.model_selection import learning_curve
# 导入digits数据集
from sklearn.datasets import load_digits
# 支持向量机
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
# neg_mean_squared_error代表求均值平方差
# 使用SVM的分类模型,输入特征为X,输出label为y,进行10折交叉验证,通过均值平方差的方式计分,学习曲线分为5段。其一共具有3个返回值,分别是train_sizes, train_loss, test_loss,其中train_loss指的是训练集的loss,其shape为(5,10),第n行对应学习曲线的第n段,第n行的内容代表着第n段的10折交叉验证的结果;test_loss的含义与train_loss类似,其对应的是测试集的loss。
train_sizes, train_loss, test_loss = learning_curve(
SVC(gamma=0.01), X, y, cv=10, scoring='neg_mean_squared_error',
train_sizes=np.linspace(.1, 1.0, 5))
# loss值为负数,需要取反
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
# 设置样式与label
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
# 显示图例
plt.legend(loc="best")
plt.show()
2、K折交叉验证
K折交叉验证首先要将整个数据集分成K份。
1、取前面K-1份用于训练,最后一份用于测试,并取得测试结果。
2、取前面K-2份和最后一份用于训练,取第K-1份用于测试,并取得测试结果。
3、以此类推,将数据集的每一份均用于测试过一次。
4、取所有测试结果取平均。
from sklearn.model_selection import cross_val_score
cross_val_score(
estimator,
X, y=None,
scoring=None,
cv=None,
n_jobs=1,
verbose=0,
fit_params=None,
pre_dispatch=‘2*n_jobs’
)
参数:
1、estimator:用于预测的模型。
2、X:预测的特征数据
3、y:预测结果
4、scoring:调用的方法
代码:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# K折交叉验证模块
from sklearn.model_selection import cross_val_score
# 导入k聚类算法
from sklearn.neighbors import KNeighborsClassifier
# 加载iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=4)
# 建立Knn模型
knn = KNeighborsClassifier()
# 使用K折交叉验证模块
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy')
# 将5次的预测准确率打印出
print(scores)
#将5次的预测准确平均率打印出
print(scores.mean())
3、验证曲线
验证曲线主要反应的是当超参数变化时,模型的训练状况,常用的表示方法是训练集的loss和测试集的loss与超参数之间的关系,其作用是可以帮助我们选择合适的超参数。
from sklearn.model_selection import validation_curve
validation_curve(
estimator,
X, y,
param_name,
param_range,
groups=None,
cv=’warn’,
scoring=None,
n_jobs=None,
pre_dispatch=’all’,
verbose=0,
error_score=’raise-deprecating’
)
参数:
1、estimator:用于预测的模型
2、X:预测的特征数据
3、y:预测结果
4、param_name:超参数的名称
5、param_range:超参数的取值范围
6、cv:交叉验证生成器或可迭代的次数
7、scoring:调用的方法
代码:
# 验证曲线模块
from sklearn.model_selection import validation_curve
# 导入digits数据集
from sklearn.datasets import load_digits
# 支持向量机
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
digits = load_digits()
X = digits.data
y = digits.target
# 建立参数测试集
# 从1e-6到1e-2次方,分五段
param_range = np.logspace(-6, -2, 5)
#使用validation_curve快速找出参数对模型的影响
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring='neg_mean_squared_error')
# loss值为负数,需要取反
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
# 设置样式与label
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
# 显示图例
plt.legend(loc="best")
plt.show()















 8558
8558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











