







该爬虫大致分为以下步骤:
0.搜索关键词、点击搜索、进入新页面
1.获取每个页面的HTML
2.解析每个页面的HTML
3.将爬取到的数据写入csv文件
(这里搜索的例子是华晨宇,爬取前5页)
因为刚学爬虫,所以注释会写得比较多,方便自己理解。
文章末尾有完整源代码,分析过程的代码比较杂。
先引入相关模块、做好准备工作:
import requests
from bs4 import BeautifulSoup
from selenium import webdriver # 引入浏览器驱动
from selenium.webdriver.common.by import By # 借助By模块进行操作
from selenium.webdriver.support.ui import WebDriverWait # 显式等待
from selenium.webdriver.support import expected_conditions as Ec # 显式等待的条件
from selenium.common.exceptions import TimeoutException # 捕获超时异常
import pandas as pd
browser = webdriver.Chrome() # 获取浏览器对象
WAIT = WebDriverWait(browser,10) # 指定最长等待时间
url = 'https://www.bilibili.com'
print('开始访问b站……')
browser.get(url)
0.搜索关键词、点击搜索、进入新页面:
首先我们按F12观察一下b站页面的搜索框和搜索按键:
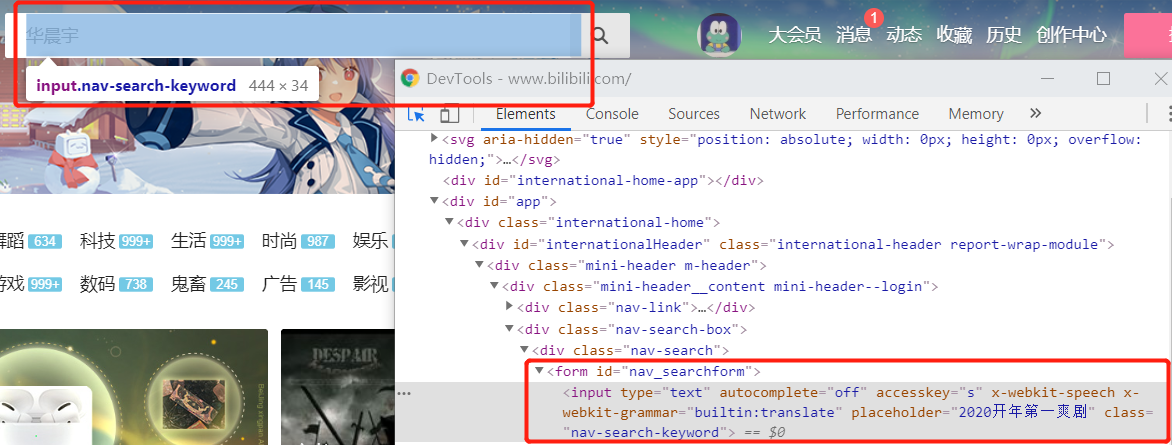
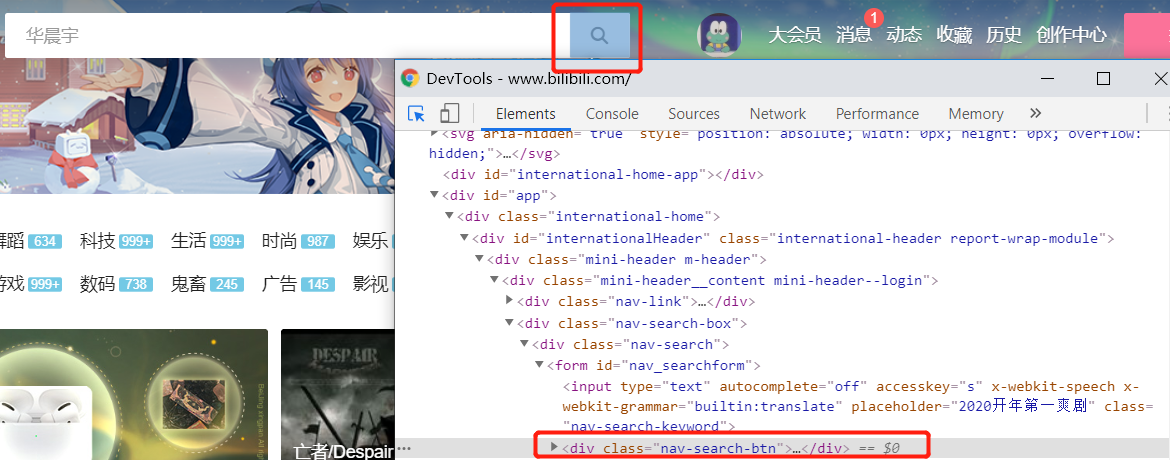
这里我们使用XPath选取节点,右键点击框起来的标签选择Copy XPath。
def search(content):
print('正在进行搜索……')
# 用XPath选取节点
input = WAIT.until(Ec.presence_of_element_located((By.XPATH,'//*[@id="nav_searchform"]/input') 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9328
9328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









