







背景:神经网络的起源是人们想尝试设计出模仿大脑的算法,它的理念就是,如果我们想要建立学习系统,那为什么不去模仿我们所认识的,最神奇的学习机器,人类的大脑呢?
神经网络逐渐兴起于20世纪80、90年代,应用得非常广泛,但由于各种原因,在90年代的后期应用减少了。
再次兴起的原因之一是神经网络的计算量较大,因此,大概到了近些年,计算机的运行速度变快,才足以运行大规模的神经网络。
神经网络在学习复杂的非线性假设上被证明是一种好的算法。
即使输入特征空间很大,也能轻松搞定。
0、如何表示神经网络?
先来看单个神经元在大脑中是什么样的:

神经元是大脑中的细胞,其中很多输入通道叫做树突(Dendrite)(可以把它们想象成输入电线),它们接收来自其他神经元的信息。神经元有一条输出通道叫做轴突,这条输出通道是用来给其他神经元传递信号或者传送信息的。
简而言之,神经元是一个计算单元,它从输入通道接受一定数目的信息,并做一些计算,然后将结果通过它的轴突传送到其他节点或者大脑中的其他神经元。
在人工神经网络里,我们将使用一个很简单的模型来模拟神经元的工作,我们将神经元模拟成一个逻辑单元:
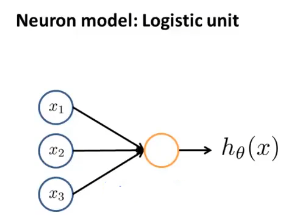
黄色圆圈类似于神经元细胞体的东西,然后我们通过输入通道(树突)传递给它一些信息,然后神经元做一些计算,并通过它的输出通道(轴突)输出计算结果。
这样的图表表示 :
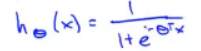
通常
x
x
x 和
θ
θ
θ 是参数向量:
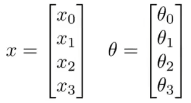
当绘制一个神经网络时,通常只绘制输入节点
x
1
x_1
x1、
x
2
x_2
x2、
x
3
x_3
x3,有必要的时候,会增加一个额外的节点
x
0
x_0
x0,这个
x
0
x_0
x0 节点有时也被称作偏置单元或偏置神经元:
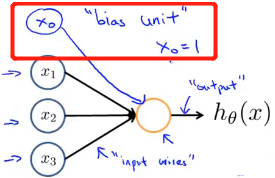
但因为
x
0
x_0
x0 总是等于
1
1
1,所以有时候会画出它,有时候不会画出,这取决于在具体例子中加上
x
0
x_0
x0 是不是表示起来更方便。
θ θ θ 为模型的参数(或称为权重)。
在神经网络术语中,激活函数是指代非线性函数
g
(
z
)
g(z)
g(z) 的另一个术语:

这个图代表单个的神经元:

神经网络其实就是一组神经元连接在一起的集合:

这里有
3
3
3 个神经元,在最后一层有第三个节点,该节点输出假设函数
h
(
x
)
h(x)
h(x) 计算的结果。
关于神经网络的术语:
-
网络中的第一层也被称为输入层,因为我们在这一层输入特征 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3。
-
最后一层也称为输出层,因为这一层的神经元输出假设的最终计算结果。
-
任何非输入层或非输出层的层就被称为隐藏层,在监督学习中,你能看到输入,也能看到正确的输出,而隐藏层的值在训练集里是看不到的,它的值不是 x x x 也不是 y y y,所以我们叫它隐藏层。
1、逐步分析神经网络具体的计算步骤:
这里使用 a i ( j ) a^{(j)}_i ai(j) 来表示第 j j j 层第 i i i 个神经元的激活项。
所谓激活项是指由一个具体神经元计算并输出的值。
此外,神经网络被这些矩阵参数化, Θ ( j ) Θ^{(j)} Θ(j) 就是权重矩阵,它控制比如说从第一层到第二层或者第二层到第三层的映射。
这就是这张图表示的计算:

举个例子,
a
1
(
2
)
a^{(2)}_1
a1(2) 等于
s
i
g
m
o
i
d
sigmoid
sigmoid 函数作用在这种输入的线性组合上的结果:
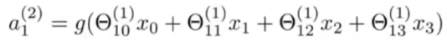
在这里,我们有三个输入单元和三个隐藏单元,
θ
(
1
)
θ^{(1)}
θ(1) 就是控制着从三个输入单元到三个隐藏单元的映射的参数矩阵,因此
θ
(
1
)
θ^{(1)}
θ(1) 就是一个
3
×
4
3×4
3×4 矩阵。
更一般地,如果一个网络在第 j j j 层有 s j s_j sj 个单元,在 j + 1 j+1 j+1 层有 s j + 1 s_j+1 sj+1 个单元,那么矩阵 θ ( j ) θ^{(j)} θ(j) 即控制第 j j j 层到第 j + 1 j+1 j+1 层映射的矩阵,它的维度为 s ( j + 1 ) × ( s j + 1 ) s_{(j+1)}×(s_j+1) s(j+1)×(sj+1) 。
最后在输出层还有一个单元,它计算 h θ ( x ) h_θ(x) hθ(x):
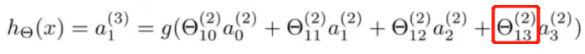
θ
(
2
)
θ^{(2)}
θ(2) 是参数矩阵(权重矩阵),该矩阵控制从第二层的
3
3
3 个单元到第三层的
1
1
1 个单元的映射。
总结一下,这里讲解了如何定义一个人工神经网络,其中的神经网络定义了函数 h h h,从输入到输出的映射,这些假设被参数化,将参数标记为大写的 Θ Θ Θ,改变 Θ Θ Θ,就能得到不同的假设,有不同的函数。以上就是怎么从数学上定义神经网络的假设。
参考资料:吴恩达机器学习系列课程















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









