







解答题
什么是极大似然估计
已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值。
什么是最大后验估计
根据已知样本,来通过调整模型参数使得模型能够产生该数据样本的概率最大,只不过对于模型参数有了一个先验假设,即模型参数可能满足某种分布,不再一味地依赖数据样例。
什么是贝叶斯估计
贝叶斯估计是典型的贝叶斯学派观点,它的基本思想是:待估计参数θ也是随机的,和一般随机变量没有本质区别,因此只能根据观测样本估计参数θ的分布。
什么是朴素贝叶斯分类器
朴素贝叶斯分类器是一系列以假设特征之间强(朴素)独立下运用贝叶斯定理为基础的简单概率分类器。
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
什么是先验概率、后验概率
先验概率是指根据以往经验和分析得到的概率,如全概率公式,它往往作为"由因求果"问题中的"因"出现.
后验概率是指依据得到“结果”信息所计算出的最有可能是那种事件发生,如贝叶斯公式中的,是"执果寻因"问题中的“因”。
什么是试投密度,如何选择试投密度

试投密度的选择有三个条件:
① 它是一个概率密度函数
② 形状与f(x)要相近
③ f(x)=o(g(x))
什么是重要性采样?它的优点是什么?
重要抽样法(importance sampling method)是最有效的蒙特卡罗技巧之一,其主要思想是,它不从给定的概率分布函数中进行抽样,而是对所给定的概率分布进行修改,使得对模拟结果有重要贡献的部分多出现,从而达到提高效率,减少模拟的时间,以及缩减方差的目的。(解决在估计时减小σ)
优点:
① 减小方差
② 对稀有事件有效采样
③ π(x)复杂,难以计算时,该方法效率较高。
什么是蒙特卡洛积分,它的优点和不足是什么
如果找不到被积函数的原函数,那么利用经典积分方法是得不到积分结果的,但是利用一个随机变量对被积函数进行采样,并将采样值进行一定的处理,那么当采样数量很高时,得到的结果可以很好的近似原积分的结果。
蒙特卡洛法优点:
① 方法的误差与问题的维数无关。
② 对于具有统计性质问题可以直接进行解决。
③ 对于连续性的问题不必进行离散化处理
蒙特卡罗法缺点:
① 对于确定性问题需要转化成随机性问题。
② 误差是概率误差。
③ 通常需要较多的计算步数N.
什么是随机投点法(随机投点法的思想是什么)
在积分区域外面定义一个规则区域,并在该区域内随机均匀投点,用落在积分区域内的概率来计算该积分的值。这种方法叫做随机投点法。
平均值法的基本思想是什么?
利用平均值来求解问题的方法被称为平均值法,它是多变的,因具体问题而异。
常用的方差缩减技术有哪些
重要抽样法、分层抽样法、控制变量法、对立变量法,条件期望法
什么是隐变量
不能被直接观察到,但是对系统的状态和能观察到的输出存在影响的一种变量
EM算法的基本思想是什么?
E步:通过观测数据和已有的模型来估计参数,并用此参数估计值计算似然函数的期望值。
M步:寻找似然函数期望最大时对应的参数。
什么是KL散度
KL散度可以衡量两个随机分布之间的距离,当两个随机分布相同时,它们的KL散度为零,当两个随机分布的差别增大时,它们的KL散度也会增大。
什么是高斯混合模型

GMM是多个高斯分布的加权和,并且权重α之和等于1。这里不难理解,因为GMM最终反映出的是一个概率,而整个模型的概率之和为1,所以权重之和即为1
用高斯概率密度函数(正态分布曲线)精确地量化事物,它是一个将事物分解为若干的基于高斯概率密度函数形成的模型。
什么是条件期望
① 设X和Y是离散随机变量,则X在给定事件Y=y条件时的条件期望是x在Y的值域的函数
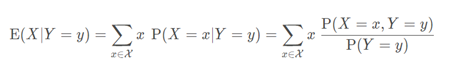
其中,x是处于X的值域。
② 如果现在X是一个连续随机变量,而Y仍然是一个离散变量,条件期望是
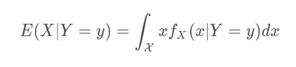
什么是条件方差
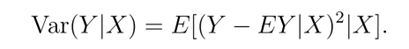
把生成X的步骤看成两步:
先生成Y,由此可以确定X的均值和方差;
再根据这个均值和方差生成X。
那么X的方差的来源就分为两部分:
第一步中,由Y的不同导致的X的均值的波动;
第二步中,确定了X的均值之后X本身的波动。
Simpy是用来干什么的
一个Python第三方库,可以基于“过程”进行离散事件的仿真。
Simpy,所有的过程都使用python“生成器”来实现,可以对汽车、服务业等包含很多活跃体的情况进行仿真。simpy还支持各种资源的分配(如服务员、隧道等)。
仿真的速度可以是实时的也可以快进。
什么是贝特朗悖论
在一给定圆内所有的弦中任选一条弦,求该弦的长度长于圆的内接正三角形边长的概率。
什么是马尔可夫性
又称无记忆性,指下一状态只与当前状态有关,与上一状态无关
什么是状态转移矩阵
一个系统的某些因素在转移过程中,第n次结果只受第n-1的结果影响,即只与上一时刻所处状态有关,而与过去状态无关。状态转移是指客观事物由一种状态转移到另一种状态。
在状态转移矩阵中,矩阵各元素表示状态转移的概率,并且各行元素之和等于1,其现实意义是,各个状态的百分比总和为1
什么是细致平稳条件
从任意状态i转移到状态j的速率等于从状态j转移到状态i的速率,则状态转移稳定。定理中π分布就是我们研究的概率分布,我们构造出P,则构造出了稳定状态满足π分布马尔科夫链。若状态转移矩阵P和分布π满足:
π(i)P(X_(n+1)=j|X_n=i)
Gibbs采样的基本思想
需要应用在至少二维的数据上,一维一维地进行采样,多维的情况下,每一次采样还是只能移动一个维度,其余的n−1个维度都作为条件。
HMM三要素
① 状态转移矩阵A:a_ij=P(i_(t+1)=q_j | i_t=q_i )
② 观测概率矩阵B:b_ij=P(o_t=v_j | i_t=q_t )
③ 初始隐状态分布π:π_i=P(i_0=q_i )
MCMC算法基本思想
核心思想是我们已知一个概率密度函数,需要从这个概率分布中采样,来分析这个分布的一些统计特性

什么是逆变换法(连续性和离散型)
逆变换法(连续型):设 为连续型随机变量,取值于区间 (可包括 和端点), 的密度在 上取正值, 的分布函数为 , ,则 。
逆变换法(离散型):设 为离散型随机变量,取值于集合 ,F 为 的分布函数, ,根据 的值定义随机变量 为 ,当且仅当 , , 则 。
计算题
朴素贝叶斯分类器例题
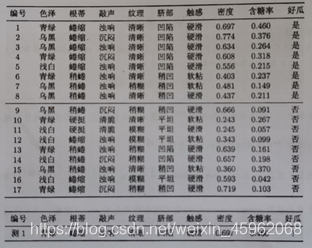

样本均值方差计算

逆变换法的计算步骤

连续型随机变量拒绝接受法采样计算步骤
①根据试投分布G生成随机变量Y
②生成[0,1]上的均匀分布的随机变量U
③若 
重要性采样计算步骤
① 寻找试投密度函数g(x)
② 生成X~g(x)
③ 积分 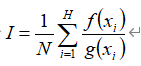
EM算法目标函数推导

概率统计基本内容(两个原题:条件概率|全概率,贝叶斯公式)





随机投点法例题
π的近似计算
① 取单位圆的第一象限部分
② 取XU(0,1),YU(0,1),共N个点
③ 若x2+y2≤1,n=n+1
④ 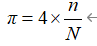

平均值法例题

重要抽样法例题

控制变量法例题

对立变量法例题
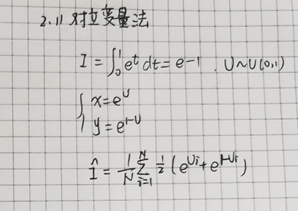
条件期望法例题

MH抽样计算步骤


程序设计题
逆变换法|拒绝接受法抽样
逆变换法
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return -1*np.log(1-x) #拟合正态分布函数的反函数
def eit(n):
u1 = np.random.random(n)
u2 = np.random.random(n)
x1 = f(u1) #拟合正半轴的随机数
x2 = -f(u2) #拟合负半轴的随机数
x = np.append(x1,x2)
plt.hist(x,bins=100)
plt.show()
return x
print(eit(2000)) #运行
舍选法采样
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return np.exp(x)
def rm(a,b,m,n):
u1 = np.random.random(n)
u2 = np.random.random(n)
x = a+(b-a)*u1
y = m*u2
z = []
for i in range(n):
if y[i] <= f(x[i]):
z.append(x[i])
plt.hist(z,bins=100)
plt.show()
return z
x = rm(-1,1,3,10000)
print(x)
Bootspit采样(自助采样)
from sklearn.utils import resample
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import numpy as np
import pandas as pd
data = pd.read_csv('Iris.csv')
values = data.values
print(values)
n = 10
size = len(data)
scores = []
for i in range(n):
train = resample(data, n_samples = size)
test = np.array([x for x in values
if x not in train])
model = RandomForestClassifier()
model.fit(train[:,:-1],train[:,-1])
predictions = model.predict(test[:,:-1])
score = accuracy_score(test[:,-1], predictions)
print(score)
scores.append(score)
print(scores)
赌徒输光问题模拟
import pandas as pd
import random
sample = []
round_num = 1000
person_num = 10
for person in range(1,person_num+1):
money = 100
for round in range(1,round_num+1):
result = random.randint(0,1)
if result ==1:
money += 1
elif result ==0:
money -= 1
if money == 0:
break
sample.append([person,round,money])
df = pd.DataFrame(sample,columns=['person','round','money'])
print(df)
基于马尔科夫列的采样
import numpy as np
import random
def randomstate_gen(cur_state,transfer_matrix):
u = random.random()
i = cur_state-1
if u <= transfer_matrix[i][0]:
return 1
elif u <= transfer_matrix[i][0]+transfer_matrix[i][1]:
return 2
else:
return 3
transfer_matrix = np.array([[0.7,0.1,0.2],
[0.3,0.5,0.2],
[0.1,0.3,0.6]],dtype='float32')
m = 10000
N = 100000
cur_state = random.choice([1,2,3])
state_list = [cur_state]
for i in range(m+N):
state_list.append(cur_state)
cur_state = randomstate_gen(cur_state,transfer_matrix)
state_list = state_list[m:]
print('1:',state_list.count(1)/float(len(state_list)))
print('2:',state_list.count(2)/float(len(state_list)))
print('3:',state_list.count(3)/float(len(state_list)))
MH抽样
'''
我们的目标平稳分布是一个均值3,标准差2的正态分布,
而选择的马尔可夫链状态转移矩阵Q(i,j)的条件转移
概率是以i为均值,方差1的正态分布在位置j的值。
'''
import random
from scipy.stats import norm
import matplotlib.pyplot as plt
#目标平稳分布:均值3,标准差2的正态分布
def f(x):
y = norm.pdf(x, loc=3, scale=2)
return y
n = 5000
pi = [0 for i in range(n)]
for i in range(n):
#生成一个均值为pi[t-1],标准差为1的正态分布随机数
ps = norm.rvs(loc=pi[i-1], scale=1, size=1, random_state=None)
alpha = min(1, (f(ps[0]) / f(pi[i-1])))
u = random.uniform(0, 1)
if u < alpha:
pi[i] = ps[0]
else:
pi[i] = pi[i-1]
plt.scatter(pi, norm.pdf(pi, loc=3, scale=2))
plt.hist(pi, bins=50, normed=1, facecolor='red', alpha=0.7)
plt.show()
蒙特卡洛积分,随机投点,平均值法
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return x**2
#随机投点法
def rc(a,b,m,n):
u1 = np.random.random(n) #生成(0,1)之间随机数n个
u2 = np.random.random(n)
x = a + (b-a)*u1
y = m*u2
count = 0
for i in range(n):
if y[i] <= f(x[i]):
count += 1
s = (b-a)*m
return count/n*s
#平均值法
def mv(a,b,n):
u = np.random.random(n)
x = a+(b-a)*u
return np.mean(f(x))*(b-a)
print(rc(1,2,4,1000000))
print(mv(1,2,1000000))
欢迎大家加我微信学习讨论





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











