









哈夫曼树
哈夫曼树的基本概念
结点间的路径:从一个结点到另一个结点之间的分支序列。
结点间的路径长度:从一个结点到另一个结点之间的所经过的分支数目。
例如:B到F?
路径:BE、EF 路径长度:2
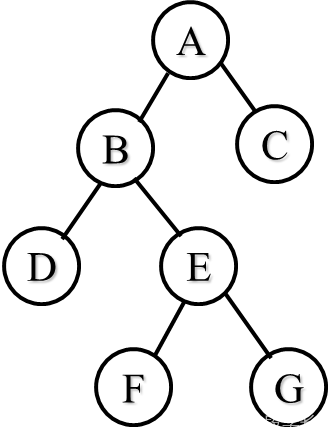
结点的权:给结点赋予的具有某种意义的实数,该实数称为结点的权。
结点的带权路径长度:把从树根到某一结点的路径长度与该结点权的乘积,称为该结点的带权路径长度。
例如:结点F的带权路径长度?
7×3=21
树的路径长度PL:树中从根到各个结点的路径长度之和。
树的带权路径长度WPL :树中从根到叶子结点的各个带权路径长度之和。
例如:
PL=0+1+1+2+2+3+3=12
WPL=4×2+7×3+5×3+2×1
=46
问题1:什么样的二叉树的路径长度最小?
完全二叉树的路径长度最小,但不唯一。
PLa=0+1+1+2+2=6
PLb=0+1+1+2+2=6
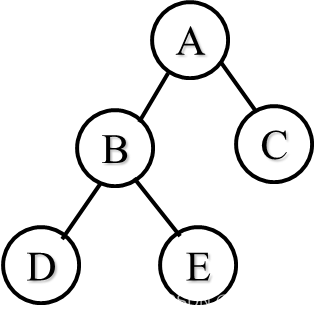
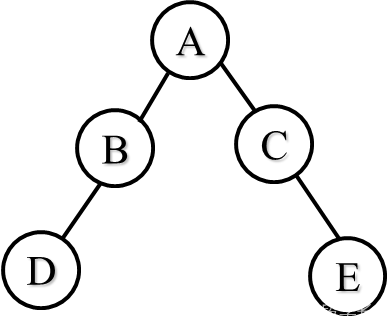
问题2:什么样的带权路径长度最小?
WPLa=7×2+5×2+2×2+4×2=36
WPLb=4×2+7×3+5×3+2×1=46
WPLc=7×1+5×2+2×3+4×3=35
在叶子数目及权值相同的二叉树中,完全二叉树不一定是最优二叉树。
一般情况下,最优二叉树中,权值越大的叶子离根越近;权值越小的叶子离根越远。
构造哈夫曼树
(1) 哈夫曼树的概念
哈夫曼树:是由n个带权叶子结点构成的二叉树中带权路径最短的二叉树,又称又称最优二叉树。
哈夫曼树的形态不唯一。
(2) 构造哈夫曼树的算法步骤
① 初始化:用给定的n个权值{w1,w2,…wn}构造n棵二叉树并购成森林F={T1,T2,…,Tn},其中每棵二叉树都是单结点二叉树。
② 找最小树:在森林F中选出两个根结点的权值最小的二叉树合并,作为一棵新二叉树的左、右子树,标记新二叉树的根结点权值为其左、右子树根结点权值之和。
③ 删除与加入:从森林F中删除选取的那两棵二叉树,并将新二叉树加入森林F中;
④ 判断:重复②、③步,直到森林F中只含有一棵二叉树为止,此时得到的二叉树就是哈夫曼树。
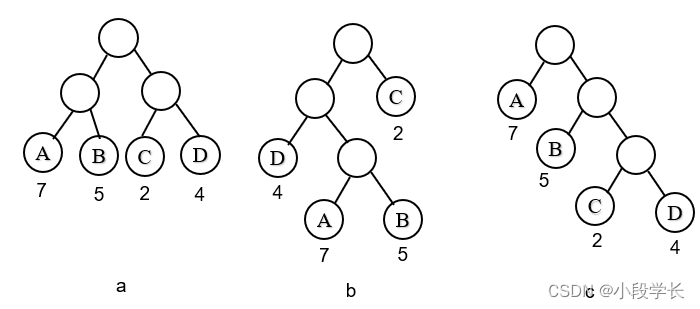
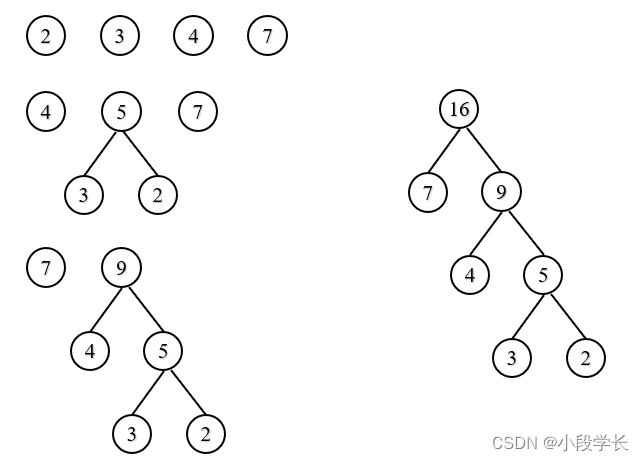
例1:给定一组权值{7,4,3,2},构造哈夫曼树
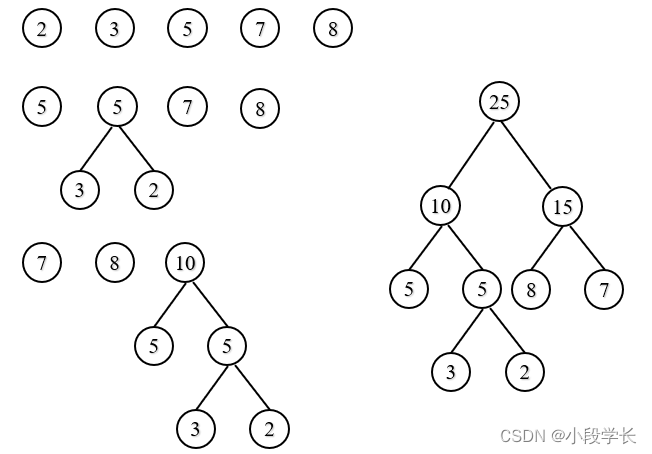
例2:给定一组权值{3,8,7,2,5},构造哈夫曼树
哈夫曼树的类型定义
(1) 存储结构
哈夫曼树是最优二叉树,可以用通用链式存储结构。
哈夫曼树有n个叶子结点,n-1度为2的结点,结点总数2n-1个。
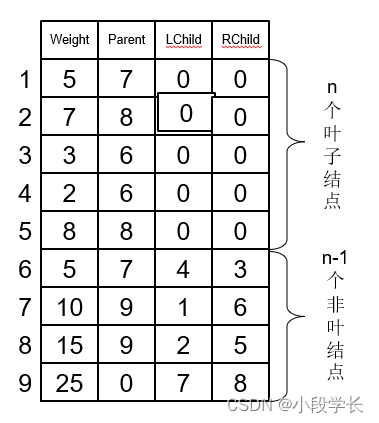
哈夫曼树的顺序存储结构:一维结构数组,构成静态三叉链表。
静态三叉链表的结点结构:权值、双亲序号、左孩子序号、右孩子序号。

哈夫曼树的顺序存储结构:
(2) 哈夫曼树类型的定义
#define N 20 /* 叶子结点的最大值 */
#define M 2*N-1 /* 结点的最大值*/
typedef struct {
int Weight; /* 结点的权值 */
int Parent; /* 双亲的下标 */
int LChild; /* 左孩子的下标 */
int RChild; /* 右孩子的下标 */
} HTNode,HuffmanTree[M+1];
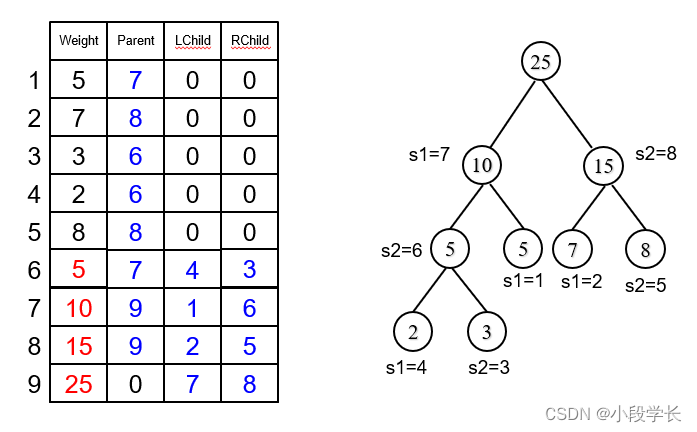
创建哈夫曼树:初始化 + 选择、删除合并
哈夫曼编码
哈夫曼树的概念
二进制编码:用二进制序列表示字符。
定长编码:每个字符用相同数目的二进制位编码。
ASCII编码:一个英文字符用7位二进制位编码,使用一个字节,最高位规定为0。
例如:A 0100 0001
a 0110 0001
前缀编码:任一字符的编码都不是其它字符编码的前缀。
例如:编码系统01、001、010、100、110就不是前缀编码。
01001:01、001
01001:010、01
哈夫曼编码:对一棵具有n个叶子结点的哈夫曼树,若对树中的每个左分支赋0,右分支赋1(也可以规定左1右0),则从根到每个叶子路径上的二进制串就是哈夫曼编码。
哈夫曼编码的性质:
(1) 哈夫曼编码是前缀编码
(2) 哈夫曼编码是最优前缀编码
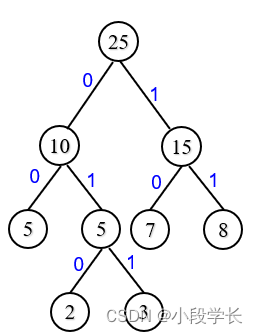
例:要传送数据state, seat, act, tea, cat, set, a, eat, 请给出各字符的哈夫曼编码。
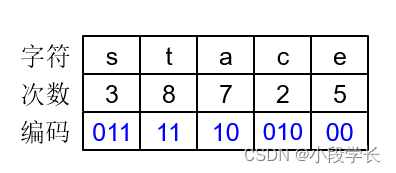
cat编码为:0101011
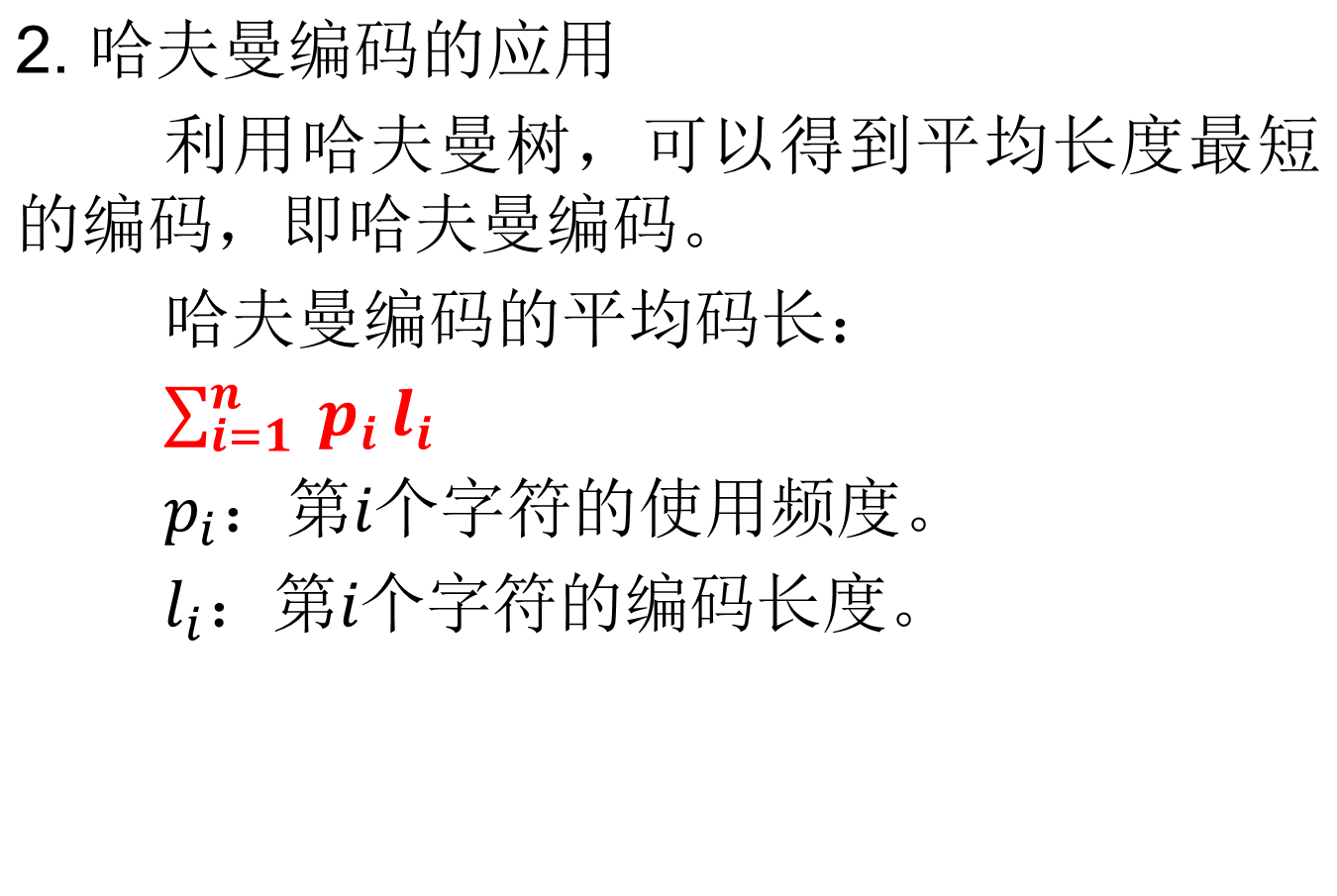
例:设有一台模型机,共有7种不同的指令,其使用频率如下表所示,请设计哈夫曼编码。
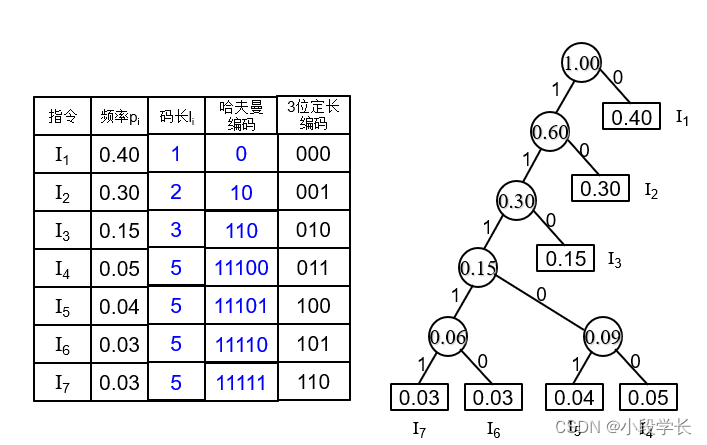
哈夫曼编码的平均码长=
=0.40×1+0.30×2+0.15×3+0.05×5
+0.04×5+0.03×5+0.03×5
=2.20
显然,2.20<3
例:计算1000条指令定长编码总位数和哈夫曼编码总位数。
1000×3=3000
1000×2.20=2200
欢迎大家加我微信交流讨论(请备注csdn上添加)

















 2030
2030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











