








代码地址->https://github.com/cug-ygh/TMT
abstract
多模态情感识别是一项复杂的挑战,因为它涉及到使用各种模式(如视频、文本和音频)识别人类情感。现有方法主要关注多模态数据的融合信息,但忽略了对情绪有不同贡献的模态特定异质性特征的相互作用,导致结果不理想。为了解决这一挑战,我们提出了一种新的Token-disentangling Mutual Transformer (TMT),通过有效地分离和交互模态间的情感一致性特征和模态内的情感异质性特征,用于鲁棒的多模态情感识别。
具体来说,TMT包括两个主要模块:多模态情感Token解纠缠和Token相互转换。
在多模态情感Token解纠缠中,我们引入了一种具有精细Token解纠缠正则化的Token分离编码器,有效地将模态间情感一致性特征Token与各模态内情感异质性特征Token分离开来;因此,情绪相关的一致性和异质性信息可以独立和全面地执行。此外,我们设计了带有两个跨模态编码器的Token互转换器,通过双向查询学习来交互和融合分离的特征Token,从而为多模态情感识别提供更全面和互补的多模态情感表示。我们在三个流行的三模态情感数据集(即CMU-MOSI, CMU-MOSEI和CH-SIMS)上对我们的模型进行了评估,实验结果证实了我们的模型与目前最先进的方法相比具有优越的性能,实现了最先进的识别性能。
Q:什么叫token分离?什么是异质性token和一致性token?
A:token分离指的是在多模态情感识别中,通过特定的算法或模型结构(如transformer编码器)将输入的多模态数据中的特征向量进行分离和重组,使得这些特征向量更好地反映出数据的内在情感状态。这种分离过程能够将不同模态间共有的情感特征(一致性特征)与每个模态特有的情感特征(异质性特征)区分开来,从而为进一步的情感分析和识别提供更准确的信息。
异质性token:这类Token代表了每个模态内部独有的情感信息,即在多模态数据中,各个模态所表达的情感特征可能会有所不同,异质性Token就是为了捕捉这种在特定模态中独特的情感或信息特点。例如,在一段视频中,视觉信息可能显示一个人在笑,而音频信息中的语调则可能传达出悲伤,这种情况下视觉和音频的特征就是异质性的。
一致性token:这类Token代表了不同模态间共享的、相互一致的情感信息。例如,视频、音频和文本可能都在表达同一种情感如快乐或悲伤,一致性Token的目的就是捕捉并表达这种跨模态的共同情感。
intro
情绪识别是人工智能和情感计算领域的研究热点(Sun et al ., 2020a;安万忠,2023;辛格和卡普尔,2023)。传统的单模态情绪识别只关注从单一模态识别情绪(Chen and Joo, 2021),与之相比,利用不同数据源(如视频、音频和文本)的多模态情绪识别在提高对人类情绪的理解方面具有显著优势,并且更符合现实世界的情绪交互和应用(Zadeh et al ., 2017a);Tsai et al ., 2019a;Lv等,2021;Hazarika等,2020a;袁等,2021a;Yan et al ., 2023a,b)。从互联网上的视频、帖子和评论中获得的情感信息可以用于许多目的(Liu et al ., 2023;钟等人,2022)。例如,政府可以利用这些信息来预测人们想要如何投票。电影制片人可以根据评论预测电影的最终票房方向。公司可以根据用户反馈改进产品(Zeng et al ., 2024)。
为了满足真实应用场景的情感交互需求,多模态情感识别通过对不同模态的情感信息进行提取和融合,越来越受到研究者的关注。例如,Sun等人(2020b)引入了深度典型相关分析(DCCA)来捕捉模态之间的相关特征。Liang等人(2021)开发了一个模型,解决了模态不变空间中的分布差异,从而减少了模态间的异质性。Zadeh等人(2017b)将多模态特征向量融合为张量,并对模态之间的相互作用进行动态建模,成功克服了多模态场景下融合的挑战。
上述方法取得的进展主要集中在通过多模态融合技术对共同的情感信息进行建模,而忽略了不同模态的独特信息。这使得这些方法难以有效地模拟不同模态之间的情感关系,从而影响了多模态情感识别的性能
最近,Transformer由于其对序列数据的关系学习和建模能力,在计算机视觉、自然语言处理和多模态识别领域得到了广泛的应用(Dosovitskiy等;Liu et al ., 2021;Liang等,2021;Lin等,2021;Zhang et al, 2024)。例如,Delbrouck等人(2020)在Transformer模型的基础上引入了一种新的编码架构,利用模块化注意力机制对多模态的关系进行编码。Han等人(2021)采用不同的模态作为Transformer翻译模型的输入源和目标源,通过建模它们与情绪的关系来实现模态融合。Wang等人(2020)分别引入了文本音频融合模块和文本视频融合模块,利用Transformer的门控机制增强了两个模块的输出结果。
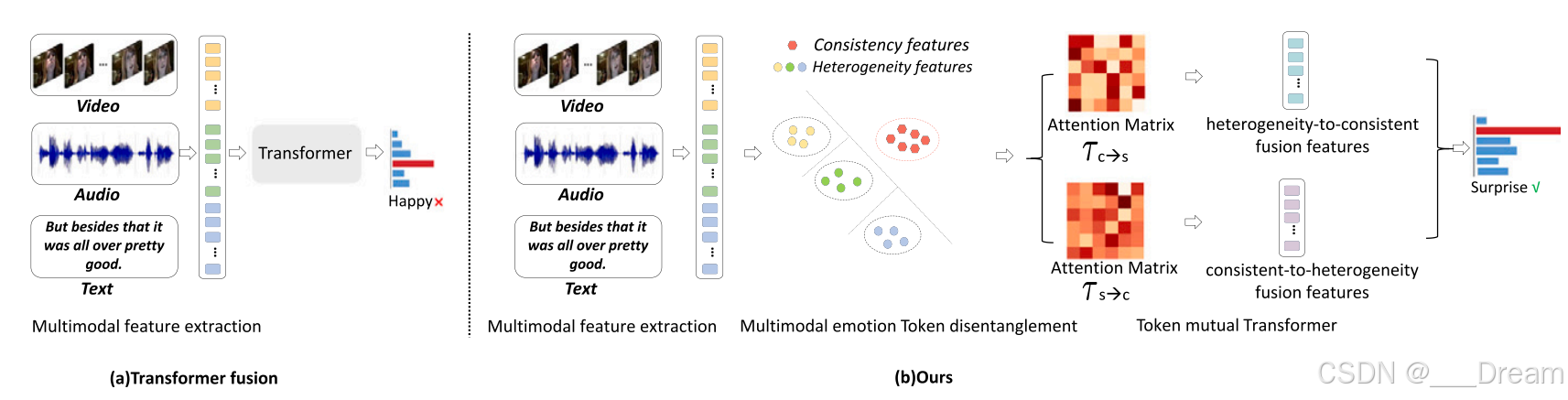
对现有的基于Transformer融合的多模态情感识别方法与基于TMT的多模态情感识别方法进行了比较。
(a)基于Transformer fusion的多模态情感识别,
(b) Our基于TMT的多模态情感识别。TMT通过联合多模态情感Token解纠缠和Token互变,实现更全面、互补的多模态情感表示,实现鲁棒性情感识别。
尽管利用Transformer进行多模态特征融合在建模不同模态之间的情感关系方面是有效的,但它们仍然没有考虑到特定模态对情感交互的微妙异构特征,从而导致次优性能(见图1)。
为此,一种策略是引入对抗学习(Yang et al ., 2022b),分别提取多模态的一致性信息和各模态的异质性信息。Park和Im(2016)将对抗性学习应用于多模态情感表示学习,仅使用类别信息进行多模态嵌入。他等人(2023)提出了对抗性不变性表征融合模型,通过缩小不同模态之间的分布差距来实现模态不变性表征。尽管取得了进展,但不同模态之间微妙的异质性相互作用仍然使我们感到困惑,并且很容易构成学习综合多模态表征的障碍。
例如,音频情态包含独特的语调情感信息,这在其他情态(如图像和文本)中很难匹配。因此,目前直接使用普通Transformer (Vaswani et al ., 2017)或多层感知器(Tolstikhin et al ., 2021)来执行异构和一致特征融合的基于对抗性学习的方法很难捕捉到它们之间微妙的异质性情感交互。也就是说,微妙但有意义的情态信息仍然会被忽略。
此外,基于对抗性学习的方法(Yang et al ., 2022b;Park and Im, 2016;他等人,2023;Liu et al ., 2023b)也需要额外的精心设计的网络模块和大量的训练数据来进行适当的训练。这可能导致巨大的模型容量,使得实现鲁棒和高效的多模态情感识别变得具有挑战性。
为了解决上述问题,我们提出了一种新的用于多模态情感识别的Token-disentangling互变器(TMT)。TMT通过引入多模态情感Token解纠缠和Token互变两个主要模块,可以有效地分离模态间情感一致性特征和模态内情感异质性特征,并将它们相互融合,形成更全面的多模态情感表征。TMT的动机以及与现有融合方法的比较如图1所示。具体而言,多模态情感Token解纠缠模块首先通过一种新颖的Token分离编码器及其Token解纠缠正则化,将模态间情感一致性特征Token与每个模态内情感异质性特征Token彻底解纠缠。然后,为了全面探索解纠缠特征Token之间的情感交互,我们进一步设计Token互转换器,通过在两个跨模态编码器中进行两次双向查询学习,将解纠缠特征整合为更全面的多模态情感表示。
结合这两个模块,我们的TMT可以实现最先进的多模态情感识别性能。综上所述,本文的重要贡献可以概括如下:
•我们提出了一种用于鲁棒多模态情感识别的新型TMT。引入多模态情感Token解纠缠模块和Token互转换模块,有效挖掘和整合多模态情感信息,实现鲁棒多模态情感识别。在三个广泛使用的数据集(CMU-MOSI, CMU-MOSEI, CH-SIMS)上的实验证明,我们的方法在多模态情感识别方面优于现有的最先进的方法。
•我们提出了一种新颖且易于实现的多模态情感Token解纠缠模块,可以有效地将模态间情感一致性特征Token与每个模态内情感异质性特征Token分离开来。为了实现这一点,我们在模块中引入了一个令牌分离编码器及其令牌解纠缠正则化,以帮助Transformer在不增加额外参数和计算复杂性的情况下分离四组特征。
•我们设计了一个双向查询学习的Token互变器,通过探索情感一致性和异质性信息在情感交互中的相互作用,充分交互和整合情感一致性和异质性信息,从而获得更全面、互补的多模态情感表征。例如,音频情态包含独特的语调情感信息,这在其他情态(如图像和文本)中很难匹配。因此,目前直接使用普通Transformer (Vaswani et al ., 2017)或多层感知器(Tolstikhin et al ., 2021)来执行异构和一致特征融合的基于对抗性学习的方法很难捕捉到它们之间微妙的异质性情感交互。也就是说,微妙但有意义的情态信息仍然会被忽略。
此外,基于对抗性学习的方法(Yang et al ., 2022b;Park and Im, 2016;他等人,2023;Liu et al ., 2023b)也需要额外的精心设计的网络模块和大量的训练数据来进行适当的训练。这可能导致巨大的模型容量,使得实现鲁棒和高效的多模态情感识别变得具有挑战性。
related work
多模态情绪识别
大多数现有的多模态情感识别方法可以大致分为两大类:基于表示学习的方法和基于多模态融合的方法。
基于表征学习的方法侧重于通过考虑不同模态的差异性和一致性来学习模态表征,从而提高多模态情感识别。例如,Yang等人(2022a)使用编码器和鉴别器通过对抗性学习学习多种模式的一致性和异质性特征。Hazarika等人(2020a)使用度量学习来学习多模态情感识别任务的模态特定和模态不变表征。Han等人(2021b)提出了一个名为MMIM的框架,该框架通过分层互信息最大化来改进多模态表示。Zhao等人(2020)提出了一种新的基于注意力的vanet,该vanet集成了空间、通道和时间注意力,用于音视频情感识别。Lv等人(2021)引入了一个消息中心,通过向每个模态发送共同的消息并加强其特征,与每个模态交换信息。Zeng等人(2024)提出了一种基于特征的多模态情感分析恢复动态交互网络。近年来,特征解缠方法已被应用于情感识别中,以实现与情感相关的特征对齐。例如,Hazarika等人(2020b)提出的MISA方法涉及通过应用精心设计的约束和编码器将每种模态投影到两个不同的子空间中。类似地,Yang等人(2022a)引入了特征分离多模态情感识别(FDMER)方法,通过将每个模态映射到模态不变子空间和模态特定子空间来解决模态异质性。
通过对抗性学习策略的结合,他们改进了特征分离的公共和私有表示。
另一个值得注意的贡献是Yang等人(2022b)提出的多模态特征分离方法(MFSA),该方法提出了一种在异步序列中获取有效多模态表示的方法,特别强调了实现特征解纠缠。
然而,这些方法主要集中在不同模态的情感表征上,忽略了进行全面特征学习的模态融合,导致性能不佳。
基于多模态融合的方法主要是为了减少模态之间的异质性,获得更全面的多模态情感特征。Zadeh等(2017b)提出了一种张量融合方法(TFN),通过计算笛卡尔积对不同模态之间的关系进行建模。Liang等(2018)提出了递归多级融合方法,通过将融合分为多个阶段,不断融合多模态信号子集来解决融合问题,完成最终的融合任务。Lv等人(2021)提出了渐进式模态强化(Progressive modal Reinforcement, PMR)方法,该方法引入模态强化单元来学习跨模态元素之间的定向配对注意,以实现模态异步融合。尽管取得了进步,但目前的许多方法主要强调多个特征的集成,很少深入研究这些特征的相互作用,并且经常忽略微妙的异构特征
多模态transformer
Transformer是Vaswani等人(2017)引入的一种基于注意力的机器翻译模块。它通过聚合整个序列的数据来学习token之间的关系,在语音处理、自然语言处理和计算机视觉等各种任务中表现出出色的建模能力(Kenton and Toutanova, 2019;Carion等,2020;Chen et al ., 2022;刘等,2023a;Tang et al ., 2023, 2022)。Dosovitskiy等人提出了一种方法,该方法包括在序列中添加一个额外的可学习令牌,以捕获分类信息。因此,它被用于多模态情感识别,以促进多模态序列之间的融合。例如,Yuan等人(2021b)提出了一种基于transformer的特征重构网络,用于处理随机缺失的多模态数据集。他们在前端采用了一种跨模态注意机制进行融合,并结合了一个缺失的重建模块来生成缺失的特征。Tsai等人(2019b)引入了一种端到端网络MulT,它利用跨模态注意机制在不同模态之间进行信息交互,实现了信息跨模态的潜在流动。虽然已经取得了一些进展,但现有的基于变换的方法主要是学习模态关系,仍然没有考虑到特定模态对情感交互的微妙异构特征,导致性能不佳。为了解决这一限制,我们提出的TMT可以通过先解耦然后与多个特征交互来更有效地获取多模态情感信息。
方法
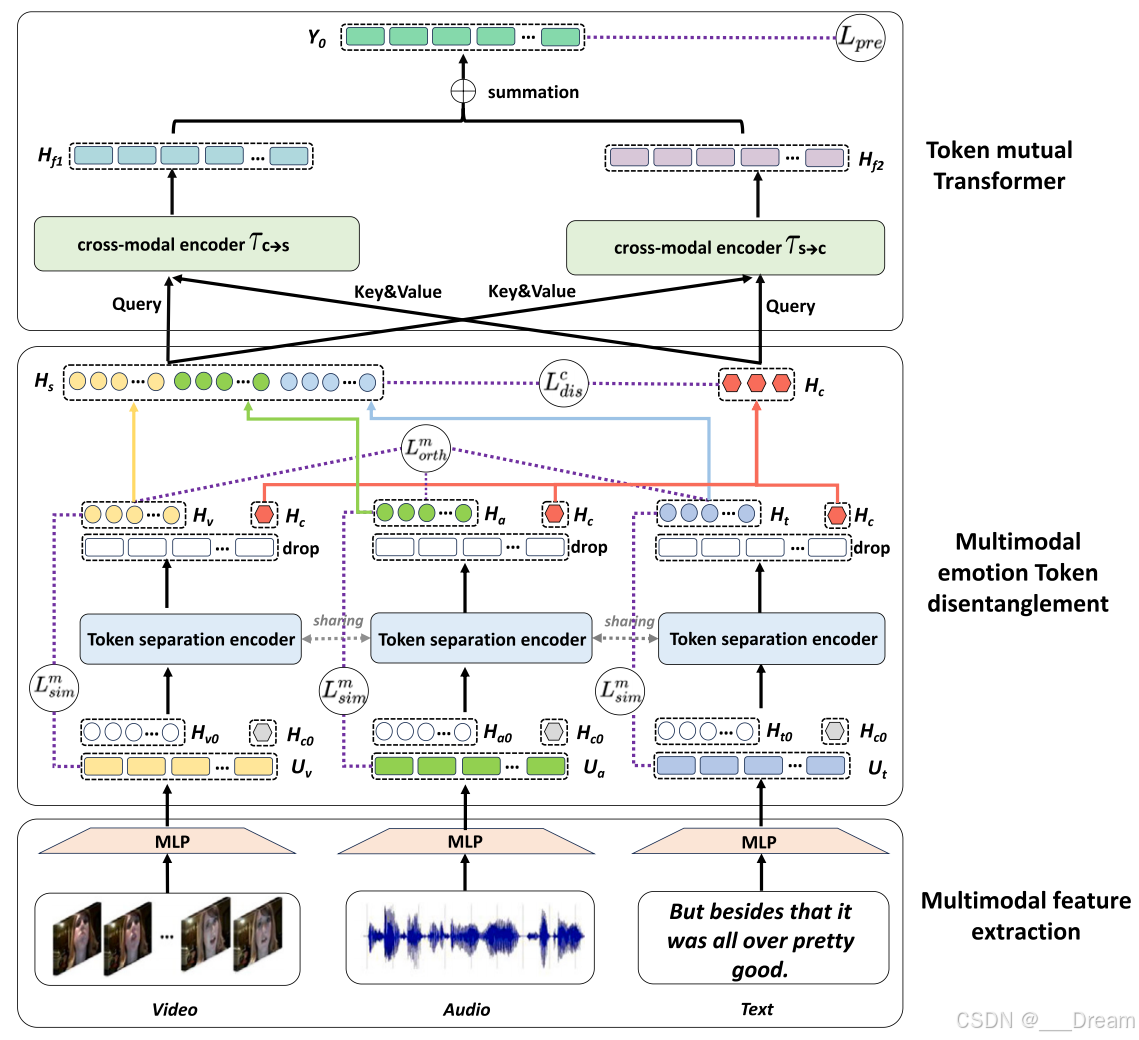
提出的用于多模态情感识别的Token-disentangling互变器(TMT)的训练管道。利用提取的多模态特征,TMT首先利用多模态情感Token解纠集将模态间情感一致性特征Token与每个模态内情感异质性特征Token分离,然后利用Token互变器在两个跨模态编码器中通过双向查询学习进行特征交互和融合,从而获得更全面的多模态情感表征。
针对传统的多模态情感识别Transformer注重特征融合而忽略跨模态交互的特点,本文提出了一种新颖有效的Token-disentangling互Transformer(即TMT),通过对多模态数据中的情感一致性和异质性信息进行充分的分离和交互,实现鲁棒多模态情感识别。图2显示了多模态情感识别的TMT训练管道,该管道由两个主要模块组成,即多模态情感Token解纠缠和Token互转换。具体而言,多模态情感Token解纠缠模块首先采用参数共享Token分离编码器及其Token解纠缠正则化(包括模态内相似损失、模态间正交损失和多模态解纠缠损失),利用三个多层感知器(MLP)从多模态数据中提取的多模态特征;分别将情感一致性特征Token从情感异质性特征Token中分离出来。然后,为了充分挖掘解耦Token在情感交互方面的贡献,我们进一步设计了带有两个跨模态编码器的Token互转换器,利用双向情感查询学习进行情感特征融合,从而获得更全面的多模态情感表征,实现鲁棒多模态情感识别。

为了帮助用户更好地理解所提出的方法,我们在表1中总结了所提出方法中定义的所有符号。我们将在以下章节中描述多模态情感令牌解缠和令牌相互转换。
多模态特征提取
对于正常的多模态情感识别,我们分别使用符号𝑈𝑎、𝑈𝑣和𝑈𝑡来表示音频、视频和文本的输入多模态信息。在相关文献中(Mao et al, 2022),通常使用预先计算的特征,而不是不同模态的原始数据。因此,公平地说,我们论文中的𝑈𝑎,𝑈𝑣和𝑈𝑡代表了预先计算的特征向量。例如,不使用视频的2D图像,我们可以将预先计算的视频模态特征![]() 作为视频输入,其中𝑇𝑜表示视频的长度,𝑑𝑣表示每个视频特征向量的长度。因此,我们还将预先计算的文本和音频模式的特征作为输入
作为视频输入,其中𝑇𝑜表示视频的长度,𝑑𝑣表示每个视频特征向量的长度。因此,我们还将预先计算的文本和音频模式的特征作为输入![]() 和
和![]() ,
,![]()
分别表示对应文本和音频特征向量的长度。在多模态情感识别的文献中,预先计算特征的使用已被广泛接受。对于预先计算的特征𝑈𝑎,𝑈𝑣,𝑈𝑡,我们使用三个并行多层感知器(表示为𝑀𝐿P),即全连接层,将每个特征向量的序列维度归一化为𝑑= 256。与这三个归一化特征向量,然后执行连接操作![]() ,从而获得多通道3维的特征向量
,从而获得多通道3维的特征向量![]() 。
。
多模态情感符号解缠
token分离编码器
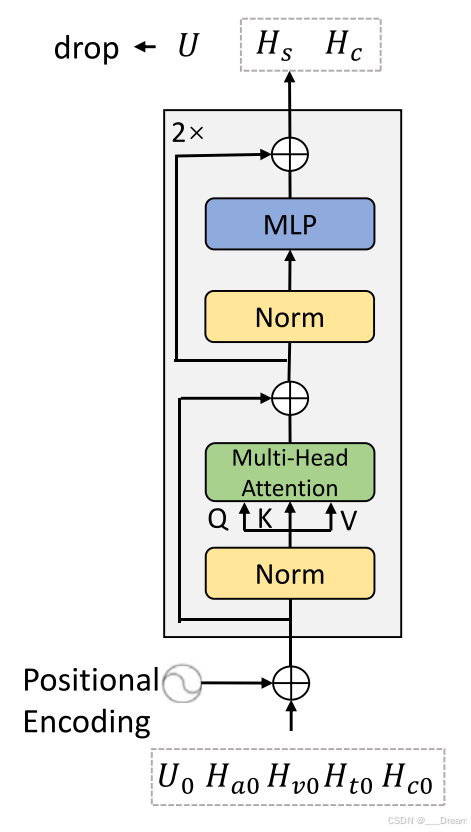

Q1:作者的描述令我混乱,从MLP层提取出来的只有Ua,Uv,Ut和一个组合向量U0,我的疑问是,Hv0,Ha0,Ht0是怎么得到的?Hc0又是怎么得到的?
A1:
初始步骤和Token的初始化
初始Token的生成:
- Ha0,Hv0,Ht0 和 Hc0 是作为模型输入的一部分随机初始化的。这意味着在训练开始时,这些Token只是随机值,没有具体的语义意义。
设计意图:
- Ha0,Hv0,Ht0 分别旨在捕捉音频、视频和文本模态的独特情感特征,而 Hc0 设计用来捕捉跨模态的共享情感特征。
模型结构和特征提取
- 特征融合与编码:
- 初始的多模态向量 U0 是通过 Ua,Uv,Ut 的组合生成的,通常是通过简单的拼接(concatenation)操作。
- U0 与初始化的 Ha0,Hv0,Ht0,Hc0 一起输入到Token分离编码器。
Token分离编码器的工作原理
- Token分离编码器 T(⋅) :
- 输入: Ha0,Hv0,Ht0,Hc0 和 U0 被合并作为Token分离编码器的输入。
- 自注意力机制: 在Token分离编码器中,通过自注意力层处理这些合并的输入。每个Token通过与其他Token的交互被进一步更新和精炼。
特征学习和更新
- 更新过程:
- 通过编码器中的自注意力和前馈网络,每个Token(Ha0,Hv0,Ht0,Hc0)被更新,以更准确地反映其对应模态的特定情感特征或跨模态的共享特征。
- 这些更新是基于它们与模态特征 Ua,Uv,Ut 以及组合向量 U0 的交互。
输出和解耦
- 输出:
- 经过训练和多次迭代后,Ha0,Hv0,Ht0,Hc0 逐渐学习到并捕捉其各自模态的情感特征和跨模态共享的情感特征。
这个过程中的关键是通过训练和模型内部的机制(如自注意力)使得这些初步随机的Token逐渐与数据特征对齐,从而有效地表示各自模态的情感特征或跨模态的共性特征。
Q2:从模型图上来看,Hv,Ha,Ht是从不同的token separation encoder生成的,另外还生成了三个Hc,怎么解释这一步,和你之前说的U0 与初始化的 Ha0,Hv0,Ht0,Hc0 一起输入到Token分离编码器得到Hc,Hv,Ha,Ht是否矛盾?
A2:确实存在潜在的矛盾或者解释上的不清晰
图中显示了三个独立的token 分离编码器,每个编码器处理不同的模态,并且没有涉及到U0,这个只能看代码知道作者到底用的什么方法了。
Q3:输入编码器的特征是什么?Hv0和Hc0吗?可是这两个不是随机生成的吗?为什么可以管用?
A:您的问题涉及到多模态学习中的一个重要方面:如何有效地从初始的、未训练的或随机初始化的Token中提取有用的特征。这里的核心在于理解Transformer编码器和神经网络学习机制如何能够从随机初始化的数据中学习到有意义的表示。
随机初始化的Token如何变得有用
参数初始化:
- 在深度学习中,随机初始化是一种常见的技术,用于开始训练过程。这包括权重和有时包括特征表示(如Token)。初始的随机性可以帮助模型避免在训练开始时陷入局部最优。
- 随机初始化的 Hc0H_{c0}Hc0 和 Hv0H_{v0}Hv0 之类的Token被设计为通过学习过程调整其值,从而更好地表示数据的底层结构和关系。
自注意力机制的作用:
- Transformer编码器通过自注意力层处理这些Token,计算不同Token之间的关系。即使这些Token最初是随机生成的,注意力机制也可以通过加权和组合这些Token的特征来发现和增强数据中有意义的模式。
- 自注意力层使得模型能够根据输入数据动态调整Token的表示,从而学习到哪些特征对于分类或其他任务是重要的。
学习过程:
- 在训练过程中,模型通过后向传播和梯度下降不断更新Token和网络参数。这意味着即使Token是随机初始化的,它们也会逐渐演化成为能够有效捕捉和表示输入数据特征的向量。
- 训练的目标是最小化输出和真实标签之间的差异,通过这个过程,模型学会如何调整这些初始化的Token,使它们对最终任务有用。
为什么这种方法有效
- 表示学习:Transformer的核心优势之一是其能力在于学习复杂的、高维的数据表示。通过自注意力和多层处理,模型能够从原始或随机的输入中提取有意义的信息。
- 数据驱动:这种学习过程完全是数据驱动的,意味着模型的有效性和学习的深度直接受到可用数据量和数据质量的影响。
- 多模态融合:在多模态设置中,不同模态的信息可以在模型中相互补充,增强了从任一单一模态中无法完全捕获的信息的表达。
综上,虽然输入Token Hc0H_{c0}Hc0 和 Hv0H_{v0}Hv0 等最初是随机初始化的,但是通过适当的训练和利用Transformer架构的强大表示能力,它们可以转化为对最终任务有极大帮助的有意义的特征表示。这种从“无到有”的转变是深度学习特别是在使用强大的模型架构时的一个重要特点。
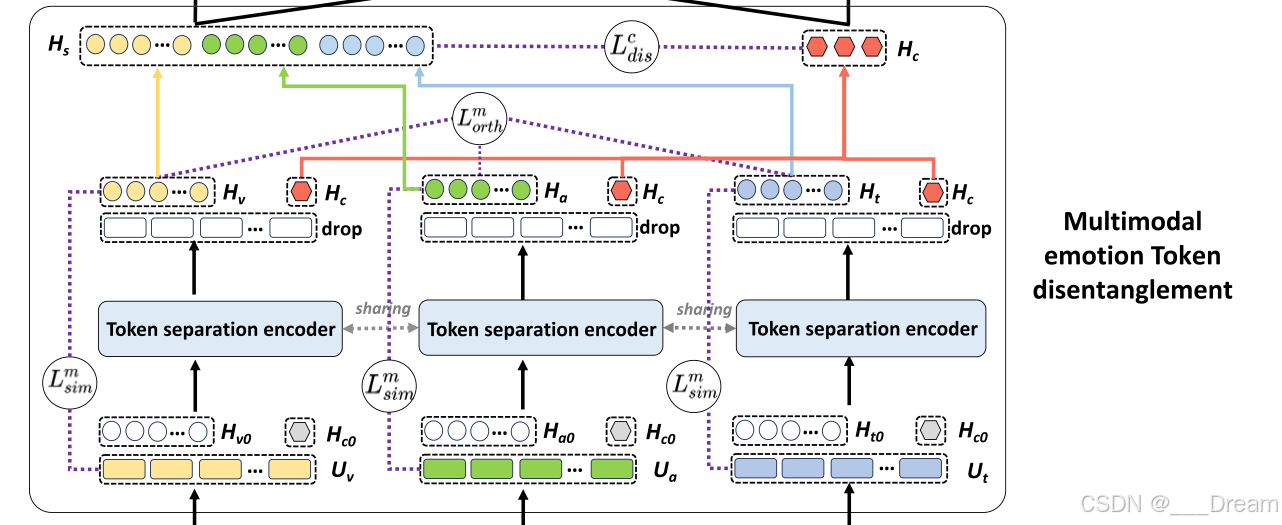
令牌解纠缠正则化

模态内相似性损失

Q:逐步解释一下模态内相似损失函数
A:
这个损失函数的核心目的是确保模型从每种模态(如文本、音频、视频)提取的特征Token与原始的模态输入特征在统计分布上尽可能相似。这有助于模型更准确地捕获和表达每种模态的本质特征。
其中,MMD(Ut,Ht),MMD(Ua,Ha),MMD(Uv,Hv)这些项分别计算文本Ut,Ua和Uv的原始特征向量与相应模态的特征Ht,Ha,Hv之间的最大均值差异。
最大均值差异MMD是一种衡量两个概率分布差异的非参数检验方法。它通过比较在再生核希尔波特空间(RKHS)中的均值嵌入来实现。具体来说,MMD检验的是两个分布的样本均值在高维空间中的距离:
在这里,p 和 q 分别代表了原始模态特征和模型生成的特征Token的分布。通过最小化这些分布之间的MMD,模型被训练来使生成的Token在统计上更接近于原始的模态特征,从而捕捉每种模态数据的本质属性。
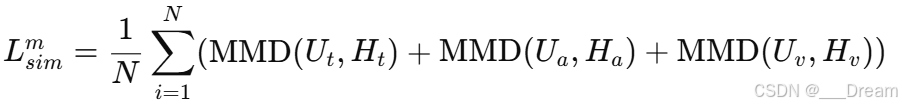

模态间正交损失

Q:逐步解释一下模态间正交损失函数
A:这种损失的核心是使用Frobenius范数度量两个矩阵的点积,从而强制不同模态的特征Token相互正交(即点积为零或接近零)。具体的公式如下:
具体意义和作用:
正交性的重要性:在多模态学习中,如果不同模态的特征之间存在高度相关性(即非正交),模型可能无法区分这些模态所独有的信息,从而导致信息冗余和模型性能下降。通过强制这些特征正交,可以确保它们各自独立地贡献于最终任务的解决,增加模型的信息利用效率。
降低冗余:正交约束帮助模型在处理具有复杂交互的多模态数据时,更有效地隔离和利用每种模态的独特信息。这样不仅减少了冗余,也提升了模型对于每种模态信息的敏感性和响应性。
在模型中的应用:
- 训练过程中的应用:在模型的训练过程中,通过加入这种正交损失,可以作为正则化项,帮助模型在损失函数的其他部分(如分类损失、重构损失等)外额外确保特征的独立性。
- 特征解耦:此损失不仅仅是正则化,它在特征解耦的目标中起到直接作用,帮助模型学习到能够更全面表达数据而不是混合噪声和冗余信息的特征。
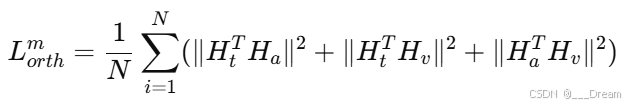

模态解离损失

Q:模态解离损失和模态间正交损失有什么区别吗?
A:在多模态学习的背景下,尽管模态间正交损失(Inter-modality Orthogonal Loss)和多模态解耦损失(Multimodal Disentanglement Loss)听起来具有不同的目标,但两者在实际应用中可能采用类似的数学形式。这种情况可能是因为两者的目标在数学实现上具有相似性,或者是在某些情况下,两个概念在实际操作中被视为达成相同的最终效果。这里我们可以探讨这种现象的可能原因及其在模型中的实现方式。
相似性的原因:
目标重叠:
- 模态间正交损失旨在确保不同模态的特征在表示上相互独立。这意味着,例如文本和音频的特征不应该包含太多相同或相似的信息。
- 多模态解耦损失则可能更关注于确保跨模态一致性特征 Hc 与各自模态特异性特征 Ht,Ha,Hv 的独立性。这有助于模型更好地区分哪些是共享的一致性信息,哪些是每个模态特有的信息。
损失函数实现:
- 在某些情况下,这两种损失函数都可以通过约束特征向量的点积来实现。例如,可以使用Frobenius范数来度量两个特征向量之间的点积,并通过最小化这个度量来鼓励特征向量之间的正交性。
token交互transformer
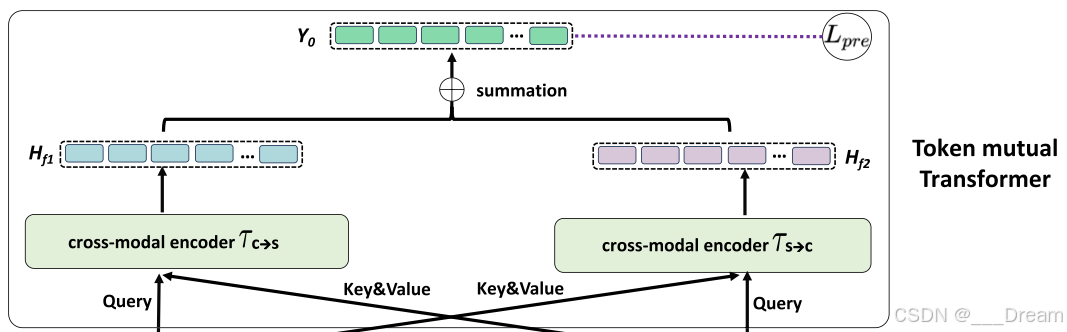
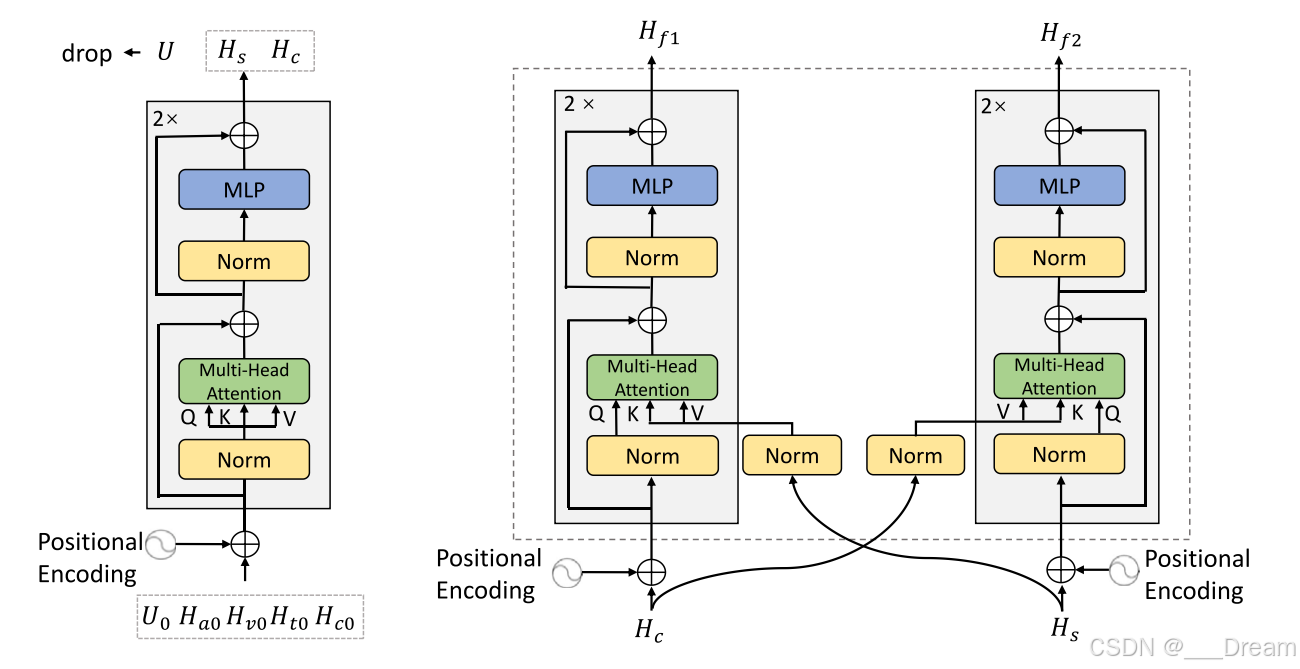
图3所示。TMT中的Transformer结构。(a) Token分离编码器的详细结构;(b) Token互感器中跨模态编码器的体系结构。
通过将解耦后的情感相关的跨模态一致性特征Token以及各内模态异质性特征Token转化为查询(query)、键(key)和值(value)的表示形式,普通的变换器(Transformer)可以模拟查询和键之间的关系,以实现查询和值之间的有效融合。
为了获得有希望的情感识别性能,获得一个全面且稳健的查询表示对变换器来说至关重要。然而,我们发现现有的变换器方法主要依赖于来自特定模态的查询表示,这可能会倾向于关注与查询模态表示相关的情感特征,并忽视微妙的情感交互,导致融合不完整,影响识别性能。
为了解决这一限制并获得更全面、更稳健的情感表示,我们进一步设计了Token互助变换器(Token mutual Transformer),通过在两个跨模态编码器中使用双向查询学习,完全探索不同解耦特征在情感交互方面的贡献,从而实现有效的信息融合,提高情感识别性能。Token互助变换器的详细架构如图3(b)所示。
形式上,给定三个解纠缠的模态内异质性特征令牌𝐻𝑎,𝐻𝑣,𝐻𝑡作为输入,我们首先将它们拼接形成异质性特征张量,表示为𝐻𝑠={𝑐𝑜𝑛(𝐻𝑎,𝐻𝑣,𝐻𝑡)}。然后,我们采用两个并行的跨模态编码器和双向查询学习来充分融合和交互𝐻𝑠和𝐻𝑐的情感信息。两个平行的跨模态编码器可以分别表示为![]() 和
和![]() 。他们分别使用𝐻𝑠和𝐻𝑐作为查询表征,通过自适应相互学习融合更全面互补的情感表征。每个跨模态编码器都遵循典型的Cross-Transformer编码器结构(Tsai et al ., 2019b),包括多头自关注层、归一化层和MLP层。
。他们分别使用𝐻𝑠和𝐻𝑐作为查询表征,通过自适应相互学习融合更全面互补的情感表征。每个跨模态编码器都遵循典型的Cross-Transformer编码器结构(Tsai et al ., 2019b),包括多头自关注层、归一化层和MLP层。
更具体地说,以模态内异质性特征张量𝐻𝑠作为查询,以模态间一致性特征Token 𝐻𝑐作为值和键,将跨模态编码器![]() 用于异质性对一致性情感融合的贡献,从而探索异质性特征对情感交互的贡献。
用于异质性对一致性情感融合的贡献,从而探索异质性特征对情感交互的贡献。![]() 使用查询张量作为参考,并根据𝑞和𝑘之间的关系将值张量转换为所需的输出。在转换过程中,采用多头注意机制实现关系建模和数据融合。
使用查询张量作为参考,并根据𝑞和𝑘之间的关系将值张量转换为所需的输出。在转换过程中,采用多头注意机制实现关系建模和数据融合。![]() 的学习过程可以实现为:
的学习过程可以实现为:

其中![]() 为异构到一致的融合特征,通过重构𝐻𝑠的情感信息并接收来自𝐻𝑐的信息,学习到更多与情感相关的有意义的信息。
为异构到一致的融合特征,通过重构𝐻𝑠的情感信息并接收来自𝐻𝑐的信息,学习到更多与情感相关的有意义的信息。
此外,我们使用解纠结的𝐻𝑐作为查询,𝐻𝑠作为键和值,遵循其他跨模态编码器![]() 进行一致性到异质性的情感融合,这倾向于探索一致性特征对情感交互的贡献。我们将
进行一致性到异质性的情感融合,这倾向于探索一致性特征对情感交互的贡献。我们将![]() 实现为:
实现为:

其中![]() 是一致性到异质性的融合特性。
是一致性到异质性的融合特性。
综上所述,通过两个跨模型编码器的双向查询学习,我们可以得到两个融合的情感表征,即![]() ,可以从不同的角度充分探索微妙的情感交互。最后,我们使用简单的求和运算对
,可以从不同的角度充分探索微妙的情感交互。最后,我们使用简单的求和运算对![]() 进行进一步整合,从而得到最终的综合多模态情感表示
进行进一步整合,从而得到最终的综合多模态情感表示![]() ,用于情感分类。在实践中,我们还使用了更复杂的注意机制来整合两种习得的融合表征,消融研究的结果(见4.5.7节)表明,简单的求和融合获得了最优的性能。
,用于情感分类。在实践中,我们还使用了更复杂的注意机制来整合两种习得的融合表征,消融研究的结果(见4.5.7节)表明,简单的求和融合获得了最优的性能。
整体学习目标
对于训练,TMT模型包括四个学习目标,即模态内相似性损失![]() 、模态间正交损失
、模态间正交损失![]() 、多模态解纠缠损失
、多模态解纠缠损失![]() 𝑠和情绪预测损失
𝑠和情绪预测损失![]() 。由于本研究中的情绪标签是多重的,即既包括离散的情绪类别标签,也包括连续的情绪评级。因此,我们引入交叉熵损失(Tsai et al ., 2019a)作为情绪学习损失
。由于本研究中的情绪标签是多重的,即既包括离散的情绪类别标签,也包括连续的情绪评级。因此,我们引入交叉熵损失(Tsai et al ., 2019a)作为情绪学习损失![]() 为分类,并且均方误差(MSE) (Hazarika et al ., 2020b)作为情绪学习损失
为分类,并且均方误差(MSE) (Hazarika et al ., 2020b)作为情绪学习损失![]() 为回归。数学上,
为回归。数学上,![]() 由下式给出:
由下式给出:
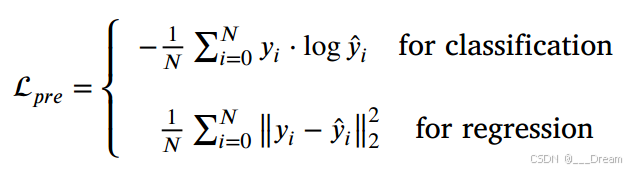
其中,![]() 部分表示预测结果,
部分表示预测结果,![]() 部分表示实际标签,N表示训练样本的个数。数学上,TMT的总体学习目标可以写成:
部分表示实际标签,N表示训练样本的个数。数学上,TMT的总体学习目标可以写成:
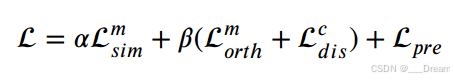
其中,α和β为平衡多任务学习的各子空间约束损失的权值分布。
Q:为什么一个用于分类一个用于回归?这个是怎么设计的?
A:

experiments
datasets
我们使用三种广泛使用的多模态情绪数据集来评估TMT模型:CMU-MOSI (Zadeh等人,2016a), CMU-MOSEI (Zadeh等人,2018b)和CH-SIMS (Yu等人,2020)。
CMU-MOSI数据集(Zadeh等人,2016b)是一个广泛使用的多模态情感识别数据集,包括视频、文本和音频模态。它由89位演讲者的89个视频组成,总共有2199个视频片段。每个片段都被手工标注了情绪得分,范围从- 3到3,分为七个级别。−3表示极度消极的情绪,3表示极度积极的情绪。
CMU-MOSEI数据集(Zadeh等人,2018b)是最广泛的多模态数据集之一,包括视频、文本和音频模态。它包括来自1000多名解说员的视频,有23453个视频片段。该数据集提供了情绪和情绪的两个标签,情绪分为六类:愤怒、快乐、悲伤、惊讶、恐惧和厌恶。情绪强度在−3到3的连续尺度上标注,涵盖了从极端消极到极端积极的情绪。视频和音频特征分别以15hz和20hz采样。
CH-SIMS数据集(Yu et al, 2020)是一个流行的中国细粒度多模态情感数据集,包含2,281个精细视频剪辑,具有三种模态:视频、文本和音频。CH-SIMS分别注释每个模态,以更好地捕获它们的相互作用,不像前两个数据集。标签的取值范围为−1 ~ 1,分为“负”、“中性”和“正”3类,共11种不同的强度。消极情绪包括−1.0和−0.8;弱负面情绪包括- 0.6、- 0.4和- 0.2;中性标记为0;弱积极情绪包括0.2、0.4和0.6,积极情绪包括0.8和1.0。
实现细节
本文所描述的实验使用PyTorch 1.11.0进行,并在NVIDIA GeForce RTX 2080Ti GPU上进行训练。
多模态情感令牌解纠缠模块中的令牌分离编码器和令牌互变模块中的跨模态变压器编码器都有两层。按照典型的crosstrtransformer编码器结构(Tsai et al ., 2019a),这些编码器的每一层包括一个8头多头自注意、2级归一化和一个256 dim MLP。对于所有三个数据集:CMU-MOSI, CMU-MOSEI和CH-SIMS,批量大小为16。
使用Adam优化器进行学习,CMU-MOSI数据集的学习率为0.001,CMU-MOSEI和CH-SIMS数据集的学习率为0.002。模态间情感一致性特征Token维度为6 × 256,各模态异质性特征Token维度为2 × 256。
整体性能
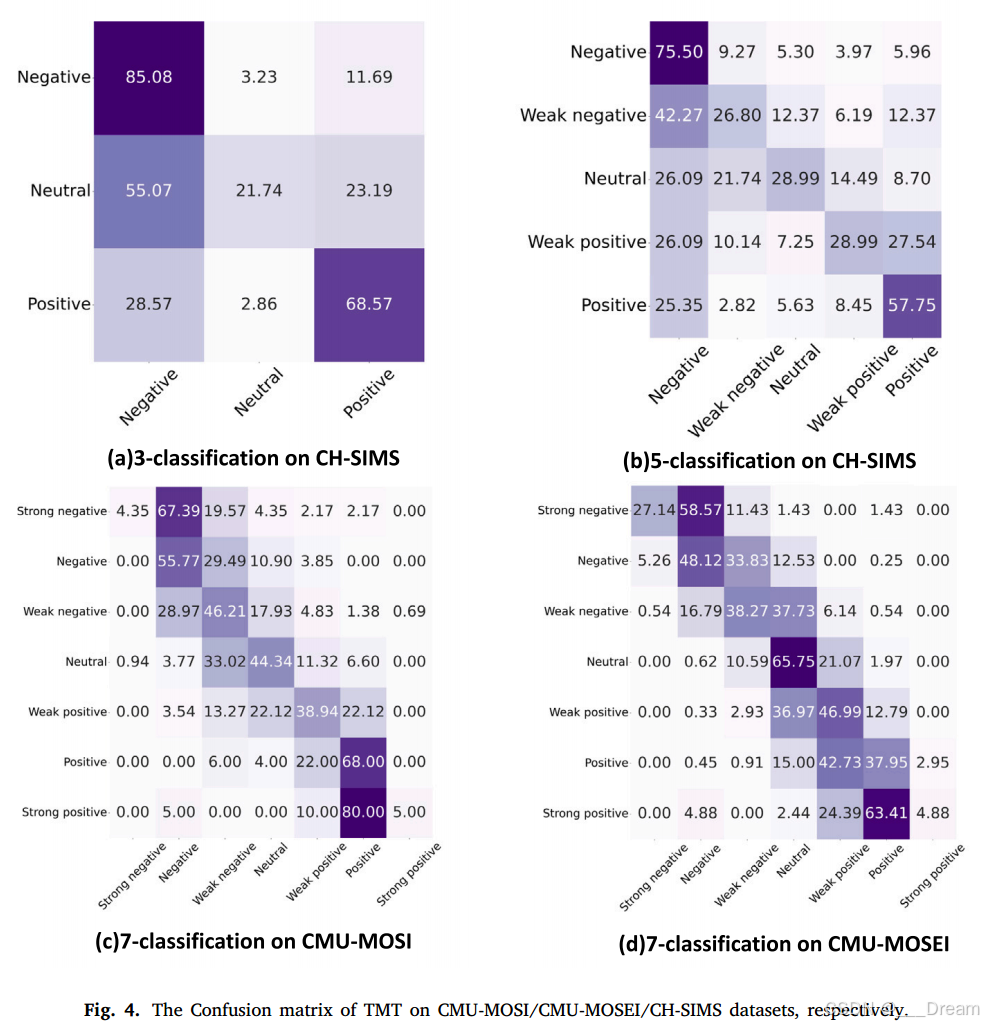
TMT在CMU-MOSI/CMU-MOSEI/CHSIMS数据集上的混淆矩阵分别如图4所示。此外,我们还可视化了CMU-MOSI、CMU-MOSEI和CH-SIMS数据集上的一些预测结果,以便在图5中进行分析。从图5(a)和图5(c)可以看出,我们的模型对分类和回归任务的预测结果都是准确的,这证明了我们模型的稳健性。如图5(b)所示,对于样本Video_0006 clip1,虽然我们的模型在5分类任务中可能会对“Weak positive”做出错误的预测,但在3分类任务中,它准确地预测了正确的分类。这导致在三分类任务中正确预测“正面”类的准确率为68.57%(见图4(a)),但在图4(b)中描述的五分类任务中下降到57.75%。此外,CMU-MOSI数据集中回归值与真实值之间的差异可能会导致分类任务中的误分类。从图5(d)可以看出,在样本cW1FSBF59ik clip24上,我们的模型的回归预测值为- 0.4,而地面真值为0。这也会导致7分类任务中的错误。因此,在图4(c)中,中性作为弱阴性的错误分类率为33.02%。
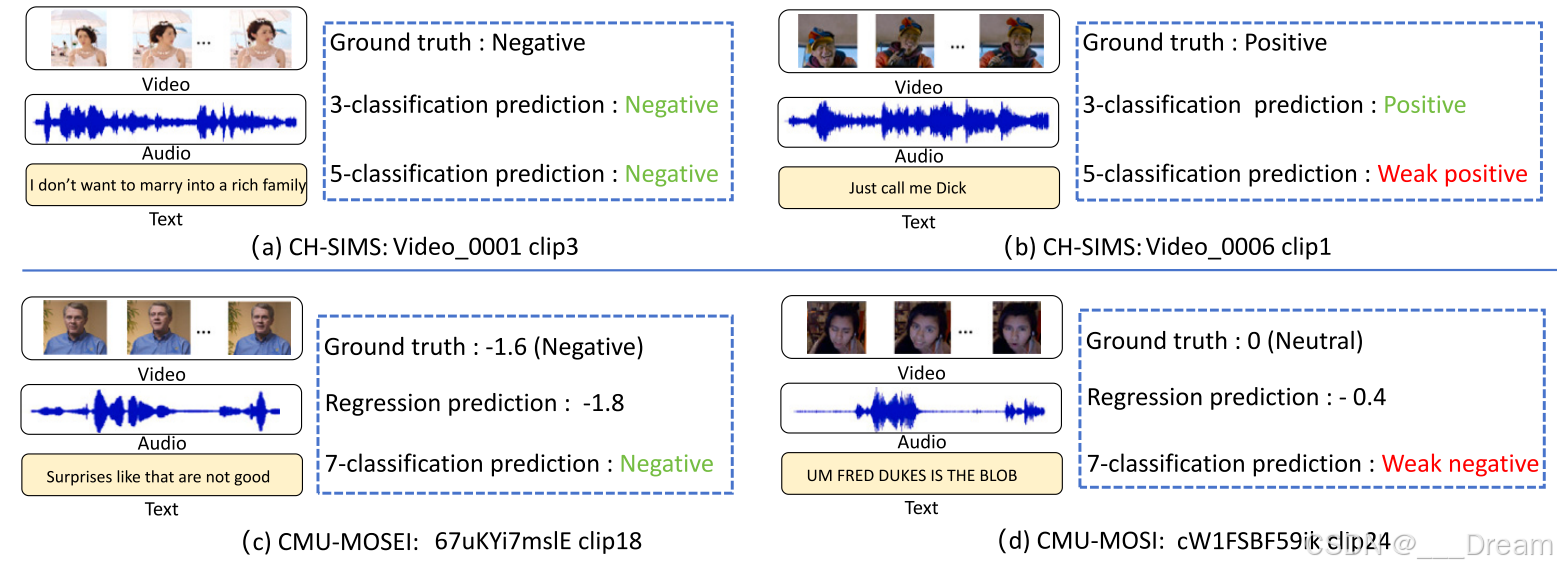
图5:TMT模型预测的样本可视化,其中绿色高亮的代表正确预测结果,红色高亮的代表错误预测结果。
综上所述,虽然我们的模型在分类和回归任务上都取得了令人满意的结果,但在增强鲁棒性方面仍有改进的空间,尤其是在高维分类任务上。
评估
为了对模型进行综合评价,我们采用Pearson相关系数(Corr)和平均绝对误差(MAE)作为评价指标。采用Acc-2和F1作为二值分类评价标准。采用阴性/非阴性和阴性/阳性分类评估Acc-2。对于7分类任务,我们采用Acc-7度量进行评估。值得注意的是,MAE是唯一一个认为值越小越好的指标,而其他四个指标则受益于值越大。
本文采用了所提出的TMT模型,并在三个广泛使用的多模态情绪数据集上进行了比较:CMUMOSI (Zadeh等人,2016b)、CMU-MOSEI (Zadeh等人,2018b)和CH-SIMS (Yu等人,2020)。我们的实验结果表明,我们的方法在这三个数据集上的性能超过了现有最先进的方法,包括TFN (Zadeh等人,2017b)、MFM (Tsai等人,20119c)、MULT (Tsai等人,2019b)、MISA (Hazarika等人,2020b)、ICCN (Sun等人,2020b)、Self-MM (Yu等人,2021)、CubeMLP (Sun等人,2022)和TETFN (Wang等人,2023)。图4显示了CH-SIMS数据集上3类和5类情绪识别的TMT混淆矩阵,以及CMU-MOSI和CMU-MOSEI数据集上7类情绪识别的TMT混淆矩阵。
CMU-MOSI数据集的比较
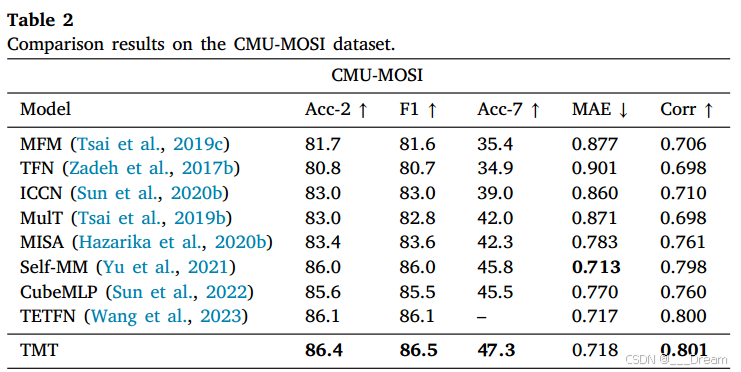
表2给出了CMU-MOSI数据集上的比较结果。
与目前最先进的模型相比,TMT模型在几乎所有指标上都表现出优越的性能。Acc-2准确率达到86.43%,F1得分达到86.5,Acc7准确率达到47.3%。MAE值降至0.718,表明准确率提高,相关系数(Corr)增强至0.801。在Acc-7指标上,我们的TMT方法比Self-MM高1.5%,比CubeMLP高1.8%。与TETFN相比,我们的TMT在所有指标上都达到了最先进的性能。
这归功于我们基于token学习的解纠缠方法,该方法学习了更全面的多模态表示,促进了随后的融合过程。这些进步表明,与以前最先进的模型相比,两类和七类的分类精度都有了显著提高。
CMU-MOSEI数据集的比较
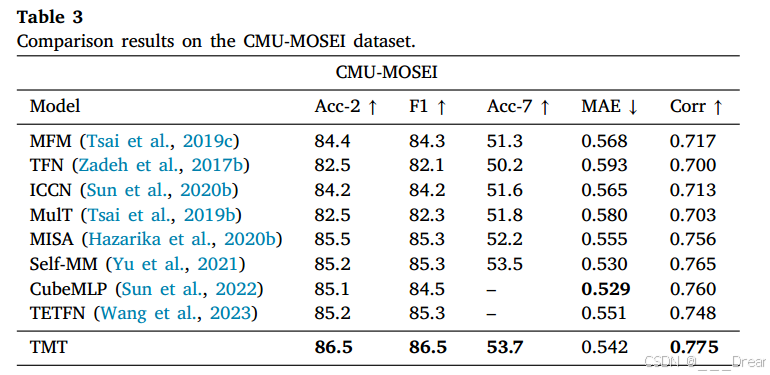
表3显示了我们提出的TMT方法与现有模型在CMU-MOSEI数据集上的比较结果。我们的TMT模型在几乎所有指标上都优于当前最先进的模型。我们的模型的Acc-2精度为86.5%,比MFM (Tsai et al ., 2019c)的精度高2.1%。此外,我们的模型达到了53.7%的Acc-7精度,比MISA (Hazarika et al, 2020b)的精度高出1.6%。这些结果证明了我们的方法在CMU-MOSEI数据集上的优越性。我们的TMT方法在Corr度量上优于Self-MM 0.01和CubeMLP 0.015。与次优化结果TETFN相比,TMT在所有指标上都达到了最先进的性能。我们领先的原因是我们的TMT通过基于token学习的解纠缠方法简化了模型的复杂性,同时获得了更全面的表示。此外,它补充并完全集成了未纠缠的特性。
CH-SIMS数据集的比较
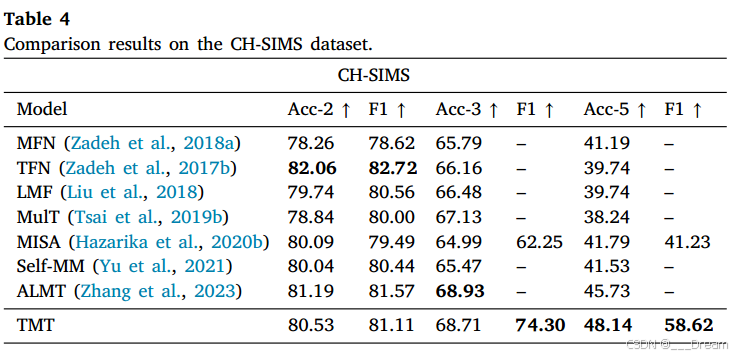
表4给出了我们提出的方法与现有模型在CH-SIMS数据集上的比较结果。我们的方法在所有指标上都优于目前的主流模型,其中TMT的性能最好。具体来说,我们的模型达到了48.14%的ac -5准确率,显著高于当前最先进的模型MISA (Hazarika et al, 2020b) 6.35%。我们的模型在Acc-3和Acc-5指标上分别比Self-MM提高了3.24%和6.61%。与最新的方法ALMT相比,我们的TMT在Acc-5上仍然领先2.41%。这是因为我们的TMT方法充分解开并融合了相互作用的情态间情绪一致性特征和情态内情绪异质性特征。
这表明我们的方法利用多模态情感Token解纠缠学习来获得全面、鲁棒的情感表示,提高了多模态情感识别的准确性。
消融实验
为了全面评估我们提出的模型的有效性,我们在随后的章节中提供了CMU-MOSI, CMUMOSEI和CH-SIMS数据集的详细消融结果。在接下来的章节中,我们将全面描述从烧蚀实验中获得的结果。
解缠特征令牌的效果

为了证明分离出来的模态间情绪一致性特征Token和模态内情绪异质性特征Token的有效性,我们进行了消融实验,从模型中去除一致性特征或异质性特征,观察其表现,见表5。在多模态情感互变过程中,我们只向Token互变模块发送模态间情感一致性特征令牌(或模态内情感异质性特征令牌)。表5的结果表明,去除一致性或异质性特征都会导致情绪识别准确率下降。
去除情感一致性特征后,CMU-MOSI/CMU-MOSEI数据集的MAE分别提高到0.790/0.781。当不考虑异质性特征时,CMU-MOSI/CMU-MOSEI数据集的MAE分别增加到0.750/0.690。CH-SIMS数据集的Acc-5指标分别下降2.19%和2.0%。这表明多模态情感Token解纠缠模块解纠缠的两个特征都是有意义的。此外,对比上述两个消融实验可以发现,只保留一致性特征的影响明显小于只保留异质性特征的影响,说明模型提取的情绪一致性特征比情绪异质性特征对情绪识别更为重要。
关键模块的效果
多模态Token disentanglement的影响

为了评估多模态情感Token解纠缠模块的贡献,我们删除了TMT中的情感解纠缠模块,并直接用MISA中的mlp替换它们(Hazarika et al, 2020b),以获得情感表征。实验结果见表6“w/o-多模态情感Token解缠模块”。在CMU-MOSI、CMUMOSEI和CH-SIMS数据集上的实验结果表明,去除多模态情感标记解纠缠模块导致模型的识别性能显著降低。其中,CMU-MOSI和CMU-MOSEI的相对MAE分别增加0.015和0.001。
CH-SIMS数据集上的Acc-2指标降低了1.97%。
这表明,多模态情感Token解纠缠模块由于更有效地学习了情态中的情感信息,显著提高了多模态情感识别的结果。
token mutual transformer的影响
为了演示Token互感器模块的影响,我们删除了TMT中的融合模块,并用简单的逐行拼接操作取而代之。具体来说,对于获得的解纠缠特征𝐻𝑠和𝐻𝑐,每个特征的维度都是B × 6 × 256(其中B表示批大小),我们直接将𝐻𝑠和𝐻𝑐连接起来,得到维度B × 12 × 256。随后,我们沿着第一个维度进行平均,得到维度为B × 256的多模态特征,用于情绪预测。实验结果如表6“w/o-Token互感器模块”所示。
结果表明,在后期融合中直接使用逐行拼接操作会使模型在这三个数据集上的性能有不同程度的下降。同时,CMUMOSI/CMU-MOSEI数据集上的MAE分别提高了0.029/0.002。
CH-SIMS数据集上的Acc-2指标降低了2.90%。实验结果表明,Token互感器模块有利于提高模型的性能。
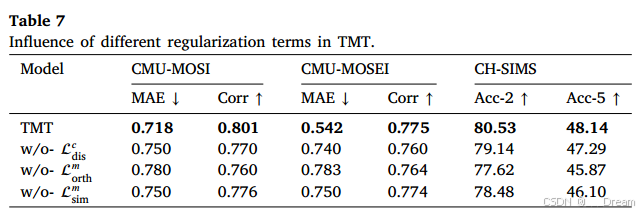
不同正则化项的影响
我们建立了三个损失函数来约束模型,以分离出情绪异质性特征和一致性特征。为了证明不同损失函数的重要性,我们探讨了在没有其中一个损失函数的情况下模型的表现。不同正则化项的影响如表7所示。从表7可以看出,这三种损失对MAE在三个不同数据集上的性能影响是不同的。这种效应的变化主要归因于数据集规模和收集背景的差异。例如,CMU-MOSI数据集包含2199个样本,CH-SIMS数据集包含2281个样本,CMU-MOSEI数据集更大,有23,453个样本。此外,CMU-MOSI和CMU-MOSEI数据集采集自英语视频背景,而CH-SIMS数据集采集自中文视频背景。这些都会影响训练过程中特征解耦和融合的学习效果。
没有![]() :在不使用多模态解纠缠损失的情况下,模型性能有所下降,CMUMOSI/CMU-MOSEI数据集上的MAE也分别提高到0.77 /0.760。CH-SIMS数据集上的Acc-5指标降低了0.85%。可能的原因是
:在不使用多模态解纠缠损失的情况下,模型性能有所下降,CMUMOSI/CMU-MOSEI数据集上的MAE也分别提高到0.77 /0.760。CH-SIMS数据集上的Acc-5指标降低了0.85%。可能的原因是![]() 的缺失导致一致性和异质性特征之间的解耦不足,导致模型性能显著下降
的缺失导致一致性和异质性特征之间的解耦不足,导致模型性能显著下降
没有![]() :模态间正交损失的缺失导致了模型性能的下降。例如,CMU-MOSI/CMU-MOSEI数据集的平均绝对误差(MAE)分别增加到0.780/0.783。CHSIMS数据集上的Acc-5指标降低了2.27%。这是因为学习到的异质性特征在模式之间没有有效地分离,导致模型性能下降。
:模态间正交损失的缺失导致了模型性能的下降。例如,CMU-MOSI/CMU-MOSEI数据集的平均绝对误差(MAE)分别增加到0.780/0.783。CHSIMS数据集上的Acc-5指标降低了2.27%。这是因为学习到的异质性特征在模式之间没有有效地分离,导致模型性能下降。
没有![]() :去掉模态内相似度损失后,CMU-MOSI/CMU-MOSEI数据集的MAE也分别增加到0.750/0.750。CH-SIMS数据集上的Acc-5指标降低了2.04%。由于缺乏MMD损失,使得模态内情感异质性特征Token的数据分布与模态输入特征向量的数据分布差异太大
:去掉模态内相似度损失后,CMU-MOSI/CMU-MOSEI数据集的MAE也分别增加到0.750/0.750。CH-SIMS数据集上的Acc-5指标降低了2.04%。由于缺乏MMD损失,使得模态内情感异质性特征Token的数据分布与模态输入特征向量的数据分布差异太大
此外,由于这些数据集的显著差异,我们发现三种损失对Corr性能的影响也略有不同。去除多模态解纠缠损失![]() 、模态间正交损失
、模态间正交损失![]() 和模态内相似性损失
和模态内相似性损失![]() 后,CMU-MOSI数据集的Corr指标分别下降0.031/0.041/0.025和0.015/0.011/0.001
后,CMU-MOSI数据集的Corr指标分别下降0.031/0.041/0.025和0.015/0.011/0.001
不同模式的影响
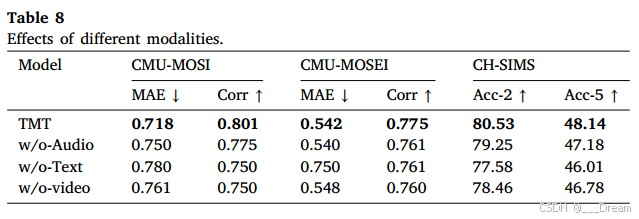
为了评估不同模式对情感识别的影响,我们系统地排除了文本、视频和音频模式的组合特征向量,并分析了它们的效果。实验结果如表8所示。如表8所示,去除任何模态都会导致模型的相关性(Corr)降低,平均绝对误差(MAE)升高。其中,当省略文本模态时,CMU-MOSI/CMU-MOSEI数据集的Corr分别降低0.051/0.014,MAE分别增加0.062/0.208。CH-SIMS数据集上的Acc-5指标降低了2.13%。这些发现强调了三种模式之间相互作用的互补性,从而提高了情绪识别的准确性。值得注意的是,当删除文本模态时,性能下降最为明显。例如,在CMU-MOSEI数据集中,MAE从0.542增加到0.750。这表明文本信息包含了在多模态情感识别中占主导地位的关键情感线索。因此,文本信息的删除对模型的性能有很大的影响
不同减重参数的影响
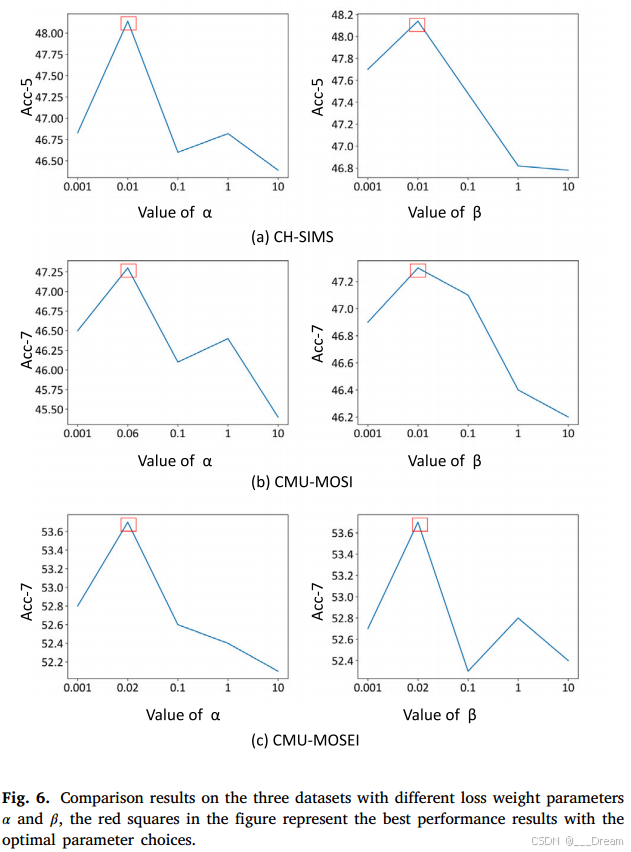
图6显示了Eq.(9)中的关键参数选择。我们分别在CMU-MOSI、CMU-MOSEI和CH-SIMS数据集上进行了大量具有不同损失权参数(即时延、时延、时延)的实验。如图所示,在CHSIMS数据集上,当我们将其设置为0.01和0.01时,最高准确率(Acc-5)达到48.14%。Acc-7在CMU-MOSI数据集上实现了47.3%的效率,其中时延设置为0.06,时延设置为0.01。另外,在CMU-MOSEI数据集上,当设置为0.02和0.2时,Acc-7达到53.7%。图中的红色方块表示在最佳参数选择下的最佳性能结果。我们观察到,当参数设置过大或过小时,性能指标都会下降。
不同解缠方法的效果
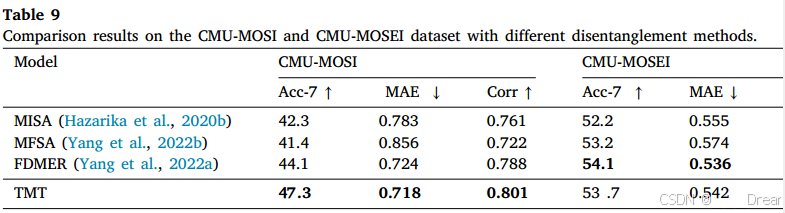
如表9所示,我们使用不同的解耦方法对CMU-MOSI进行了对比实验,以证明我们基于令牌分离编码器的方法的有效性。MISA (Hazarika等人,2020b)通过设计约束和编码器将每种模态投影到两个不同的子空间中。Yang等人(2022a)设计了一种特征分离多模态情感识别(FDMER)方法,该方法通过将每个模态投影到模态不变子空间和模态特定子空间来解决模态异质性问题。通过采用对抗性学习策略,他们改进了特征分离的公共和私有表示。MFSA (Yang等人,2022b)引入了一种在异步序列中学习有效多模态表示的方法,重点是特征解纠缠。
结果表明,我们的令牌分离编码器优于其他解纠缠方法。在Acc-7指标方面,在CMU-MOSI数据集上,它比MISA提高了11.8%,比MFSA提高了14.3%,比FDMER提高了12.4%在Corr指标方面,在CMU-MOSEI数据集上,它比MISA有2.5%的相对改善,比MFSA有7.0%的相对改善,比FDMER有0.3%的相对改善。这可以归因于Token学习对特征解缠的有效性。
不同融合方法的效果
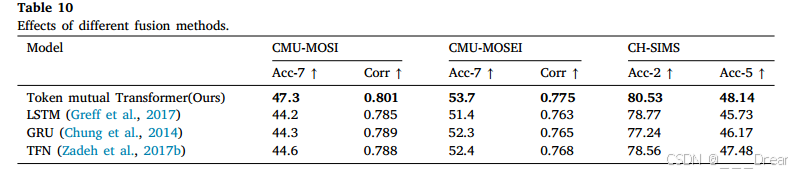
为了讨论不同融合方法的效果,我们比较了不同的融合技术,包括GRU (Chung等人,2014)、LSTM (Greff等人,2017)和TFN (Zadeh等人,2017b)分别在CMU-MOSI、CMU-MOSEI和CH-SIMS数据集上进行特征融合。
详细信息如表10所示。显然,我们的TMT在使用Token mutual Transformer进行特征融合时取得了最好的性能,这表明Token mutual Transformer通过双向查询学习来充分交互和整合情感一致性和异质性信息,通过探索它们在情感交互中的相互贡献,可以获得更互补的特征用于情感识别
token mutual transformer中不同特征集成机制的影响
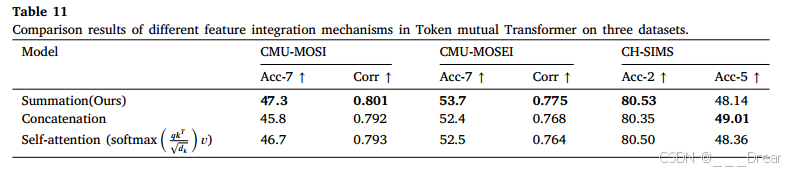
利用Token互感器模块得到的两个双向交互特征𝐻𝑓1、𝐻𝑓2,比较了三个数据集上不同的特征集成机制,包括特征的求和、连接和自关注。自关注融合过程遵循典型的Transformer编码器机制,其计算公式如表11所示。在这里,q、k和v的值是通过𝐻𝑓1和𝐻𝑓2的直接连接得到的。对比结果如表11所示。我们采用的简单的求和方法可以在三个数据集上获得更好的结果。
此外,我们观察到不同的融合方法对最终结果的影响很小,这表明𝐻𝑓1,𝐻𝑓2学习了全面互补的情绪信息
每个输入特征向量的维数的影响
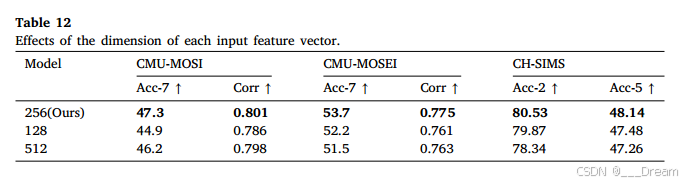
如表12所示,为了验证每个输入特征向量的序列维度对实验结果的影响,我们分别选取了128、256、512等不同的序列维度进行实验。实验结果表明,当每个输入特征向量的序列维数设置为256时,该模型在三个数据集上的整体性能最好。因此,考虑到效率和准确性之间的权衡,我们经验地将d的值设置为256(见表12)。
令牌分离编码器中不同层数的影响
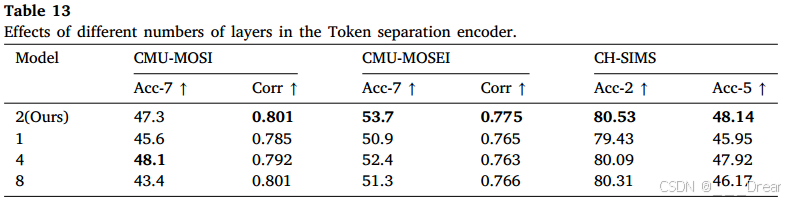
如表13所示,我们分别在CMU-MOSI、CMU-MOSEI和CH-SIMS数据集上给出了Token分离编码器中不同层数的实验结果。我们发现在令牌分离编码器中选择2层时,可以获得最佳的性能。值得注意的是,当模型的层数设置为4时,虽然模型在ccu - mosi数据集上的Acc7中性能最好,但在Corr中的性能相对较差。因此,基于这些观察,我们经验地选择了一个两层模型。
令牌互感器中不同层数的影响
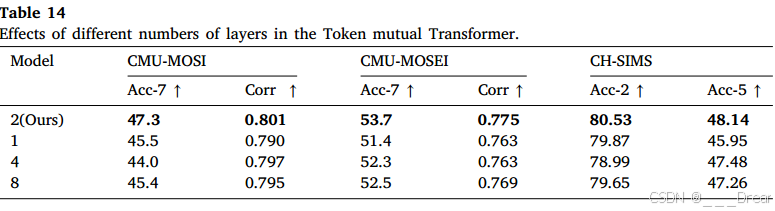
如表14所示,我们分别在CMU-MOSI、CMU-MOSEI和CH-SIMS数据集上给出了令牌互感器中不同层数的实验结果。我们将层数设置为1、2、4和8进行消融实验。结果表明,带两级编码器的令牌互感器达到了最佳性能。
模型复杂度分析
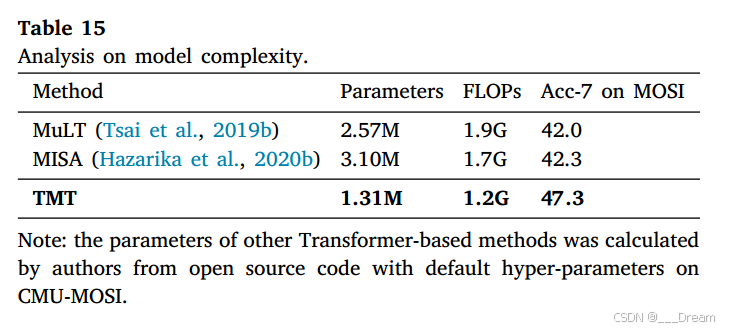
如表15所示,我们将TMT的参数和FLOPs (Molchanov等人,2017)与其他最先进的基于变压器的方法进行了比较。每个数据集的不同超参数配置可能会导致参数和复杂度计算的轻微差异。我们计算了CMU-MOSI在超参数设置下的模型参数和FLOPs。根据Liu et al . (2023c),我们计算了除预训练的Bert文本提取器外的模态解纠缠和模态融合模块。在比较分析中,我们提出的Token-disentangling Mutual Transformer (TMT)比竞争方法MuLT和MISA显示出显着的进步。TMT在参数效率和计算复杂度上都有了很大的提高,参数数量减少了1.31M。这种改进归功于它的Token解纠缠模块的直接方法,不需要额外的参数学习。具体来说,我们通过初始化token学习解耦的一致性特征和异构特征。本文中模态间一致性特征Token的维数为6 × 256,其他三个模态内异质性特征Token的维数为2 × 256。这样,使用更少的参数来存储用于学习的特征。该方法使用较少的参数来存储用于学习的特征。因此,与其他方法相比,我们的TMT可以保持更高的精度和效率。
可视化分析
具有不同解纠缠损失的解纠缠特征的可视化
为了验证所提出的多模态情感Token解纠缠损失的有效性,图7显示了分别在CMU-MOSI和CMU-MOSI数据集上使用t-SNE (van der Maaten和Hinton, 2008)对解纠缠的情感异质性特征和情感一致性特征的可视化结果。图中,采用多模态情感Token解纠缠损失的解纠缠特征为:表示不使用多模态情感Token解纠缠损失(即去除多模态解纠缠损失、模态间正交损失和模态内相似损失)的解纠缠特征。
在这里,我们选择整个测试集的所有样本解纠缠特征进行可视化。
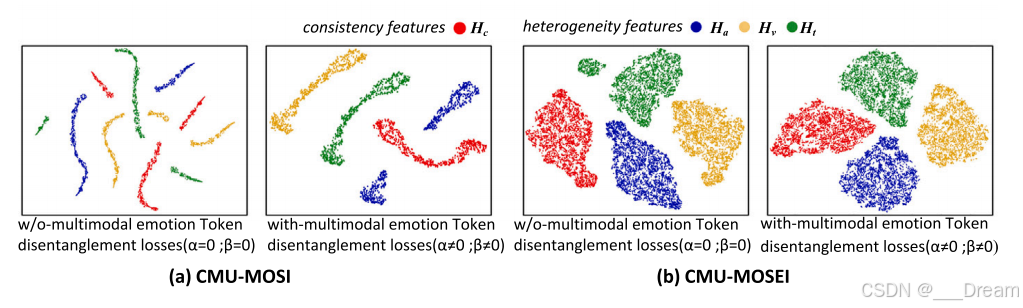
图7所示。提出的多模态情感令牌解纠缠损失对特征解纠缠的影响。
(a) CMU-MOSI数据集的特征可视化;
(b) CMU-MOSI数据集的特征可视化。𝐻𝑐、𝐻𝑎、𝐻𝑣和𝐻𝑡分别代表情感一致性特征、音频异构特征、视频异构特征和文本异构特征。其中,ρ = 0, ρ≠0表示在Eq.(9)中使用多模态情感Token解纠缠损失的解纠缠特征,而ρ = 0, ρ = 0表示不使用多模态情感Token解纠缠损失的解纠缠特征,即从Eq.(9)中去掉多模态解纠缠损失、模态间正交损失和模态内相似损失。
如图7所示,引入多模态情感Token解纠缠损失有效地将一致性特征(𝐻𝑐)与异质性特征(𝐻𝑎、𝐻𝑣和𝐻𝑡)分离开来。值得注意的是,音频异质性特征不能有效地聚合,这可能是由于与视频和文本特征相比,音频异质性特征对与情绪无关的信息(即噪音)的高度敏感性。此外,在我们的模型中选择的Transformer架构可能更有利于视觉和文本模式的特征学习。此外,我们观察到CMU-MOSI和CMUMOSEI数据集之间的尺度差异导致分离程度的变化。更大的CMU-MOSEI数据集使模型能够在更多样本上进行训练,与CMU-MOSI数据集相比,实现了更高程度的分离。
损失函数的可视化
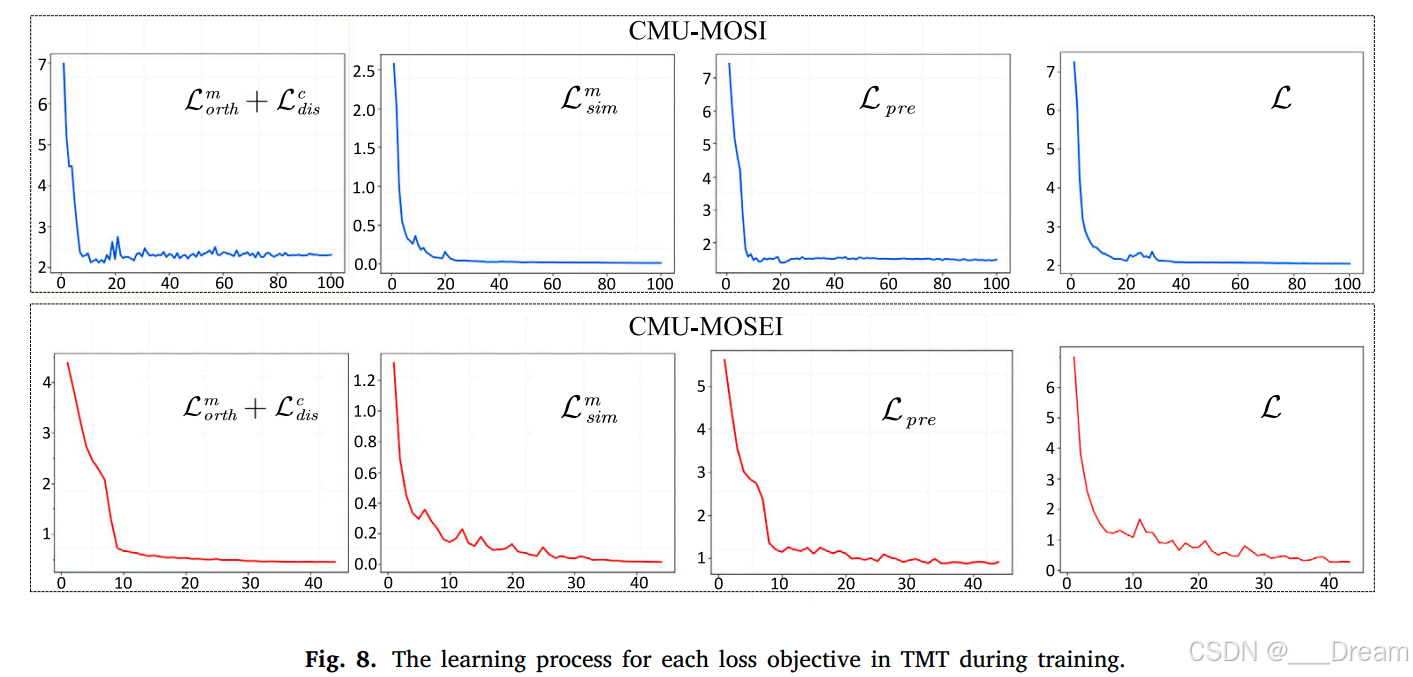
在图8中,我们可视化了TMT在训练过程中的模态间正交损失![]() 、多模态解离损失
、多模态解离损失![]() 、模态内相似性损失
、模态内相似性损失![]() 、情绪预测损失
、情绪预测损失![]() 和整体学习损失
和整体学习损失![]() 的变化。蓝线表示CMU-MOSI数据集上每个损失函数的学习过程,红线表示CMU-MOSEI数据集上的学习过程。
的变化。蓝线表示CMU-MOSI数据集上每个损失函数的学习过程,红线表示CMU-MOSEI数据集上的学习过程。
从图中可以看出,所有的损失函数在第20个epoch都表现出明显的收敛性。这表明我们提出的模型训练效率高,训练速度快,泛化能力强。
令牌互感器中注意力的可视化
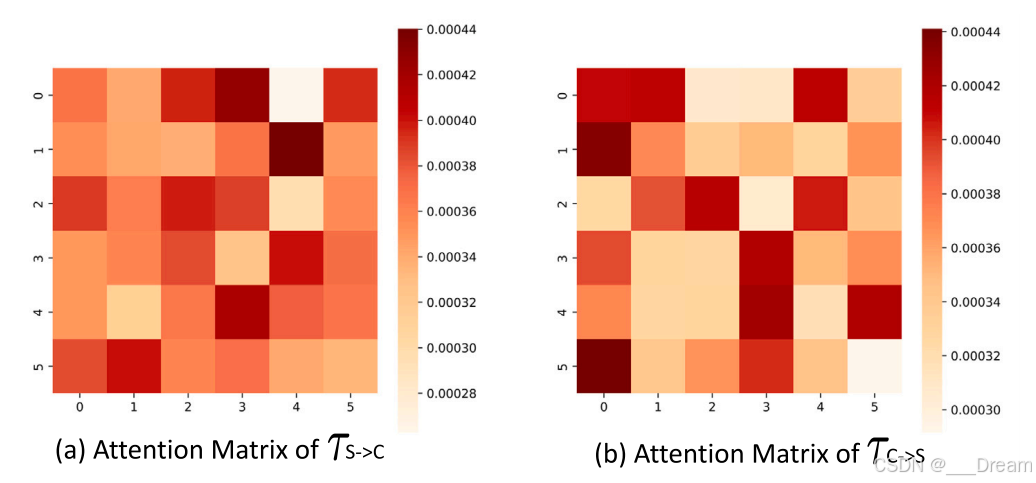
令牌互感器中注意力的可视化。很明显,Token互变的两个跨模态编码器学习到的注意权值是互补的,说明获得了更全面、互补的多模态情绪信息。注意:颜色越深表示学习的注意权重越高。
为了评估模型整合异构和一致特征的能力,我们在CMU-MOSI数据集上可视化了Token互感器模块中模态间一致性特征𝐻𝑐和模态内异质性特征𝐻𝑠的学习平均注意矩阵,如图9所示。具体来说,我们随机选择一个样本来可视化Token互变中最后一层的多头平均注意力矩阵,表示为![]() 。图9中的每个网格表示异质性特征和一致性特征之间的相互关注权重,颜色越深表示关注权重越高。较高的关注权重表示一个解耦特征从另一个解耦特征中学习到更多有价值的信息,表明学习到的融合特征更强。从图中可以看出,当异质性特征和一致性特征分别作为查询项(Q)时,注意力分布是不同的。这种差异使它们的学习效果互补,从而使它们的特点更加全面,学习效果得到提高。
。图9中的每个网格表示异质性特征和一致性特征之间的相互关注权重,颜色越深表示关注权重越高。较高的关注权重表示一个解耦特征从另一个解耦特征中学习到更多有价值的信息,表明学习到的融合特征更强。从图中可以看出,当异质性特征和一致性特征分别作为查询项(Q)时,注意力分布是不同的。这种差异使它们的学习效果互补,从而使它们的特点更加全面,学习效果得到提高。
输入单峰特征和最终融合特征的可视化
如图10所示,我们使用t-sne分别对5类情绪识别任务的输入单峰特征(即𝑈𝑎、𝑈𝑣和𝑈𝑡)和最终融合特征𝑌0进行可视化。可视化结果表明,与具有重叠分布的情绪分类单峰特征相比,最终融合的特征表现出更明显的聚类,特别是对于积极情绪和消极情绪。这表明TMT有潜力通过整合来自每种模态的不同和互补的信息来提高分类精度。
conclusion
本文提出了一种有效的多模态情感识别方法——Token-disentangling Mutual Transformer (TMT)。
该方法有效地分离了与情绪相关的模态间情绪一致性特征和模态内情绪异质性特征,并与之相互作用,实现了稳健的多模态情绪识别。TMT包括两个主要部分:多模态情感令牌解纠缠和令牌互变。为了实现多模态情感Token解纠缠,我们在Transformer框架中引入了一种具有相应情感解纠缠损失的Token分离编码器。该方法有效地从多模态特征中分离出与情绪相关的模态间一致性特征和模态内异质性特征。Token互变模块利用解缠特征,利用两个双向跨模态变形器进行双向查询交互融合,得到更全面的多模态情感表示。在三个具有挑战性的多模态情绪数据集(CMU-MOSI, CMU-MOSEI, CH-SIMS)上进行了大量实验来评估我们的方法的性能。结果表明,我们的方法优于现有的多模态情感识别方法,达到了最先进的性能。
尽管我们的方法是有效的,但我们发现我们的方法并没有捕捉到缺乏情感标签的问题。在未来,我们将在我们的方法中引入更先进的半监督或自监督学习机制,以从未标记的数据中学习,从而获得更强大的情感理解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









