








代码地址 -> github地址传送
abstract
针对多模态情感分析中的情态缺失问题,当情态缺失导致情感发生变化时,会出现不一致现象。决定整体语义的缺失情态可以被认为是关键的缺失情态。然而,以前的研究都忽略了不一致现象,简单地丢弃缺失的模态,或者仅仅从可用的模态中生成相关的特征。忽略关键的缺失情态格可能导致错误的语义结果。
为了解决这个问题,我们提出了一个基于集成的缺失模态重构(EMMR)网络来检测和恢复关键缺失模态的语义特征。具体来说,我们首先通过主干编码器-解码器网络学习剩余模态的联合表示。然后,基于恢复的特征,我们检查语义一致性,以确定缺失的情态是否对整体情感极性至关重要。一旦由于关键模态缺失而导致的不一致问题存在,我们集成了几种编码器-解码器方法以更好地做出决策。在CMU-MOSI和IEMOCAP数据集上进行了大量的实验和分析,验证了该方法的优越性。
intro
情感分析在过去几年中取得了重大进展(Zhang等人,2016),传统的文本情感分类已经发展成更复杂的多模态情感分析(MSA)模型。“是的,我想是的。“例如,如果没有足够的词汇信息,很难读懂情绪,如果有的话,声学形态可能有助于情绪识别。”因此,将不同的模式结合起来进行准确的情感分析是至关重要的。
到目前为止,在假设所有模式都可用的情况下,MSA已经得到了很好的研究。
然而,在现实中,这样一个强有力的假设并不总是成立,我们经常遇到的情况,部分模式可能会丢失。为了解决缺少数据的问题,已作出相应的努力以恢复缺少的模式。Tran等人(2017)首先发现了多模态数据中的缺失模态问题。最近的几部作品(Suo et al, 2019;Ma等人,2021;赵等,2021;Yuan等,2021;Zeng et al ., 2022)以不确定的方式关注缺失模态问题。

然而,上述所有工作都忽略了一个重要的洞察,即当情态缺失时,情绪可能会发生变化,从而导致预测结果不准确。例如,如图1所示,为了直观地表达,用情感语气来描述声学情态;视觉模态由多个面部图像组成;而文本情态指的是相应的文本。
由于声学模态的轻微音调和面部特征的轻微波纹,原始情感是中性的,模态饱满。然而,一旦语音情态缺失,剩余的情感就会受到语篇情态的引导,并倾向于消极。有或没有声情态的语义不一致,缺失的情态可以认为是一个关键的缺失情态。因此,忽略关键缺失模态可能导致不正确的预测。标记和恢复关键缺失情态对于MSA中情绪的准确识别具有重要意义。此外,对于恢复的特征,当他们表达不同的情绪时,权衡不同的模式仍然是非常具有挑战性的。
在本文中,我们通过提供一个集成解决方案来解决上述挑战,该解决方案可以准确地检测和恢复关键缺失模态的特征。更具体地说,我们提出了一个基于集成的缺失模态重构(EMMR)网络来处理不一致问题,进一步提高性能。提出的EMMR由一个骨干网络组成,该骨干网络利用编码器-解码器结构来恢复缺失的模态特征。此外,为了区分关键缺失情态,我们将恢复的完整情态与原始可用情态进行语义比较,以检查其一致性。然后,为了减轻不一致性,我们以集成的方式聚合基于Auto-Encoder (AE)和基于transformer的编码器-解码器方法。
这种策略自然地扩展了特征搜索空间,因此更适合做出连贯的决策。
正如预期的那样,并将通过实验验证,所提出的EMMR在两个基准数据集上显著优于几种最先进的基线。我们的主要贡献总结如下:
•我们提出EMMR以解决缺少关键模态的不一致问题,从而提高MSA的性能。
•我们将基于ae和基于transformer的编码器-解码器方法集成在决策制定中,以更好的预测性能减轻不一致性。
•与几种最先进的方法相比,我们的EMMR在各种具有挑战性的MSA数据集(包括CMU-MOSI和IEMOCAP)上实现了更好的性能。
related work
missing modality problem in MSA
以往的作品大致可以分为两类:1)生成方法和2)联合学习方法。
生成方法旨在生成与观察到的分布相匹配的新数据。(Kingma and Welling, 2014)提出了变分自编码器(Variational Auto-Encoder, VAE),用于将输入变量映射到多元潜在分布。Cai et al(2018)依靠GAN (Goodfellow et al ., 2014),将模态缺失问题转化为条件图像生成任务,旨在以现有模态为条件生成缺失模态图像。
联合学习方法试图从观察到的表征中学习潜在表征。为了提高联合表示学习的鲁棒性,在(Zhao et al ., 2021)中应用了循环一致性策略。此外,Zeng等(2022)重建了带有附加标签的不确定缺失模态的特征。
我们想指出的是,在处理缺少关键模态的情况时,上述工作可能没有考虑到不一致性而做出了不正确的预测。很快就会清楚,我们对MSA中的不一致现象进行了全面的分析。
ensemble learning
集成学习(Lee et al, 2021)旨在通过组合多个基本模型获得比单一模型更好的预测性能。近年来,集成技术已应用于许多NLP任务(Li et al ., 2021;Duan et al, 2021)。主要的想法是,权衡和汇总几个意见比选择一个人的意见更好(Sagi和Rokach, 2018)。具体而言,Li等(2021)使用随机种子生成多个候选结果,然后训练融合分类器来提高情绪识别性能。此外,Duan等人(2021)利用权重调制技术开发了数据多样性的集成语言模型。
沿着这条线,在本文中,我们聚合了几种用于集成学习的重建方法,以在表达不同情绪时权衡不同的模式,并以更好的预测性能进一步减轻不一致性。
方法
符号以及研究问题的定义
 骨干网
骨干网
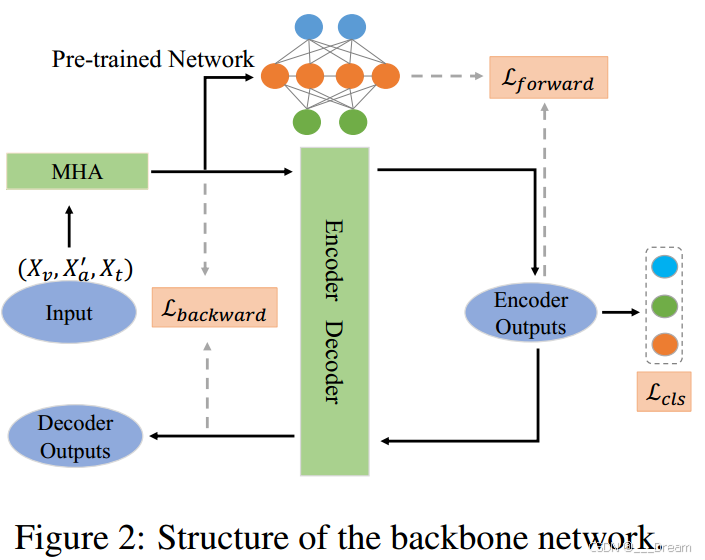
图2显示了基于编码器-解码器结构的骨干网。以缺乏声学模态的三重(Xv, X ' a, Xt)作为输入,首先由多头注意(MHA)模块编码(Vaswani等人,2017),然后经过两个分支:1)一个由预先训练的网络编码,该网络使用所有完整模态进行训练,2)另一个通过编码器-解码器网络获得相应的输出,其中编码器输出用于情感分类。最后,计算前向相似损失和后向重构损失来监督联合特征的学习过程。
Q:backbone好眼熟
A:是的,backbone和TATE有异曲同工之妙,以下是TATE的流程图
特征提取
在被MHA模块处理之前,我们提取每个模态的特征如下:视觉表示:如下(Yu et al ., 2010;Zeng等人,2022),我们也采用OpenFace2.0工具包(Baltrusaitis等人,2018)来获得709维的视觉表示,除了帧号、face_id和时间戳等无关属性的数据。
文本表示:对于每个文本话语,使用预训练的Bert (Devlin等人,2019)(12层,768隐藏,12头)来获取768维单词向量。
声学表示:采用Librosa (McFee et al, 2015)提取33维声学特征,包括过零率、Mel-Frequency倒谱系数(MFCC)和常q变换(CQT)的属性。
然后提取出所有的模态特征,由MHA编码
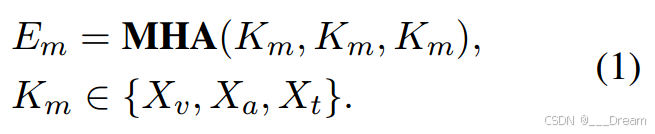
然后,所有的模态被连接成一个完整的输入序列![]()
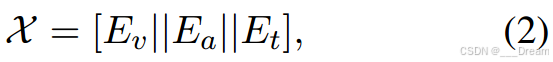
其中||是垂直连接操作。
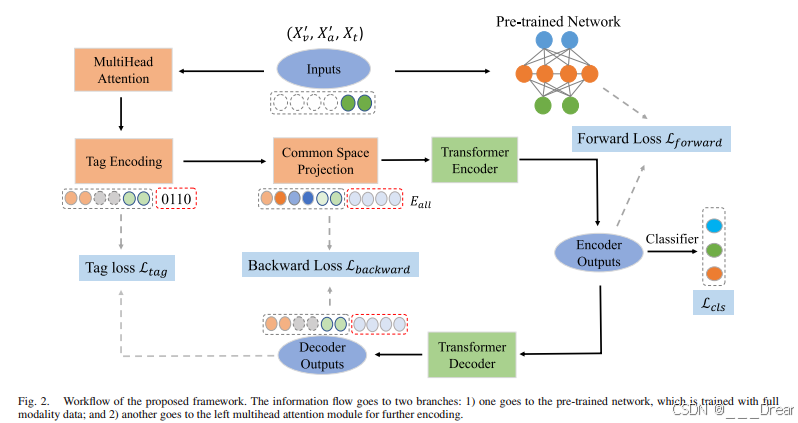
Q:还是眼熟!
A:wowowowo~是的啦,这里有MHA分别提取每个模态特征的高级表示之后,用||合成一个向量的操作,和TATE的pre-trained是一样的,在TATE中,后序还有softmax,下面贴出TATE的pre-trained模型图
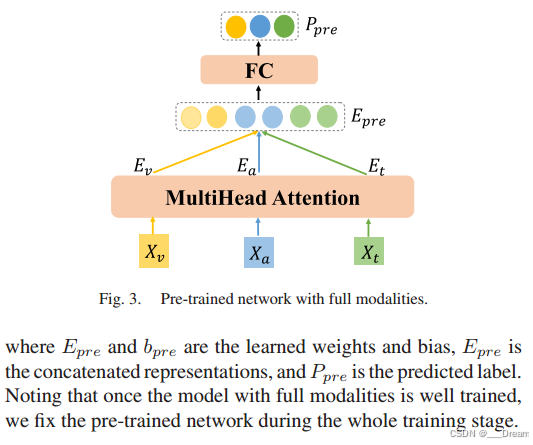
预训练网络
利用完整模态的预训练网络来指导缺失模态的学习过程。具体来说,我们首先连接三个完整的模态,然后将它们输入softmax分类器进行训练:
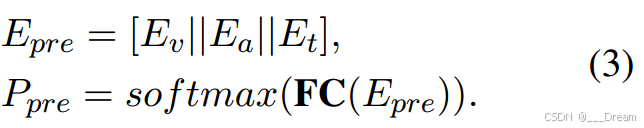
注意,一旦具有完整模态的模型得到很好的训练,我们在整个训练阶段固定预训练的网络
Q:所以backbone,预训练模型都是TATE的?那这篇文章的创新点在哪里?
A:还是有点区别的,TATE中两个分支一边MHA一边pre-trained,这篇文章两条分支都需要走一遍MHA,具体看两者backbone的模型图,不过这种区别几乎忽略不计。
Encoder-Decoder网络
编解码器网络包含一个映射输入(X)的编码器(φ)和一个映射重构输入(X’)的解码器(ψ),其定义如下:

其中F是编码器的输出。
Q1:啥意思这里?
A1:这个网络包括一个编码器将输入映射到一个内部特征表示,以及一个解码器将这个特征表示映射回重构的输入。网络设计目的是在有缺失模态时,通过自动编码器和变换器基础的编码器-解码器模型,重建缺失的模态数据,以保持模型的一致性和性能。
Q2:和TATE的transformer encoder - decoder目的一样吗?
A2:差不多的,目的之一吧,只不过TATE这个部分是用MHA和ReLU组成的。
AE
由于集成学习融合了来自多个模型的信息知识,并以自适应的方式获得了更好的预测性能,可以有效地缓解不一致现象。在我们的方案中,自动编码器(AE) (Baldi, 2012),缺失模态选择想象网络(MMIN) (Zhao et al ., 2021)和基于变压器的编码器-解码器模型(TF)进行决策。现在我们逐一介绍它们。
AE是经过训练将其输入复制到输出的网络。具体来说,我们采用全连接(FC)层,尺寸为[300,256,128,64,128,256,300](详见附录)。
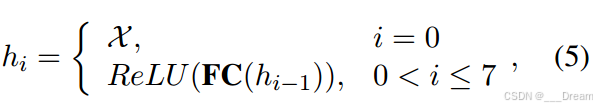
其中编码器输出![]() ,解码器输出
,解码器输出![]()
自编码器是一个由全连接层FC构成的神经网络
网络包含多个全连接层,具体尺寸依次为300,256,128,64,128,256,300
这种设计通常表明网络的前半部分作为编码器,后半部分作为解码器。编码器逐步降低数据维度,捕捉关键信息;解码器则逐步恢复数据维度,重建原始数据。
每个全连接层后面使用了ReLU(Rectified Linear Unit)激活函数,除了第0层和最后一层之外。ReLU函数用于增加网络的非线性能力,有助于处理复杂的数据结构。

MMIN
MMIN采用级联残差自编码器(CRA) (Tran et al ., 2017)结构,带有一组残差自编码器(RA)。具体来说,我们在AE中采用5个具有相同图层设置的RA。
则可以得到CRA的编码器输出和解码器输出:
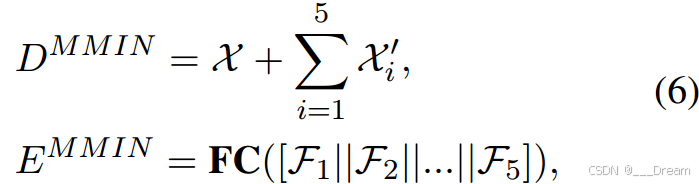
其中![]() 和
和![]() 分别是第i个RA的编码器输出和解码器输出
分别是第i个RA的编码器输出和解码器输出
TF
Transformer体系结构遵循编码器-解码器结构,可以有效地处理顺序输入数据。通过多头注意(MHA)机制和前馈网络(FFN),可以访问编码器输出(![]() )和解码器输出(
)和解码器输出(![]() ):
):
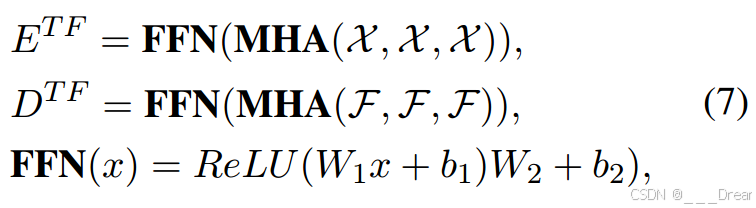
其中W1和W2是两个权重矩阵,b1和b2是两个可学习的偏差
ensemble
对于输入的重建,我们用解码器输出中的相应表示替换缺失的模态。例如,给定输入![]() 和重建输出
和重建输出![]() ,
,
我们可以得到恢复的输入![]() 为了简化随后的数学表达式,我们将恢复的输入表示为
为了简化随后的数学表达式,我们将恢复的输入表示为![]() 。可以获得恢复输入的情绪:
。可以获得恢复输入的情绪: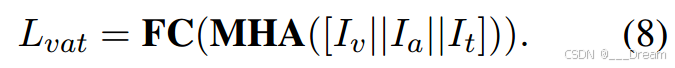
如前所述,在交际语篇中,由于缺少情态而导致情绪发生变化时,就会出现不一致现象。基于这一现象,我们利用不一致性来确定缺失情态是否对整体情感极性至关重要。具体来说,我们首先结合每两个模态来获得相应的情感标签:
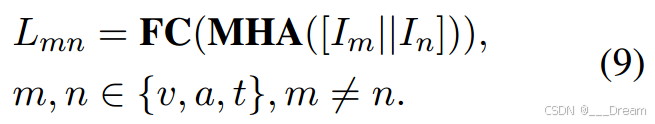
当恢复的完整模态的情感标签与剩余可用模态的语义标签不相等时,缺失模态可以视为关键缺失模态。也就是说,在![]() 的情况下,如果
的情况下,如果![]() ,声学模态是关键缺失模态。为了获得一致的预测结果,必须减轻不一致现象。
,声学模态是关键缺失模态。为了获得一致的预测结果,必须减轻不一致现象。
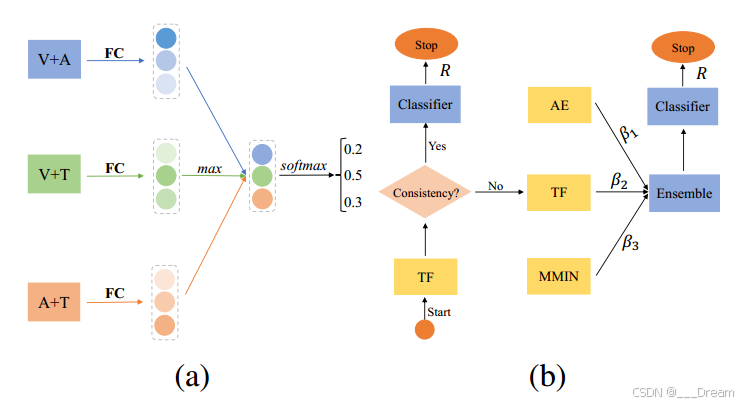
集成方法的说明。(a)计算聚合向量的融合权值;(b)关键缺失模态的集成方法工作流。
处理缺少关键模态问题的一个直接方法是投票。然而,每种模式的重要性是不同的。如图3(a)所示,我们建议根据它们的最大逻辑值(![]() )来分配权重:
)来分配权重:
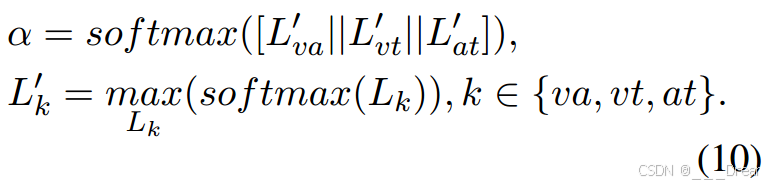
然后,可以访问具有键缺失模态的聚合表示:
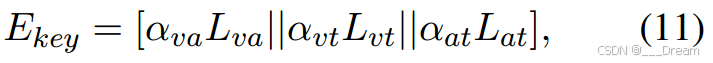
其中αva、αvt、αat为由式计算出的相应权值。(10)。
如图3(b)所示,我们首先用TF编码器将输入馈送到骨干网络。基于恢复的特征,我们检查恢复的完整模态与原始可用模态之间的语义一致性。一旦它们与缺失模态不一致或不一致,我们就整合TF、AE和MMIN以进行进一步的决策。考虑到集成学习中多种方法的综合性能优于单一方法,我们根据相应的关注权重将三个提取的特征组合在一起。设H为由式(11)产生的三个向量![]() 组成的矩阵。
组成的矩阵。
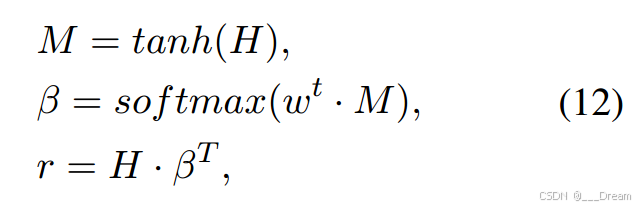
其中w是一个可训练的参数向量,T是转置算子。因此,我们的集成方法的第i个输出(Ri)可以表示为:
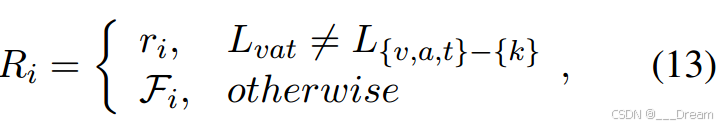
其中k为缺失模态,k∈{v, a, t}。
训练目标
总体培训目标(Ltotal)表示为:
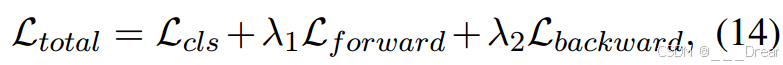
其中,Lcls为分类损失,Lf forward为正向差分损失,Lbackward为后向重构损失,λ1、λ2为对应的权值。现在我们详细介绍这些损失条款
前向差分损失(Lf Forward):前向损失由预训练输出(Epre)与编码器输出(F)之差和Kullback Leibler散度损失计算函数(DKL):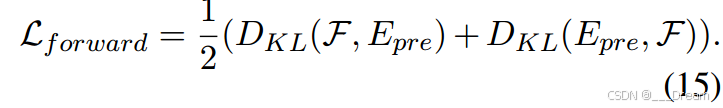
后向重构损失(Lbackward):对于后向损失,我们的目标是监督由解码器输出(X ')和处理后的输入(X)计算的联合公共向量重构。
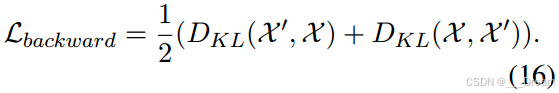
分类损失(Lcls):我们将最终输出R输入到一个带有softmax激活函数的全连接网络中,用于最终的情感分类:
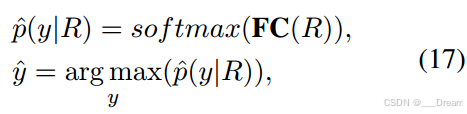
其中![]() 为预测标号。具体来说,我们使用标准的交叉熵损失来完成这个分类任务:
为预测标号。具体来说,我们使用标准的交叉熵损失来完成这个分类任务:
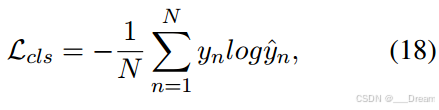
式中N为样本个数,yn为第N个样本的真实标号。
experiments
在本节中,我们主要介绍实验设置,数据集,基线,实证研究和观察结果
实验装置
数据集:我们在两个基准数据集上评估我们的模型:CMU-MOSI (Zadeh等人,2016)和IEMOCAP (Busso等人,2008)。CMUMOSI数据集包含2199个片段,情感得分在[- 3,3];IEMOCAP数据集包含5个会话和151个视频。在我们的实验中,我们报告了CMUMOSI的三级(阴性:[-3,0),中性:[0],阳性:(0,3])结果,以及IEMOCAP的两级(阴性:[沮丧,愤怒,悲伤,恐惧,失望],阳性:[高兴,兴奋])结果
基线:我们选择以下基线进行比较:AE (Baldi, 2012), CRA (Tran等人,2017)和MMIN (Zhao等人,2021)用于基于AE的方法;MCTN (Pham et al, 2019);和TransM (Wang et al ., 2020)的基于翻译的方法;TATE (Zeng et al ., 2022)和提出的基于变压器的EMMR方法。
准确度(Accuracy, ACC)和M cross−F1 (M-F1)用于衡量模型的性能。
详细的实现、数据集统计和超参数设置可在附件中获得
结果
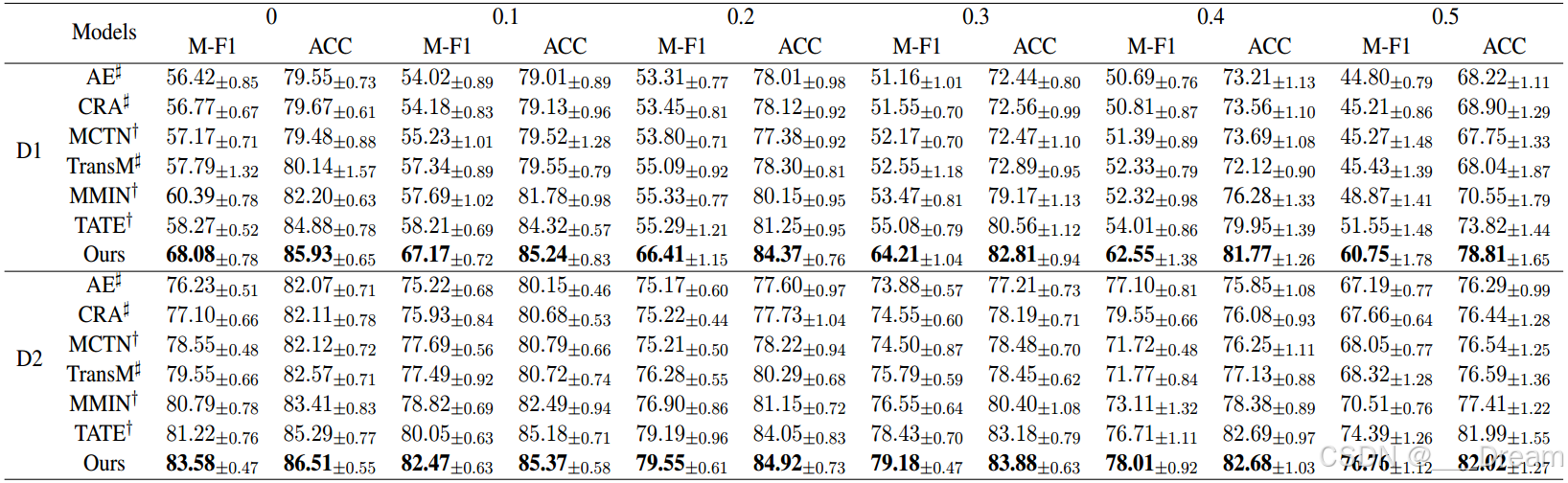
表1显示了所有基线的定性结果。我们提出的EMMR在所有设置下都取得了最好的结果,特别是在CMU-MOSI数据集上的M-F1提高了8.54% ~ 11.12%。由于三种集成方法可以很好地处理缺少关键模态时的不一致问题,从而进一步提高鲁棒性,因此本研究结果具有重要意义。当缺失比从0增加到0.5时,随着缺失样本的增多,性能逐渐下降。我们还发现MCTN和TransM比AE和CRA具有更好的性能,这意味着循环翻译可以更好地融合来自多个模态的多模态信息。此外,由于变压器结构具有较强的学习能力,TATE和EMMR优于其他基准。
另一个观察结果是,当近一半的样本缺失时,我们提出的EMMR仍然表现良好,这是由于三种集成方法可以以互补的方式结合它们的预测。
不同设置的影响
这一部分的实验设置和TATE是一样的
在本小节中,我们首先进行烧蚀研究,以便更好地了解不同模块的影响。之后,我们通过用替代品替换几个核心组件来进一步评估模型的性能。
1)消融研究:我们用几种设置来评估我们的模型:a)只使用一种模式;B)使用两种模式;C)去除预训练的网络;d)拆除反向重构模块。
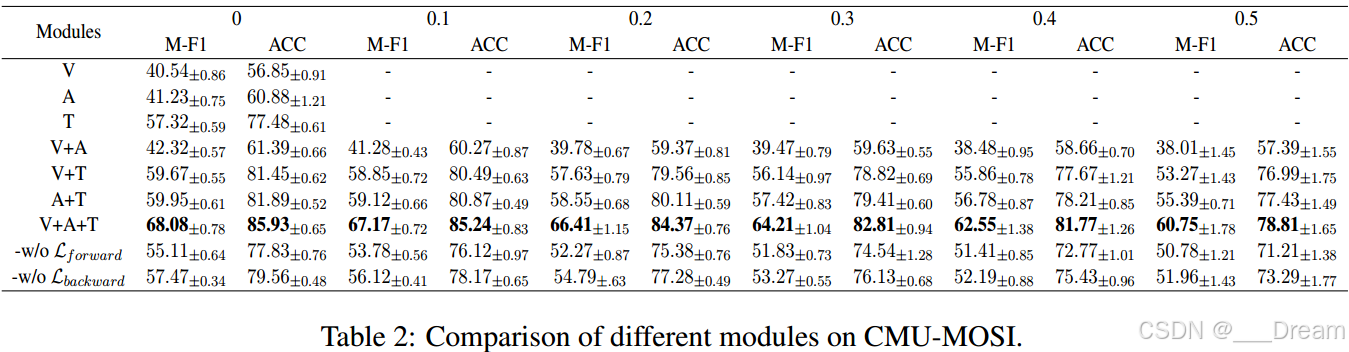
从表2的结果可以看出,在单一情态下,特别是在去掉文本情态时,性能急剧下降。然而,当视觉模态缺失时,没有观察到类似的减少。这些结果表明,语篇情态可能主导着整体情感。此外,从数据中得出的一个显著结果是,两种模式结合后,性能有所提高,这表明多种模式可以通过相互学习互补的特征来提高性能。此外,从后两行可以看出,去除预训练网络后,相对于M-F1性能下降约9.97% ~ 14.39%,相对于ACC性能下降约7.60% ~ 9.12%,可见前向指导的重要性。同时,进一步分析表明,后向重构模块也为最终的联合表示学习提供了很好的监督。
2)不同集成方法的效果:我们现在检验不同集成方法的有效性。为了比较,我们进行了几种设置的实验:a)仅使用骨干网,b)将两种集成方法结合起来,c)将三种集成方法与最大操作结合起来,d)将三种集成方法与平均操作结合起来。
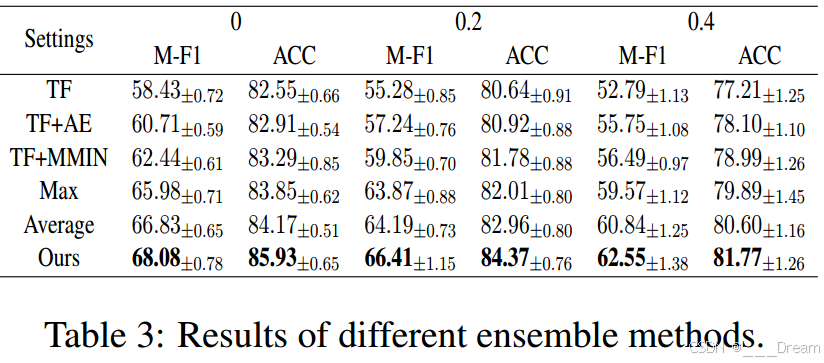
从表3可以看出,虽然骨干网络与TF达到了相当的性能,AE与MMIN相结合仍有提高。原因可能是集成学习结合了来自多个模型的知识,以获得更好的预测性能。
此外,TF+MMIN优于TF+AE,说明MMIN比AE能更好地提取模态特征。与平均操作相比,我们的加权融合方法相对于M-F1提高了1.71% ~ 2.25%,相对于ACC提高了1.17% ~ 1.76%,验证了加权融合机制的有效性
3)不同词嵌入的效果:如前所述,文本情态可能主导整体情感,我们现在评估不同词嵌入模型的性能。
为此,我们选择Word2vec (Mikolov et al ., 2013)、Glove (Pennington et al ., 2014)和ALBERT (Lan et al ., 2020)作为预训练Bert的替代方法,并评估各自的预测性能。这里,我们将Word2vec中的嵌入大小设置为128,并在Glove中选择300维的840B标记。为了公平比较,所有设置共享相同的参数。
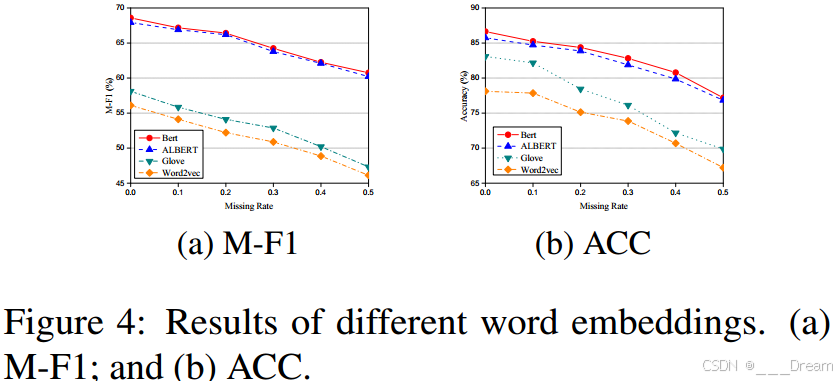
如图4所示,不同的嵌入模型对整体性能有显著影响,其中基于bert的方法效果较好,而Word2vec模型最差。这些结果提供了一个重要的见解,Bert嵌入导致更好的词语义相关性,因为它是从大量的文本语料库中训练出来的。
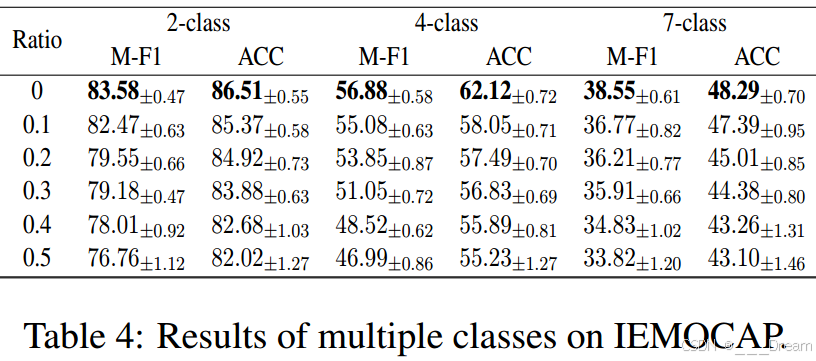
4)多个类的效果:我们还想观察多个类在IEMOCAP上的性能。在一般2级实验结果的基础上,选取快乐、愤怒、悲伤和中性情绪作为4级实验,选取额外的沮丧、兴奋和惊讶情绪作为7级实验。表4显示,随着情绪类别的增加,M-F1和ACC都出现了急剧下降。更具体地说,由于多个类别的混淆,7类实验的性能下降了近一半,模型很难正确分类。需要进一步努力来提高多类场景下的性能。
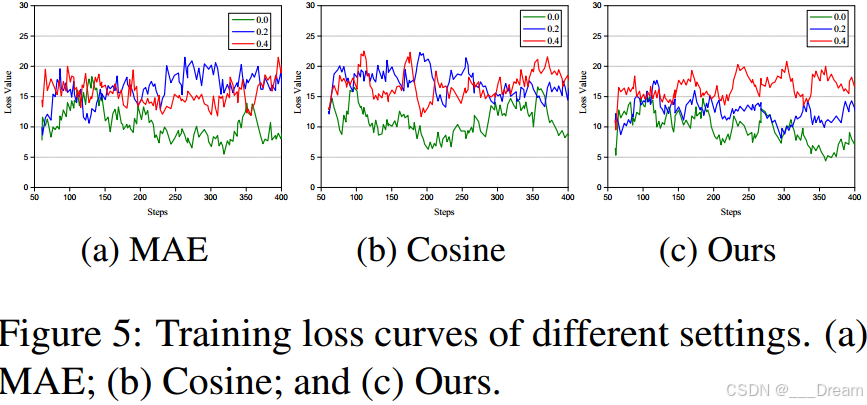
5)不同损失的影响:我们进一步分析研究不同损失的影响。为了比较,我们选择MAE损失和余弦损失作为KL损失的替代方法。图5给出了CMU-MOSI数据集上的训练损失曲线(步长从50到300),包括0、0.2和0.4三种缺失率。可以看出,我们的方法(图5(c))的训练损失曲线波动相对于其他两种损失设置(图5(a)-(b))平滑,表明我们的设置具有较好的收敛性。此外,随着缺失率的增加,训练损失曲线的波动更大,特别是当缺失率为0.4时。与余弦相似损失和MAE损失相比,我们的KL散度损失导致的最小损失值为4.89。然后我们得出结论,KL散度损失可以很好地评估两个概率分布之间的相似性
案例研究

为了更好地理解所提出的方法在哪些条件下有效,我们提出了几个具有挑战性的案例进行进一步分析。为此,图6给出了两个例子,其中带下划线的蓝色单词可能表达了情感极性,缺失的情态用红色虚线标记。
从图中我们可以发现:1)在E1中,虽然缺少视觉模态,但所有模型都生成了正确的结果。由于文本“惊艳”一词的强烈引导,积极的极性得到了明显的表达。这个案例表明,当现有的模态表达相同的显式语义时,传统的方法可以很好地执行。2)在E2中,语篇情态表达积极的极性,而视觉形态往往是消极的,因为面部特征的皱眉和闭嘴唇。当声模态缺失时,很难确定极性。
具体而言,AE和CRA错误地将情绪分类为消极情绪,而除了EMMR之外的其他方法都在语篇情态的主导地位方面预测了积极情绪。相比之下,我们的方法(EMMR)首先判别是否存在不一致现象,然后将三种方法相结合,以互补的方式获得更好的决策
可视化
为了进一步展示不同集成模型的学习能力,我们采用T-SNE工具箱来展示学习到的联合表示,如图7所示。
具体来说,我们在CMU-MOSI上可视化了大约1000个具有三种集成设置的向量,其中红色,蓝色和绿色分别表示负,中性和正。可以看到,在图7(a)-(c)中,所有学习到的向量一般都以TF为骨干网络聚类为三类。此外,由于单个模型的误差可以通过其他模型来补偿,因此集成方法越多,离群值越少。这一现象也与图7(c)(d)的观测结果相一致。此外,红色和绿色的簇更加离散,缺失率也更大。然后我们得出结论,模型很难收敛太多的缺席样本,从而降低了性能
conclusion
在本文中,我们重点研究了在MSA中缺少关键模态时的不一致现象。EMMR首先通过主干编码器-解码器网络从剩余模态中学习特征。然后,我们通过检查恢复的完整模态与原始可用模态之间的语义一致性来区分关键模态。然后,利用三种基于主干编解码器网络的集成方法,在存在不一致现象时进行决策。实验结果和分析证明了该方案与几种最新方法的有效性。未来的研究将集中于综合不同的集成方法进行综合分析。
局限
我们将在本节中讨论详细的限制。如上所述,当存在不一致现象时,我们集成了三种不同的编码器-解码器方法来进行决策。
虽然选择正确的集成方法并正确地使用它们是很重要的,但是集成学习的模型在时间和空间上都是昂贵的。从附件中可以看出,我们对总体参数和测试时间进行了综合比较,这促使我们进一步有效地优化所提出的模型。

















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









