







目录
持久化
什么需要持久化,什么不需要持久化
持久化就是把不能丢失的数据保存到磁盘中,我们需要持久化raft节点的部分信息和kvDb的快照
其中raft节点的部分信息包括m_currentTerm、m_votedFor以及m_logs。
为什么这些需要持久化,为什么那些不需要持久化,从共识安全以及效率优化两个角度去考虑
回答以下疑问:
为什么raft的m_currentTerm、m_votedFor以及m_logs需要持久化?
m_currentTerm 需要持久化,以便节点重启时能够知道自己上次选举的状态和任期,从而避免“脑裂”问题,确保正确的选举和日志一致性。
那么,思考一下,在Raft中每一轮选举都会重新投票,那么为什么需要持久化m_votedFor来确保一致性呢?事实上,m_votedFor 是在同一轮选举内记录的投票信息,这也同样重要。
假设一个场景:一个节点在某个任期内投票给了候选人A,然后节点崩溃并重启,如果没有持久化m_votedFor,节点在重启后不知道它已经投过票了,它可能会再次投票给候选人B,这一过程导致出现重复投票,违反了Raft协议的规则。
所以需要持久化m_votedFor,即使节点重启,它仍然能正确知道自己在当前任期内已经投过票,这样就能防止重复投票,从而确保选举过程的一致性。
m_logs同样需要持久化,因为Raft 的一致性依赖于所有节点的日志在相同的索引上存储相同的条目。因此,为了确保日志的持久性、数据的可靠性和一致性,必须持久化节点的日志。一旦日志被提交,它必须被存储在磁盘上,以便在节点重启时能够恢复日志数据。持久化 m_logs 是为了保证即使在节点崩溃后重启,也能恢复到崩溃前的状态,继续执行一致性协议。
为什么快照需要持久化?
随着Raft日志的增长,日志文件会变得很大,快照是Raft中用来减少日志存储的机制。快照保存了日志的一个切片snapshot,使得节点可以从快照恢复到某个时间点,避免在崩溃之后重新回访到所有日志条目。持久化的目的是因为它是恢复系统状态的关键,如果日志过长,Raft 节点会创建新的快照来保持日志的精简。没有快照,节点可能会在崩溃后必须回放所有日志条目,这会非常低效。
那么,为什么不用持久化commitIndex呢?
commitIndex表示领导者已经提交的日志的最大索引。提交的日志是指已经被大多数节点接收并存储的日志条目。commitIndex是一个相对动态的变量,它依赖于日志和领导者的提交进度。
- 在 领导者重启 后,领导者会通过读取日志中的条目,重新计算
commitIndex。即使commitIndex没有持久化,也可以通过检查日志来恢复其正确值。 - 在 Follower 重启 后,
commitIndex不需要持久化,因为 Follower 会通过日志条目和领导者的提交进度来更新其自己的commitIndex。 commitIndex是用来管理已经提交的日志条目索引的,它的值可以根据日志的状态动态计算。因此,它并不需要持久化,恢复时会通过日志信息推算出。
节点身份(m_me等标识节点的变量)为什么不需要持久化呢?
节点身份通常是唯一的标识符(如节点ID)或者是与节点硬件相关的唯一信息。这个信息一般由外部配置系统或启动时动态获取,并不依赖于节点的持久化存储。例如,节点的ID可以由集群初始化时分配,或者从配置文件读取。即使节点重启,节点的身份依旧是固定的,因此没有必要将其持久化到磁盘。节点的身份通常只会在节点启动时由外部传入,而不受内部状态(日志、任期)的影响
持久化commitIndex和节点身份会有什么风险吗?
持久化 commitIndex 没有太大必要,因为它是动态计算的,可以通过日志推算得到。持久化 commitIndex 会增加不必要的磁盘存储和复杂性,且与日志的持久化本身没有冲突。节点恢复时可以通过日志回放来恢复 commitIndex。
节点的身份一般由外部系统提供(如通过配置文件或者在集群初始化时分配),并不会受到 Raft 协议本身的影响。持久化节点身份反而会增加存储负担。节点身份的变化通常只会发生在节点加入或离开集群时,而这些操作通常是由外部管理系统控制的,因此不需要在每次节点重启时进行持久化。
关于kvDb的快照:
m_lastSnapshotIncludeIndex :快照的信息,快照最新包含哪个日志Index
m_lastSnapshotIncludeTerm :快照的信息,快照最新包含哪个日志Term,与m_lastSnapshotIncludeIndex 是对应的。
Snapshot是kvDb的快照,也可以看成是日志,因此:全部的日志 = m_logs + snapshot
因为Snapshot是kvDB生成的,kvDB肯定不知道raft的存在,而什么term、什么日志Index都是raft才有的概念,因此snapshot中肯定没有term和index信息。
所以需要raft自己来保存这些信息。
故,快照与m_logs联合起来理解即可。
为什么snapshot可以压缩日志?
在 Raft 协议中,日志 是用来记录系统状态变更的,它是通过记录每一个客户端请求和状态修改的日志条目来确保数据的一致性。每当系统状态(比如一个变量或多个变量的值)发生变化时,Raft 会创建一个新的日志条目,并追加到日志中。这些日志条目可以不断增长,因为每个操作(即每个请求)都会产生一个新的条目。
然而,快照(Snapshot)则是对整个系统当前状态的一个“快照”,它记录的是系统的某一时刻的所有变量的最终值,而不是所有历史修改。快照的作用是将一段时间内的所有日志合并为一个单一的状态快照,这样即使日志非常庞大,我们也能通过加载快照来恢复系统状态,避免从日志中逐条重放每一个历史操作。
什么时候持久化?
需要持久化的内容发送改变的时候就要注意持久化。
比如term 增加,日志增加等等。
谁来调用持久化?
谁来调用都可以,只要能保证需要持久化的内容能正确持久化。
仓库代码中选择的是raft类自己来完成持久化。因为raft类最方便感知自己的term之类的信息有没有变化。
虽然持久化很耗时,但是持久化这些内容的时候不要放开锁,以防其他线程改变了这些值,导致其它异常。
具体如何持久化?
持久化需要考虑:速度、大小、二进制安全。
仓库实现目前采用的是使用boost库中的持久化实现,将需要持久化的数据序列化转成std::string 类型再写入磁盘。
具体做法:
持久化节点状态的做法:
- 这个函数的目的是将 Raft 节点的状态保存到一个字符串中。这些状态包括:
- 当前的任期(
m_currentTerm) - 投票信息(
m_votedFor) - 快照元数据(
m_lastSnapshotIncludeIndex、m_lastSnapshotIncludeTerm) - 当前节点的日志(
m_logs)
- 当前的任期(
- 节点状态被持久化后,能够在节点重启时恢复这些信息,以保证 Raft 协议的一致性。
日志的持久化:
m_logs 中保存了 Raft 节点的所有日志条目,这些日志是系统执行的操作记录。通过将这些日志序列化为字符串并持久化,可以确保节点恢复时不丢失已执行的操作。
序列化和反序列化:
使用 Boost 库的序列化功能,确保对象可以安全地转化为存储格式,并能在需要时从存储中恢复。text_oarchive 将对象序列化为文本格式(通常为字符串),这使得数据持久化到文件系统、数据库等存储介质时更为方便。
最后函数返回一个字符串,它包含了Raft节点的所有持久化数据(任期、投票、日志、快照信息等)。这个字符串可以被存储到磁盘或数据库中,以便节点重启时恢复状态。
std::string Raft::persistData() {
BoostPersistRaftNode boostPersistRaftNode;
boostPersistRaftNode.m_currentTerm = m_currentTerm;
boostPersistRaftNode.m_votedFor = m_votedFor;
boostPersistRaftNode.m_lastSnapshotIncludeIndex = m_lastSnapshotIncludeIndex;
boostPersistRaftNode.m_lastSnapshotIncludeTerm = m_lastSnapshotIncludeTerm;
for (auto &item: m_logs) {
boostPersistRaftNode.m_logs.push_back(item.SerializeAsString());
}
std::stringstream ss;
boost::archive::text_oarchive oa(ss);
oa<<boostPersistRaftNode;
return ss.str();
}kvServer
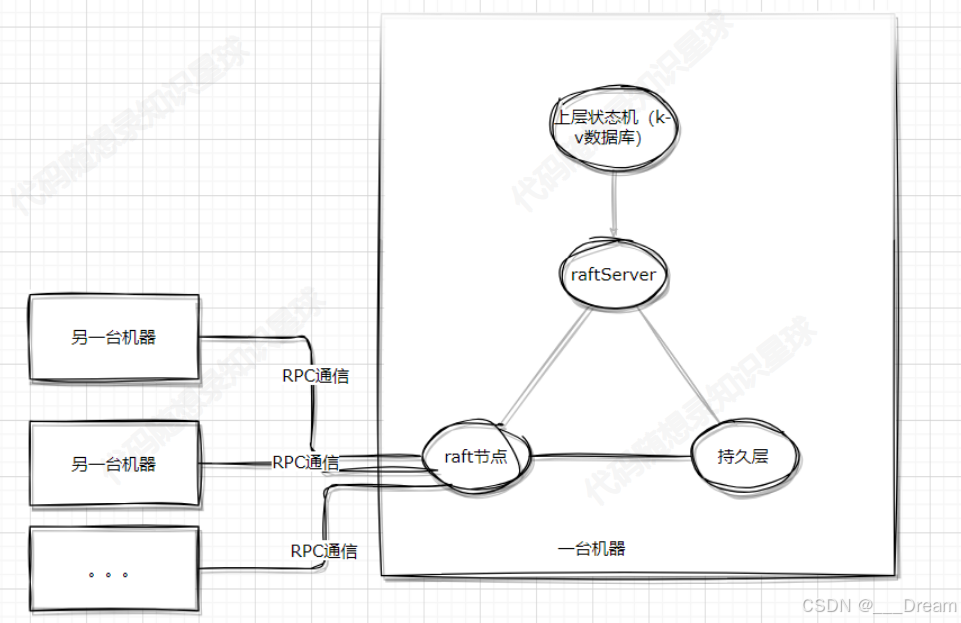
kvServer == raftServer
kvServer是一个中间组件,负责沟通kvDB和raft节点,也负责外部请求的处理
kvServer怎么和上层kvDB沟通呢,怎么和下层raft节点沟通呢?是通过两个成员变量实现的:
std::shared_ptr<LockQueue<ApplyMsg> > applyChan; //kvServer和raft节点的通信管道
std::unordered_map<std::string, std::string> m_kvDB; //kvDB,用unordered_map来替代kvDB使用的是unordered_map来替代上层的kvDB
raft节点,其中的lockQueue是一个并发安全的队列,这种方式其实是模仿的go中的channel机制。
在raft类中可以看到,raft类中也拥有一个applyChan,kvServer和raft类都持有同一个applyChan,来完成互相的通信。
kvServer怎么处理外部请求
kvServer负责与外部clerk通信
那么一个外部请求的处理可以简单的看成两步:1.接收外部请求。2.本机内部与raft和kvDB协商如何处理该请求。3.返回外部响应。
接收与响应外部请求
对于1和3,请求和返回的操作我们可以通过http、自定义协议等等方式实现,但是既然我们已经写出了rpc通信的一个简单的实现,那就使用rpc来实现吧。
而且rpc可以直接完成请求和响应这一步,后面就不用考虑外部通信的问题了,好好处理好本机的流程即可。
相关函数:
void PutAppend(google::protobuf::RpcController *controller,
const ::raftKVRpcProctoc::PutAppendArgs *request,
::raftKVRpcProctoc::PutAppendReply *response,
::google::protobuf::Closure *done) override;
void Get(google::protobuf::RpcController *controller,
const ::raftKVRpcProctoc::GetArgs *request,
::raftKVRpcProctoc::GetReply *response,
::google::protobuf::Closure *done) override;
请求分成两种:get和put。如果是putAppend,clerk中就调用PutAppend 的rpc。如果是Get,clerk中就调用Get 的rpc。
与raft节点沟通
在此之前,我们先了解一下线性一致性:
假设你有一个系统,系统执行了多个操作,比如读和写,这些操作是由多个客户端发起的,执行的顺序可能是乱序的,或者说存在并发的情况。线性一致性要求我们系统的操作是可以按照某种顺序重排的,并且这个顺序需要满足一下几点:
1. 操作顺序必须符合现实中的时间顺序:比如说,现在有两个操作,客户端A发送了写数据,修改了某个数据。客户端B发出了一个度操作,读取了这个数据。那么如果客户端A的写操作结束了,B就能读到A的最新写入结果。也就是说,B的读操作不可以发生在A写之前,它必须是A的后续操作。
2. 每个操作都必须遵循“先发出请求,后完成”的顺序
3. 每个读操作必须看到最新的写操作
在分布式系统中,通常涉及多个节点,这些节点可能并行处理多个请求,导致请求的执行顺序可能并不固定。如果不加以控制,可能会出现读到旧数据或者操作执行顺序混乱的情况,线性一致性通过强制规定一个操作完成的顺序,确保每个操作的结果都符合客户端的预期,从而避免不一致或混乱的结果。
那么raft是如何处理线性一致问题的呢?
每个client都需要一个唯一标识符,它的每个不同命令需要有一个顺序递增的commandId,clientId和这个commandId,clientId可以唯一确定一个不同的命令,从而使得各个raft节点可以保存各命令是否已应用以及应用以后的结果
在保证线性一致的情况下如何写kv?
下面这段代码的功能是处理请求的超时情况,并根据请求的重复性和当前Raft集群状态返回相应的错误信息。它的核心逻辑是处理客户端发来的请求并决定是否执行,特别是考虑到命令执行的超时和重复请求的情况。
解释:
假如超时了
timeOutPop是一个带超时的操作,它会等待某个操作(如 Raft 日志的提交)完成,超时则返回false。具体来说,它是用于等待一个 Raft 操作的提交结果。CONSENSUS_TIMEOUT是一个常量,表示等待 Raft 日志提交的最大时间(超时时间)。- 如果操作超时,
timeOutPop返回false,进入if分支,表示 Raft 集群的操作没有在规定时间内完成。
如果请求超时了,但是请求是重复请求(通过 ClientId 和 RequestId 判断),则认为这次操作是客户端的重试操作,不需要执行实际的操作,直接返回 OK。
假如没超时
ifRequestDuplicate(op.ClientId, op.RequestId)是检查当前请求是否是一个重复请求的方法。重复请求是指客户端发出的请求在系统中已经存在过,并且没有被执行。- 例如,客户端可能由于网络问题没有收到之前的请求响应,因此会重试请求,Raft 会检测这个请求是否已执行过,并直接返回成功。
- 如果请求超时且不是重复请求,说明当前操作没有成功完成。由于 Raft 协议是基于 Leader 的,如果超时没有得到响应,则认为操作可能没有由正确的 Leader 处理。
- 返回
ErrWrongLeader,这个错误提示客户端需要重新选择正确的 Leader 进行请求重试。 - 如果
timeOutPop没有超时(即操作在规定时间内完成),那么raftCommitOp会包含已经执行的操作的结果。这里,raftCommitOp代表 Raft 集群已经提交的操作数据。 - 接下来,代码会检查
raftCommitOp是否和当前请求的客户端 ID 和请求 ID 匹配。- 如果匹配,则表示当前请求已经成功执行,返回
OK。 - 如果不匹配,则说明当前请求可能被其他 Leader 提交了日志或者发生了 Leader 变更,导致日志覆盖,因此需要返回
ErrWrongLeader错误,提示客户端请求的 Leader 不正确,应该重新发起请求。
- 如果匹配,则表示当前请求已经成功执行,返回
另外,这里的命令执行成功是指:本条命令在整个raft集群达到同步的状态,而不是一台机器上的raft保存了该命令。
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) {//通过超时pop来限定命令执行时间,如果超过时间还没拿到消息说明命令执行超时了。
if (ifRequestDuplicate(op.ClientId, op.RequestId)) {
reply->set_err(OK);// 超时了,但因为是重复的请求,返回ok,实际上就算没有超时,在真正执行的时候也要判断是否重复
} else {
reply->set_err(ErrWrongLeader); ///这里返回这个的目的让clerk重新尝试
}
} else {
//没超时,命令可能真正的在raft集群执行成功了。
if (raftCommitOp.ClientId == op.ClientId &&
raftCommitOp.RequestId == op.RequestId) { //可能发生leader的变更导致日志被覆盖,因此必须检查
reply->set_err(OK);
} else {
reply->set_err(ErrWrongLeader);
}
}在保证线性一致性的情况下如何读kv?
读就是处理来自客户端的Get请求,在 Raft 集群中提交日志后,决定是否执行该操作。它包括两部分逻辑:
- 处理超时情况:如果 Raft 操作在规定时间内没有完成,检查是否是重复请求,并返回适当的响应。
- 处理已提交日志的情况:如果 Raft 集群已成功提交该命令(
op),则执行命令并返回响应
读与写不同的是,读就算操作过也可以重复执行,不会违反线性一致性。因为毕竟不会改写数据库本身的内容。
没有成功提交,而是超时了
GetState(&_, &isLeader):获取当前节点的状态,检查该节点是否是 Raft 集群中的 Leader。isLeader为true表示当前节点是 Leader。_用来接收 Raft 节点的当前 Term,但在这个场景下并未使用,因此它被赋值为-1。ifRequestDuplicate(op.ClientId, op.RequestId):检查当前请求是否为重复请求。请求的唯一标识由ClientId和RequestId组成。如果是重复请求,则不需要再次执行,只返回上次的结果。对于Get请求,重复请求通常是客户端因为超时等原因重试的请求。isLeader:还需要检查当前节点是否是 Raft 的 Leader。如果当前节点不是 Leader,即使请求是重复的,也无法处理该请求,因此需要返回错误。ExecuteGetOpOnKVDB(op, &value, &exist):如果是重复的请求并且当前节点是 Leader,则执行Get操作。执行过程中,查询 Key-Value 数据库,获取对应的值。value:查询结果值。exist:如果查询结果存在,exist为true,否则为false。
- 如果查询结果存在(
exist为true),则返回OK和查询结果value。 - 如果查询结果不存在(
exist为false),则返回ErrNoKey错误,并且value为空字符串。 - 如果当前节点不是 Leader 或者请求不是重复请求,则返回
ErrWrongLeader错误,提示客户端切换到正确的 Leader 进行重试。
成功提交,没有超时
-
raftCommitOp包含了已提交操作的信息。此时,我们可以认为日志已经在 Leader 节点上成功提交,因此可以执行命令。 -
raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId:通过比较raftCommitOp中的ClientId和RequestId,确保提交的日志与当前请求对应。如果匹配,说明该请求已在 Raft 集群中提交,并且可以执行。 -
然后调用
ExecuteGetOpOnKVDB查询数据库,返回查询结果。- 如果查询成功,返回
OK和查询结果值。 - 如果查询失败,返回
ErrNoKey错误。
- 如果查询成功,返回
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) {
int _ = -1;
bool isLeader = false;
m_raftNode->GetState(&_, &isLeader);
if (ifRequestDuplicate(op.ClientId, op.RequestId) && isLeader) {
//如果超时,代表raft集群不保证已经commitIndex该日志,但是如果是已经提交过的get请求,是可以再执行的。
// 不会违反线性一致性
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader); //返回这个,其实就是让clerk换一个节点重试
}
} else {
//raft已经提交了该command(op),可以正式开始执行了
//todo 这里感觉不用检验,因为leader只要正确的提交了,那么这些肯定是符合的
if (raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId) {
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
}
}另外来看看Get请求:
Get 请求使用 Raft 协议来保证一致性,并将结果返回给客户端。
// 处理来自clerk的Get RPC
//Op op;:定义一个操作(Op)结构体,表示当前的 Get 请求。
//这里将 Get 请求的关键字、客户端 ID、请求 ID 等信息从请求参数中填充到 op 中。
void KvServer::Get(const raftKVRpcProctoc::GetArgs *args, raftKVRpcProctoc::GetReply *reply) {
Op op;
op.Operation = "Get";
op.Key = args->key();
op.Value = "";
op.ClientId = args->clientid();
op.RequestId = args->requestid();
//m_raftNode->Start:将操作 op 提交给 Raft 协议,并获取 raftIndex(即该操作在 Raft 日志中的索引)。
//raftIndex 是 Raft 预期的日志索引,通常它是准确的,表示 Raft 日志中该操作的位置。
//isLeader 用来标识当前节点是否是 Raft 的 Leader。
int raftIndex = -1;
int _ = -1;
bool isLeader = false;
m_raftNode->Start(op, &raftIndex, &_, &isLeader); // raftIndex:raft预计的logIndex
//if (!isLeader):如果当前节点不是 Leader,返回 ErrWrongLeader 错误,表示该操作需要由 Leader 节点处理,客户端应该切换到其他节点重试。
if (!isLeader) {
reply->set_err(ErrWrongLeader);
return;
}
// create waitForCh
//m_mtx.lock():为了保护 waitApplyCh 这个共享资源,使用互斥锁(mutex)确保线程安全。
m_mtx.lock();
//waitApplyCh:这是一个用于存储与 Raft 日志索引(raftIndex)对应的 LockQueue 的映射,LockQueue 用于存储操作,确保等待日志被应用时操作的顺序。
//如果 raftIndex 不在 waitApplyCh 中,则为该索引创建一个新的 LockQueue<Op>,并将其插入映射中。
if (waitApplyCh.find(raftIndex) == waitApplyCh.end()) {
waitApplyCh.insert(std::make_pair(raftIndex, new LockQueue<Op>()));
}
auto chForRaftIndex = waitApplyCh[raftIndex];
m_mtx.unlock(); //直接解锁,等待任务执行完成,不能一直拿锁等待
// timeout
Op raftCommitOp;
//如果超时,意味着 Raft 集群还没有保证日志已提交,因此需要执行超时处理。
if (!chForRaftIndex->timeOutPop(CONSENSUS_TIMEOUT, &raftCommitOp)) {
//再次获取 Raft 集群的状态,检查当前节点是否是 Leader。
int _ = -1;
bool isLeader = false;
m_raftNode->GetState(&_, &isLeader);
//检查当前请求是否是重复请求。Raft 协议允许重复请求的幂等操作(例如 Get 操作),即使操作超时,只要客户端发送的请求是相同的,可以安全地重试。
//如果请求是重复的且当前节点是 Leader,执行 Get 操作,查询数据库中的值。
if (ifRequestDuplicate(op.ClientId, op.RequestId) && isLeader) {
// 如果超时,代表raft集群不保证已经commitIndex该日志,但是如果是已经提交过的get请求,是可以再执行的。
// 不会违反线性一致性
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
//如果查询到的值存在(exist == true),返回 OK 和查询到的值;如果值不存在,返回 ErrNoKey。
//如果请求不是重复请求或者当前节点不是 Leader,则返回 ErrWrongLeader 错误,提示客户端重新选择 Leader 进行重试。
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader); // 返回这个,其实就是让clerk换一个节点重试
}
//raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId:在 Raft 日志提交之后,再次检查操作的客户端 ID 和请求 ID 是否匹配,以确保操作是由相同的客户端发出的。如果匹配,执行 Get 操作并返回查询结果。
//如果匹配,执行 Get 操作并返回查询结果(与上面相同的逻辑)。
//如果不匹配(例如 Raft 日志中提交的是一个不同的请求),返回 ErrWrongLeader 错误,表示操作无法完成。
} else {
// raft已经提交了该command(op),可以正式开始执行了
// todo 这里感觉不用检验,因为leader只要正确的提交了,那么这些肯定是符合的
if (raftCommitOp.ClientId == op.ClientId && raftCommitOp.RequestId == op.RequestId) {
std::string value;
bool exist = false;
ExecuteGetOpOnKVDB(op, &value, &exist);
if (exist) {
reply->set_err(OK);
reply->set_value(value);
} else {
reply->set_err(ErrNoKey);
reply->set_value("");
}
} else {
reply->set_err(ErrWrongLeader);
}
}
//操作完成后,获取锁并删除与 raftIndex 相关联的 LockQueue,确保资源得到释放。
m_mtx.lock(); // todo 這個可以先弄一個defer,因爲刪除優先級並不高,先把rpc發回去更加重要
auto tmp = waitApplyCh[raftIndex];
waitApplyCh.erase(raftIndex);
delete tmp;
m_mtx.unlock();
}
RPC调用
RPC如何调用
这里以Raft类为例讲解下如何使用rpc远程调用的。
1.写protoc文件,并生成对应的文件
Protocol Buffers (简称 protobuf) 文件,用于定义远程过程调用(RPC)接口及其消息类型。protobuf 是 Google 开发的一种数据序列化格式,可以用来定义消息类型和服务接口,随后生成相应的代码来实现客户端和服务器之间的通信。
kvServerRPC.proto,具体实现了一个分布式键值存储系统中 Raft 协议相关的 RPC 服务。
//表示该文件使用的是 proto3 语法。
//proto3 是 Protocol Buffers 的一种版本,相对于旧的 proto2 语法,proto3 具有简化的功能和更强的可扩展性。
syntax = "proto3";
//package 定义了消息类型和服务所属的命名空间。这样可以避免不同项目或模块之间的命名冲突。
package raftKVRpcProctoc; //所在的命名空间
//cc_generic_services = true 用来开启生成通用的服务 stub 代码,使得可以生成一些通用的服务器端和客户端代码,这对于需要通过 RPC 实现通信的服务是必需的。
option cc_generic_services = true; //开启stub服务
// 日志实体
// GetArgs消息定义了Get请求的参数
// 其中包括:key,请求的键。ClientId,客户端的标识。RequestId,请求的ID,用于标识该请求的唯一性
message GetArgs{
bytes Key = 1 ;
bytes ClientId = 2 ;
int32 RequestId = 3;
}
// GetReply消息定义了Get请求返回的结果
// Err是错误信息(字节数组bytes类型),可能包含错误代码或其他错误信息。value,对应key值(字节数组bytes类型)
message GetReply {
// 下面几个参数和论文中相同
bytes Err = 1;
bytes Value = 2;
}
// Put or Append
// PutAppendArgs 消息定义了 Put 或 Append 操作的请求参数:
// Key: 请求的键(字节数组 bytes 类型)。
// Value: 请求的值(字节数组 bytes 类型)。
// Op: 操作类型,可能是 Put 或 Append(字节数组 bytes 类型)。
// ClientId: 客户端的标识(字节数组 bytes 类型)。
// RequestId: 请求的 ID,用于标识该请求的唯一性(整数类型 int32)。
message PutAppendArgs {
bytes Key = 1;
bytes Value = 2 ;
bytes Op = 3;
// "Put" or "Append"
// You'll have to add definitions here.
// Field names must start with capital letters,
// otherwise RPC will break.
bytes ClientId = 4;
int32 RequestId = 5;
}
message PutAppendReply {
bytes Err = 1;
}
//只有raft节点之间才会涉及rpc通信
service kvServerRpc
{
//PutAppend(args *PutAppendArgs, reply *PutAppendReply)
//Get(args *GetArgs, reply *GetReply)
rpc PutAppend(PutAppendArgs) returns(PutAppendReply);
rpc Get (GetArgs) returns (GetReply);
}
// message ResultCode
// {
// int32 errcode = 1;
// bytes errmsg = 2;
// }
// message GetFriendsListRequest //请求,响应
// {
// uint32 userid = 1;
// }
// message GetFriendsListResponse //请求,响应
// {
// ResultCode result = 1;
// repeated bytes friends = 2;
// }
// // 好友模块
// service FiendServiceRpc //具体的服务模块和服务方法
// {
// rpc GetFriendsList(GetFriendsListRequest) returns(GetFriendsListResponse);
// }2.继承生成的文件的类 class Raft : public raftRpcProctoc::raftRpc
3.重写rpc方法即可
// 重写基类方法,因为rpc远程调用真正调用的是这个方法
//序列化,反序列化等操作rpc框架都已经做完了,因此这里只需要获取值然后真正调用本地方法即可。
void AppendEntries(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::AppendEntriesArgs *request,
::raftRpcProctoc::AppendEntriesReply *response,
::google::protobuf::Closure *done) override;
void InstallSnapshot(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::InstallSnapshotRequest *request,
::raftRpcProctoc::InstallSnapshotResponse *response,
::google::protobuf::Closure *done) override;
void RequestVote(google::protobuf::RpcController *controller,
const ::raftRpcProctoc::RequestVoteArgs *request,
::raftRpcProctoc::RequestVoteReply *response,
::google::protobuf::Closure *done) override;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









