







 数据仓库是决策支持系统的基础,其数据质量直接影响到数据分析和挖掘的效果。数据质量包括准确性、完整性、简洁性和适用性,这些都会随业务需求变化。数据清洗是解决数据质量问题的关键,涉及缺失值、重复数据和错误值的处理。清洗流程包括数据抽取、确认、标准化及错误纠正。常用清洗策略有手工、自动和特定领域方法。常见清洗方法包括忽略或填充缺失值,以及识别和处理重复数据。
数据仓库是决策支持系统的基础,其数据质量直接影响到数据分析和挖掘的效果。数据质量包括准确性、完整性、简洁性和适用性,这些都会随业务需求变化。数据清洗是解决数据质量问题的关键,涉及缺失值、重复数据和错误值的处理。清洗流程包括数据抽取、确认、标准化及错误纠正。常用清洗策略有手工、自动和特定领域方法。常见清洗方法包括忽略或填充缺失值,以及识别和处理重复数据。
基于ETL的数据清洗技术
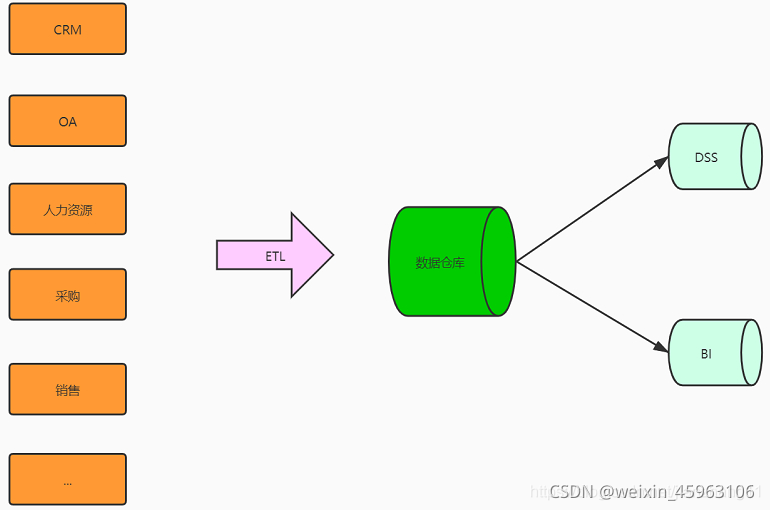
数据仓库:是一个面向主题的、集成的、相对稳定的、且随时间变化的数据集合,用于支持管理决策。是数据源的整合,需要统一的数据采集,处理,存储,分发,共享。
由上图可知,数据仓库是DSS(决策支持系统),BI(商务系统)的基础,试想:如果作为决策支持的数据仓库存放的数据不达标,将直接导致数据挖掘,数据分析得不到理想信息,甚至得到错误信息,进而误导决策。
由此可见得到数据仓库中数据质量的重要性。
1.1.1 数据质量的概述
定义:是指在业务环境下,数据符合数据消费者的使用目的,能满足业务场景具体需求的程度。在不同的业务场景下,消费数据者对数据质量有着各自不同的观点。
从适用性的角度看,数据质量是一个相对概念,不同的决策者对数据的质量的高低要求也是不同的。对于一个无关数据,即使质量再高对决策也起不到任何作用。
数据质量的显著特点如下: 1、“业务需求”会随时间变化,数据质量也会随时间发生变化。 2、数据质量可以借助信息系统度量,但独立于信息系统存在。 3、数据质量存在于数据的整个生命周期,随着数据的产生而产生,随着数据的消失而消失
1.1.2 数据质量的评价指标
数据质量的评价指标主要包括:准确性,完整性,简洁性,适用性,其中数据的准确性,完整性,简洁性是为了保证数据的适用性。
1、 准确性:数据的准确性就是要求数据中的噪声尽可能少。 2、完整性:完整性指的是数据信息是否存在缺失的状况 。 3、简洁性:简洁性就是要尽量选择重要的本质属性,并消除冗余。
4、适用性:实用性是评价数据质量的重要标准。数据质量能否满足决策的需求是适用性的关键所在。从数据的实际效用上讲适用性才是评价数据质量的核心准则。
1.1.3 数据质量的问题分类
数据质量的问题可以分为两类:1、是基于数据源的“脏”数据分类;2、是基于清洗方式的脏数据分类。
1、基于数据源的“脏”数据分类
由于数据仓库的数据来自底层数据源,因此”脏”数据出现的原因与数据源有密切关系。

模式层:指的是数据库的结构,具有固定形式的表结构。
实例层:也称元祖,记录,通常指的是二维表的一行。
2、基于清洗方式的脏数据分类
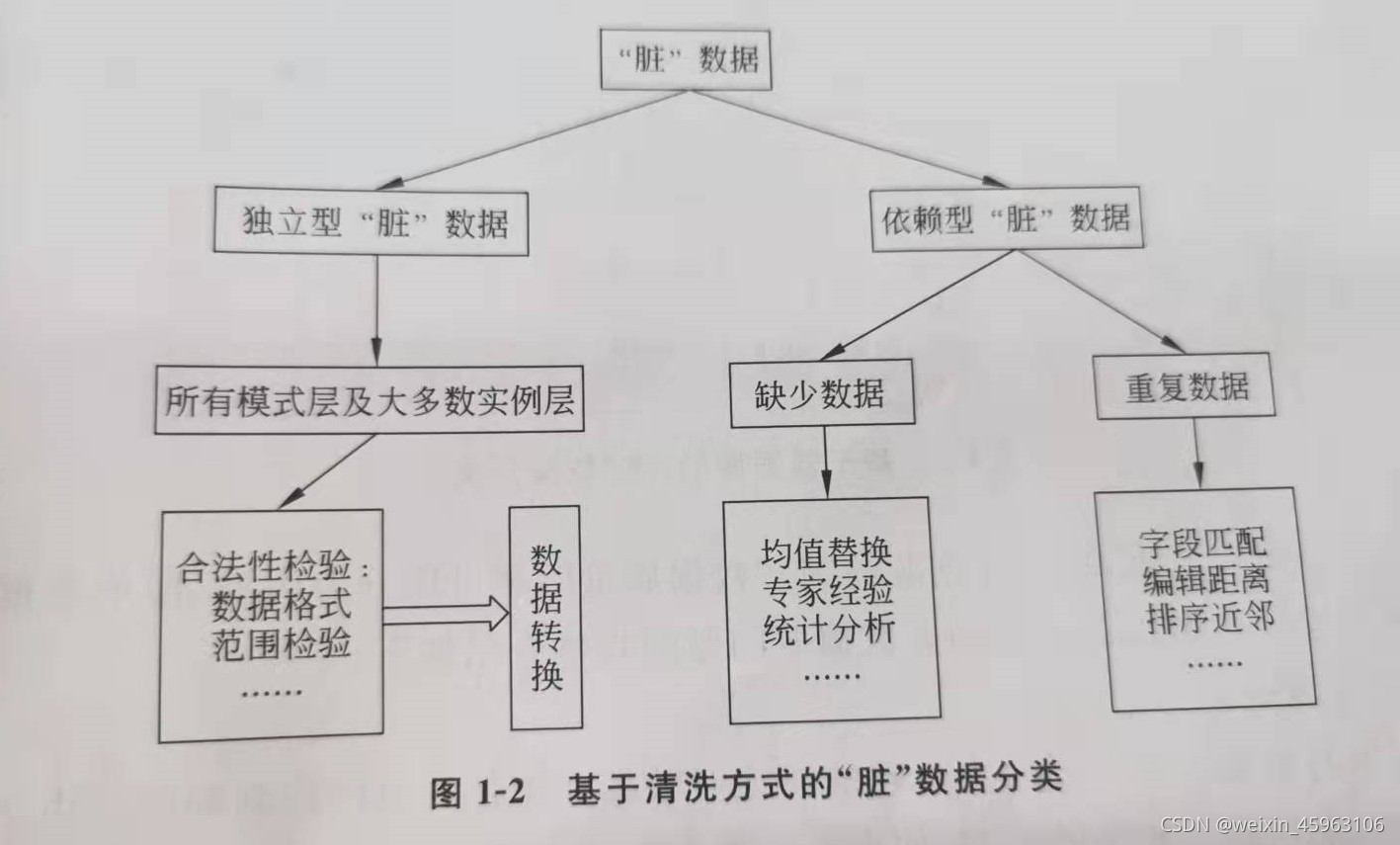
独立性脏数据:独立性脏数据可以通过记录或本身属性检验出是否包含脏数据,不需要依赖其他记录或属性检测。
合法性检验:是判断数据是否符合给定标准的过程。
数据转化 是将脏数据进行清洗的过程,包括模式转化和实例转换。
依赖性脏数据:依赖性脏数据主要包括缺失数据和重复数据等“脏数据”。由于需要综合考虑与其他记录间的关系,依赖性脏数据的处理很难有通用的方法。一般针对特定脏数据有特定的清洗方法
1、缺失数据:主要包括数据空值和数据异常
2、重复数据:是指一个现实实体在数据集合中以多个不完全相同的记录表示。
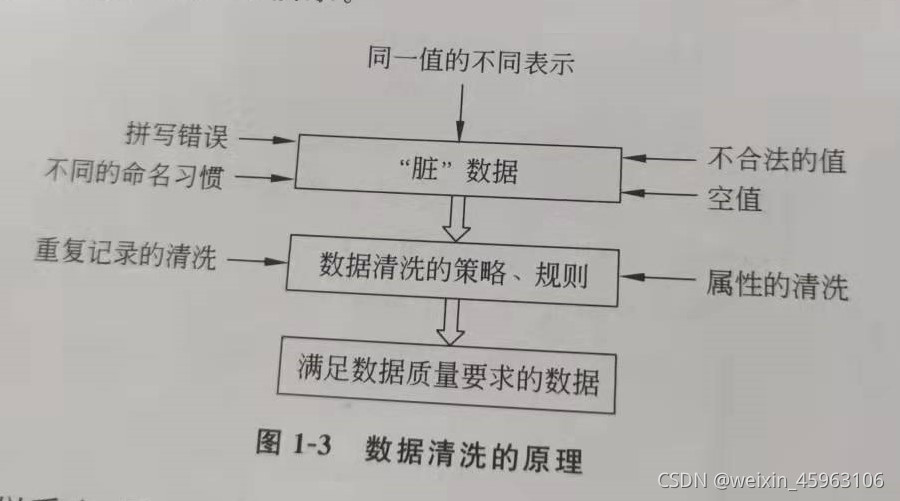
1.2 数据清洗的原理
1.3 数据清洗的基本流程
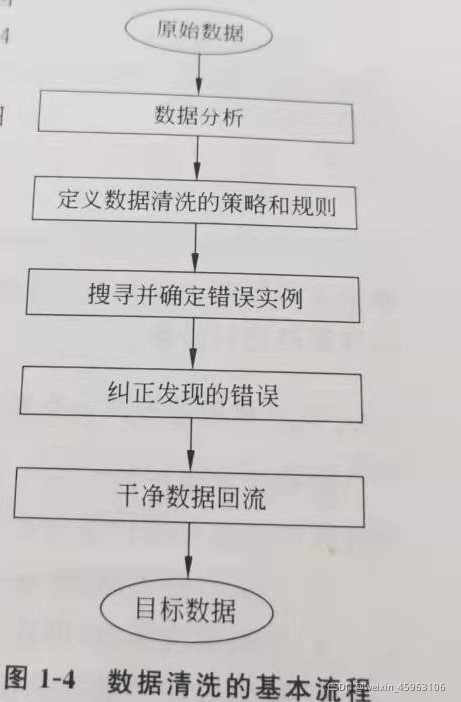
纠正发现的错误
为了便于处理单数据源、多数据源以及单数据源与其他数据源合并的数据质量问题,一般需要在各个数据源上进行转换操作,具体如下:
1、从数据源的属性字段抽取值。2、确认并记录。3.标准化
1.4 数据清洗的策略
一般的数据清洗策略:
1、手工清洗策略,通过人工直接改脏数据。 2、自动清洗策略,通过编写专门的应用程序检测并修改脏数据。 3、特定应用领域的清洗策略,根据概率统计学原理检测并修改数值异常记录。 4、与特定应用领域无关的清洗策略,根据相关算法检测并删除重复记录。
混合数据清洗策略:
主要以自动清洗为主。
1.5 常见的数据清洗方法
缺失值的清洗:忽略缺失值数据,填充缺失值数据
(1)忽略缺失值数据: 直接通过删除属性或者实例。
(2)填充缺失值数据: 使用最接近缺失值的值代替缺失的值。
重复清洗
基本思想:排序和合并
(1)相似度计算是通过计算记录的个别属性的相似度,然后考虑每个属性的不同权重值,进行加权平均后得到记录的相似度,若两记录相似度超过某一个阈值,则认为两条记录相匹配。
(2)基于基本邻近排序算法的核心思想是为了减少记录的比较次数。
错误值的清洗
错误值的清洗包括用统计方法识别可能的错误值、使用简单规则库、使用不同属性间的约束以及使用外部的数据等方法。
摘自《数据清洗》黑马程序员/编著
借鉴(21条消息) ETL的基础知识,看完你就全明白了!_飘渺Jam的博客-CSDN博客_etl

















 4614
4614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









