







Java面试题 - Java基础
参考教程
【本文参考自以下文章,部分图片及代码片段也取自以下文章,如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
Java_集合1(Collection接口方法、Iterator迭代器接口、Collection子接口:List、Set)
JVM虚拟机系统性学习-垃圾回收器Serial、ParNew、Parallel Scavenge和Parallel Old
浅析经典JVM垃圾收集器-Serial/ParNew/Parallel Scavenge/Serial Old/Parallel Old/CMS/G1
【本文参考自以上文章,部分图片及代码片段也取自以上文章,如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
Java 【语言】
基本语法
==
对于基本数据类型, == 比较两个对象的值是否相等
对于引用数据类型, == 比较两个对象的内存地址是否相等
【== 比较的永远是地址】
Java虚拟机中存在一片栈空间,用来存储基本数据类型的数据
在程序中声明一个基本数据类型量,将产生一个引用,存放在堆空间中,引用指向该数据的地址
int a = 3;
int b = 3;
// 以上声明将产生两个引用a,b,引用都指向3这个数据所在的位置
但是栈空间不能存储全部的基本数据量
当引用需要指向某个数据 num,则先在栈空间寻找 num 是否存在,如果存在则引用指向该地址
否则将 num 加入栈空间,引用指向栈空间的 num
equals()
equals() 是父类 Object 的一个方法
Object 是所有类的父类,在不重写 equals() 方法的情况下,equals() 默认使用 == 作运算
因此所有引用类型的默认比较方式都是 == 比较
重写equals()方法 | hashCode()
针对引用数据类型的对象,重写 equals() 方法来判定两个对象是否相同
从浅显的程序运行结果来看,equals() 重写生效但是我们认为如果两个对象相等,那么他们的 hashcode 也应该一致
为什么需要这样的设计呢
针对 集合 这个数据类型,要保证集合中的对象唯一,于是每次进行插入操作时都需要调用 equals() 方法
为了避免这种情况
使用算法为每个对象计算得一个 hashcode 值,将 Hash结构理解成链表组成的数组,相同 hashcode 值的对象以链表形式存储。当需要插入一个对象时,如果其 hashcode 已经存在,则调用 equals() 方法,结果为 false 时,才将该对象插入到链表;如果该对象的 hashcode不存在,则直接插入这边将 Hash结构看作链表组成的数组只是为了方便理解,实际上 hashcode 的组织方式非常的多
实际上 hashcode 是计算 Hash 表索引的依据,通过这个索引能够很快地确认对象则一定有以下情况:
hashcode 相同,但是对象不同;
对象相同,hashcode 一定相同;hashcode 不相同,则对象一定不相同hashCode() 也是 Object 类的一个方法,作用是返回一个对象的 hashcode
那么如果 equals() 返回的结果为 true,但未重写 hashCode() 方法,则可能出现 hashcode 不相同,但是对象相同的情况
I. 违反了 hashcode 的规定
II. 在基于集合的数据类型上,集合的特征会失效,出现相同元素
public class Point {
private final int x, y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof Point)) return false;
Point point = (Point) obj;
return x == point.x && y == point.y;
}
public static void main(String[] args) {
Point p1 = new Point(1, 2);
Point p2 = new Point(1, 2);
System.out.println(p1.equals(p2));// true
Map<Point, String> map = new HashMap<>();
map.put(p1, "p1");
System.out.println(map.get(p2)); // null,根据hashcode判断,p1和p2不相同
}
}
更加合适的理解是:
对于集合类型(Map、Collection),实例的 hashcode 作为集合索引的依据,如果不重写 hashCode 方法,则导致无法正确计算出索引值
static
修饰成员属性
被 static 修饰的属性将被该类的所有对象使用
一个对象A对其进行修改,别的对象B再使用该属性,该属性的值为被对象A修改后的值
修饰成员函数(方法)
当一个方法被 static 修饰,则可以不通过创建该类对象,使用 static 方法
使用方式为 Class_name.function_name()
class Test {
public static void sayHello(String name) {
System.out.println("Hello," + name);
}
}
public class Demo {
public static void main(String[] args) {
Test.sayHello("Tony"); // output: Hello,Tony
}
}
因为不需要创建类对象,可以节省空间
修饰内部类
【在此只阐述静态内部类的特殊性质,其余内部类的用法详见 Java · 基本语法 · 内部类 】
- 其他文件的类创建成员内部类对象:
new Host_class().new Inner_class() - 其他文件的类创建静态内部类对象:
new Host_class.Inner_class() - 静态内部类只能访问外部类的静态成员/静态方法
静态内部类的出现使得其他文件 The_other_class 在使用宿主类中的内部类时,可以不创建宿主对象
修饰代码块
被 static 修饰的代码块将在类加载器加载到该类的时候被执行,并且也只有在该时刻被执行
因此说它只会被执行一次
也因此常常用来做静态变量的初始化
认为在应用启动时,类加载器不会加载所有的类,也不进行对象的创建
因此静态代码块的执行并不需要类对象支持
静态导包
使用 static 修饰 import 导包语句,在后续使用中,包中的方法可以直接通过方法名进行调用
import static com.dotgua.study.PrintHelper.*;
public class Demo {
public static void main( String[] args ) {
print("Hello World!"); // 直接通过方法名进行调用,不需要写包名等
}
}
当包中的函数与类中的函数名冲突时,不可直接通过方法名调用方法,需要加上包名
静态方法为什么不能调用非静态的方法和变量
静态方法在初始化的时候就被加载,此时非静态方法和变量还未装载,因此不能
【更加详细的阐述见 JVM · 类加载】
static 与 final
final修饰类
- 被 final 修饰的类,表示该类不能被继承,一般是出于安全性考虑会这样做,其他情况下不建议使用 final 修饰类
- 被 final 修饰的类,它的方法也是隐式 final 属性的
final修饰方法
- 同样表示该方法不会被修改(不会被重写)
final修饰变量
-
被 final 修饰的变量几乎和被 const 修饰的变量一致,不能被修改
如果 final 修饰的是基本数据类型,则变量不允许被修改
如果 final 修饰的是引用数据类型,则引用与对象的指向关系不能被修改,但是对象本身还是可以修改的这与 C/C++ 中的 const + point 的情况有些相像
-
static final 修饰的变量,被称作编译期常量
个人理解的话,是因为 static 的量在编译期就会确定,如果这个静态量同时被 final 修饰,则它将在编译期确定为常量
-
一定有要求:final 量在使用之前,需要进行赋值(或者说初始化)
static 与 final 的区别
- static 修饰的量在编译期就被初始化,final 修饰的量在对象实例化时才会被初始化
- 如果一个量被 static final 同时修饰,则它的初始化流程基本等同于被 static 修饰,只是它被初始化后就不允许被修改了
面向对象
内部类
引言
- 在类里面定义的类称为内部类,内部类可以呈现嵌套的关系,它可以忽略外部类的成员属性、方法属性,访问外部类的所有成员和方法(静态内部类除外),同时,又可以将自身设为 protected 或 private 属性
- 内部类破坏了类面向对象思想,无论外部类的接口关系、类继承关系如何,内部类可以单独实现接口或继承其它的类
- 内部类在编译时,也将独立生成 .class 文件,如下
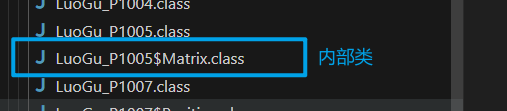
成员内部类/非静态内部类
- 在外部类中使用内部类,需要实例化内部类 Inner inner = new Inner()
Matrix matrix = new Matrix(row_n, column_n); - 在其他外部类中使用内部类,需要实例化外部类和内部类 Inner in = new Outer().new Inner()
Matrix matrix = new LuoGu_P1005().new Matrix();
静态内部类
- 使用 static 修饰的内部类,其性质已在 static 部分阐述过了awa
匿名内部类
-
针对只需要使用一次的对象(一般这样的对象会继承抽象类或实现接口),或者针对实现方式多种且每种方式都不相同的接口,可以使用匿名内部类进行处理
因此使用匿名内部类的时候,需要 new 出一个没有名字的对象
-
匿名内部类也在方法内使用,与局部内部类相似,之内使用方法中的 final 属性的变量,但能访问外部类的成员
/* 以按钮的点击事件为例 */
// 接口
public interface ClickListener {
void OnClick(); // 点击按钮之后需要进行的处理
}
// 按钮类
public class Button {
public void setOnClickListener(ClickListener listen) {
}
}
setOnClickListener(new ClickListener() { // 匿名内部类
@Override
public void OnClick() {
/* 点击按钮后的操作 */
}
})
局部内部类
- 在方法中定义的类叫做局部内部类,和其他内部类相同,它可以访问外部类的所有成员,但是局部内部类不能被访问控制修饰符和 static 修饰,并且,局部内部类的作用域只有当前方法,也只能访问当前方法中被 final 修饰的变量(JDK 1.8 之后,被局部内部类访问的变量天然具有 final 属性)
- 局部内部类中的内部类也不能使用访问控制修饰符和 static 修饰
- 在低版本的局部内部类,不能使用 static 修饰成员和方法
// JDK 8之后,局部内部类也可以使用 static
public class PartOutClass{
/* 外部类的成员及方法 */
public void function() {
class Inner { // 局部内部类
int i = 10;
static int a = 10; // 内部的静态变量
public static void funinner() { // 静态方法
}
}
// 从内部类外访问静态变量和静态方法,可以不用提前实例化内部类
// 从内部类外访问普通变量和方法,需要实例化内部类
Inner inner = new Inner();
}
}
- 当局部内部类使用结束后,将由系统在某时刻回收其资源
接口 | 抽象类
接口与抽象类的相同点是:实现接口和继承抽象类的类都需要对抽象函数进行实现(强制)
当然在 JDK1.8 之后,可以使用 default、static 对接口中的函数进行修饰
那么将抽象类理解为含有抽象函数的类
接口就是接口
-
类可以有构造方法,接口不可以
-
类可以含有普通方法(拥有函数体的方法),接口只能拥有抽象函数(JDK1.8 之后例外)
-
类可以有自己的成员变量,接口中的变量只能是常量
需要注意的是,这里的常量不是指 const 修饰的变量
而是被public static final修饰 -
由于抽象方法需要被实现,因此在类中,抽象方法的访问修饰符只能是 public、protected
default 不可以吗
接口中的抽象方法只能是 public 的
接口是没有子类的,所以 protected 修饰符是不起效的
大概
泛型
引言
-
从定义和使用的层面上来讲,泛型很好理解,即规定一个数据类型 可以接收其他任何数据类型的对象,然后进行统一的操作
-
泛型的另一作用是约束集合等类中的元素的数据类型,如 ArrayList,它可以接收任一引用数据类型作为列表元素,在列表声明时,不对数据类型进行指定,则将使用 Object 作为数据类型
ArrayList list = new ArrayList();如果对泛型的数据类型进行指定,则列表只能单一接收某个数据类型的值,从而避免运行时异常
ArrayList<String> list = new ArrayList<>(); -
泛型接口即,在接口声明时,将接口中需要使用的某些参数定义为泛型,当类实现接口时,需要对泛型进行指定
-
泛型类即在类定义时,将某个成员/方法参数的数据类型定义为泛型
-
泛型对象在实例化时,才对泛型类声明时指定的泛型进行参数和方法的初始化,因此,泛型类中的泛型元素、泛型方法,不能使用 static 修饰
public class Test<T, K> {
public static T one; // 编译错误
public static T show(T one){ // 编译错误
return null;
}
// 泛型类定义的类型参数 T 不能在静态方法中使用
public static <E> E show(E one){ // 这是正确的,因为 E 是在静态方法签名中新定义的类型参数
return null;
}
// 普通方法
public T ord_show(K one){
return one;
}
}
-
但是泛型方法可以使用函数名中指定的泛型,因此对于使用新定义的泛型的方法,可以声明为 static
其底层原因是,泛型方法中声明的泛型是针对方法的,和类定义中的泛型无关
泛型方法在声明时,需要在返回值类型前加上 <> 泛型定义
-
在泛型方法被调用时定义数据类型,也可以不指定数据类型
Test test = new Test<String, Integer>();
test.show(20); // 隐式指定泛型为 Integer(自动装箱) 类型
test.<String>show("muhuai"); // 显式指定泛型为 String 类型
使用场景 - ResultWrapper 封装类
- 举一个应用比较宽泛的例子:Mybatis-plus 中的分页函数,它接收的实例类型为泛型,使得它可以对任意实体的查询结果进行分页
- ResultWrapper 封装类
@Data
public class ResultWrapper<T> { // 泛型类声明
private T data;
/* 其他成员及构造函数 */
// 封装函数,返回一个ResultWrapper<T>对象
public static <T> ResultWrapper<T> assemble(int code, boolean success, T data) {
ResultWrapper<T> resultWrapper = new ResultWrapper<>();
resultWrapper.setCode(code);
resultWrapper.setSuccess(success);
resultWrapper.setData(data);
return resultWrapper;
}
public static <T> ResultWrapper<T> success(T data) {
return assemble(ResultCode.SUCCESS.getCode(), true, data);
}
public ResultWrapper<T> data(T data) {
this.setData(data);
return this;
}
}
泛型与 CountDownLatch
-
CountDownLatch 是 JUC 下的一个线程管理类,主要应用于多线程协调,使得某线程(一般是主线程)可以在其他线程执行完毕之后,再继续向下执行
CountDownLatch 维护了一个计数器,当计数器为 0 时,表示需要等待的线程已经执行完,则主线程可以向下执行,它和 join 的作用是一致的,但是 join 不适用于线程池,主线程必须等待其他线程结束后才能继续
-
但是 CountDownLatch 只能对线程进行管理,并不能获得线程执行的结果,为了解决这个问题,可以使用泛型接收执行结果
-
使用一个泛型类包裹 CounDownLatch,CountDownLatch 主要有以下四个函数
void countDown(); // 计数器自减long getCount(); // 获取计数器中的计数值void await(); // 等待其他线程运行,直到计数器中的值为 0boolean await(long timeout, TimeUnit unit); // 等待其他线程运行,如果超时,则停止等待
public class SynchroniseUtil<T>{
private final CountDownLatch countDownLatch = new CountDownLatch(1);
private T result;
public T get() throws InterruptedException{
countDownLatch.await();
return this.result;
}
public T get(long timeout, TimeUnit timeUnit) throws Exception{
if (countDownLatch.await(timeout, timeUnit)) {
return this.result;
} else {
throw new RuntimeException("超时");
}
}
public void setResult(T result) {
this.result = result;
countDownLatch.countDown();
}
}
拆箱 | 装箱
众所周知,在 Java 中的8种基本数据类型都各自对应了8种封装的引用类型(包装类)
| 基本数据类型 | 大小 | 包装类型 | 缓冲区数据范围 |
|---|---|---|---|
| byte | 8 | Byte | [-128, 127] |
| short | 16 | Short | [-128, 127] |
| int | 32 | Integer | [-128, 127] |
| long | 64 | Long | [-128, 127] |
| float | 32 | Float | / |
| double | 64 | Double | / |
| char | 16 | Character | [0, 127] |
| boolean | / | Boolean | / |
boolean 单独使用时,占 4 个字节(和 int 一样大),当它作为数组使用时,每个boolean占 1 个字节
为什么要使用封装类
- 因为基本数据类型不是对象,没有面向对象的思想
- 因为 Java 的泛型、集合不支持基本数据类型?
- 封装类提供更多更优雅更好用的函数
封装类是引用数据类型!!!
必须明确的一点是,封装类它是引用数据类型,因此使用 == 将比较它们的地址,同时,因为 equals() 方法只针对同一数据类型的两个对象,因此不能使用
但是!!!自动拆箱与装箱解决了基本数据类型和封装类之间的问题
自动拆箱 | 装箱
拆箱是指:将包装类转化为基本数据类型;装箱是指:将基本数据类型转化为包装类
public class Demo {
public static void main(String[] args) {
int int1 = 12;
int int2 = 12;
Integer integer1 = new Integer(12);
Integer integer2 = new Integer(12);
System.out.println((int1 == int2)); // true
System.out.println((int1 == integer1)); // true
System.out.println((integer1 == integer2)); // false
}
}
在包装类与基本数据类型进行比较时,包装类会自动拆箱成基本数据类型
所以int1 == integer1 = true
但是integer1 == integer2是包装类之间的比较,不发生拆箱,因此为 false
值得注意的是,自动拆箱和自动装箱都采用了类似于 intValue() 和 longValue() 的方法,因此自动拆箱可能出现空指针异常,如下:
Integer a = null;
System.out.println(2 == a);
缓冲区
在介绍 String 常量池的时候有说到,基本数据类型也将维护一个缓冲区(常量池),但是又有所不同
缓冲区的数据是固定的一组数据,数据范围如上表
基本数据类型应该不具有:当出现了缓冲区不存在的量,就创建,同时放入缓冲区的行为
包装类使用直接复制(装箱)的方式创建对象时,会去缓冲区查找该值是否在缓冲区数据范围内,如果在,则直接返回缓冲区该值的引用
Integer a = 127;
Integer b = 127;
Integer c = 128;
Integer d = 128;
System.out.println(a == b); // true
System.out.println(c == d); // false
执行效率
很明显,基本数据类型更快一点
反射
引言
反射
- 反射的核心思想是,在 Java 中,一个类在加载后,将由系统在堆中生成一个类的 Class(对象),这个 Class 将包含该类的所有信息,包括成员及方法等,通过对象访问该类的所有信息,如同透过镜子看到对象的全貌一样,称之为反射
- 所以反射的核心思想就是:获得类的 Class 对象,然后通过 Class 加载对象信息,再使用方法对象/成员变量对象等中间工具,访问类成员及方法
为什么使用反射 / 反射的作用
-
通过配置文件访问类及类方法
如:现有一个 re.properties 文件,可以使用 .getProperty 方法获取到类全名及类方法,但是却无法通过 classfullpath / methodName 来访问类
public class ReflectionQuestion {
public static void main(String[] args) throws Exception {
// 1. 使用Properties 类, 可以读取配置文件
Properties properties = new Properties();
properties.load(new FileInputStream("src//re.properties"));
// 获得类全名
String classfullpath = properties.getProperty("classfullpath");
// 获得类方法名
String methodName = properties.getProperty("method");
// 2. 使用反射机制
// (1) 加载类, 返回 Class 类型的对象 cls (类在堆中由系统生成的 Class )
Class cls = Class.forName(classfullpath);
// (2) 通过 cls 得到你加载的类的对象实例
Object o = cls.newInstance();
// (3) 通过cls得到你加载的类的方法对象
Method method = cls.getMethod(methodName);
// (4) 通过method 调用方法: 即通过方法对象来实现调用方法
method.invoke(o); //传统方法对象.方法() , 反射机制:方法.invoke(对象)
}
}
-
类加载
类加载即将类的 .class 文件读入内存,并生成 java.lang.Class 对象(反射就是通过这个对象实现)
-
动态类加载
使用反射访问类成员及方法,和传统类加载(静态加载)不同,此时类在反射被调用时,才会被加载;静态加载会在 显式实例化对象(使用 new 关键字实例化对象)/访问类中的静态成员或静态方法/加载子类的时候加载其父类 的情况下被加载
反射类加载
常见的反射类加载就以下三种
class Student {
/* 成员变量及函数 */
}
// Class_name.forName("the path of Class")
Class <?> aClass1 = Class.forName("demo01.Student");
// ClassLoader
Class <?> aClass1 = ClassLoader.getSystemClassLoader().loadClass("path of Class");
// Class_name.class
Class<Student> aClass2 = Student.class;
// Object_name.getClass()
Student s = new Student();
Class<? extends Student> aClass3 = s.getClass();
// 以上三种方式得到的反射类地址相同
Class.forName
一般我们使用普通的 forName() 方法,但是它还提供一个重载,
这个重载可以让程序员决定是否要对获得的反射类进行初始化:
boolean initialize 如果参数值为 true,则进行初始化(初始化静态资源)
public static Class<?> forName
(String name, boolean initialize, ClassLoader loader) {}
我们看 forName() 方法的原码,就会发现它的初始化默认为 true,即默认进行初始化
@CallerSensitive
public static Class<?> forName
(String className) throws ClassNotFoundException {
// 此处可见 forName() 使用了反射类(接口)?
Class<?> caller = Reflection.getCallerClass();
return forName0(className, true, ClassLoader.getClassLoader(caller), caller);
}
forName() 方法的底层还是 ClassLoader,使用它的 ClassLoader.getClassLoader 方法
ClassLoader
- ClassLoader 不支持初始化,但是 ClassLoader 还可以加载图片、配置文件等,也可以加载不在 classpath 下的类及资源
- ClassLoader 的使用方式
ClassLoader.getSystemClassLoader().loadClass("path of Class")
类加载完成后,要想实例化对象,需要调用 .newInstance 方法
反射类实例化
- newInstance() 创建反射类的实例,可以使用无参构造和有参构造
// Class.newInstance()调用无参构造函数
Class <?> ac1 = Class.forName("demo01.Student");
Person person = (Person)ac1.newInstance(); // 实例化得到Person对象
// Constructor.newInstance() 可以调用有参构造函数
// 一个用来承接构造函数、成员函数的Constructor数组
Constructor<?> cons[] = ac1.getConstructors(); // 反射对象构造器
// 调用构造函数创建实例
test = (Test) cons[0].newInstance("Tony");
反射类方法
-
通过反射访问类方法,需要先借助方法类 java.lang.reflect.Method 获取方法对象
Method method = ac1.getMethod("function_name", paremeter_type.class);Example: Method method = ac1.getMethod("sayHello", String.class, Integer.class); -
通过 invoke 调用反射类中的方法
method.invoke(ac1);Example: method.invoke(ac2.newInstance(), "Tony", 20); -
需要注意的是,使用反射调用类方法可以无视访问修饰符的限制,只需要使用
setAccessible(true)进行访问设置即可method.setAccessible(true);
修改反射类属性
-
获取反射类的属性需要借助类 java.lang.reflect.Field,通过属性对象访问反射类的属性
Field field = ac1.getDeclaredField("member_name");
User user = new User();
Class<? extends User> aClass = user.getClass();
Field nameField = aClass.getDeclaredField("name");
nameField.setAccessible(true); // 将name属性设置成可被外部访问
/* 通过反射访问name属性内容 */
nameField.setAccessible(false); // 将name属性设置成不可被外部访问
-
和反射方法类似,通过反射类访问属性时,也使用对象作为参数,属性作为主体
nameField.set(user, "Tony");
其他
获取反射类的父类
- 通过 getSuperClass 获取父类之后,访问父类
Class<? extends User> aClass = user.getClass(); // 获取反射类
Class<?> superclass = aClass.getSuperclass(); // 获取反射类的父类
Field[] superFields = superclass.getDeclaredFields(); // 父类的属性列表
for (Field declaredField : superFields) { // 增强循环
String name = declaredField.getName();
System.out.println(name);
}
访问数组
-
借助 .getComponentType 方法加载数组的 Class 类
Class<?> c = arr.getClass().getComponentType(); -
依然借助 .newInstance 方法进行反射数组类的实例化
但是我现在也不知道构造函数和成员函数在数组中是怎么组织的 awa
数据类型
引用类型
强弱软虚
强引用
- 被强引用关联的对象无论如何都不会被垃圾回收,JVM 在内存不足时会抛出 OOM,这种情况下也不会回收强引用相关的对象
- 大部分的引用都是强引用
软引用
-
当内存不足时,JVM 将对软引用关联的对象进行回收
确切地说是,当发生 GC 后还是内存不足,JVM 就会回收软引用的对象,即在内存足够时,GC 无法回收软引用对象手动 GC:
System.gc(); -
软引用主要用于缓存
-
软引用在使用时,需要使用 softReference 包裹对象
// 创建一个User对象的软引用
SoftReference<User> softReference = new SoftReference<User>(new User());
// 获取软引用中的对象,如果get到的值为null,则说明该对象被回收了
User User = softReference.get();
弱引用
- 当发生 GC 时,弱引用关联的对象就会被回收
- 弱引用也主要用于缓存,如 ThreadLocal、WeakHashMap,针对于需要随时拿取,并且用得较少的对象
- 软引用在使用时,使用 WeakReference 包裹对象
// 为一个User对象创建一个弱引用
WeakReference<User> weakReference = new WeakReference<User>(new User());
// 获取弱引用中的对象
User User = weakReference.get();
虚引用
-
虚引用的主要作用是向程序员告知虚引用中的对象是否将要被回收,这使得程序员在对象被回收之前可以做一些必要的操作
-
虚引用一般和 ReferenceQueue 联用,被虚引用关联的对象被 PhantomReference 关键字包裹
-
被虚引用的对象,在 GC 时,会先进行入队到 ReferenceQueue,程序员通过访问队列知道该对象是否要被回收
-
通过 PhantomReference 的 get 方法无法获取到对象本身,只能获取到 null,这是因为如果虚引用的 get 方法如果能够获取到对象,则这个引用就应该是(强/软/弱)引用【跟没说有什么区别】
如果要获取虚引用中的对象,我记得是有一个办法的,但是我忘了QAQ
常用类
String
String
String的底层字符数组使用 final 进行修饰,因此不能修改 String 的值,只能更改引用的指向
- 保证了线程安全,也从一定程度上保证系统的安全,外来数据不能对 String 内容进行修改
- 更好地支撑常量池的应用,一个不可变的字符串放入常量池,然后在需要的时候直接返回常量池中对象的引用,会比每次都创建一个对象快很多
当然,可变的对象不能放入常量池显而易见 - 支持更快的效率
字符串不可变使得对于一个 String 来说,不需要每次去计算它的 hashcode,因此在 Java 的 hash 表中,String类型的字段作为键(key)
通过反射修改 String 的值
- String 的底层作为字符数组,本质是数组,也是引用数据类型,而使用 final 修饰,只能限制字符数组的引用不改变,因此可以绕过数组地址,直接修改数组的数据
- 使用反射【 Java 的反射机制详见 Java · 反射】
import java.lang.reflect.Field;
public class stringDemo {
public static void main(String[] args)
throws NoSuchFieldException, IllegalAccessException {
String s = "abc";
Class clz = s.getClass();
//需要使用getDeclaredField(), getField()只能获取公共成员字段
Field field = clz.getDeclaredField("value");
field.setAccessible(true);
char[] ch =(char[])field.get(s);
ch[1] = '8';
System.out.println("abc"); // output: a8c
}
}
Java 机制中,“abc” 也将指向一个对象,即常量池中 “abc” 字面量对应的对象
但是通过 getDeclaredField() 和 setAccessible() 方法,绕过数组地址,直接改变了数组内容
因此输出 “a8c”
String | StringBuffer | StringBuilder
- String是一种特殊的封装类,底层的字符数组用 final 修饰,一旦声明之后,不可修改,也因此线程安全
- StringBuffer和StringBuilder的底层字符数组没有用 final 修饰,因此可变
StringBuffer的每个方法前都使用 synchronized 进行修饰,因此线程安全
StringBuilder并没有线程安全的处理,因此运行速率更快 - 从运行速率的角度:StringBuilder > StringBuffer > String
关于运行速率的解释,可以认为
String 的字符数组由 final 修饰,每次进行字符串的修改时,都需使引用重新指向需要指向的对象
StringBuffer 和 StringBulider 由于底层字符数组可变,在进行字符串修改时,只需要修改该对象即可
由于 StringBuffer 使用了线程锁,因此更慢一点
常量池
-
Java会为每个被装载的类(也可以认为常量池中的数据类型只包括基本数据类型和String)准备一个常量池,用来存储在编译器就能确定的数据,比如字面量、使用 final 修饰的数据、确定的符号引用等
字面量:
String str = "muhuai";中的muhuai就是一个字面量 -
使用new关键字,将创建一个对象,并将对象放入堆中
直接用字面量进行 赋值 操作,将创建一个引用变量,变量指向字面量所对应的对象
题目:说明以下情况中,会创建的对象个数
String str1 = "muhuai"; // 创建了一个对象muhuai,并将它放入常量池,str1作为引用变量指向该对象
String str2 = new String("muhuai"); // 创建了一个对象,str2作为对象,指向常量池中的对象muhuai
// 创建一个mh对象,放入常量池,再创建一个str3对象,指向mh对象
String str3 = new String("mh");
// 先创建两个对象m,huai放入常量池,再创建两个String对象,指向常量池中的两个对象
// 经过运算得到的mhuai对象,即str4将放入堆区
String str4 = new String("m") + new String("huai");
// huai已经存在于常量池,mu不存在,因此创建一个对象mu,放入常量池
// str1是编译期不能确定的,因此由运算得到的对象放入堆区,即str5放入堆区,str5作为对象存在
String str5 = "mu" + str1 + "huai";
// 同理,new出的对象也无法在编译期确定,因此str8作为对象,放在堆区
// lin gui作为字面量,且不存在于常量池中,因此创建两个对象,放入常量池
// 同时,new声明的隐式对象也将放在堆中,指向gui,所以一共创建4个对象
String str8 = "lin" + new String("gui");
// 对于Java编译期来说,str6可以在编译期得到,muhuai,并且发现muhuai存在于常量区,因此不新增对象
// 同理,对于str7,xinxin,则需要创建一个对象,放入常量区
// str6 str7均作为对象存在
String str6 = "mu" + "huai";
String str7 = "xin" + "xin";
在编译期就能确定的量,将放入常量池,等到运行时才能确定的量,放入堆区
intern
与 C/C++ 中的 extern 相比较,extern 引入其他文件的定义为己用
Java 的 intern 将指定字符串加入常量池,如果常量池中已存在该字符串,则返回它的引用
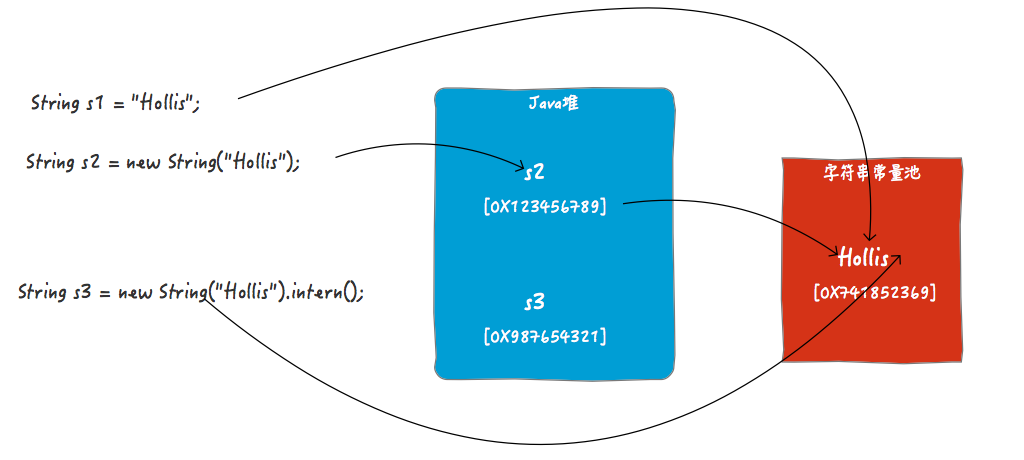
在 Java 的运行方式中,确定的字符串加入常量池,不确定的字符串将使用 StringBuilder 进行转化
因此,对于大量使用而又不能确定的字符串,可以使用 intern() 方法将其加入常量池
String s1 = "Hollis";
String s2 = "Chuang";
String s3 = s1 + s2;
// 反编译后的结果【也可理解为实际上运行时的处理方式】
String s1 = "Hollis";
String s2 = "Chuang";
String s3 = (new StringBuilder()).append(s1).append(s2).toString();
// 如果对s3使用intern()方法,"HollisChuang"就会被加入常量池
集合
首先我们要明白,这里所指的集合,是实现了 Collection 或者 Map 接口的类
Collection
Java_集合1(Collection接口方法、Iterator迭代器接口、Collection子接口:List、Set)
List
ArrayList
ArrayList 和 数组
- ArrayList 和 数组
之前我一直觉得 ArrayList 和 数组是一个东西
ArrayList 基于数组,但是比数组更加灵活,它像是一个封装好的 “顺序表” - ArrayList 可以动态扩充大小,数组在初始化时就需要指定大小
ArrayList 只能存放引用数据类型,但是同一个 ArrayList 中,可以存放不同类型的数据 - ArrayList 提供了很多好用的方法
将封装看作数据类型,因此 ArrayList 支持在任意位置增删数据
// 创建ArrayList
ArrayList L1 = new ArrayList(); // 创建ArrayList,不指定数据类型,初始容量为0
ArrayList L2 = new ArrayList(10); // 创建ArrayList,不指定数据类型,初始容量为10(但均为空值)
ArrayList<Integer> L3 = new ArrayList<Integer> (10); // 创建ArrayList,指定数据类型为Integer,初始容量为10(但均为空值)
// 增添元素 arraylist.add()
ArrayList <Integer> arrlist = new ArrayList<Integer>();
arrlist.add(10); // 在末尾添加10
arrlist.add(0,4); // 在0位置前插入元素4
// 删除元素 arraylist.remove()
arrlist.remove(new Integer(10)); // 删除第一个值为10的元素,必须传入一个对象
arrlist.remove(0); // 删除索引为0的元素
// 遍历 迭代器 arraylist.iterator,效率最低
ArrayList<Integer> L = new ArrayList<Integer> (10);
Iterator<Integer> it = L.iterator();
while(it.hasNext()){
System.out.print(it.next()+" ");
}
// 遍历 foreach(增强循环)
for(Integer element : arrlist){
System.out.print(element + " ");
}
// 遍历 索引值 arraylist.get(),效率最高
for(int i = 0; i < 15; i++){
System.out.print(arrlist.get(i) + " ");
}
// arraylist.clear() 清空ArrayList
// arraylist.isEmpty() ArrayList是否为空
// arraylist.size() ArrayList中元素的个数
// arraylist.toArray() 将ArrayList转为Array
需要注意的是,ArrayList转为Array属于向下转型,直接这样使用是不行的
Integer[] intarr = (Integer[])L.toArray();需要先声明一个
intarr,再进行转化
Integer[] intarr = new Integer[L.size()];
L.toArray(intarr);
数组
- 需要注意在 Java 中的数组声明和初始化的方式(与 C/C++ 不同)
- 在 Java 中,数组是一个对象,拥有成员函数
int[] arr1 = new int[3]; int[] arr2 = {1,2,3}; // int[] arr3 = new int[3] = {1, 2, 3}; // error // arr.clone() 克隆 int[] arr_clone = arr2.clone(); // arr.length() 数组的大小 System.out.println(arr1.length()); // 3 /* C 写法 int array1[10]; int array2[10] = {0}; */Array
- Array 作为一个工具类,对数组类型的数据进行操作
String[] strs = {"mu", "hu","ai", "mh"}; // sort() 排序 // toString() Arrays.sort(strs); System.out.println(Arrays.toString(strs)); // [ai, hu, mh, mu] // binarySearch() 对有序数组进行二分查找,返回下标 System.out.println(Arrays.binarySearch(strs, "ai")); // 0 // asList() 将数组转化为 ArrayList【但是存在相互影响的问题】对于基本数据类型和 String 类型,不需要实现 sort 接口,默认升序排序
ArrayList 和 LinkedList
- ArrayList 基于数组,LinkedList 基于链表
==> ArrayList 支持随机访问,LinkedList 不支持
==> ArrayList 在插入元素时效率较低大概是因为在插入元素并进行扩容时,需要进行复制操作LinkedList 在插入操作时效率较高 - 将 ArrayList 理解为封装后的顺序表,LinkedList 理解为双向链表
线程安全
这个教程讲得真的非常好 awa
Java–ArrayList保证线程安全的方法
ArrayList 是线程不安全的
-
将 ArrayList 插入元素操作分为三个部分
I. 判断当前空间是否足够
II. 插入元素arraylist[size] = e;
III.size++; -
则对于两个线程来说,可能出现的执行顺序有
线程1:执行 I. II. II. ==> 结果向 arraylist 插入一个元素 ==> 成功;
线程2:执行 I. II. II. ==> 结果向 arraylist 插入一个元素 ==> 成功;
==> 无异常线程1:获得时间片,执行 I. ==> 结果为空间足够(最后一个空间);线程2:获得时间片,执行 I. ==> 结果为空间足够(最后一个空间);
线程1:执行赋值操作,并执行自加操作;线程2:执行赋值操作;
由于此时用于标志数组位的 size 已经进行自加,线程2执行赋值操作时将发生数组越界;
==> 发生数组越界异常线程1:获得时间片,执行 I. ==> 结果为空间足够;线程2:获得时间片,执行 I. ==> 结果为空间足够;
线程1:进行赋值操作;线程2:进行赋值操作;
线程1:自加操作;线程2:自加操作;
==> 线程2的赋值操作覆盖线程1的赋值操作,导致线程1的数据丢失
==> 两次自加操作导致中间有一次的数据没有进行赋值,出现 null 值
解决 ArrayList 线程不安全的办法
-
使用 Vector,Vector 线程安全
因为 Vector 使用了 synchronized 锁 -
使用 Collections.synchronizedList(list)
即在声明时就使用 Collections.synchronizedList(new ArrayList<>()) 包裹 ArrayList
List<String> list = Collections.synchronizedList(new ArrayList<String>());
需要注意的是,这种方法的本质是使用一个加锁的 List 包裹 ArrayList,而 ArrayList 本身的数据不是加锁的,因此在直接、间接使用迭代器的时候也需要加锁 -
使用 JUC 中的 CopyOnWriteArrayList
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<String>();每次进行读写操作的时候都复制一份快照数组出来,在快照数组的基础上进行读写,当快照数组被修改,则将原数组指针指向新快照
扩容
-
和使用 C/C++ 实现顺序表一样,扩容的本质是:
new 一个更大容量的空间,然后将原来的数组数据复制到新空间中,最后将数组首地址指向新空间 -
Java ArrayList 和 Vector 的初始容量都为 10
这不是说它们在初始化时就具备 10 的容量,在没有声明初始容量大小的情况下,它们的初始化容量都是 0
初始大小是说它们在第一次插入元素时,将会声明的空间大小为 10 -
ArrayList 的扩容倍数为 1.5;Vector 的扩容倍数为 2
即每次扩容都在原容量的基础上 × 1.5 或者 × 2
-
具体的 ArrayList 的扩容机制还将涉及到最大、最小容量的比较和选择
【等我彻底学会了再做补充】
LinkedList
LinkedList 和 链表
- 链表是一种数据结构,有多种类型
单向链表 | 双向链表
循环链表 | 非循环链表
带头结点 | 不带头结点 - LinkedList 的底层是双向链表
线程安全
LinkedList 是线程不安全的
- LinkedList 的不安全性很好理解,链表中的增删操作都不是原子操作,在多线程场景下,甚至导致链表的结构发生变化
- 如,在线程1遍历链表时,线程2正对链表进行修改(增删操作),则线程1可能访问到一个结构发生变化的链表
解决 LinkedList 线程不安全的办法
- 同 ArrayList,使用 Collections.synchronizedList() 包裹 LinkedList
- 使用 JUC 中的 ConcurrentLinkedQueue
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue();
Vector
-
Vector 实现了 Serializable、Cloneable、RandomAccess 接口
Serializeable 用于支持序列化与反序列化(即将对象写入磁盘/从磁盘中读取对象)
Cloneable 的主要使用场景在于 .clone 方法的使用
RandomAccess 即支持随机访问,实际上是支持 ArrayList 的随机访问,而 ArrayList 的底层是数组,从理论上提供了随机访问功能;Vector 的底层也是 ArrayList,可以将其看作线程安全的 ArrayList
-
Vector 还继承了 AbstractList 抽象类,抽象类实现了 List 接口,因此 Vector 也实现了 List 规定的方法
与 ArrayList 的相同点
- 底层都是基于数组,支持随机访问,即便封装后的数据结构可以支持数据的增删,但是从原理上来讲,增删数据依然是较为不便的操作
- 都支持迭代器对容器元素进行访问
- 初始的默认容器(数组)大小都为 10,但是 Vector 在对象实例化时,就会实际分配 10 个对应空间,而 ArrayList 等到执行 .add 操作时,才会分配空间
- 都是存储引用数据类型的容器
与 ArrayList 的不同点
- Vector 的所有方法都是用了 synchronized 关键字,保证了线程安全
- Vector 的数组扩容方式为原大小 × 2,而 ArrayList 为原大小 × 1.5
- 当容器元素是 Object 时,由于 ArrayList 对于数组使用了 transient 关键字,在序列化时 Object 对象将舍去成员变量的实际值,在反序列化时, Object 对象的成员变量将进行初始化,初始化为 0/null
List 相关方法
subList()
相互影响
subList() 是 List 的一个方法 即所有实现 List 接口的类都可以使用该方法
- subList() 将获取到 列表 的 子列表
List<Integer> integerList = new ArrayList<>();
integerList.add(1);
integerList.add(2);
integerList.add(3);
List<Integer> subList = integerList.subList(0, 2); // [1, 2]
其中 integerList 将获取到 integerList 的下标 0 到 下标 2 的数据 (闭开区间)
- subList() 获取到的子列表,它的首地址依然指向原列表,对子列表进行操作,将同时影响原列表;同样的,对原列表进行操作,也将同时作用到子列表上
// 原列表 [1, 2, 3]; 子列表 [1, 2];
subList.set(0, 10); // 将子列表的0位设为10
integerList.set(1, 20); // 将原列表的1位设为20
// 进行set操作之后,原列表变为 [10, 20, 3]; 子列表变为 [10, 20];
- Array 的 asList 方法也有相互影响的问题
解决相互影响的办法
- 在 subList() 外包裹一个 ArrayList
个人理解来说就是,使用了一个新的 List 来承接 subList() 的结果,使得子列表指向新 List 的首地址
List<Integer> subList = new ArrayList<>(integerList.subList(0, 2));
安全删除
使用 List 提供的删除函数(底层都是使用了迭代器 Iterator)
-
removeIf()
removeIf() 好像是使用了 Lambda 表达式的写法
list.removeIf(item -> /* condition */);
如:list.removeIf(item -> "b".equals(item));以上代码等价于
Iterator<String> it = list.iterator(); while (it.hasNext()) { String s = it.next(); if ("b".equals(s)) { it.remove(); } }当然我也没试过这样的写法
list.removeIf(item -> { /* condition */ }); -
stream().filter() 【流 + 过滤器】
List<String> newList = list.stream() .filter(e -> !"b".equals(e)) .collect(Collectors.toList());如上,最后还使用终止操作,同时用到 Collections 工具类,生成一个 List
遍历删除
需要特别注意,遍历删除最好使用倒序遍历,原因见【常见问题】
for (int i = list.size() - 1; i >= 0; i--) {
if ("b".equals(list.get(i))) {
list.remove(i);
}
}
遍历删除也是最容易出错的
是因为在 Java 中,使用 remove() 方法删除元素,则 List 的 size 也将一并自减,并进行元素移动操作
常见问题
// 删除List里面的所有数据
/* 创建数组 */
private static List<String> list = new ArrayList<>();
public static void main(String[] args) {
reset();
}
private static void reset(){
list.clear();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
}
/* 正序删除 不能得到正确结果 */
/* 是因为每次进行remove操作时,都会进行size自减和元素前移操作 */
/*
i = 0,size = 5;删除a,size = 4,bcde前移;i++
i = 1,size = 4;删除c,size = 3,de前移;i++
i = 2,size = 3;删除e,size = 2,over
*/
public static void method1() {
for (int i = 0; i< list.size(); i++) {
list.remove(i);
}
System.out.println(list); // [b, d]
}
/* 正序删除下标0位元素,出现的问题同理,size做自减,导致无法完全删除 */
/* List倒序一半的元素不能被删除 */
public static void method2() {
for (int i = 0; i< list.size(); i++) {
list.remove(0);
}
System.out.println(list); // [d, e]
}
/* 提前使用len存储List的元素个数size,将出现下标越界异常 */
/* 因为在remove过程中,等价于数组大小的自减,因此在i自增的过程中,出现i>size的情况 */
public static void method3() {
int len = list.size();
for (int i = 0; i < len; i++) {
list.remove(i);
}
System.out.println(list);
}
/* 提前使用len存储List的元素个数size,删除下标0位元素,正确 */
public static void method4() {
int len = list.size(); // 保证只获取一次长度
for (int i = 0; i< len; i++) {
list.remove(0);
}
System.out.println(list);
}
去重
直接去重
- stream().distinct()
list.stream().distinct().collect(Collections.toList());
- HashSet(HashSet 得到的集合是无序的)
如果想要得到一个有序的集合,则使用 ArrayList 等,将 HashSet 中的值复制到有序集合(列表)
使用 add() 方法
HashSet<Integer> h = new HashSet<>(list);
return new ArrayList<>(h); // 无序
Set<Integer> set = new HashSet<>();
List<Integer> newList = new ArrayList<>();
for (Integer element : list) {
if (set.add(element)) // 能够添加证明唯一
newList.add(element);
}
return newList; // 有序
当然再次声明,有序,不是指升序或者降序
- TreeSet
TreeSet<Integer> set = new TreeSet<>(list);
return new ArrayList<>(set); // 有序
根据对象的属性去重
- TreeSet
TreeSet 比较好理解,使用了 Lambda 表达式在初始化 TreeSet 时传入判断两个对象是否相等的判断方法,应该是 TreeSet 的构造函数提供的
此处写的比较方法类似于:
将年龄和姓名拼成一个字符串,然后做比较
Set<User> setByName = new TreeSet<User>((o1, o2) ->
o1.getName().compareTo(o2.getName()));
setByName.addAll(list);
List<User> listByName = new ArrayList<>(setByName);
System.out.println(listByName);
//[User{name='Pepper', age=20, Phone='123'}, User{name='Tony', age=20, Phone='12'}]
Set<User> setByNameAndAge = new TreeSet<User>((o1, o2) -> {
return (o1.getName() + o1.getAge())
.compareTo((o2.getName() + o2.getAge()));
// return o1.getName().compareTo(o2.getName()) == 0
// ? o1.getAge().compareTo(o2.getAge())
// : o1.getName().compareTo(o2.getName());
});
setByNameAndAge.addAll(list);
List<User> listByNameAndAge = new ArrayList<>(setByNameAndAge);
System.out.println(listByNameAndAge);
//[User{name='Pepper', age=20, Phone='123'},
// User{name='Tony', age=20, Phone='12'},
// User{name='Tony', age=22, Phone='1234'}]
-
stream + TreeSet
【
但是我没看懂这种高级的办法】
List<User> streamByNameList = list.stream()
.collect(Collectors
.collectingAndThen(Collectors.toCollection(() ->
new TreeSet<>(Comparator.comparing(User::getName))),
ArrayList::new));
System.out.println(streamByNameList);
//[User{name='Pepper', age=20, Phone='123'}, User{name='Tony', age=20, Phone='12'}]
List<User> streamByNameAndAgeList = list.stream()
.collect(Collectors
.collectingAndThen(Collectors.toCollection(() ->
new TreeSet<>(Comparator.comparing(o -> o.getName() + o.getAge()))), ArrayList::new));
System.out.println(streamByNameAndAgeList);
//[User{name='Pepper', age=20, Phone='123'},
// User{name='Tony', age=20, Phone='12'},
// User{name='Tony', age=22, Phone='1234'}]
排序
在 C++ 中有一个很好用的 sort() 方法,Java 的 List 也提供 sort 方法,使用 Lambda 表达式更方便
List.sort()
- Comparator.comparing()
// 按照用户名自然排序
list.sort(Comparator.comparing(User::getName));
- Lambda 表达式
// ~~我比较习惯的方式~~
list.sort((o1, o2) -> {
int i = o2.getName() - o1.getName(); // 返回o1 < o2
if(i == 0) { // name 相等时
return (o2.getAge() - o1.getAge()); // 返回o1 < o2
}
});
// 比较推荐的方式,将需要比较的字段拼接成字符串,然后作比较
list.sort((o1, o2) -> {
String str1 = o1.getName() + ":" + o1.getAge();
String str2 = o2.getName() + ":" + o2.getAge();
// 为什么不使用 <= 操作符
// 因为Java没有重写比较操作符,compareTo方法就是比较大小的方法
return str1.compareTo(str2);
});
但是需要注意的是,Java中的字符串拼接使用的是+操作符,对于两个数字类型的数据做+操作,会得出结果然后转字符串进行比较,为了避免这种情况,会使用字符将两个字段隔开并做连接
list.stream().sotred()
- list.stream().sotred() + Comparator.comparing().thenComparing()
list.stream().sorted(Comparator
.comparing(User::getName)
.thenComparing(User::getAge)
.thenComparing(User::Score));
- list.stream().sotred( Lambda )
list.stream().sorted((o1, o2) -> {
/* 调用 compareTo() 方法,或者返回一个 int 值 */
});
实现 Comparable 接口,重写 compareTo 方法
需要 Collections 工具类辅助
// User类重写compareTo方法
@Override
public int compareTo(User o) {
int i = o.getScore() - this.getScore();
if(i == 0){
return this.getAge() - o.getAge();
}
return i;
}
// 调用
Collections.sort(list);
Collections 工具类 + Comparator 重写 compare 方法
Collections.sort(users, new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
int i = o2.getScore() - o1.getScore();
if(i == 0){
return o1.getAge() - o2.getAge();
}
return i;
}
});
Set
List 和 Set
- List 是个有序列表,Set 是个集合,保证集合中元素的唯一性(null也是唯一的)
- Set 集合不保证有序或无序,HashSet 无序,LinkedHashSet、TreeSet 等有序
需要注意的是,有序,是指元素的插入次序或者其他次序,而非升序降序
Set 集合,与数学中集合的定义不同的是,Set 集合只保证元素的唯一性,不保证元素的有序或无序
接口
-
Set 是一个接口,HashSet/LinkedHashSet/TreeSet 是接口的实现类,在使用集合时,需要声明其实现类
Example: Set<String> set = new HashSet<>(); -
Set 接口规定了一些方法:
boolean add(E e):向集合中添加一个元素,如果添加失败,则可能表示该元素已经在集合中存在boolean remove(Object o):删除集合中的某个元素void clear():清空集合中的元素boolean contains(Object o):判断集合中是否包含元素 oboolean isEmpty():判断集合是否为空int size():返回集合中元素的个数
不支持随机访问
- Set 的底层不是数组
Set 的底层结构是 Hash/链表Hash/Tree 结构?不支持随机访问 - 要访问 Set 中的元素,需要借助迭代器,或者使用 forEach 增强循环
Queue
-
队列作为一种线性数据结构,有很多种实现方式,即便是使用 ArrayList/数组 或者使用 链表 实现队列,都是很简单的
在 Java 中虽然也提供了队列的实现类,但也不是一定要使用 -
Queue 也实现了 Collection 接口,但是它还规定了一些队列需要实现的方法:
boolean add(E e)/boolean offer(E e):入队/向队尾添加元素,如果队列已满,则抛出异常/返回 falseE remove()/E poll():出队/删除队首的元素,并返回其值,如果队列为空,则抛出异常/返回 nullE element()/E peek():返回队首元素,如果队列为空,则抛出异常/返回 nullint size():返回队列中元素的个数boolean isEmpty():返回队列是否为空void clearn():清空队列中的元素boolean contains(Object o):判断队列中是否包含元素 o -
Java 中常见的队列实现类如:ArrayDeque/PriorityQueue 以及后文会提到的阻塞队列
如 Java 提供的 LinkedList 实现了 Queue 接口,因此也是队列的实现类
PriorityQueue 和后文提到的 PriorityBlockingQueue 不同之处在于:
虽然二者都是具有优先级的队列,但是 PriorityBlockingQueue 基于链表,而 PriorityQueue 基于数组,以数组的形式组成一个二叉树(堆)
Map
HashMap
JDK8
- HashMap应该是按照HashCode的顺序进行存储,因此不支持按插入顺序存放,也具有无序性
- 底层的数据结构为 数组 + 链表 + 红黑树;
在使用链表的阶段,采用尾插法进行插入,解决了多线程死循环的问题,但是还是无法避免出现覆写和 null 值 - 允许存在一条 key 值为 null 的数据,value 值没有限制
JDK7
- 底层的数据结构为 数组 + 链表
底层原理
JDK7
- JDK7 HashMap 的底层是 数组+链表 ,查找效率为 O(n)
JDK7 的 HashMap 的组织方式,大概就像这样
JDK8
- JDK8 HashMap 的底层是 数组+链表+红黑树
- 当链表的长度>8且数组的长度<64时,HashMap只进行扩容,此时的组织方式和 JDK7 的 HashMap 一致
- 当链表的长度>8且数组的长度≥64时,HashMap 的结构转为 数组+红黑树
查找效率为 O(logn)
在此只以 JDK8 为基础
初始大小
- HashMap 在声明和实例化时不声明存储 键值对 数据的空间,当向 HashMap 中插入数据时,Map 的大小初始化为 16
- 16 表示:按照链地址法的方式,可以存储 16 个不同的 hash 索引
索引算法 + 链地址法
-
链地址法:如 JDK7 的组织方式所示,相同 hash 值的数据通过链表存储,并将链表头结点放入数组
数组的下标为 hash 经过运算后的索引值 -
索引算法
I. 一个对象经过 Hash 算法得到一个 hash 值
II. hash 值经过索引算法得到 HashMap 的数组索引值
索引算法为:(hash_value)%(HashMap.length());表示使用 hash 值对 Map 的容量取模需要注意的是,在源代码中,并不采用 % 这样的运算方式,而是
h & (length-1);做取模
随机存取
- 随机存取都基于 HashMap 的索引算法
即需要存一个数,则直接计算其 hashcode,再算索引,再进行插入或覆写;
需要取一个数,则计算其 hashcode,得索引,然后读取数据; - 由于 HashMap 的数组 backet 由索引计算所得,因此可以直接计算得到
哈希方法
- key 为 null 的数据存放在 HashMap 数组的首位
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
- 可以认为所有的求 hashcode 都是使用了这个方法
h = 31 * h + val[i]中对 31 取模的原因是:
I. 31是一个不大不小的质数
II. 31满足等式 h*31 == (h<<5)-h;为什么要满足这个等式,因为虚拟机喜欢做这样的优化
为什么虚拟机喜欢做这样的优化,我不知道,3q
哈希冲突见下文 【哈希冲突】
哈希冲突
链地址法
如 JDK7 的 HashMap 的组织方式,hash 冲突的元素以链表形式存储,头结点放入数组 backet
- 优点
I. 处理冲突的方式简单,平均查找长度较短
II. 因为链表动态申请空间,适合总数经常变化的数据,同时对于删除操作也很友好
III. 相比起来占空间比较小,在数据量非常大时,整个结构中的指针域可忽略不计 - 缺点
I. 查询效率低(在 hash 冲突时,查询的长度可能是链表的长度)
II. 不容易序列化
为什么说链地址法不容易序列化:
序列化即将对象数据写入磁盘,而链地址法中的对象含有指针,不容易序列化
再Hash法
第一个 hash 冲突时,则使用第二个哈希函数,…,直到不发生 hash 冲突为止
- 优点
不易产生聚集
我觉得这样的方式也具有更高的查询效率【大概】 - 缺点
计算 hash 的时间长
公共溢出区
将 hash 冲突的数据,统一放入溢出区
开放定址法
当关键字 key 的哈希地址 hash1 出现冲突时,以 hash1 为基础,产生新的 hash2,…,直到找出一个不冲突的 hash ,将相应元素存入其中
- 线性探测再散列
顺序查看下一个单元,直到下一单元为空,则插入数据,或者一直没有空单元,直到遍历完全表 - 二次平方探测再散列
在表的左右进行跳跃式探测,直到找出一个空单元或查遍全表
即 hash - 1^2,hash + 1^2, hash - 2^2, hash + 2^2, …, hash - k^2, hash + k^2 - 伪随机探测再散列
和上述两种散列方式类似,只是它的探测规则是使用一个伪随机数来进行空单元的探测 - 优点
I. 容易序列化
II. 若预知数据量,则可以创建完美的哈希数列 - 缺点
I. 占空间大,对于总量未知的数据,需要很大的空间来应对 hash 冲突的情况
II. 删除节点不能直接将节点置为空,只能标记该节点已被删除(不能进行物理删除,只能进行逻辑删除)
因为每个节点的位置都有可能是 hash 冲突后散列得到的,当某个节点被物理删除,则根据它散列得到的位置将出现问题
HashMap 和 HashSet
- HashMap 和 HashSet 都使用 key 的 hashcode 作为 hash 值存放
- HashMap 将 value 直接作为 value 值存放
HashSet 将 HashSet 的 final 变量(Object 类型) PRESENT 作为 value 值存放 - HashSet 实现的是 Collection 接口,HashMap 实现的是 Map 接口
HashSet 的底层是 HashMap
- 可以认为,HashSet 的元素唯一性的依据是:底层的 HashMap 的 key 值具有唯一性,而 HashSet 是一个 value 值恒为 PRESENT (Object类型)的HashMap
- 插入数据时 HashSet 会调用 HashMap 的 put 方法
HashMap 与 Set/Collection
- 可以使用 .keySet()/Set() 方法将 HashMap 中的 key 值存储进集合中
- 可以使用 .value() 方法将 HashMap 中的 value 值存储进顺序表(Collection)结构中
ConcurrentHashMap
ConcurrentHashMap 和 HashMap 的不同:ConcurrentHashMap 线程安全;
其他方面ConcurrentHashMap 和 HashMap 一致(就连 JDK7 和 JDK8 在组织方式上的区别也一致);
在实现线程安全的方式上,JDK7 和 JDK8 也有所不同;
【ConcurrentHashMap 的底层原理,在课程资料里面已经介绍得很清楚了】
【 在此只根据我个人的理解进行记录 】
线程安全 JDK1.7
-
HashMap + ReentrantLock + Segment,即分段锁
分段锁的结构和 HashMap 几乎一致,它的底层也是 数组+链表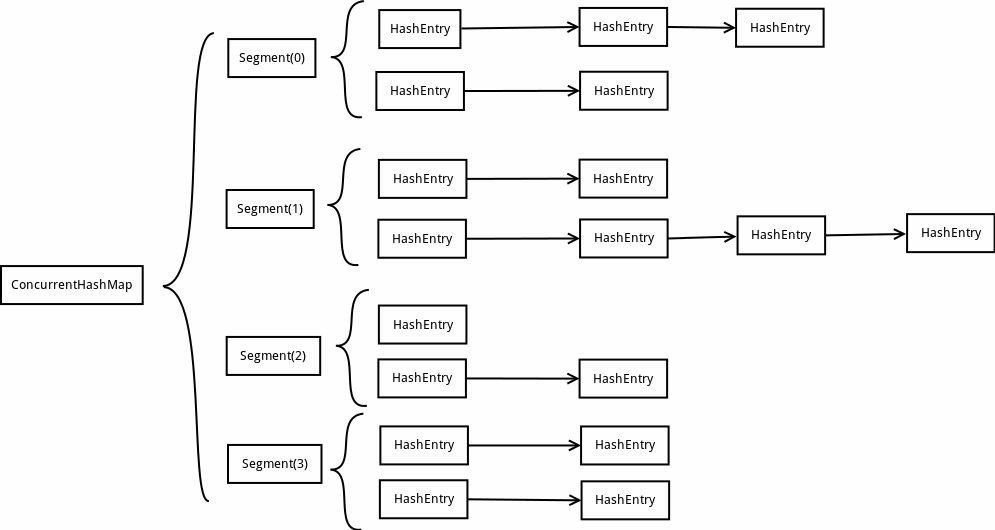
-
首先需要明确的一点是,JDK1.7 的 ConcurrentHashMap 底层只使用了数组和链表,因此对于写操作来说,需要做的只是插入或替换
put操作
-
使用元素的 key 值计算得一个 hash 值,根据这个 hash 值确定它对应的 Segment(分段锁)
-
对 key 进行第二次 Hash,得到一个新的 hash 值,根据这个 hash 确定在 Segment 内部的数组索引位置 HashEntry
-
获取分段锁,如果获取成功,则直接将数据插入到 ConcurrentHashMap 中,或者修改 ConcurrentHashMap 中数据的 value 值
向 Map 中插入一个已存在的 key 值,则产生覆写
-
如果获取分段锁失败,则当前线程采用自旋的方式获取锁,当自旋的次数超过某特定值只会,线程挂起
-
释放锁
get操作
- get 操作不涉及数据的修改,因此不需要加锁,但是和 HashMap 不同的是,ConcurrentHashMap 需要进行两次 Hash,一次获取 Segment,一次获取 HashEntry
- 存储在 ConcurrentHashMap 中的数据都使用了 volatile 关键字,使得该数据对所有线程可见
size操作
- 获取当前 ConcurrentHashMap 中元素的个数
- 进行两次 size 操作(遍历所有的 Segment)
- 如果两次 size 得到的结果相同,则直接返回 size 得到的结果
- 如果两次 size 得到的结果不同,表示在两次 size 期间发生了数据增删操作,则 ConcurrentHashMap 将对所有 Segment 加锁,然后进行遍历
(因此得到的结果非常准确)
因此,JDK1.7 中 ConcurrentHashMap 的操作粒度为 Segement
线程安全 JDK1.8
-
HashMap + synchronized + CAS
【
具体的底层原理我按照我的理解进行叙述,可能有些许错误 awa】
put操作
-
由于舍弃了 Segment 的组织方式,在 JDK1.8 中,对于需要插入的元素,将根据它的 key 计算得一个 hash 值,这个 hash 值对应到一个 bucket
bucket 即 HashMap 中的数组项
-
对 bucket 加锁
-
进行数据的插入或者更新操作
需要注意的是,如果是在红黑树中插入数据,可能需要进行树旋转 -
释放锁
get操作
- 同 JDK1.7,存储在 ConcurrentHashMap 中的数据都使用了 volatile 关键字,使得该数据对所有线程可见
因此,在 JDK1.8 中的 ConcurrentHashMap 中,操作粒度为 bucket
线程安全
实现线程安全的办法
-
和 List 接口一致,实现线程安全有三种办法:使用线程安全的实现类;使用 synchronizedMap;借用 JUC 的方法;
-
HashTable 是线程安全的,因为它对每个读写方法都使用了 synchronized 关键字
-
Collections.synchronizedMap 的实现思想和 HashTable 几乎一致,使用 Collections.synchronizedMap 包裹 HashMap,效果等同于为 HashMap 的读写方法加锁
其特性可能和 List 一致,它只为数据体加锁,因此在使用迭代器进行数据访问时,还需要单独加锁
List 的线程安全中没有特殊说明使用 Collections.synchronizedList加锁的原理,但是大概和 synchronizedMap 一致:
使用互斥量 mutex 进行互斥访问,mutex 是 Java 提供的一个互斥对象(大概) -
使用 JUC 的 ConcurrentHashMap,相关说明见上文 【ConcurrentHashMap】
List 使用 JUC 是通过 CopyOnWriteArrayList 生成类似快照的数据体,然后进行读写
HashMap线程不安全的说明 - 死循环(JDK7 会出现死循环)
- 在 HashMap 进行扩容时,将使用以下代码(简化)(HashMap 的链式结构不带头结点)
while(null != e) { // 遍历链表,并将每次遍历到的头结点插入新数组
Entry<K,V> next = e.next; // 记录将被转移的头结点的下一个结点
e.next = newTable[i]; // 转移头结点(头结点指向原头结点)
newTable[i] = e; // 转移头结点(原链表的头指针指向新头结点)
e = next; // 遍历下一个头结点
}
- 线程1扩容:先记录头结点的下一个结点,时间片用完,挂起
- 线程2扩容:扩容成功,原链表在新数组中倒置(因为使用的头插法)
- 线程1:此时线程1的栈空间会呈现:原来的 next 被倒置后指向了原来的 e
- 线程1:e 转移到新数组的头结点的位置
- 形成单链表循环(死循环)
HashMap线程不安全的说明 - 数据覆盖
- 执行 put 操作时,HashMap 先根据 hashcode 检测当前 bucket 中是否为空,如果为空,则直接插入,否则使用散列算法进行散列
- 线程1插入数据:检测到 bucket 为空,时间片被用完,挂起
- 线程2插入数据:检测到 bucket 为空,插入数据
- 线程1:继续执行插入操作,直接向 bucket 写入数据
- 线程2的数据被覆盖
- 数据被覆盖可能导致 HashMap 的 size 只执行了一次 ++ 操作,导致 size 错误
HashMap线程不安全的说明 - 读出为 null
- 在扩容时,线程1还没将数据转移到新表,就被挂起,然后线程2进行数据读取,会读取新表的内容
- 读出为 null
ConcurrentSkipListMap
引言
- ConcurrentSkipListMap 是 JDK1.6 新增的,适用于高并发场景的 Map,能够在大部分情况下保证线程安全
因为 ConcurrentSkipListMap 的操作其实不是原子操作,所以说基本情况下是线程安全的 - 基于跳表结构 ==> 增删改查的时间复杂度都为 O(logn) ==> key 有序
- key 和 value 都不能为 null
不然就不能完成排序了
跳表
- 跳表中的元素是以指针的形式相互联系的,可以将整个跳表理解为若干个层级的索引结构,从高层级向低层级,元素依次增多(像金字塔一样),且每一层的元素都保持有序(一般是升序排列)
- 最底层的索引是所有元素组成的链表,且有序
- 从最底层元素中挑取若干元素,按照次序以链表的形式相互组织,同时,该元素也以一个指针指向下层的等值元素,因为这些元素从底层挑取且依次排列,因此有序,也可作为数据访问时的索引
- 向上层索引元素同理…
- 图取自 CSDN - 跳表(Skip List) - hakusai22
以访问一个元素为例,如果需要访问值为 8 的元素,则
I. 从跳表的顶层开始,向链表尾遍历,直到遍历到的值 ≥ 8(遍历到了表尾 13)
II. 向前遍历一个元素(遍历到 1)
III. 以此时的元素为基准,在下一级索引中向表尾遍历链表,直到遍历到的值 ≥ 8(遍历到了表尾 13)
IV. 向前遍历一个元素(遍历到 7)
V. 以此时的元素为基准,在下一级索引中向表尾遍历链表,直到遍历到的值 ≥ 8(遍历到了 8)
- 因此,删除/修改跳表中的元素时,需要同时修改其索引
TreeMap
- 默认按照 key 的升序进行存放,因此不支持按照插入顺序存放
同时提供排序方法的重写,即重写 Comparator 的 compare 方法,完成自定义排序
TreeMap 是有序的 - 底层为 红黑树
- 不允许存在 key 值为 null 的数据,不然就没法排序了
- 不是线程安全的类
LinkedHashMap
- LinkedHashMap按照插入顺序进行数据存储
因此它是有序的,并且不支持排序 - LinkedHashMap底层是 双向链表 + HashMap;【LinkedHashMap 是 HashMap 的子类】
也因此比较好理解为什么按照插入顺序存放 - 和 HashMap 一样,LinkedHashMap 只允许一条 key 值为 null 的数据,value 值无限制
扩容
HashMap、HashSet、HashTable
| 类 | 初始容量 | 最大容量 | 扩容时倍数 | 加载因子 |
|---|---|---|---|---|
| HashMap | 16 | 2^30 | n*2 | 0.75 |
| HashSet | 16 | 2^30 | n*2 | 0.75 |
| HashTable | 11 | Integer.MAX_VALUE-8 | n*2+1 | 0.75 |
加载因子
- 加载因子一般是一个处在 (0,1) 之间的数,表示 Hash 结构的填充程度,同时加载因子也作为结构扩容的判断条件
如一个容量为16的 Hash 结构,它填充了12个元素,填充程度达到加载因子 0.75 ,因此在下一次插入数据时进行扩容 - 为什么需要加载因子
加载因子是用来应对 hash 冲突的,当出现 hash 冲突时,可能意味着需要更多空间来存储数据,因此一直需要一些空间来处理冲突 - 为什么是 0.75
大概是 0.75 的加载因子可以正好做到即不浪费过多的空间,又足够处理 hash 冲突
此处的加载因子说法来源于 自学精灵
扩容机制
HashMap 和 HashSet 的容量为 2^n
- 一般为了减少冲突,Hash 结构的容量会设置为质数,或者尽量设计为奇数
(因为索引的计算方式为hashcode % Map.length()) - HashMap 和 HashSet 的容量设计为 2^n,是为了在取模和扩容时做优化
?
初始化
Hash 结构在声明和实例化时并不会扩容,也不具备初始容量的空间
当使用 put 插入元素时才会进行扩容,第一次插入元素时,结构将扩容为初始容量
初始化和后续扩容的方式为调用 resize() 函数
resize()
- 判断旧数组的容量是否达到 2^30
I. 若旧数组的大小已达到 2^30,则进行最后一次扩容,扩到 2^31-1 的大小,之后就不进行扩容了
II. 若旧数组的大小未达到 2^30,则容量扩充为原来的2倍 - 创建一个容量更大的新数组
- 将旧数组中的内容转移到新数组(使用新数组的容量重新进行索引计算)
迭代器
为什么使用迭代器
- 为了屏蔽数据结构内部的特征,比如在需要访问 HashMap 中元素的时候,使用迭代器就不需要考虑此时的 HashMap 是链式结构还是红黑树,只需要使用迭代器的 next() 方法即可
- 另外,迭代器针对整个集合类型起效,使得确定了数据类型的迭代器 可以访问几乎任意 存储了该数据结构的集合容器(代码来自 博客园 - Java基础 – 深入理解迭代器 - 大奥特曼打小怪兽)
public static void display(Iterator<Person> it) {
while(it.hasNext()) {
// 存储了Person的集合容器都可以被it迭代器访问
}
}
我个人理解的话,还有一个原因:Java 没有指针,在一些需要指针的场景,可以使用迭代器;另外迭代器提供了很多优雅方便的封装接口函数,在使用过程中更方便也更安全
IO流 与 异常
IO流
字节流
字符流
缓冲流
JavaIO 流相关的底层内容太复杂了,之后看懂了再来补充,暂且浅浅写一下三种 IO 流的区别
- 字节流以一个字节为单位,即 1byte == 8bit;
字符流以一个字符为单位,因为 Java 采用 Unicode 编码,一个中文占 2 个字节,因此,Java 的字符流单位为 2byte == 16bit - 字符流具有缓冲区,但是相比缓冲流来说,字符流的缓冲功能相对较弱
- 字节流可以读写任何格式的数据,但是字符流更加适用于文本文件
BIO | NIO | AIO
关于 BIO、NIO、AIO 的具体底层和实现,等我学会了再进行补充,在此浅浅列出它们的区别
-
Java 的所有版本都支持 BIO;Java 1.4 才开始支持 NIO;Java 1.7 才开始支持 AIO
-
BIO 理解为同步阻塞,即一个请求(连接)对应一个线程,在 IO 资源未就绪时,该请求(线程)将进入阻塞态,直到 IO 就绪,然后执行
这使得
I. 一个请求如果没有得到相应的 IO 资源,将被阻塞
II. 当请求数量庞大的时候,将造成大量的阻塞态的线程,会崩溃 -
NIO 理解为同步非阻塞
它引入两个新的定义:Selector 选择器 + Channel 通道
I. 通道会关注相应的事件(读写操作等)
II. 选择器是一个多路复用器,每个请求都会注册到多路复用器上面,然后选择器根据通道的事件状态为请求创建线程如:对于读写操作,当 IO 准备就绪后,才会为 IO 处理请求创建线程
-
AIO相对来讲用的不是很广泛,它支持异步非阻塞
可以理解为,用户进程发起 IO 请求,然后就 return ,处理自己的程序
当 IO 就绪并处理完成之后,则由封装程序通知用户进程
序列化与反序列化
引言
- 浅显地理解来说,序列化就是将 Java 的对象信息转化为字节流,以方便传输或存储,反序列化就是将字节流读取为对象信息
- 实现了 Serializable 接口的类具备序列化和反序列化的基础,在此基础上,需要输入/输出流以承接字节流的输入/输出,有了输入/输出流之后,使用写入函数 writeObject / 读取函数 readObject 进行序列化/反序列化,操作完成之后,需要关闭输入/输出流
- 实际上,Serializeable 是一个标记接口,接口中并未定义函数,只是标记了类是否支持序列化
- 使用了 transient 关键字的成员不能被序列化,同样,静态成员也不能被序列化
序列化/反序列化时如何保证对象之间的关系
- 序列化时,对象及其作为成员的对象,会递归地写入到字节流中
如:Person 类对象的成员 Address 对象,会在序列化时,被递归地转为字节流 - 反序列化时,根据比对类唯一的序列化编号,可以确定反序列化对象所对应的类是否对应,因此,如果类结构发生变化,则可能导致反序列化失败
对于对象中的成员对象,如果该成员对象其实是同一个对象的引用,则在反序列化时只进行一次反序列化
如:对象 obj1 和 obj2 都拥有共同的成员对象 obj_common ,如果 obj_common 指向的是同一个对象,则在反序列化时,obj_common 只会被反序列化一次
异常
Java 异常统一实现 Throwable 接口
它的两个直接子类即 Error 和 Exception
基本定义
Error
-
Error 出现时,则 JVM 内部出现了问题,比如资源不足等,无法由程序员进行处理
对 Error 的理解更倾向于它的英文本意,即 错误
Exception
-
Exception 出现时,一般可以通过外部处理进行恢复
对 Exception 的理解也如它的英文本意,即 异常
-
有两种类型的 Exception :
I. RuntimeException - 非受检异常
II. 其他 Exception - 受检异常
使用建议:将checked exceptions用于可恢复的情况
将unchecked exception用于编程的错误将受检异常和非受检异常的区别理解为:是否需要强制加上
try ··· catch或Throws受检异常,即会在编译期被检查的异常
非受检异常,即在编译期不会被检查的,在运行期才会体现的异常
处理异常的方法
try ··· catch ··· finally
- 在有异常的一般情况下,执行顺序 try=> catch=> finally=> finally块之外
- 如果 catch 中有 return,则在捕获异常执行 catch 和 finally 之后,再执行 catch 中的 return,try 中的 return 不执行
- 如果 catch 和 finally 中都有 return,则执行 finally 的 return
public class Demo {
public static void main(String[] args) {
Object handler = handler();
System.out.println(handler.toString());
}
public static Object handler() {
try {
System.out.println("try:内(前)");
// 在此处会出现异常,因此此处语句以及之后语句不执行
System.out.println("try:内(异常)" + 5 / 0);
System.out.println("try:内(后)");
return "try:返回";
} catch (Exception e) {
System.out.println("catch:内(前)");
} finally {
System.out.println("finally:内");
}
System.out.println("最后");
return "最后(返回)";
}
}
try:内(前)
catch:内(前)
finally:内
最后
最后(返回)
- 在无异常的情况下,将不执行 catch 之内的语句,但是会执行 finally 代码块中的内容
顺序为 try ==> finally ==> try 代码块中的 return
但如果 finally 中含有 return ,
则 执行finally 中的return,try中的return 不执行
总结
- 一旦出现异常,异常之后的代码就不执行( return 语句包含在内),在catch 中发生的异常也是
- 异常处理的次序在 return 语句的前面一点点(return 是最后执行的)
- 异常处理中的 return 执行的优先级为 : finally > catch > try ; 而且 return 语句只执行一次
系统问题
线上系统问题
死锁
数据库死锁
数据库索引失效
死锁
JVM
内存
内存模型 JMM
引言
- JMM 即 Java Memory Model,规定了 JVM 的内存结构,但此结构并不是真实存在的,只是一个抽象的划分
- JMM 定义了程序中变量的访问方式,从而屏蔽操作系统和硬件环境的差异,使得 java 程序在各种环境下都能达到一致
主内存空间与线程空间
- 主内存空间是所有线程都可以访问的空间,比如堆和方法区
- 线程空间也称作工作空间或栈,存储线程的私有数据,线程之间相互独立,即工作空间互不影响
- 在 JMM 模型中,线程将先从主内存空间访问并拷贝需要的数据,然后在工作空间中对拷贝下来的数据进行操作,操作完成之后,再将数据回写到主内存空间
JMM 模型提供的定义
-
原子性
原子性保证一组操作不可分割和中断不可分割理解为:这组操作要么都执行,要么都不执行
不可中断理解为:这组操作中涉及到的数据,在操作开始后就不允许被其他线程修改,直到这组操作结束int i = 2;基本类型的赋值操作为原子操作int i = j;先读取 j 的值,然后将 j 赋值给 i,不是原子操作 -
可见性
由上文可知,一个线程对某数据进行操作,其实是修改的主内存空间中该数据的拷贝,当操作完成后,将该数据回写到主内存空间后,其他线程才可以读取到最新数据可见性使得一个线程在操作完一个数据后,其他线程立马就知道该数据被修改了
Java 的可见性通过 volatile 实现,被 volatile 修饰的变量,在修改之后,会立马同步到主内存空间
synchronized 是另一种实现可见性的方式,被 synchronized 修饰的数据,在操作之前进行加锁,在数据回写到主内存之后,才进行解锁,这保证所有线程在拿取到数据时,该数据都是最新的(否则就无法获取)
final 保证数据的可见性是因为 final 属性的对象在初始化后就不允许被修改
-
有序性
有序性针对指令重排;指令重排是指编译期为了性能而改变代码执行的顺序,这种改变并不影响代码最后的运行结果而 JMM 定义的有序性使得编译器按照代码的顺序执行代码
volatile 和 synchronized 都可以禁止指令重排,它们的执行方式都是在关键字修饰的语句前后加上内存屏障,内存屏障使得屏障内部的语句不可进行顺序交换,也不可和屏障外的语句进行交换
内存交互
线程工作空间和主内存空间的交互见【主内存空间与线程空间】
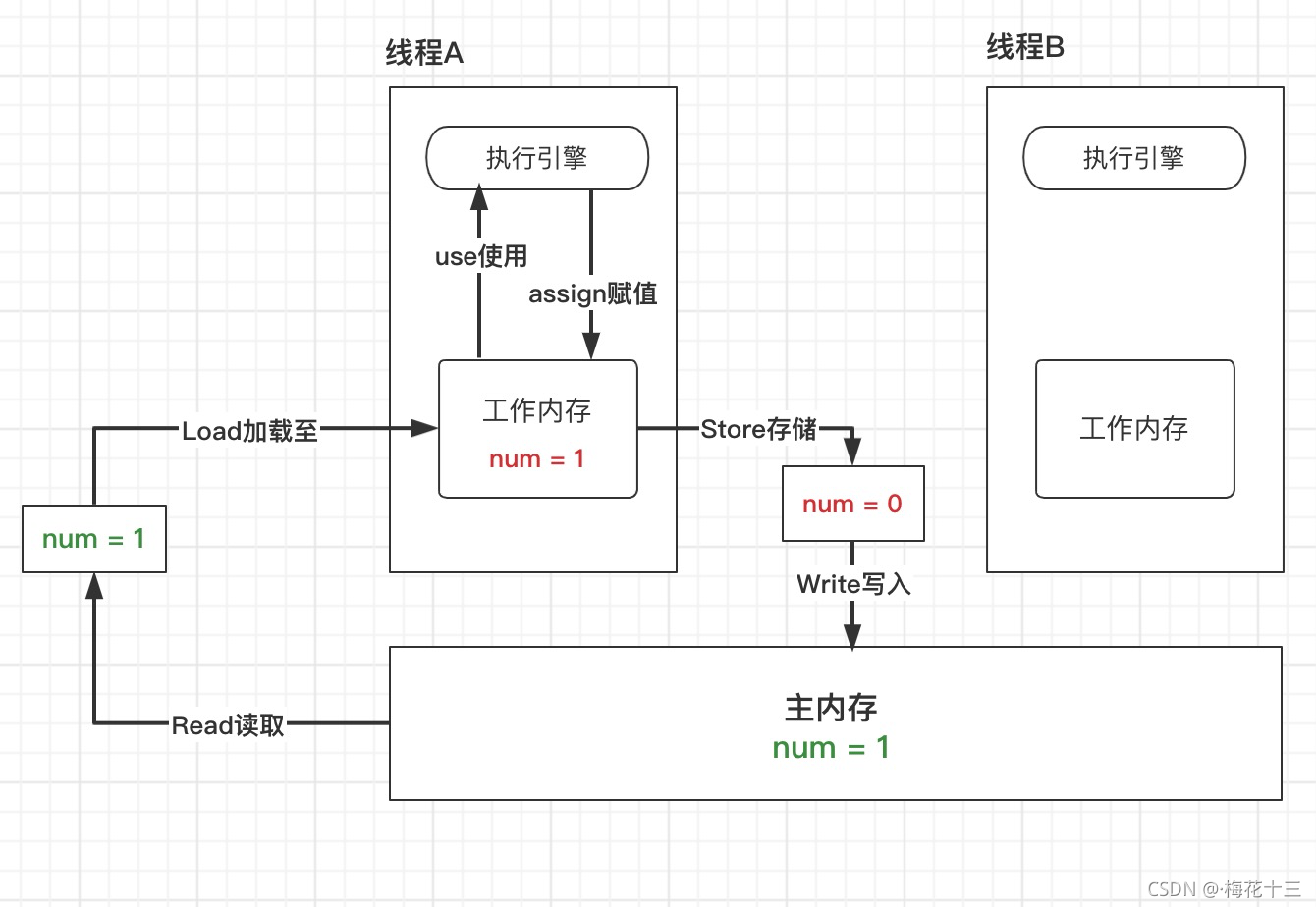
线程从主内存中获取数据
- Lock:锁定,当线程获取数据时,就将该数据锁定,并将数据状态标识为由当前线程独占【
使用 volatile 修饰的变量可能不会进行锁定操作】
执行 Lock 操作时,当前线程中该变量的值将被清空 - Read:读取,获取主内存中的数据,并将该数据传输到工作空间
- Load:将 Read 操作传入的数据拷贝到工作内存的变量副本
线程对数据进行操作
- Use:使用,在不改变数据值的情况下进行的访问等操作
- Assign:赋值,即对数据进行修改
在工作空间之上还有一个结构——执行引擎
数据传输到执行引擎,即数据的 Use;从执行引擎中接收到值,并赋值给变量,即 Assign;
线程将数据回写到主内存
- Store:存储,数据经过一系列操作后,传入一个值到主内存空间
- Write:写入,主内存空间中的数据接收到 Store 传入的值,并将该值赋值给变量
- Unlock:以上操作完成,释放锁
内存交互规则
- Read 和 Load 操作、Store 和 Write 操作、Lock 和 Unlock 操作成对出现
- 当线程对变量进行赋值 Assign 后,必须通知主内存【即 Assign 操作之后一定有 Store 和 Write(大概)】
- 没有进行过赋值 Assign 的变量,不允许向主内存中回写
- 变量一定诞生在主内存中,工作内存不允许直接对未初始化的变量进行 Use 和 Store 操作【也因此线程不能直接对未初始化的变量进行 Load 和 Assign 操作】
- 执行 Unlock 操作之前,一定先执行 Store 和 Write 操作
指令重排
引言
- 指令重排的核心是:JMM 向程序员保证,指令重排后的执行结果与顺序执行的结果一致;JMM 对编译器和处理器进行要求,保证指令重排后的执行结果与顺序执行的结果一致
- 以下的 as-if-serial 和 happens-before 规则都是对于指令重排的规定,即只要满足 as-if-serial 和 happens-before 规则 的要求,编译器可以进行指令重排
as-if-serial
- as-if-serial 是 JVM 对程序员的承诺,即:在单线程场景中,JVM 可以根据性能优化的需要,改变代码运行的次序,并保证在单线程场景中,重排后的执行结果与原顺序执行结果一致
- 具体描述为:编译器和处理器不会对存在数据依赖关系的操作进行重排序
如:int a = 10; int b = 11; int c = a + b;中 a 和 b 操作没有依赖关系,因此 a 与 b 的定义语句可能会被重排,但是 c 依赖于 a 和 b,因此 c 一定排在 a 和 b 的后面
happens-before
引言
-
与 as-if-serial 类似,happens-before 也是 Java 编译期对程序员做出的承诺,即在多线程场景中,编译器保证数据在线程之间的可见性;
这里的可见性是指,如果一个线程 A 的操作需要在线程 B 之前,那么 A 线程对 B 线程可见,需要保证线程 B 获得的数据是 A 线程处理过的,即线程 A 执行后才能执行线程 B
-
如果重排序后的执行结果与按照顺序执行的结果一致,则编译器可以对代码进行重排
规则
-
程序顺序规则:即按照程序代码的先后顺序执行
这里的先后顺序是指:在执行结果层面,得到的结果与 按照代码先后顺序 运行得出的结果一致;在实际执行顺序层面,可以允许指令重排
-
监视器锁规则:即对于一个锁,如果它正处于锁定状态,则需要等它解锁之后,才能再次对其进行加锁
-
volatile 变量规则:与 volatile 的作用一致,即如果一个线程对该变量进行了修改,那么其他线程读取到的变量应该是修改后的值
保证 volatile 变量的可见性
-
传递规则:如果 A 发生在 B 之前,B 发生在 C 之前,那么 A 发生在 C 之前
-
线程启动规则:如果线程 A 先启动,然后由 A 启动线程 B,那么线程 A 对变量的修改,在 B 中可见【也称 start 规则】
-
线程中断规则:
这个规则我看不明白,就按照我粗浅的理解记录一下
在 Java 中,如果线程调用了 interrupt 函数,则 interrupt 函数在中断发生之前就会执行,并且,interrupt 函数中产生的修改,将对中断发生后的程序可见在 Java 中,interrupt 函数算是一个检测函数,目的是检测是否有中断发生
-
线程终结规则:如果线程 A 在执行过程中,通过制定 ThreadB.join() 等待线程 B 终止,那么在 B 运行时所作的修改,在 B 终止后,该修改都将对 A 可见【也称 join 规则】
-
对象终结规则:对象的初始化方法发生在对象的 finalized 方法之前
数据区
数据区信息总览
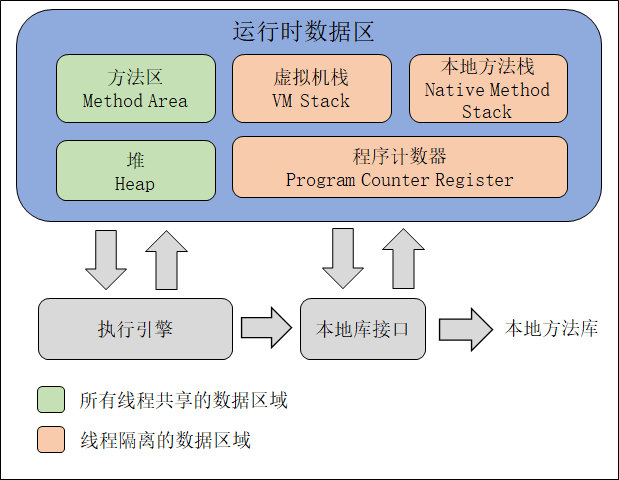
-
堆:存放对象实例、String 常量池、基本数据类型常量池、静态变量
-
方法区(元空间):存放类信息、类常量池、运行时常量池
运行时常量池包括:符号引用和字面量字面量理解为在代码中直接定义出现的数据,如
int num = 1;中的 1;如String str = "muhuai"中的 muhuai;需要注意的是,Java 规定 char 类型的字面量使用 ‘’ 包裹,String 类型的字面量使用 “” 包裹;
-
虚拟栈区:存放临时变量(局部变量)
方法区:永久代和元空间
-
永久代和元空间都是方法区的实现方式,JDK8 之前使用永久代实现方法区,JDK8 之后使用元空间
-
从 JDK6(大概)开始,永久代就逐渐被移除,直到 JDK8 才彻底移除,因此我们简单理解为 JDK8 之前都使用永久代实现方法区
-
永久代的方法区内存占用的是 JVM 的空间,并且 JVM 会设定永久代的内存上限,它的垃圾回收机制为 Full GC,即扫描整个堆,回收没有被 JVM 回收的对象
因此 JDK8 之前很容易出现内存泄漏,进而导致内存不足java.lang.OutOfMemoryError: PermGen -
元空间的方法区占用的是系统的空间,有自己的垃圾回收算法,因此以元空间实现的方法区只受到系统的限制
元空间溢出将报错:java.lang.OutOfMemoryError: MetaSpace -
在 JDK8 之前,String 和 基本数据类型的常量池也放在方法区,导致永久代更容易出现内存不足
但其实在 JDK7,String 和基本数据类型的常量池就放进堆中了
设置永久代的空间参数
# 设置永久代分配的初始空间大小,默认是20.75M
-xx:Permsize
# 设置永久代的最大空间,32位机器默认64M,64位机器默认82M
-XX:MaxPermsize
设置元空间的空间参数
# 设置元空间分配的初始空间大小,默认根据运行时程序的需求动态调整
-xx:MetaspaceSize
# 设置元空间的最大空间,默认只受系统空间的限制
-XX:MaxMetaspaceSize
堆外内存
堆外空间分为 元空间 + 直接内存 + 其他堆外内存 ,此处我们不讨论元空间
直接内存
- 直接内存一般指能通过 DirectByteBuffer 申请的内存,这块内存也是机器物理内存
- 可以通过【
-XX:MaxDirectMemorySize】来设置堆外内存的最大值(默认为64M) - 这块空间不足时,也会抛出 OOM
DirectByteBuffer
-
申请堆外内存:
ByteBuffer.allocateDirect(size) -
释放堆外内存:在 DirectByteBuffer 对象进行初始化时,会同时创建一个 Cleaner 对象,当某时(一般是 FGC 时),Cleaner 将执行 unsafe.freeMemory(address) 方法,从而回收堆外内存;
如果 DirectByteBuffer 对象在 YGC 中被回收了,则 Cleaner 对象将在 FGC 时执行Cleaner.clean()回收堆外内存但是这个方法内部还是调用了 System.gc() ,因此不能开启 -XX:+DisableExplicitGC
同时这也意味着,如果不发生 FGC ,则一直无法回收堆外内存
-
当然直接使用 System.gc() 进行 FGC 时也会进行堆外内存的回收
其他堆外内存
- 其他堆外内存是通过 Unsafe 或其他 JNI 手段申请的堆外内存,没有相关参数约束这块空间的大小,虚拟机也无法自动对其进行 GC
- sun.misc.Unsafe 提供了一组方法来进行堆外内存的分配,重新分配,以及释放
// 分配一块内存空间
public native long allocateMemory(long size);
// 重新分配一块内存,把数据从address指向的缓存中拷贝到新的内存块
public native long reallocateMemory(long address, long size);
public native void freeMemory(long address); // 释放内存
- 但是直接使用 unsafe 会报错,因为 Unsafe 不让直接使用,因此如果要用 Unsafe,需要借助反射
为什么使用堆外内存
- 使用堆外内存能够带来更高的读写效率
I. 当需要将数据写入磁盘时,需要先将数据复制到堆外内存,然后再从堆外内存复制到磁盘
II. 当需要把磁盘的数据加载到堆中,也需要经过堆外内存(大概) - 因为堆外内存不参与 JVM 的 GC 过程,因此从某种程度上,使用堆外内存可以减少 STW 的时间
缺点
- 堆外内存泄漏难以发现
- 不过也有办法查看是否发生了堆外内存泄漏【此部分我也不是很清楚,以后再进行补充】
内存泄漏
ThreadLocal
-
ThreadLocal 是一种线程封闭的对象,线程将拥有独立的实例空间,以此保证线程之间的独立性
-
ThreadLocal 保证独立性的组织方式是维护一个 ThreadLocalMap,这个 Map像一个键值对数组,ThreadLocal 的一个弱引用作为 key,value 是 ThreadLocal 所保存对象的引用
-
由于 key 所保存的引用是弱引用(不管内存是否足够,在弱引用不被使用时,GC 就会回收它),当作为 key 的引用被回收之后,按理说 value 应该也被回收,但是 value 如果是强引用,就始终无法被回收
为什么 ThreadLocal 的 key 是弱引用
因为如果是强引用,则在 ThreadLocal 线程结束时,由于 key 还保留着 ThreadLocal 的强引用,所以无法被回收一个键值对我们称为 Entry
-
作为强引用的 value 其实是这样的一条强引用链:Thread Ref ==> Thread ==> ThreaLocalMap ==> Entry ==> value
remove() 和 set(null)
-
在线程结束时,应该关闭线程,并释放该线程所持有的资源,常见的方式如下:
-
使用 remove() 将直接删除 Entry(它将清除线程中所有 key == null 的 Entry)
-
使用 set() 只是将 Entry 的 value 值置为空,因此可能导致原本的 value 不能被回收
正常情况下,当 value 置为空时,原来的 value 如果没有被其他的对象引用,则会在一段时间后由系统进行垃圾回收
另一种 value 无法回收的情况是 key 的 this 指针无法删除,从而导致该指针对应的 value 实例无法被回收
还有一种是,ThreadLocal 对象对实例的引用是软引用,在 ThreadLocal 对象被 GC 之后,value 对应的实例没有被回收
线程池
- 在上述情况中,当线程结束时,ThreadLocal 会被回收,但是在线程池中很少去删除一个线程,则在这种情况下使用 set(null) 终止线程,很容易出现内存泄漏
- 建议使用 remove() 终止线程(或者释放线程)
未关闭的资源
- 使用了BroadcastReceiver,ContentObserver,File,Cursor,Stream,Bitmap等资源之后,如果没有关闭资源,则可能导致内存泄漏
- 通常在使用了相关资源后,需要使用它的 close() 方法先关闭资源,然后设为 null
改变 hash 值
-
被存储进 Hash 结构的对象,它字段中参与计算 hashcode 的字段尽量不要被修改
因为对 Hash 结构中的元素进行定位时,会先计算 hashcode,如果参与计算 hashcode 的字段被修改,则可能导致无法查找到相应的对象,从而导致内存泄漏
因此,HashMap 中的 key 值一般不允许被修改
内部类
内部类导致内存泄漏的说明
- 如果要使用非静态的内部类,或者匿名内部类,则要先声明它的外部类实例
- 当静态内部类或内名内部类还在被使用时,外部类的内存无法被释放,因此容易发生内存泄漏
- 尽量使用静态内部类
如何避免内部类导致内存泄漏
一言以蔽之,使用静态内部类
finalize()
- finalize() 是资源回收时的函数(多用于析构函数),一般不要轻易修改(重写) finalize() 函数
- 如果在 finalize() 函数中出现异常,则可能导致资源无法回收
其他
-
static,被 static 修饰的资源几乎将存在于整个程序的生命周期,如果静态资源过多,就会导致内存泄漏或内存不足(OOM)【显然】
-
集合容器
不用担心作为局部变量的容器会导致内存泄漏,当程序运行到超出局部变量的作用域,则在某时刻系统会将该资源回收
对于静态容器或者全局容器,则有可能导致内存泄漏【显然】 -
常量字符串
字符串有一个字符串常量池,如果常量池中的字符串过于庞大,在 JDK7 之前,常量池在方法区,则容易导致内存泄漏使用 intern 将字符串导入常量池,该字符串就会保留在常量池
类加载
【写在前面:此节涉及的行为都针对类,而不针对对象】
加载=>链接=>初始化=>使用=>卸载
加载=> 链接(验证+准备+解析)=> 初始化=> 使用=> 卸载
加载 - 将硬盘中的二进制文件(.class 文件)转化为内存中的 Class 对象
-
通过类的全限定名获取该类的二进制文件,内部类也有单独的 .class 文件
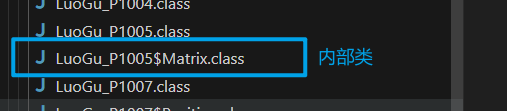
-
将字节流代表的静态存储结构转化为方法区的运行时数据结构
可以理解为,在此时,类信息被加载到方法区
-
在内存中生成一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口
方法区存在一个 java.lang.Class,它不是程序员创建的类,它的作用体现在类数据的访问
理解为,类信息放在方法区,如果需要访问类,就通过这个 Class 访问它也是获取反射类的基础
链接 - 给静态变量赋初始值,符号引用替换成直接引用
链接包括:
-
验证:检查 .class 文件的正确性
-
准备:给静态变量赋初值(这次过程中,也为静态变量分配了内存)
静态变量会直接赋初值为 0 或 null 或 false;static final 的 String 类型会直接赋初值为最终值;基本数据类型直接赋初值为最终值;此处的最终值是定义变量时的值
-
解析:(可选)将常量池内的符号引用替换为直接引用
符号引用理解为像函数名一样的引用,它表示在该程序段时需要执行代码的名字为 xxx,而由于 Java 的懒加载性质,需要到该代码被执行的时候,才知道相关代码和数据在内存的哪个位置;
直接引用则是直接取到某对象或者其他数据,能够确切地知道数据的地址(或者说,取到的就是数据的地址)
如:Object obj = new Object();
如:Object obj = Method.getObj();
初始化 - 初始化类的变量 + 执行静态语句块
-
此时按照 静态数据 > 父类的静态数据 > 父类 > 子类 > 子类的构造方法 的顺序初始化
更确切的表述是:
静态方法 > 静态块 > 父类的静态方法(静态块) > 子类的普通方法 > 子类的普通块 > 构造方法
【构造方法是最后的】 -
在准备的基础上,为静态变量进行显示赋值,执行静态代码块
我理解为,在准备阶段对静态变量分配内存并且赋初值,这个初值是默认的 0 或 false 或 null,只有 staatic final 的 String 类型和基本数据类型会直接赋初值为字面量
然后在初始化阶段,其他类型的静态变量才真正初始化为定义时指定的值
使用 - 以 new 一个对象为例
- 在执行 new 操作时,先看该对象的类是否进行了初始化,如果没有,则按照上述顺序,执行类的初始化
- 然后在堆上面创建该对象,分配空间,并且给所有数据设为默认值
- 按照类定义为对象赋初值
- 按照 父类的构造函数 > 子类的构造函数 的顺序调用构造函数
对类进行初始化的场景
类初始化只发生一次,即如果类已经被初始化过,就不会再初始化一次了
因此以下所述情况,都是类还未初始化,然后进行类初始化
- new 一个对象的时候
- getstatic 访问一个类的静态字段
- putstatic 设置一个类的静态字段
- invokestatic 访问一个类的静态方法
- 使用 java.lang.reflect 包对类进行反射调用
在前文有阐述反射的流程,通过反射获取到类信息后,调用类方法,因此在获取类时,如果类没有初始化,就先初始化类 - 初始化类的时候,如果它的父类没有没初始化,则也一起初始化它的父类
- 程序启动时,xxxApplication 启动类的初始化
- 当使用 JDK 1.7 的动态语言支持时,如果一个 java.lang.invoke.MethodHandle 实例最后的解析结果 REF_getStatic、REF_putStatic、REF_invokeStatic 的方法句柄,并且这个方法句柄对应的类没有进行过初始化,则需要先触发其初始化【听不懂这句 awa】
静态域
访问类或接口的静态域时,只有真正声明这个域的类或接口才会被初始化
class B {
static int value = 100;
static {
System.out.println("Class B is initialized."); //输出
}
}
class A extends B {
static {
System.out.println("Class A"); //不会输出
}
}
public class Demo {
public static void main(String[] args) {
System.out.println(A.value); //输出100
}
}
在以上代码中,访问的是 A 的父类的静态字段,因此在初始化时,只会初始化 A 的父类
【但是此时通过 A 进行访问的,为什么 A 不初始化呢】
静态方法不能访问非静态成员
在 Java 中,这个规定变得好理解
- 静态成员在类初始化时就会进行初始化、赋初值等
- 非静态成员在对象实例化时才会进行初始化等操作
- 在静态成员初始化时,非静态成员还没有被分配相应的内存
轻微吐槽,在 C/C++ 中解释这个规则真的很难说明白
手动装载
- 使用
Class_name.loadClass(类的全限定名)装载一个类 - 使用
Class_name.forName(类的全限定名)初始化一个类
线程安全
类的装载过程是线程安全的
类加载器
双亲委派模型
概念
- 双亲委派模型的基本含义:当一个类加载器收到类加载的请求时,它先不会尝试加载类,而是将加载请求委派给它的父类,以此类推,因此,最后所有的加载请求都会由最顶端的启动类加载器进行加载
- 如果启动类加载器在它的搜索范围内没有找到相应的类,子加载器才会尝试加载
作用
- 如果每个类加载器都单独进行类加载,则每个加载器都需要在自己搜索范围内确定相应的类,也要判断该类是否被加载(大概)
- 如果类加载器搜索范围的界限不合理,可能导致同一个类被不同的加载器加载若干次,或者不被加载等(大概)
- 如果所有类加载器的搜索范围都是全部,则可能在多线程情况下出现重复加载(大概)
其他说明
- 双亲委派模型并不是 Java 强制要求的规则,只是开发者建议程序员这样做
双亲委派模型被打破的三大事件
-
需要兼容旧版 JDK(程序员实现了很多用户加载器来加载类的情况)
此时许多程序员会直接重写 loadClass() 方法,导致加载器直接进行加载,而不向上委派当然开发者提供了兼容双亲委派模型的方式,即提供 findClass() 方法,希望程序员重写 findClass() 方法,这样在父类的 findClass() 没有找到相应的类时,就会使用子类的加载器,从而兼容旧版代码
-
在如 JNDI 服务的应用场景中,双亲委派模型将不使用【看不懂awa】
-
新需求的出现,如热部署等,在部署后服务能够直接使用,而不需要重启
创建对象的方式
创建对象的过程
-
在方法区(元空间)常量池中定位类的符号引用,如果没有该类的符号引用,则证明该类还没有进行初始化,JVM 则对类进行初始化操作
-
使用指针碰撞的方式为即将产生的对象分配空间
指针碰撞:即使用一个指针作为对象空间和空闲空间的分界点
如果内存空间非常紧张(空间过于碎片化等),则使用虚拟表进行空间分配(虚拟表中记录了空闲空间的地址,新对象就被散乱地分配在内存空间中)
引用数据类型只会在堆中分配4个字节的内存(引用类型的大小)【不应该是在栈中分配吗?】
-
使用 CAS 线程安全地将内存分配给对象
-
对象初始化,此处的初始化是基本的初始化,如类成员的初始化,初始化的值为0或null或false
-
设置对象的对象头,对象头中包含了对象的特定信息,如 HashCode/GC信息/锁信息 等
具体大致分为 hashcode + GC分代年龄 + 锁状态 + 线程持有的锁 + 偏向线程ID + 偏向时间戳
-
执行初始化函数,执行初始化代码块/成员变量的值/构造函数等
创建对象的方式
- new 一个对象时,将创建对象
- 利用反射获取到 .Class 信息之后,通过 newInstance() 方法实例化对象
- 通过反序列化获取对象(反序列化即将外部的对象信息转为内部的对象)
- 通过 Clone() 创建对象,但是 clone 也称为拷贝,分为深拷贝与浅拷贝,以对象成员中有引用数据类型的变量为例,浅拷贝得到的 clone_obj 中引用数据类型成员指向原对象的成员实例,深拷贝将同时拷贝该引用类型成员的实例,如果需要完成深拷贝,需要在成员引用类型的类定义时,实现 Cloneable 接口并重写 clone 方法
垃圾回收
垃圾回收策略
内存模型
Java1.8 的内存模型主要分为 Eden + Survivor + Tenured + Metaspace + 用来扩展的伸缩区
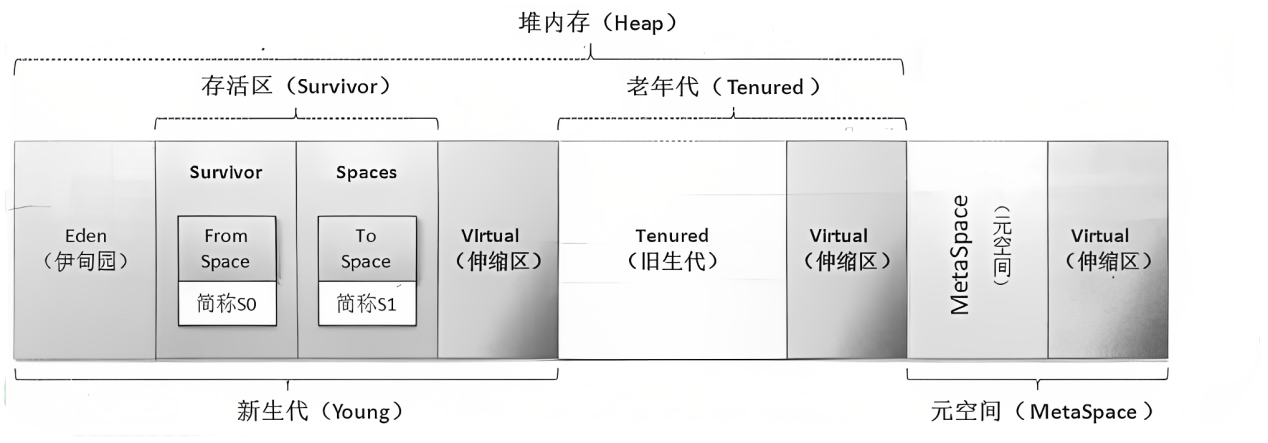
- 扩展区使得 Java 虚拟机的块内存区(新生代、老年代、元空间)都能根据需要进行动态扩充
垃圾收集流程
垃圾回收主要针对新生代(Eden+Survivor)和老年代(Tenured)
-
当需要在堆上创建一个对象时,JVM 首先会查看 Eden 区是否有多余空间,如果有,则直接将对象放在 Eden 区;如果没有,则将对 Eden 区进行 GC;
此时的 GC 称为 Young GC(Minor GC)
-
Eden 区 GC 之后,如果有多余空间,则将对象放在 Eden 区;如果还是没有多余空间,则查看 Survivor 区是否有多余空间;如果 Survivor 区有多余空间,则从 Eden 区转移部分不活跃的数据到 Survivor 区,转移数据后,Eden 区就有多余空间放新对象了(大概);如果 Survivor 区没有多余空间,则对 Survivor 区进行 GC;
Survivor 区也在新生代区域内,所以此时的 GC 也可以称为 Young GC(Minor GC)
-
Surcicor 区 GC 后,如果有多余空间,则存放从 Eden区转移过来的数据;如果还是没有多余空间,则会查看 Tenured 区是否有多余空间,如果有,则会转移部分不活跃的数据到 Tenured 区;如果没有,则会对 Tenured 区进行 GC;
一般发生在老年代的 GC 称为 Major GC
也有将老年代的 GC 称为 Full GC 的说法【Full GC 详见下文】
-
Tenured 区 GC 之后,如果有多余空间,则存放从 Survivor 区过来的数据;如果还是没有,则返回 OOM;
Full GC
STW【Stop The Word】
-
STW 即 stop the word,表示在 GC 过程中,除了用以 GC 的线程,其他的线程全部暂停
一般在 Full GC 时发生 STW
【但是也有说法是所有 GC 过程中都会发生 STW,只是 STW 的时间不同】
Full GC 是什么
-
一种说法是:发生 Full GC 表示对堆中所有区域都进行垃圾收集,包括新生代、老年代
-
也有说法是,Full GC 是发生在老年代的 GC
这种说法与 什么是FullGC - 码农教程 所述一致,通过 jstat 查看线程发生 GC 的次数,同时与 GC 日志上的 Full GC 标志进行比对,发现 Full GC 是指老年代的 GC
发生 Full GC 的情况
参考自 JVM–Java垃圾回收的原理与触发时机 - 自学精灵
其中认为 Full GC 是对新生代、老年代进行 GC
-
老年代的内存使用率达到阈值【默认为 92%】
即老年代的内存不足时,触发 Full GC,此时的 Full GC 定义与 Major GC 重合
可以通过
-XX:MaxTenuringThreshoId设置老年代进行 GC 的阈值 -
当元空间扩容到了阈值时发生 Full GC
元空间阈值可以通过
-XX:MetaspaceSize设置虽然元空间不参与 GC,但是元空间扩容到指定值时要发生 Full GC
或许是因为元空间扩容时可能会占据部分堆内存,使得堆内存减小 -
程序执行了 System.gc() 方法
程序运行到 System.gc() 时,并不一定会发生 Full GC,只是程序建议 JVM 进行 Full GC
-
上一次 GC 之后,堆的各区域分配策略动态变化
-
其他【
其他这部分我看不懂awa】
I. jmap 加了 live 参数,如jmap -histo:live <pid>jmap -dump:live,format=b,file=heap.bin <pid>等
II. RMI 等的定时触发
III. Young GC 的悲观策略
老年代 GC 的说明
-
一般不会发生老年代 GC 的,在 Java 程序开发中应尽量保持 GC 发生在新生代,但是如以下等情况下,老年代将发生 GC
-
已确定的是新对象产生时,先尝试放在 Eden 中,如果 Eden 在发生 GC 之后还是内存不足,则尝试将部分对象转移到 Survivor 区中,同理,当 Survivor 在发生 GC 之后依然内存不足,则将 Survivor 中的部分对象转移到老年代
在 Survivor 区进行了【默认15次,通过
-XX:MaxTenuringThreshold设置】的 GC 之后,还没有被清理的对象会被放在老年代 -
在进行 Minor GC 时,JVM 会检测 Survivor 区的空间。如果 Survivor 空间不够用,则检查老年代空间,检查标准为:
老年代连续可用空间是否大于min(新生代总和, 历次晋升到老年代的对象大小的平均值);在上述两次检测中,如果空间足够,则发生 Minor GC;如果两次检测空间都不足,则发生 Full GC
-
之前有提到,新对象是先尝试放入 Eden 区,但是新对象的大小如果超过某个阈值【阈值通过
-XX:PretenureSizeThreshold设置】,则该对象直接放入老年代产生大对象的情况如:查询不分页
System.gc() 的说明
-
虽然 Systemgc() 只是建议 JVM 进行垃圾回收,JVM 并不一定真正执行 Full GC,且即使 JVM 决定执行垃圾回收,也不会立即执行,但是使用了 System.gc() 方法,则在垃圾回收时会调用对象的 finalize 方法
-
System.gc() 虽然只是建议做垃圾回收,但是也增加了系统进行 Full GC 的概率,可能导致系统因为过多的 GC 卡顿
这种情况如 性能优化篇-记一次 Full GC导致的性能问题 所示
GC Roots
引言
-
判断一个对象是否需要被回收有两个方法,即引用计数算法和可达性分析算法,JVM 采用的是可达性分析算法
-
引用计数算法的核心是,每个对象都维护一个引用计数器,每当有引用指向这个对象,计数器就加 1 ,当有引用释放这个对象,计数器就减 1 ,计数器为 0 的对象表示此刻没有引用指向它,此对象需要被回收
引用计数器算法无法解决的问题是循环引用,当 A 和 B 相互引用时,它们的计数器就恒不为 0,导致对象无法被回收
-
可达性分析算法的核心是,使用类似图的结构来判断某个对象在某时刻是否能被访问到,如果不能被访问到,则表示该对象需要被回收
可达性分析的 “是否能被访问到” 是指,从 GC Roots 对象开始向下进行访问性查找,查找所经过的路径称为 引用链 ,当对所有 GC Roots 对象查找完毕时,不被任何引用链涉及的对象需要被回收【如图,对象 567 需要被回收】【GC Roots 对象详见下文】
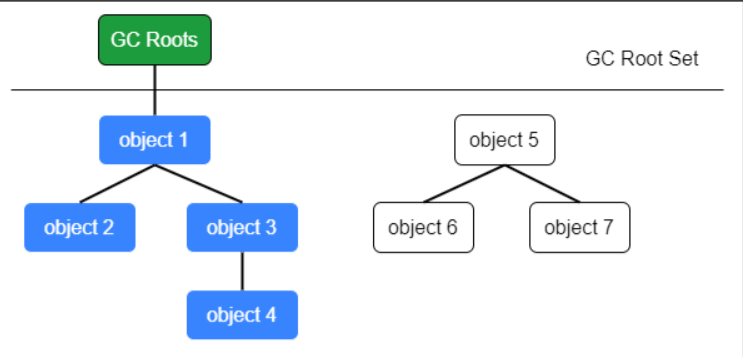
可作为 GC Roots 的对象
-
GC Roots 可以理解为,一组必须活跃的引用,并且需要确定的是,GC 针对 JVM 的堆内存,方法区和虚拟栈区等空间不受 GC 影响。可以作为 GC Roots 的对象如下
-
在虚拟机栈中引用的对象,即在栈帧中的本地变量表中引用的对象
浅显的理解为线程栈中引用的对象,这一般是局部变量引用的对象
-
在方法区中类的静态属性引用的对象
这理解为在方法区中会存放类信息,其中类的静态属性字段会伴随类的一生,如果类的静态字段是引用类型,则引用指向的对象可以作为 GC Roots
-
在方法区中常量引用的对象,如 String 的字符串常量池中的引用
同理,由于方法区不参与 GC,因此方法区中常量引用的对象也可以作为 GC Roots(常量属性的引用不能修改引用和对象之间的指向关系)
-
本地方法栈中引用的对象
本地方法栈针对程序需要使用本地(Native)方法的情况,当程序调用本地方法,则将使用本地方法栈
需要确定的是,程序是以栈的形式运行的,当发生函数调用时,则进行状态保存,然后压栈,然后调用函数
调用 Java 方法时,使用虚拟机栈,调用本地方法时,使用本地方法栈,从使用上来说,二者无甚差别,只是从一个栈转换到了另一个栈
-
JVM 内部的引用,如基本数据类型对应的 Class 对象、常驻的异常对象、系统类加载器等
反映 JVM 内部情况的 JMXBean、JVMTI 中注册的回调、本地代码缓存等常驻的异常类如 NullPointExcepiton、OutOfMemoryError 等
以上情况都可以理解为 JVM 运行时自己内部需要的一组活性对象
-
被同步锁 synchronized 持有的对象
-
根据用户的 GC 策略以及当前回收的区域,“临时性” 加入的一些对象
以上情况理解为,用户对默认的 GC 进行了选择,因此引入了新的,在GC 时需要保持活性的对象
垃圾对象的回收过程
引言
- 一个不可达的对象,需要通过两次标记后才会被回收
- 通过 GC Roots 的引用链,发现某对象不可达,则该对象被标记为可回收
- 然后对可回收的对象进行筛选。一类是需要执行 finalize 方法的,这些对象会被放在一个 F-Queue 中,然后在某时刻被 JVM 自己维护的一个低优先级线程调用 finalize 方法;另一类是已经执行过 finalize 方法或者没有 finalize 方法的对象,这些对象将直接被回收
- 需要注意的是,在 F-Queue 中的对象,会由线程在某时刻调用它的 finalize 方法,但是 JVM 并不会等待 finalize 方法执行
- 当执行完 finalize 方法后,GC 还会再判断一次该对象是否可达
GC 中对象的状态
-
unfinalized:对象刚被创建时的 final 状态,此时对象可达,GC 也并未准备回收该对象
-
finalizable:通过 GC 检测发现对象已不可达,此时可以执行 finalize 方法
-
finalized:该对象已经执行过 finalize 方法
-
reachable:通过 GC Roots 的引用链发现该对象可达
-
finalizer-reachable:通过 GC Roots检测该对象已经不可达,但是还可以通过 finalizable 的对象可达
-
unreachable:不可达,不是 reachable,也不能 finalizer-readchable 可达
对象被 GC 时的过程
-
对象创建时,处在【reachable+unfinalized】的状态,可达,且 GC 还未准备回收它
-
在程序运行过程中,对象转化为【finalizer-reachable+unfinalized】或【unreachable+unfinalized】状态
-
JVM 在某时刻发现对象处在【unfinalized】状态,但已经不能通过 GC Roots 可达,则它将该对象的状态更新为【finalizable】,同时,如果此时该对象的状态为【unreachable】,则将可达性状态更新为【finalizer-reachable】
为什么要将可达性状态更新为【finalizer-reachable】
因为在标记为 finalizable 状态后,对象会在某时刻执行 finalize 方法,此时该对象就通过某 finalizable 对象可达
也因此,没有【finalzable+unreachable】的状态
-
JVM 在某时刻取出 finalizable 状态的对象,将其放入线程中,执行 finalize 方法,此时对象状态更新为【finalized+reachable】
-
finalze 方法执行完的对象会再一次进行可达性验证,【finalized+unreachable】状态的对象,则会被 JVM 回收
- System.runFinalizersOnExit()等方法可以使对象即使处于reachable状态,JVM仍对其执行finalize方法
垃圾回收算法
分代收集算法
- 分代收集算法即对新生代、老年代采用不同的算法
标记-清除算法
- 简而言之是,将需要被回收的对象进行标记,然后根据标记回收对象
- 优点:优点在于简单,速度快,适合存活对象多的场景
- 缺点:缺点在于会产生大量的空间碎片;在需要回收的对象比较多的情况下,需要对大量分散的对象进行清除,导致耗时变长
标记-复制算法
-
标记-复制算法的大致实现思路是,在系统中开辟两份空间 S0,S1 ,每当进行 GC 时,就将存活的对象转移,剩下的死亡对象则直接被回收
如在 JVM 的新生代空间中,有三个分区:Eden + Survivor(S0) + Space(S1)
当有对象生成时,对象被放在 Eden 区,在进行 GC 时,则会将 Eden 和 S0 区的存活对象先转移到 S1 区(或者将 Eden 和 S1 区的存活对象转移到 S0 区),然后进行清理
-
优点:解决了标记-清除法产生大量空间碎片的问题
-
缺点:
I. 应对有大量存活对象的场景,在 GC 时采用标记-复制算法将在复制过程中耗费大量时间II. 同时,为了完成复制,则总有一片空间是空闲的,导致空间浪费
III. 所以为了尽可能少地浪费空间,复制区会尽可能设置得小,不过这也导致在出现大对象或存活对象很多时空间可能不够,因此需要一个 担保机制 ,即在复制区空间不够时,可以从别的地方借一点空间使用
标记-整理算法
- 标记整理法的大致实现思路是:先将对象是否存活进行标记,然后再进行整理,整理的过程中,将存活的对象移至内存的一端,而后再清理内存另一端的死亡对象
- 优点:不会产生大量空间碎片,而且适用于存活对象比较少的情况
- 缺点:标记-整理算法在每次进行 GC 时都要进行对象的迁移,因此要维护一个对象迁移的引用空间,同时也要准备一定的空间用来做对象的转移,因此总的来说耗时最长
垃圾回收器
JVM虚拟机系统性学习-垃圾回收器Serial、ParNew、Parallel Scavenge和Parallel Old
浅析经典JVM垃圾收集器-Serial/ParNew/Parallel Scavenge/Serial Old/Parallel Old/CMS/G1
新生代收集器
Serial
-
串行回收,Serial 采用 单线程 + STW + 复制算法 进行垃圾回收
-
虽然 JDK 默认的垃圾收集器没有 Serial,但是 Serial 是客户端模式下新生代的默认垃圾收集器
-
由于 Serial 采用单线程工作(或者说采用单处理器工作),它在进行 GC 时会暂停其他用户线程(STW)
这也使得 Serial 在 GC 时有比较高的收集效率,同时也不会造成太大的额外内存消耗
Parnew
- 串行回收,和 Serial 不同的是,Parnew 使用了多个线程进行回收,它的串行也只体现在 GC 中,在使用 Parnew 进行 GC 时,依然会导致 STW
- Parnew 依然使用标记-复制算法进行垃圾回收,除此之外,它的控制参数、对象分配规则、回收策略等也和 Serial 一致
- 和 Serial 一样,主要用于新生代区域的垃圾收集,不过 Parnew 主要用在服务器端,是服务器模式下的默认新生代收集器(JDK7之前);同时,它也是和 Serial 一样,可以与老年代收集器 CMS 搭配使用的收集器(其他的新生代收集器不行)
- 不过需要注意的一点是,在开启 CMS 之后,新生代的收集器会默认为 Parnew
开启 CMS 的指令:-XX: +UseConcMarkSweepGC
关闭/禁止 CMS 的指令:-XX: +/-UseParNewGC - Parnew 默认使用(和处理器核心数量相同的)线程来进行 GC
调整 Parnew 垃圾收集时能使用的线程数量:-XX: ParallelGCThreads
Parallel Scavenge
-
Parallel Scavenge 与 Parnew 不同的是,它是一个吞吐量优先的收集器
吞吐量:指在系统中程序代码运行的时间在总运行时间中的占比
之所以会有这样的标准,是因为在 GC 时产生的 STW 导致程序本身代码运行的时间减少则垃圾回收导致的 STW 越短,吞吐量越大
-
值得注意的是,Parallel Scavenge 并不追求极致的吞吐量,它的目标是吞吐量可控
-
Parallel Scavenge 还具有自适应调节策略,比较重要的三个参数如下
I.
-XX:MaxGCPauseMillis:JVM 进行 GC 时最大的 STW 时间(以毫秒为单位)【默认情况下,没有最大的 STW 时间】但是即便在设置了这个参数的情况下,也不意味着 JVM 一定保证 STW 的时间不超过该值,只能使 JVM 尽量实现该值的要求
但是值得注意的是,MaxGCPauseMillis 的值越小,则意味着 JVM 会越频繁地进行 GC,以此来尽量满足 MaxGCPauseMillis 的要求
因此,当 MaxGCPauseMillis 过小时,可能导致吞吐量变低
II.
-XX:GCTimeRatio:设置吞吐量;GCTimeRatio 设置的数值其实是吞吐量的倒数吞吐量 = (代码运行的时间 / (代码运行的时间 + 垃圾回收的时间))
GCTimeRatio = ((代码运行的时间 + 垃圾回收的时间) / 代码运行的时间)如,垃圾回收占用时间1,程序运行的总时间为20,那么吞吐量就为5%
GCTimeRatio 将被设置为 19
III.
-XX:+UseAdaptiveSizePolicy:开启/关闭 GC 自适应的调节策略;UseAdaptiveSizePolicy 参数打开后,JVM 的一些细节参数就可以由 JVM 自行调整;可以自行调节的参数如:
新生代大小:-Xmn;
Eden 区与 Survivor 区的比例:-XX:SurvivorRatio
晋升老年代对象的年龄:-XX:PretenureSizeThreshold需要用户手动设置的参数如:
基本的内存数据(堆最大空间等);-XX:MaxGCPauseMillis 和 -XX:GCTimeRatio 其中之一(为虚拟机制定 GC 的效率目标)
Parallel Scavenge 自适应调整策略的其他说明
- 在 JDK1.8 及之后,在使用 CMS 作为垃圾回收器的情况下,-XX:+UseAdaptiveSizePolicy 参数将自动失效,所以它不能搭配 CMS 的老年代收集器,而是搭配 Parallel Old 作为老年代收集器
- 当 -XX:+UseAdaptiveSizePolicy 与 -XX:SuevicorRatio 搭配使用时,将发生冲突,导致参数失效
- 在 -XX:+UseAdaptiveSizePolicy 参数开启的情况下,可能出现以下情况导致系统卡顿:自适应策略下,JVM 给新生代分配一个很小的 Survivor 区,这导致在发生 YGC 时,很容易出现 Survicor 区空间不足,进而导致对象迁移到老年代,然后触发 FGC
- 所以一般不建议打开自适应调整策略
老年代收集器
Serial Old
- 与 Serial 类似,使用 单线程 + 标记整理算法 + STW 进行 GC,主要用于客户端模式的老年代垃圾回收
- 但是在 JDK5 之前,Serial Old 也作为老年代的垃圾回收器,与 Parallel Scavenge 搭配使用;在 JDK5 之后,Serial Old 将作为 CMS 垃圾回收失败后的备用收集器
Parallel Old
- Parallel Old 和 Parnew 类似,在进行 GC 时采用多个线程并行的方式,但是在此时,用户线程处于暂停状态
- 采用 多线程 + 标记整理算法 + STW 进行 GC
- 在注重吞吐量或者处理器资源较为稀缺的场景,可以优先考虑 Parallel Scavenge + Parallel Old 的组合进行 GC
CMS
- CMS 的一个特征是 (与用户线程)并发,即宏观并行,微观串行(交替执行)
- 使用 标记清除算法 + 并发 + 低停顿 进行 GC
- 由于 CMS 可以大致上做到和用户线程并发,并且 CMS 追求尽可能小的停顿时间,因此在基于浏览器的 B/S 系统服务端或者其他关注服务器响应速度的场景比较适用
关于 CMS 的说明
-
CMS 进行垃圾回收主要经过四个步骤,如下
-
初始标记:标记与 GC Roots 直接相连的对象,此时将导致 STW,但是这个过程非常快
-
并发标记:此时用户线程并不会因为标记行为而暂停,但是 JVM 会根据初始标记的对象遍历对象图,即遍历所有引用链,这个过程的耗时会较长一些
-
重新标记:重新标记主要应对在并发标记过程中,因为用户线程活动新产生的对象,此次标记的具体标记法暂不了解,但是此过程的时间是小于并发标记但是大于初始标记的时间
重新标记也将造成 STW
-
并发清除:在不暂停用户线程的情况下,使用标记-清除法清除未被标记的对象,即死亡对象
缺点
-
由上引出 CMS 的缺点:由于 CMS 的死亡对象是并发标记和清除的,则在重新标记之后再产生的死亡对象,要等到下次 GC 时才会被回收,这些死亡对象被称为 “浮动垃圾”
浮动垃圾可能导致 Con-current Mode Failure,进而造成 FGC,并且此时表示 CMS 已经失败,将使用 Serial Old
-
与所有的标记-清除法一样,CMS 可能导致出现大量的空间碎片
-
CMS 收集器对处理器资源非常敏感(面向并发设计的程序都对处理器资源敏感),这导致在 GC 过程中虽然用户线程不会被暂停,但是由于需要占用一部分线程来进行 GC,所以用户线程的运行效率还是有一定幅度的下降
-
如上,由于 GC 时用户线程不被暂停,因此在老年代需要一直预留一块区域以供用户线程使用
整堆回收器
G1
- 与 CMS 相比,G1 算法的目标是更高的吞吐量,策略是 STW 的时间相较于 CMS 更长,但是 STW 的次数更少
与 CMS 的另一个不同点是,CMS 在进行垃圾清理时,使用并发清理;G1 采用并行清理 - 在 JDK11 及之后,JDK 的默认垃圾回收器就换成了 G1(针对老年代和新生代)
- G1 采用 整体标记整理算法 + 局部标记复制算法 + 分布式 + 多线程 进行垃圾回收,两种垃圾回收算法都不会产生空间碎片,因此 G1 不会产生内存空间碎片
G1 垃圾回收器的工作流程
【G1 进行回收的过程在此只是进行了简略的叙述,甚至可能有误awa】
需要确定的是,与其他垃圾回收器相比,G1 在对堆空间的划分层面有很大的差异
G1 将堆空间分成若干个固定大小的 Region,这个大小一般在 [1MB, 32MB] 之间,并且为 2 的 n 次幂大小【通过
-XX:G1HeapRegionSize设置】这些固定大小的 Region 根据 JVM 的需要,被分成新生代、Survivor 、老年代等,除此之外,G1 还提供了一块区域 Humongous 用来存放大对象(对于大对象的判定条件是,该对象的大小超过 Region 的一半)
Humongous 区域在 GC 时,会被默认当作老年代进行清理
另外需要确定的是,G1 回收器中,清理 Region 的判定条件是:根据每个 Region 中垃圾堆积的 “价值”(存活对象的占比(大概)) ,在后台维护的一个优先级列表,每次 GC 时,就先回收价值更大的区域
这使得 G1 回收器并不用每次都对整堆进行清理
- 初始标记:标记与 GC Roots 直接相连的对象,并修改 TAMS 指针
此时会出现 STW,但是时间非常短,而且大部分初始标记会和 YGC 同时发生,因此也可不算时间 - 并发标记:对所有对象进行可达性分析,此过程中用户线程不会被暂停
- 最终标记:此过程会出现 STW,目的是对在 并发标记 过程中,用户线程产生的垃圾进行标记
- 筛选回收(并行清理):使用标记-复制算法,将一个 Region 中的存活对象先复制到另一个空的 Region 中,然后进行清理
需要明白的是 G1 的目标:将 GC 时的 STW 时间尽量限制在某个期望值中
【通过-XX:MaxGCPauseMillis设置,默认为 200ms,通常这个值设置在 [100, 300]ms 范围内】
CMS 在小内存应用上的表现要优于 G1,而大内存应用上 G1 更有优势,大小内存的界限是6GB到8GB
G1 的缺点
- 占用内存过高:每个 Region 都需要一块空间来维护 Region 的相关信息,这部分的空间可能占到堆内存的 [10%, 20%]
- 执行负载高
ZGC
Java 的默认垃圾回收器
-
使用
java -XX:+PrintCommandLineFlags -version查看 Java 默认的垃圾回收器
Java21(即 JDK11) 已经采用 G1 作为垃圾回收器(如上)
-
历代 JDK 默认的垃圾回收器
版本 年轻代 老年代 JDK6 PSScavenge
(Parallel Scavenge)PSMarkSweep
(Parallel Scavenge)JDK7 PSScavenge
(Parallel Scavenge)PSParallelCompact(Parallel Old) JDK8 PSScavenge
(Parallel Scavenge)PSParallelCompact(Parallel Old) JDK11 G1 G1 -
PSScavenge(Parallel Scavenge) + PSMarkSweep (Parallel Scavenge) 称为 PSPS;PSScavenge(Parallel Scavenge) + PSParallelCompact(Parallel Old) 称为 PSPO
调优
新特性
JDK 8
JDK8 也就是 JDK1.8
default方法
-
众所周知,继承了接口的类,需要实现接口中的所有方法
因此,在修改接口时,则要修改所有继承该接口的类 -
在 JDK1.8 及以后,引入 default 方法。在接口中,被 default 修饰的方法,不强制要求继承接口的类实现
并且:default 修饰符允许在接口中实现方法
如果该类没有对 default 方法进行实现(重写),则在调用时会执行接口中的代码
interface MyInterface{
default void sayHello(){
System.out.println("sayHello");
}
}
class MyInterfaceImpl implements MyInterface{
public void test() { }
}
public class Demo {
public static void main(String[] args) {
MyInterfaceImpl myInterface = new MyInterfaceImpl();
myInterface.sayHello();
}
}
- 需要注意的是,当一个类继承了多个接口,而这些接口中有两个及以上的default同名函数,则报错
interface MyInterface1{
default void sayHello(){
System.out.println("sayHello(1)");
}
}
interface MyInterface2{
default void sayHello(){
System.out.println("sayHello(2)");
}
}
class MyInterfaceImpl implements MyInterface1,MyInterface2{
public void test(){
MyInterface1 myInterface = new MyInterfaceImpl();
// 将执行被重写的函数
myInterface.sayHello();
}
// 若不进行重写,则报错
@Override
public void sayHello() {
System.out.println("sayHello(Impl)");
}
}
public class Demo {
public static void main(String[] args) {
MyInterfaceImpl impl = new MyInterfaceImpl();
impl.test();
}
}
static函数
- 众所周知,接口的方法都是抽象方法,没有方法体
- static函数使得接口的方法能够有方法体,并且像访问类的静态成员函数一样,使用
interface_name.function_name(parameter)的方式调用接口中的 static 函数
Stream 与 Stream API
Stream 的具体使用等我学会了再进行补充,在此先浅进行概念的叙述
基本介绍
Stream 是一种可以将集合数据转化为流的优雅方式,同时它还为已经转化为流的数据优雅地提供操作接口
“可以像操作 SQL 一样操作流数据”
I. 流并不会保存数据,它只会在操作完数据之后,将结果保存在另外的对象中,然后返回给程序员
II. 但是 peek 方法会修改流中的元素
“惰性求值”
像 MySQL 一样,在 commit 之前的操作并不会真正执行,在 commit 的时候才会执行
当然,此处的集合不是指 Set 这个数据结构,更加合适的理解是:继承了 Collection 或者 Map 接口的类
如:List 、 Array
操作步骤
- 将集合的数据转化成流(创建流)
对于不同的集合,将使用不同的转化函数进行流创建
当然流中的内容也根据所用函数可能会有所不同 - 中间操作(可选) “像 SQL 一样”
映射、排序、peek操作过于复杂,我学会的时候再做补充
List<Integer> list = new ArrayList<>
(Arrays.asList(6, 4, 6, 7, 3, 9, 8, 10, 12, 14, 14));
List<Integer> newList = list.stream()
// 筛选符合条件的元素
.filter(s -> s > 5) //6 6 7 9 8 10 12 14 14
// 去重
.distinct() //6 7 9 8 10 12 14
// 跳过前n个元素
.skip(2) //9 8 10 12 14
// 只取前n个元素
.limit(2) //9 8
// 终止操作,将最后的结果返回成一个 List
.collect(Collectors.toList());
- 终止操作(可选)
具体使用方式等我学会了再进行补充
可以理解为将中间操作之后得到的结果返回,这个返回的数据可能是数量、最值、条件判断的结果,或者新的数据结构等
如上述代码,最后的结果将被封装为一个List
Java 多线程
线程同步方案
volatile
引言
- volatile 上下文以及 volatile 中的语句不允许指令重排,因此 volatile 可以保证有序性
- 保证可见性,即 volatile 变量一旦被修改,则对所有线程可见,因为对 volatile 变量的修改是直接刷新到主内存的
- volatile 不保证原子性,它只能保证多线程中变量可见,因此它无法代替 synchronized
synchronized
引言
- synchronized 可以保证原子性、有序性、可见性,在多线程同时使用一个 “对象监视器” 的情况下,synchronized 可以保证同步
- 被 synchronized 修饰的代码段有如下执行过程
获取锁 ==> 重置(清除)工作内存中该变量的数据 ==> 从主内存拷贝对象副本到工作内存 ==> 操作数据 ==> 刷新主内存中的变量数据 ==> 释放锁 - synchronized 前后的代码段不可与 synchronized 中的代码段重排序
- 保证 synchronized 中的代码执行结果与顺序执行得到的结果一致(允许重排序)
底层原理
【底层原理非常的复杂,此处只做简单描述】
- 与主观逻辑一致,synchronized 在底层进行了锁的获取和释放,从而达到互斥
- synchronized 获取到的锁是 Java 对象自带的内置锁,每个对象都有一个自己的内置锁,锁数据存在于对象头中,包含两个部分:锁状态 + 持有锁线程的信息
- 当线程需要访问该对象时,判断锁状态,如果锁状态为 1 则表示对象正被其他线程占用,则当前线程进入阻塞状态,当锁被其他线程释放时,JVM 将唤醒当前线程竞争锁;如果锁状态为 0 则当前线程获取锁
使用场景
修饰静态方法
- 由于类的静态方法是对所有类对象可见的,即,synchronized 修饰静态方法,锁住的对象是一个类
该方法的调用者无论是 Class 还是实例,都可以实现互斥
public synchronized static void method() {
count++;
}
修饰普通方法
- synchronized 修饰普通方法,将对每个实例对象分别进行加锁,这使得当多个线程操作同一个对象时,被 synchronized 修饰的代码块可以实现互斥
- 正如上文所示,synchronized 修饰普通方法的加锁目标是对象,因此,如果用不同对象访问 synchronized 属性的普通方法,则不能实现同步
class MyThread implements Runnable{
@Override
public synchronized void run() {
System.out.println(1);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(2);
}
}
public class Demo{
public static void main(String[] args) {
// 使用了两个对象进行监测,因此不能同步
MyThread myThread1 = new MyThread();
Thread thread1 = new Thread(myThread1);
MyThread myThread2 = new MyThread();
Thread thread2 = new Thread(myThread2);
thread1.start();
thread2.start();
}
}
修饰代码块
- synchronized 作用于代码块 与 作用于普通方法的效果类似,不同的是,synchronized 作用于代码块只会锁住一部分关键代码
public void method() {
synchronized (this) {
count++;
}
}
-
由于代码块中的内容未知,因此 synchronized 属性的代码块可以针对实例对象,也可以针对 class 对象
如在 synchronized 代码块中使用了 .class 或 .getClass() 方法,则将针对 class 对象
优缺点
- 优点是:使用简单 + CPU 占用低
- 缺点是:不灵活 + 响应缓慢(并发性差)
因此 synchronized 适用于【并发量低的场景或者大代码块的同步】
并发集合
- 如:ConcurrentHashMap【略】
就是使用线程安全的类
优缺点
- 优点是:具有高的并发性能
- 缺点是:使用集合实现线程同步,需要借助集合结构
JUC
【详见下文 Java多线程 · JUC - java.util.concurrent】
ThreadLocal
在上文【内存泄漏 – ThreadLocal】中对 ThreadLock 进行了基础的介绍,但是上文的主要侧重点为 ThreadLock 可能导致的内存泄漏与 ThreadLock 和引用的关系
在多线程层面,ThreadLock 的说明如下
引言
- ThreadLocal 和 synchronized 的不同之处在于,ThreadLocal 注重线程之间的数据隔离,ThreadLocal 为每个线程维护一个实例副本,使得线程之间能够共享类数据,但同时又独立地操作实例数据
- 可以理解为,线程拥有一个 ThreadLocalMap 属性,这个 Map 中以线程信息为 key,以相对应实例副本的弱引用为 value,而 ThreadLocal 主要是对这个 Map 进行管理,也因此,Map 的 key 用 ThreadLocal 代替(早期的 Map 以 Thread 为 key)
- 因此可以更好地理解为什么 ThreadLocal 的 value 是弱引用,如果 value 是实例的强引用,则该实例在线程存活期间就无法被回收,考虑到某些线程会伴随整个程序的生命周期,所以不能使用强引用
ThreadLocal 使用场景
-
变量在线程间相互隔离,但是在类或方法中共享
-
线程需要自己单独的实例
-
如:数据库连接/处理数据库事务时,每个线程都应控制一个属于自己的实例,但是实例得到的数据结果会在多个方法/类之间共享
底层原理
看不懂底层原理的解释,以后看懂的时候再进行补充
wait() and notify()
引言
- wait/notify/notifyAll 方法是 Object 类提供的方法,因此所有引用数据类型都可以使用
- 调用 wait/notify/notifyAll 方法的前提是,该线程已经成功获取了锁,即,方法都需要在同步方法/同步代码块中调用,也因此说方法需要与 synchronized 连用
- wait方法的主要作用是,将当前线程阻塞,并释放锁,当再次获取锁时,当前线程从 wait 开始继续执行,而非从头开始
- notify/notifyAll 方法的主要作用是,唤醒一个或多个因 wait 导致阻塞的线程,但是调用 notify/notifyAll 方法只是唤醒了线程,实际上并未释放锁
- 从理解的角度上面来讲,wait/notify/notifyAll 方法配合使用,能够在宏观角度进行线程的时分复用
对于需要等待其他资源的线程,使用 wait 方法阻塞该线程,释放锁给其他的线程使用,其他线程使用完后,使用 notify/notifyAll 方法唤醒该线程,然后继续执行
说明
- 一般 wait 方法与 while 配合使用,因为每次线程被唤醒时,从 wait 方法继续执行,如果使用 if 进行执行条件判断,则实际上只会进行一次判断
- 在 wait 状态的线程可以被 interrupt 中断
synchronized 和 volatile 和 ReentrantLock 和 Lock
synchronized 与 volatile
-
volatile 作用于变量,synchronized 作用可以作用于变量、方法、类
也可以认为,volatile 修饰变量,而 synchronized 可修饰变量、方法、类
-
synchronized 从本质上来讲是对代码(变量、类、方法)进行锁定,当多个线程进行访问时,需要竞争锁,未竞争到锁的线程会被阻塞
volatile 的本质是,为变量打上 “不确定性” 的标签,当线程访问该变量时,将从内存中直接获取值
-
因此 synchronized 可以保证变量的可见性和原子性,而 volatile 只能保证其可见性
-
volatile 的附加作用即:确定变量不被编译器优化
synchronized 与 Lock
JVM 与 API
- synchronized 是 Java 的内置关键字,在 JVM 层面,其性质更倾向于封装后的组件;Lock 是一个 Java 类,在 API 层面,其性质更倾向于一个工具
- 因此 synchronized 不需要程序员进行锁获取/释放操作,同时,也不允许查看锁的状态,不允许修改锁的类型,synchronized 使用非公平锁,当多个线程竞争锁时,未竞争到锁的线程被阻塞;
- 而 Lock 需要程序员进行 .lock 和 .unlock 操作,一般在 finally 语句中释放锁,同时提供更灵活的锁访问接口,包括查看锁状态以及选择锁类型,也可以通过 tryLock 使用公平锁,因为 Lock 的可中断性,未竞争到资源的线程可以超时退出;
可中断
- 不可中断的含义是,未竞争到资源的线程,只能等待锁释放,而不能直接被中断后退出
适用场景
- synchronized 在 JDK1.6 以前是重量级锁,在 JDK1.6 之后,优化了性能,加入了四种锁状态,在特定情况下会自动进行锁升级,四种锁由轻到重为:无锁状态 --> 偏向锁 --> 轻量级锁 --> 重量级锁
- Lock 的性能更好
- 因此 synchronized 更适用于简单的线程同步控制,多线程时,发生锁竞争的概率更高
- Lock 更适用于复杂的线程同步控制,多线程发生锁竞争的概率较低
synchronized 与 ReentrantLock
- ReentrantLock 是 Lock 的子类,因此具有 Lock 的性质,以及和 synchronized 的异同点
- ReentrantLock 支持多个锁条件
锁
死锁
死锁产生条件
- 互斥条件:线程持有一个资源之后进行排他性使用,其他线程只能等到该线程将资源释放后,才能使用资源
- 不可剥夺条件:与互斥条件类似,是指一个线程获取到资源之后,只有在资源使用完毕时才会释放资源
个人认为以上两种都不严格算作死锁,只能算作阻塞
- 请求并持有条件:是指一个线程在运行过程中,提出了新的资源要求,而这个新的资源正在被其他线程使用,此时,得不到新资源的线程被阻塞,同时,这个线程也不会释放已经占有的资源
- 环路等待条件:是指在线程和资源的关系链路中,出现了环
解决死锁的方案
- 按照以上四种定义的条件,显然,只有请求并持有条件和环路等待条件可以被避免
因此我也觉得其余两种条件不算死锁
锁升级
引言
- 只会有锁升级,不会有锁降级
synchronized 锁升级的过程
-
同步锁首先持有的是偏向锁,这时仅有一个线程持有锁
JVM 有大概 4 秒的偏向锁启动延迟
-
当多个线程共同持有锁时,如果各个线程交替使用锁而不发生竞争,或在发生竞争的情况下,线程自旋的次数小于阈值时,偏向锁升级为轻量级锁
这个升级为轻量级锁的阈值默认是 10,可以通过
-XX:PreBlockSpin修改 -
当线程自旋次数大于另外某个阈值,轻量级锁将升级为重量级锁(悲观锁)
线程池
引言
线程池的优缺点
为什么使用线程池
-
如果每出现一次线程使用请求就创建一个线程,从实现的角度来讲比较方便,但是由于创建线程和销毁线程需要时间,过多的线程也会占用空间,就会导致系统性能降低
-
线程池则将某数量的线程放入池中,并对池中的线程进行管理,当有线程需要时,就从线程池中直接获取线程,这样可以减少线程创建于销毁导致的开销,由于任务不需要等待线程的创建就可以使用线程,因此线程池也将提供更高的响应速度
具体方式为:当服务启动时,就启动多个线程并将它们放入线程池,当有请求时,就从线程池中取出线程执行任务,当任务结束后,又将该线程放入线程池中备用
在高并发场景中,如果请求的数量 > 线程池中线程的数量,则部分请求需要排队等候
当服务关闭时,直接销毁线程池即可
-
如上文所述,线程池也为管理线程提供了方便
使用场景(以网络请求为例)
- 一部分网络请求是在建立连接后,会保持相当一段时间来进行通信,如文件下载、网络流媒体等
- 另一部分请求是频繁建立连接,但每次连接后只会持续很短的一段时间来进行通信,如聊天窗口等,此时如果每次都创建线程,则会极大地影响系统性能
- 针对频繁的短时间通信,使用线程池就会很合适,即当建立线程的时间 >> 建立线程后通信的时间,就使用线程池
缺点
- 多线程在设计本身就将占用更多的 CPU,因此在高并发场景下,其他功能得响应速率可能会变慢
- 适用于生存周期短的任务
- 不能标识线程池中各个线程的状态【
因为线程池中线程的调用被封装了,所以从外界不能看到某个线程是否正在启动等【大概】】 - 对于给定的应用程序域,只能允许一个线程池与之对应【
这是什么意思】
线程池大小
CPU 密集型
-
CPU 密集型即该任务主要操作集中在计算,响应时间快,CPU 一直在运行,对 CPU 的利用率很高
CPU 密集型的特点是,被阻塞的时间 < 执行时间(表示大部分时间用来执行计算了)
-
如果线程池设计得过大,那么在多个线程就绪时,CPU 需要进行大量的线程上下文切换,导致系统性能损耗
-
但是线程池大小也应该 ≥ 处理器核心的数量
通常使用【处理器核心数量 + 1】作为线程池大小线程池数量在处理器核心数量的基础上 + 1的设计:
主要是为了预防某一线程长时间阻塞的情况,当某一线程发生故障而被阻塞或暂停,则还有多余的 1 个线程使用 CPU,以免 CPU 出现空闲
IO 密集型
-
IO 密集型即该任务的主要操作集中在 IO 操作,执行 IO 操作的时间相对较长,CPU 比较空闲,导致 CPU 利用率不高
IO 密集型的特点是,被阻塞的时间 > 执行时间
-
因此对于 IO 密集型任务,设置更大的线程池比较合理,当那些线程因为等待 IO 而阻塞时,其他线程可以使用 CPU
-
通常对于 IO 密集型任务,设置的线程池大小为【处理器核心数量×2 + 1】
其他说明
-
获取 CPU 核心数量:
Runtime.getRuntime().availableProcessors() -
对于 IO 密集型任务(或对于 CPU 密集型任务),可由以下计算方式设计线程池大小
ThreadPoolSize = N × U ÷ (1 - f);
其中 N = CPU核心的数量;
U = 期望 CPU 的使用率,U ∈ (0,1);
f = 阻塞系数 = 阻塞时间占总时间的比例,如总共运行 5 秒的程序,执行时间 4 秒,阻塞 1 秒,所以 f = 1/5
ThreadPoolExecutor
参数设置
如下是 ThreadPoolExecutor 的原型(ThreadPoolExecutor 是 ExecutorService 接口的默认实现):
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
-
corePoolSize:线程池的核心线程数量,即便线程池中没有任务,也会有 corePoolSize 数量的线程存活
-
maximumPoolSize:最大线程数量
-
keepAliveTime:线程的存活时间,主要针对 corePoolSize 数量以外的线程,当持续 keepAliveTime 的时间中都没有任务执行,就退出多余的线程
如果将
allowCoreThreadTimeOut参数设置为 true,则核心线程也会根据 keepAliveTime 参数退出 -
unit:keepAliveTime 时间的单位,如 秒 == TimeUnit.SECONDS
-
workQueue:阻塞队列,提交的任务会被放进阻塞队列中【当前线程池空闲时,任务直接被某线程执行,当前线程池繁忙时,任务就在阻塞队列中排队】【
大概】根据 【Java中的线程池使用及原理】 所述,更加合适的理解方式如下
I. 线程池中使用有 corePoolSize 个线程存活,这些一般处于存活状态的线程称为核心线程
II. 当有任务时,线程池先判断是否有空闲的核心线程,如果有,则直接取出执行任务,否则就将任务放入阻塞队列
III. 当阻塞队列满的时候,线程池则将创建新的线程,以用来执行任务
IV. 如果线程池中的线程数量已经达到 maximumPoolSize,则线程池将执行拒绝策略
因此,如果用来作为阻塞队列的队列如果无限,maximumPoolSize 参数就会失去效用
-
threadFactory:用来创建线程,同时对线程进行命名
-
handler:拒绝策略,当线程池中的线程被用完(达到最大数量),且阻塞队列也全用完,就会调用拒绝策略,默认的拒绝策略为 AbortPolicy,即不执行此任务并抛出异常
详细的拒绝策略描述见下文
向线程池中提交任务
execute()
-
是 Executor 接口的一个方法,使得给定命令在某时刻被线程池中的线程执行,一般这个给定命令可以是一个实现了 Runnable 接口的实例
此处说 execute 是 Executor 接口的方法,只是表示 execute 方法的来源是 Executor 接口,而 ExecutorService 其实也实现了这个方法
-
主要用于不需要返回值的任务,因此也无法判断任务是否执行成功
submit()
-
是 ExecutorService 的一个方法,主要用于需要返回值的任务,submit 方法会返回一个 Future 对象,可以通过 Future 对象获取任务执行的情况,或者通过 Future.get 方法获取返回值
Future.get 函数会一直阻塞当前线程直到任务完成,但如果使用
Future.get(long timeout, TimeUnit unit)函数,则 get 函数只会阻塞 timeout 的时间除此之外,Future 还提供了几个用来管理(查看)线程执行结果的函数
Future.cancel(boolean mayInterruptIfRunning):试图取消任务的执行
Future.isCancelled():查看任务是否被取消,如果任务在完成之前被取消了,则返回 true
Future.isDone():查看任务是否已完成,已完成任务则返回 true -
一般实现了 Callable 或 Runnable 接口的实例都可以通过 submit 函数提交
关闭线程池
shutdown
- 等待已提交的任务执行完之后再关闭线程池,在此过程中不接受新的提交
shutdownNow
- 尝试停止所有的任务,暂停所有正在等待的任务,关闭线程池并返回等待执行的任务列表
其他说明
- shutdown 和 shutdownNow 都是调用了各个线程的 interrupt 方法来中断线程,因此不响应中断的线程无法被终止
- 当调用上述两个函数的任意一个,那么 isShutdown 就会返回 true,但是要当所有任务都关闭时,isTerminad 才会返回 true
线程池的监控
线程池的生命周期
其他说明
虽然 Java doc 建议使用Executors 类中的静态方法来创建线程池,但是我们一般不采用这种方式,我们一般直接使用 ThreadPoolExecutor,以此来明确线程池的具体含义
Executors 类大概和 Collections 类一样,是 Java 提供的针对 Executor 接口的工具类(Collections 针对 Collection 接口)
Executors
如上文所述,Executor 充当的角色是 Executor 接口的工具类
- 通过 Executors 创建不同种类的线程池
其底层还是使用了 ThreadPoolExecutor 的构造方法 - 通过 Executors 管理线程池中的线程
.newFixedThreadPool
-
创建一个固定大小的线程池,这个固定大小和 corePoolSize 一样,当有任务到来时,如果线程数量小于 corePoolSize,则创建一个线程执行任务;否则,将任务放入阻塞队列中
-
由于 FixedThreadPool 的线程池大小不变化,因此在设计层面,它的阻塞队列是无界的 LinkedBlockingQueue,也因此参数 maximumPoolSize 会失效
无界队列的初始大小为 Integer.MAX_VALUE(Int 的最大值)
-
由于 FixedThreadPool 不存在 corePoolSize 数量外的线程,参数 keepAliveTime 也将失效
-
由于使用了无界队列,FixedThreadPool 永远不会触发拒绝策略
// 声明
ExecutorService executor = Executors.newFixedThreadPool(3);
executor.execute("实现了Runnable接口的实例"); // 执行
.newSingleThreadExecutor
-
创建一个只有一个线程在执行任务的线程池,如果这个线程出了问题,则由新的线程替换当前线程
虽然在单线程线程池中只有一个线程在执行任务,但是线程池中不只一个任务,会有 corePoolSize 个任务等待备用【
大概】 -
newSingleThreadExecutor 的队列也是无界队列
-
单线程线程池执行后的结果几乎和顺序执行得到的结果一致,一个任务结束后才会执行下一个任务
// 声明
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute("实现了Runnable接口的实例"); // 执行
ScheduledExecutorService
定时线程池的两种创建方式
ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
这种方式创建得到的结果是一个 newSingleThreadScheduledExecutor 对象,其底层调用了 ThreadPoolExecutor 的构造方法,本质上得到的是一个 ThreadPoolExecutor 对象ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(1);
这种方式创建得到的结果是一个 ScheduledThreadPoolExecutor 对象,该对象也实现了 ScheduledExecutorService 接口(上一种方式也实现了这个接口),但同时 ScheduledThreadPoolExecutor 还继承了 ThreadPoolExecutor,因此它比上一种方式多了一些方法- 两种方式的具体异同如下
ScheduledExecutorService 接口的方法
-
schedule(Callable<V> callable, long delay, TimeUnit unit)
schedule(Runnable command, long delay, TimeUnit unit)参数:实现了 Callable 或 Runnable 接口的实例、时间长度、时间单位
描述:在 delay 时间之后,执行一次任务(只执行了一次)
-
scheduleAtFixedRate(Runnable command, long initialDelay,long period, TimeUnit unit)参数:实现了 Runnable 接口的实例、第一次执行任务之前的延迟、后续任务开始执行的时间间隔、时间单位
描述:在等待了 initialDelay 时间之后,首次执行任务;然后在每隔 period 时间,就开始执行一个任务
但是需要注意的是,如果任务的执行时间 > 间隔时间,那么下一个任务会在上一任务执行完后立即执行
即:并不会出现:一个线程还没结束时,就开始下一个线程
-
scheduleWithFixedDelay(Runnable command, long initialDelay, long delay,TimeUnit unit)参数:实现了 Runnable 接口的实例、第一次执行任务之前的延迟、后续每个任务之间的时间间隔、时间单位
描述:在等待了 initialDelay 时间之后,首次执行任务;然后任务执行完之后,等待 delay 时间再进行下一个任务
scheduleAtFixedRate and scheduleWithFixedDelay
如命名所示,At 即任务开始之后,在等待了 delay 时间之后的节点开始下一个任务;With 即任务开始之后,在等待【任务完成 + delay】时间之后开始下一个任务
new ScheduledThreadPoolExecutor
public boolean remove(Runnable task)public void purge()public int getActiveCount()
ScheduledThreadPoolExecutor与Timer对比
- Timer 主要用于单线程,ScheduledThreadPoolExecutor 主要用于多线程
因此如果 Timer Task 任务用时过长,将影响其他任务 - 同时,Timer 不能捕获异常,因此 Timer Task 任务发生异常,将导致整个线程终止,进而导致其他任务也不能执行
- 从底层方面来看,Timer 只是实现了 Runnable 接口,而 ScheduledThreadPoolExecutor 还继承了 Future 类,所以 Timer 无法获取任务执行的结果,ScheduledThreadPoolExecutor 可以通过 Future 获取执行结果
异常
- 通常情况下,都会有这样的直观预测:如果异常在程序中被捕获,那么程序将会继续执行,如果没有在程序中捕获异常,那么程序将卡死(崩溃)
- 对于线程池,如果在程序中不进行异常捕获,那么在发生异常时,也会导致程序卡死,线程池中其他线程也无法执行
CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0,
Integer.MAX_VALUE,
60L,
TimeUnit.SECONDS,
new SynchronousQueue());
}
基本参数
-
corePoolSize = 0:核心线程为空,即缓冲线程池在没有任务的情况下,就没有线程存活,因此在线程池空闲时只有相当小的资源消耗
-
maximumPoolSize = Integer.MAX_VALUE:最大线程数为 int 的最大值
-
keepAliveTime = 60L:即空闲线程存活时间为 60 秒
-
缓冲线程池使用没有容量的 SynchronousQueue 作为阻塞队列,这也意味着,每出现一个任务,就将启用一个线程来执行任务,因此可能出现存活线程过多的情况,进而导致 CPU 耗尽
虽然缓冲队列没有容量,但是每当有任务提交时,还是会进行任务的出入队操作
线程执行流程
- 当任务被提交时,线程池先判断池中是否有空闲的存活线程,如果有,则取出空闲线程执行任务;如果没有空闲线程,则将创建一个线程
- 在任务完成之后,线程进入空闲状态,60 秒后,线程被结束回收;这 60 秒内如果有新的任务,则可能将这个线程取出用于执行任务
线程池和队列
队列的方法
放入数据
-
offer(E e):向队列中插入一个数据;如果队列有空闲,则直接插入数据并且返回 true,如果队列没有空闲,则直接丢弃 e 并且返回 flase;因此这个方法是非阻塞的(不会等待插入操作成功);如果 e == null,则抛出空指针异常offer(E o, long timeout, TimeUnit unit):向队列中插入一个数据;如果队列有空闲,则直接入队并返回 true,如果队列没有空闲,则方法进入阻塞态,并不断尝试入队,如果等待 timeout 时间后,还没有成功插入数据,则返回 false -
add(E e):底层调用 offer 方法,但是如果队列不空闲,则直接抛出异常 -
put(E e):向队列中插入一个数据,如果队列已满,则方法进入阻塞态,直到元素入队成功该方法处于阻塞态时,如果有其他线程为其设置中断标志,则该方法抛出中断异常并结束
取出数据
-
此处的取出数据与 pop 方法一致,指取出数据并将其从队列中移除
-
poll():在队列为空的情况下,将返回 nullpoll(long timeout, TimeUnit unit):在队列为空的情况下,阻塞线程并不断获取队首,如果在 timeout 的时间内都没有获取到队首,则返回 false -
take():与 add 方法一致,在队列为空的情况下,方法会一直阻塞,直到获取到队首或者被其他线程标记了中断标志,则方法将抛出异常并返回
-
drainTo():一次性 pop 若干个对象;drainTo 方法可以只加锁一次就获取多个对象,从某种程度上可以提升数据获取的效率
其他
remainingCapacity()contains(Object o)remove(Object o)size()
BlockingQueue
ArrayBlockingQueue - 基于数组的队列
- 因为基于数组,所以,队列有界,且在创建时需要指定其大小
- 出入队使用的同一个可重入锁,默认使用非公平锁;即当有出入队操作时,整个队列都会被上锁
- 从源码层面来看,ArrayBlockingQueue 的几乎所有方法都需要先获取一个独占锁 ReentrantLock,各个操作之间完全互斥
- 适用于吞吐量需求相对较低的场景
LinkedBlockingQueue - 基于链表的队列
- 因为基于链表,所以队列可以设置为无界(默认无界),但是如果在创建队列时就指定其大小,则它将变为有界队列,同时,它也不支持插入 null 值
- 因为使用链表实现队列,因此出队和入队可以分别使用两个不同的可重入锁;即出入队可以同时操作,因此它的吞吐量比 ArrayBlockingQueue 高
- 正如前文所述,无界的阻塞队列将使得线程一直维持 corePoolSize 的数量,新任务都放在阻塞队列中,因此 maximumPoolSize 将会失效
- 适用于任务之间相互独立的场景,如,瞬时大量的 Web 请求
PriorityBlockingQueue - 基于链表的优先级队列
-
和 LinkedBlockingQueue 类似,但是 PriorityBlockingQueue 内部会将队列中的对象进行排序,默认排序是对象的自然顺序,但是如果重写构造函数中的 Comparator 函数,则将根据 Comparator 进行排序
-
同时,也和 LinkedBlockingQueue 类似,PriorityBlockingQueue 使用了两个可重入锁进行同步,因此队列的出入队操作都需要竞争锁
-
理论上来讲,PriorityBlockingQueue 是无界的,但是当入队的元素过多,就可能因为资源耗尽导致 OOM
-
PriorityBlockingQueue 只在出队操作(poll、take、drainTo方法)时进行排序,直接使用迭代器(iterator)或可拆分迭代器(spliterator)获取到的元素是无序的,使用 peek 方法(队列获取但不删除队首元素的方法)也是未排序的
如果要获取排序后的队列元素,需要借助集合中的 Array.sort;先将队列元素转化为列表,然后排序
SynchronizedQueue
- 实际底层来看,队列无界,但是在使用时,体现出的大小为 0,每当有任务入队,则需要先等上一个队列出队,因此它不需要锁进行同步
- 以上是一种解释方法,也有解释方法认为,在任务过多,超过 maximumPoolSize 线程所能处理的情况时,SynchronizedQueue 提供了无界队列的可能性
- 通常情况下,当任务的数量 > maximumPoolSize 线程能够处理的数量时,线程池将拒绝任务
- 通常情况下,SynchronizedQueue 的吞吐量比 LinkedBlockingQueue 高
DelayedWorkQueue
- 重试队列,即在设定了 delay 值的队列中的任务,每经过 delay 的时间,就尝试获取一次资源,直到资源获取成功
- 可以设定任务获取资源失败次数的阈值,以进行其它的操作
线程池的执行过程
基本执行流程
其实线程池的执行流程在前文有所阐述,但是此处还是重新叙述一遍
- 初始化 corePoolSize 数量的核心线程等待使用
- 提交一个任务到线程池,如果有空闲的核心线程,则获取核心线程执行任务,如果没有空闲的核心线程,则将任务放入阻塞队列
- 如果阻塞队列也满了,则线程池将尝试创建新的线程来执行任务
- 如果线程池的线程数量已经达到 maximumPoolSize,则将触发饱和策略
线程池的结构
组成部分
- 线程池管理:负责管理线程池中的线程,主要包括线程的创建、分配与销毁
- 线程:即线程池中的线程
- 任务接口:即需要线程执行的任务,提供的一个能够被线程调用的接口
- 阻塞队列:超过核心线程能处理的任务,在阻塞队列中排队
类关系
-
Executor 是一个最顶层的接口,提供了 execute 方法执行任务
与之相关联的是 ExecutorCompletionService 接口,相关的实现接口是 CompletionService但是这个两个接口并不怎么重要,真的是这样吗QwQ -
ExecutorService 是继承 Execotor 的接口,提供了 submit、invokeAll、invokeAny、shutdown 等方法
-
ScheduleExecutorService 是继承 ExecutorService 的接口,主要提供定时任务的方法接口
-
AbstractExecutorService 是实现了 ExecutorService 接口的抽象类,默认的线程实现类 ThreadPoolExecutor 就继承自该抽象类
-
在以上基础上的 ScheduleThreadPoolExecutor 类,继承了 ThreadPoolExecutor 类,同时实现了 ScheduleExecutorService 接口,是周期性任务的实现类
-
在以上接口、实现类的基础上,还需要引入的关联接口及类如
Callable 接口 / Runnable接口:作为 submit 方法的参数
ScheduleFuture 接口:继承自 Future 接口和 Delay 接口,它的实现类作为定期调度任务的线程的参数
Executors 类:如 Collections 工具类一样,是线程池管理接口的工具类
线程池的状态
-
线程池被创建之后,就处于 RUNNING 状态,RUNNING 状态的线程池可以接受新任务,也会处理正在被执行的任务
在线程池创建时,会执行函数
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); -
如果对处于 RUNNING 状态的线程池执行了 shutdown 函数/命令,线程池将转为 SHUTDOWN 状态,此时的线程池不会再接受新的任务,但是已被添加的任务会继续执行
理解为,处于 SHUTDOWN 状态的线程池,只会处理当时正在执行的任务以及阻塞队列中的任务,而不会再往整个线程池系统中加新任务了
-
如果对处于 RUNNING 状态的线程池执行了 shutdownNow 函数/命令,线程池将转为 STOP 状态,此时线程池既不接受新的任务,正在执行的任务也会被中断
更别说队列中的任务了 -
如果 SHUTDOWN 状态的线程池处理完了所有任务(线程池和队列中都没有任务时),线程池转为 TIDYING 状态
如果 STOP 状态的线程池处理完了所有正在执行的任务(线程池中没有任务时),线程池转为 TIDYING 状态
TIDYING 状态表示线程池可以执行钩子函数 terminated,即线程结束时的处理函数,默认钩子函数是空函数,但是程序员可以对其进行重载
STOP 状态的线程池会中断任务的执行,大概是等待被中断任务结束吧
-
当钩子函数 terminated 执行完毕之后,线程池转为 TERMINATED 状态,表示线程池彻底被终止
饱和策略/拒绝策略
Example: corePoolSize = 3; maximumPoolSize = 5; sizeof(Queue) = 2;
.AbortPolicy
- 不执行任务且抛出异常
Example:当同时执行8个任务时,第8个任务将不被执行,并抛出异常 - 是线程池的默认饱和策略
.DiscardPolicy
-
不执行任务,但不抛出异常
Example:当同时执行8个任务时,第8个任务将会被直接丢弃
.DiscardOldestPolicy
- 丢弃队首的任务,一般来说,队首的任务就是最老的任务
因为这种策略的核心是舍弃最老的任务,所以不适用于具有优先级的队列 - Example:当同时执行8个任务,则排在队首的第6个任务会被舍弃
.CallerRunsPolicy
- 将任务返回给调用 execute 方法的线程
- Example:由 main 函数调用的 execute 方法,当同时执行8个任务时,第8个任务会被抛出到 main 函数中,由 main 函数线程执行
用户自定义饱和策略
- 是使用最多的方式
- 通过实现 RejectedExecutionHandler 自定义处理
线程池异常
引言
无法捕获到异常
- 首先需要确认的是,捕获异常是指在程序中能够捕获到异常
并不是在控制台中有异常信息的打印(应该只有我现在才理解到这个吧QAQ) - 捕获异常的目的在于处理异常
多线程环境下的异常
- 当某一个线程出现异常时,该线程被终止,但是对主线程和其他线程无影响,且感知不到异常线程的状态
- 只能使用 execute 执行任务,线程异常才能被捕获,使用 sbumit 提交的任务将被封装为 FutureTask,当发生异常时,Throwable 将捕获到 null
代码示例
class MyThread extends Thread {
private String name;
public MyThread(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(name + ":运行开始");
int i = 1 / 0;
System.out.println(name + ":运行结束");
}
}
public class Demo {
public static void main(String[] args) {
System.out.println("主线程开始");
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.execute(new MyThread("线程1"));
executor.shutdown();
System.out.println("主线程结束");
}
}
- 以上情况下,程序将无法捕获/处理异常,只会在控制台中打印异常
捕获异常的方案
Thread
- 使用自定义的 ThreadPoolExecutor 类,同时重写它的 afterExecute 方法
// 类定义
class MyThreadPoolExecutor extends ThreadPoolExecutor {
// 构造函数使用父类ThreadPoolExecutor的构造函数
public MyThreadPoolExecutor(/*parameters*/) {
super(/*parameters*/);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
/*异常处理*/
}
}
Runnable + execute
-
自定义 ThreadPoolExecutor 类,使其实现 Thread.UncaughtExceptionHandler 接口的 uncaughtException 方法
同时自定义 ThreadFactory 类,指定其异常回调函数
其过程大致为:
I. 定义一个实现了 Thread.UncaughtExceptionHandler 接口的类,这个类将作为回调函数,参与异常处理
II. 声明一个单线程线程池 exec
III. 传入线程池的参数是一个 Thread 对象,它通过 ThreadFactory 工厂类,匿名实现,其中声明了 Thread 的子类实例,同时声明异常回调函数
// ThreadPoolExecutor的实现略
// 调用
ExecutorService exec = Executors.newSingleThreadExecutor(new ThreadFactory(){
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setUncaughtExceptionHandler(new MyUncheckedExceptionHandler()); // 设置捕获异常后的回调函数
return thread;
}
});
-
使用默认的 handler 函数
核心思想依然是实现 Thread.UncaughtExceptionHandler 接口
然后通过Thread.setDefaultUncaughtExceptionHandler设置回调函数
Thread.setDefaultUncaughtExceptionHandler(new MyUncheckedExceptionHandler());
Callable + submit
- 由于 submit 提交的任务返回的异常为 null,因此想要捕获 submit 的异常,需要更深层的异常判断
- 其核心依然是自定义 Thread 类并重写 afterExecute 方法
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
if (r instanceof Thread) {
if (t != null) {
/*捕获到来自execute命令后的异常处理*/
}
} else if (r instanceof FutureTask) {
FutureTask futureTask = (FutureTask) r;
try {
futureTask.get();
} catch (InterruptedException e) {
/*捕获到来自submit命令后的异常处理*/
} catch (ExecutionException e) {
/*捕获到来自submit命令后的异常处理*/
}
}
}
submit 与 execute
概述
- execute 和 submit 提交的任务都会被 Runnable 封装
- execute 的任务最后被封装为 Worker 对象,在 Worker 对象中执行 run 方法,如果执行中出现了异常,将被 try - catch 住并将异常抛出,因此程序员能在外界捕获到异常
- submit 的任务最后被封装为 FutureTask,在 FutureTask 中的 run 方法进行了异常处理,try - catch 到的异常不会被抛出,只会将异常放进 Object 类型的 outcome 中,返回的 Throwable 为 null
因此在以上 Callable + submit 的组合中,使用 instanceof 来判断被封装后的对象,如果是 FutureTask,则使用 .get 方法获取异常
类库
SimpleDateFormat
引言
- SimpleDataFormat 是 Java 提供的一个时间类
常用方法
dateFormat.parse("2016-12-18 15:00:34");以时间格式打印时间
new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");实例化一个 SimpleDataFormat 并设置它的时间输入格式
线程不安全的原因
-
在 SimpleDataFormat 内部,存在一个 Calendar 对象,这个对象保存了基本的时间信息以及 SimpleDataFormat 需要的一些附加信息
-
如果多个线程共享同一个 SimpleDataFormat 对象,则它们也共享同一个 Calendar 对象,那么则可能出现,线程访问到一个已经被 clear 的 Calendar 对象,导致报错
理解为,当 SimpleDataFormat 进行时间访问时,需要访问 Calendar 对象,访问完成后,要进行 clear
final DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Callable<Date> task = new Callable<Date>() {
public Date call() throws Exception {
return dateFormat.parse("2016-12-18 15:00:34");
}
};
线程安全方案
局部变量
- 如上述代码所示,多个线程将在 task 中使用同一个 SimpleDataFormat,因此导致线程不安全
- 则可以使用局部变量,在 task 声明局部 SimpleDataFormat,在它的生命周期结束后,它将会被回收
- 但是使用局部变量将增加开销
synchronized
- 对上述代码块
return dateFormat.parse("2016-12-18 15:00:34");加上 synchronized 达到线程同步这很好理解 - 但是使用 synchronized 的性能比较差
ThreadLocal
- 如前文所述,ThreadLocal 为每个线程单独维护一个变量副本,使得线程隔离
class DateFormatThreadSafe {
public static final ThreadLocal<DateFormat> THREAD_LOCAL
= new ThreadLocal<DateFormat>() {
@Override // SimpleDataFormat的弱引用【大概】
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
}
};
}
Callable<Date> task = new Callable<Date>() {
public Date call() throws Exception {
DateFormat dateFormat = DateFormatThreadSafe
.THREAD_LOCAL
.get(); // 获取线程信息
return dateFormat.parse("2016-12-18 15:00:34");
}
};
- ThreadLocal 的作用方式更类似于局部变量,但是比局部变量更高效
替代类结构
Instant 代替 Data
LocalDataTime 代替 Calendar
DataTimeFormatter 代替 SimpleDataFormat
- DataTimeFormatter 的所有字段都使用了 final 关键字,因此线程安全
应用场景
Spring boot 多线程
JUC - java.util.concurrent
引言
- java.util.concurrent 包提供了一个实现了 Lock 接口的 ReentrantLock 类,ReentrantLock 实现的功能基本与 synchronized 一致,但是在 synchronized 的基础上还增加了一些功能
- 常用的接口方法如下
.locks and .unlock
- .locks() 方法将获取一个锁,.unlock() 方法将释放一个锁
- 一般使用 try 语句包裹数据操作的语句,在 finally 语句中进行锁的释放
private Lock lock = new ReentrantLock(); // 声明锁
public void subMoney(int money) {
lock.lock();
try{
if (count - money < 0) {
return;
}
count -= money;
}finally{
lock.unlock();
}
}
- 但是和 synchronized 相比,使用 concurrent 包具有更高的并发性能,但是 CPU 占用高,且需要手动释放锁,因此在代码过程中需要考虑死锁问题
- ReentrantLock 可重入锁,即线程对锁进行加锁后,还可以对其进行加锁,相对应的,也应该有相应数量的锁释放
CAS - Compare And Swap
引言
- CAS 是 JUC 的基石,在 Java 多线程并发操作中,CAS 是不可或缺的基础
- CAS 性能很高,适合高并发场景
- 在很多组件中也使用了 CAS,如
ConcurrentHashMap 的线程安全由 CAS + synchronized 实现
AQS同步组件【将在下文中进行具体阐述】
Atomic 原子操作
原理
- CAS 基于乐观锁,通过不断自旋等待获取资源,因此性能很高
- CAS 操作包含3个操作数,即内存位置(V)、预期原值(A)、新值(B)
- 当从内存中取得的值与预期原值相同时,就将内存中的原值更新为新值
如果从内存中取得得值与预期原值不同,则进行自旋,直到两个值相同,然后再将内存中的值进行更新
优点
- 性能高
缺点
-
CPU 占用高,当 CAS 自旋时间(次数)过长,则导致 CPU 占用过高
可以设置一个自旋次数的阈值,当自旋次数超过该阈值时,就停止自旋
BlockingQueue 中的 SynchronousQueue 就采用了这种方式 -
ABA 问题,由于 CAS 根据内存中的值是否与预期原值一致来判断是否有线程冲突的,因此内存中的值发生 A–B–A 变化时,CAS 将检测到没有线程冲突,但是大部分情况下,这并不影响执行结果
如果想要避免 ABA 问题,可以为单值设置一个版本号,每次发生值修改时,版本号自加,根据这种理念,Java 提供了 AtomicStampedReference 来解决 ABA 问题,其提供了一个
[E, Integer]元组,表示单值和对应的版本号 -
只能作用于单值,如上所述,CAS 只能实现单值的线程安全,如果需要保证整个操作或是代码块的原子性,则使用 Synchronized 关键字,或者使用 AtomicStampedReference 包裹多个变量
AQS - AbstractQueueedSynchronizer
引言
- AQS 是一个抽象的队列式同步器,主要作用是实现线程调配(线程同步)
同时它也是除了 synchronized 关键字之外的锁机制 - CLH:Craig,Landin,and Hagersten,即虚拟双向循环队列,是 AQS 中的 Queue,但是实际上 CLH 并没有真正地实现一个双向循环队列,它只是声明了各个任务结点之间的关系
- AQS 实现的原理可以这样理解:线程被封装后,按照双向循环队列的结构进行排队,所有线程封装对象都以 CAS 的方式竞争一个被 volatile 修饰的 state 共享值,如果竞争成功,则该对象成功获取锁,唤醒线程,开始活动,其他对象则继续进行自旋,而线程继续等待被唤醒
关于 state 的3种访问方式
- getState():获取共享资源 state 的值
- setState(E e):修改共享资源 state 的值为 e
- compareAndSetState(E old_v, E new_v):比较 state 的值是否为 old_v,如果是,则将 state 的值修改为 new_v
setState 与 compareAndSetState 的重要区别在于:
二者在线程安全层面来说,setState 是获取了资源之后,再进行修改,整个过程具有原子性,而 compareAndSetState 是在获取锁之前就尝试进行修改,为了保证原子性,则需要使用 CAS
两种资源共享的方式
- 独占式 - Exclusive:同时只能有一个线程使用资源,如:ReentrantLock
- 共享式 - Share:资源可以同时被多个线程使用,如:Senaphore等
自定义实现同步器
- 自定义实现同步器的核心是实现了模板方法模式,程序员一般只自定义实现资源的获取及释放部分,而具体线程调用和同步的细节由 AbstractQueuedSynchronizer 规定的方法实现
- 一般来说,自定义实现的同步器,要么是独占的,要么是共享的,即tryAcquire-tryRelease 和 tryAcquireShared-tryReleaseShared 选其一实现,但是也可以都实现,如 ReentrantReadWriteLock
- 常见的被实现的自定义方法如:
- isHeldExclusively():该线程是否正在独占资源
- tryAcquire(int):尝试获取资源,如果获取成功,则返回 true,该方法是独占的
- tryRelease(int):尝试释放资源,如果释放成功,则返回 true,该方法是独占的
- tryAcquireShared(int):尝试获取资源,如果获取失败,则返回负数,如果获取资源功能后,没有空闲资源了,则返回0,如果获取资源之后,还有空闲资源,则返回剩余空闲资源的数量,该方法是共享的
- tryReleaseShared(int):尝试释放资源,如果资源释放成功,且允许后续结点被唤醒,则返回 true,否则返回 false
CountDownLatch
- CountDownLatch 和 ReentrantLock 类似,都是采用了 AQS 的方式实现的锁,但是 CountDownLatch 是共享锁,即多个线程共享资源 state
- 在锁初始化时,state 初始化为共享锁的线程数量,如:CountDownLatch 将被 3 个线程共享,则 state 初始化为 3
- 当有线程需要占用锁时,state 进行自减,当 state 自减为 0 时,将通知主线程 (
unpark()函数),主线程将从wait()函数返回,进行后续操作
ReentrantLock
根据 AQS 对可重入锁的解释
- 首先需要明确的是,ReentrantLock 是锁的类型,锁的获取及释放操作依据 AQS 进行
- 锁初始化时,state 初始化为 0;
当线程需要获取锁时,将独占式调用 tryAcquire 函数获取锁,如果获取成功,state 将进行自加;
当线程释放锁时,则独占式调用 tryRelease 方法,并对 state 自减 - 在线程占用锁的过程中,如果该线程重复进行了 tryAcquire 方法,则 state 进行累加(自加),释放锁时,也需要进行 state 次的自减和 tryRelease 操作
公平锁/非公平锁
- ReentrantLock 默认使用的是非公平锁,即,多个线程获取锁时,后来的线程可能先获取到锁
- ReentrantLock 也可以实现公平锁,即线程按照队列的结构排列,先来的线程先获得锁
// ReentrantLock的两个构造函数
public ReentrantLock() {
sync = new NonfairSync();
}
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
// 非公平锁的lock方法
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
// 公平锁的lock方法
final void lock() {
acquire(1);
}
// acquire方法
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
- 由上可知,非公平锁的 lock 方法在 acquire 之前,尝试使用了 CAS 方法compareAndSetState,这使得当 state 一旦为 0,线程就可以尝试使用 .lock 函数获取 state 资源,然后再进行获取锁操作和线程唤醒操作
- 这使得当上一个线程刚刚释放完锁,state = 0,此时新到的线程就将直接抢占 state,而排队的线程还未被唤醒,出现"插队"
非公平锁 .lock 的底层原理
-
由非公平锁的 .lock 方法可知,未竞争到资源的线程将执行 acquire 方法,而 acquire 方法的核心是 tryAcquire() 和 acquireQueued()
-
tryAcquire() 方法即尝试获取资源,其底层为 nonfairTryAcquire 函数
其实现的功能为:当检测到 state = 0,则占用 state 资源(锁),并返回 true;当检测到 state ≠ 0,并且该资源正被当前线程占用,则 state 自加,并返回 true;否则,返回 false -
acquireQueued() 方法的目的是,将当前线程放入队列,并在某种条件成立时,将线程挂起
-
首先是 acquireQueued() 方法的参数,addWaiter(Node.EXCLUSIVE) 使线程入队,如果当前队列还未创建(初始化),则需要入队的线程进行 CAS 竞争锁,完成队列创建,可以将队列理解为一个具有头结点的循环双向链表结构
-
当所有线程入队之后,处在 head 结点之后的第一个结点(即队首后紧接的结点)将会尝试获取锁,如果线程一直不能获取锁(包括队列中其他的线程),则线程尝试挂起
-
线程挂起的条件为,
shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()均为真,其具体含义是
I. 如果当前节点的前驱结点处于 SIGNAL 状态,shouldParkAfterFailedAcquire 为真;
或者,如果前驱结点处于 CANCELLED 状态,然后往前遍历直到出现非 CANCELLED 状态的结点,则将当前结点插入该结点之后,并将该结点的状态设为 SIGNAL,shouldParkAfterFailedAcquire 为真;II. 线程挂起操作成功,则 parkAndCheckInterrupt 为真;
-
SIGNAL 状态即:当该线程完成操作之后,释放锁时,会唤醒它的后继结点线程
非公平锁 .unlock 的底层原理
- 如果占用锁的不是当前线程,则直接抛出异常
- 如果占用锁的是当前线程,则释放锁,并使 state 自减,如果 state 自减后为 0 ,则释放锁成功,并清空独占线程,返回 free
- 释放锁成功后,如果当前线程结点的状态为 SIGNAL ,则唤醒后继结点的线程
- 如果 state 自减后不为 0,则释放锁失败
可轮询与可中断
-
与 synchronized 关键字相比,ReentrantLock 的显著优点就在于可轮询与可中断,它使得超时机制得以实现
-
在 ReentrantLock 中的超时任务通过 tryLock 方法实现,其功能是浅显的,如果超过一定时间还未成功获取锁,则退出任务
但是它底层的运行流程是,先和非超时任务一致,入队,然后进行自旋,如果自旋结束后还未获取到锁,则将线程结点挂起,挂起的时间超过某值时,线程退出,返回 false
其他
以上只是从大方向阐述了公平锁、非公平锁的底层原理,更加细致的说明见
Java–ReentrantLock的用法和原理
原子类 - atomic
基本类型
- AtomicBoolean(底层的实现方式是将 boolean 转为 int 进行运算)
- AtomicInteger
- AtomicLong
基本原子类常用方法
<T> addAndGet(<T> delta):使实例中的值加上 delta ,返回相加的和boolean compareAndSet(<T> expect, <T> update):如果实例中的值与 expect 相等,则将实例中的值更新为 update,并返回 true,否则返回 false<T> getAndIncrement():返回原值再自增,等价于 obj++;void lazySet(<T> newValue):某段时间之后,将实例中的值更新为 newValue<T> getAndSet(<T> newValue):返回原值并将实例的值设置为 newValue
其他说明
- 原子类的实现方式是 CAS ,它在运算方面,和常用的类一致,它只是从设计方面向程序员保证:该运算是原子性性的
- 如下,使用 AtomicLong,在多线程场景下,自增操作具有原子性,得到结果是依次自增的
class Counter implements Runnable{
private static AtomicLong atomicLong = new AtomicLong(0);
@Override
public void run() {
System.out.println(atomicLong.incrementAndGet());
}
}
public class Demo {
public static void main(String[] args) throws InterruptedException {
Counter[] threads = new Counter[50];
for(int i = 0; i < 50; i++){
threads[i] = new Counter();
}
for(int i = 0; i < 50; i++){
new Thread(threads[i]).start();
}
}
}
原子更新引用类型
AtomicMarkableReference<String> atomicRef = new AtomicMarkableReference<>(obj, bool);
boolean updated = atomicRef.compareAndSet(obj, new_obj, bool, new_bool);
- 原子更新引用类型的思想类似于:用原子类包裹引用类型,像在引用类的方法上加 synchronized 一样,使得引用类的方法具有原子性
- AtomicReference:原子更新引用类型,是最基础的包裹引用类型的原子类
- AtomicStampedReference:带有时间戳的原子更新引用类型,因为带有时间戳,可以避免 ABA 问题
- AtomicMarkableReference:在原子类的构造函数中构造一个
<Boolean, Object>的键值对,可以使用 compareAndSet 方法对原子类中的实例进行更新
原子更新数组
- 与其他的原子更新类相似,使用原子类包裹数组,使得对呀数组中元素的操作具有原子性
- AtomicIntegerArray:原子更新整型数组里的元素
- AtomicLongArray:原子更新长整型数组里的元素
- AtomicReferenceArray:原子更新引用类型数组里的元素
需要注意的是,原子类实例化时,放入原子类中的数组其实是原数组的拷贝,当使用原子类更新数组时,原数组不发生变化,如下
public class Demo {
static int[] value =new int[]{1,2};
static AtomicIntegerArray ai =new AtomicIntegerArray(value);
public static void main(String[] args) {
ai.getAndSet(0,2);
System.out.println(ai.get(0)); // 2
System.out.println(value[0]); // 1
}
}
原子更新字段
- AtomicReferenceFieldUpdater:原子更新引用类型的字段
- AtomicIntegerFieldUpdater:原子更新整型的字段的更新器
- AtomicLongFieldUpdater:原子更新长整型字段的更新器
- AtomicStampedFieldUpdater:原子更新带有版本号的引用类型
// 创建一个更新器,并且设置需要原子更新的字段
private static AtomicIntegerFieldUpdater<User> ai = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
System.out.println(ai.getAndIncrement(User_obj));
- 能够被原子更新的字段需要是 public volatile 属性的
可以理解为 AtomicReferenceFieldUpdater 包含了原子更新器
JDK 1.8 更新的原子运算器
-
DoubleAccumulator、LongAccumulator、DoubleAdder、LongAdder
-
其核心思想是,由原子类包裹运算规则,实现原子性
private static LongAccumulator accumulator1 = new LongAccumulator((x, y) -> x+y, 0);private static LongAccumulator accumulator2 = new LongAccumulator((x, y) -> x*y, 1); -
xxxAdder 可以理解为 xxxAccumulator 的一部分,但是在高并发场景下 Adder 的性能会更高;二者的性能都比之前 Aotmicxxx 的性能高,因为二者都只是使用了 CAS 的思想,而没有使用 Unsafe 的 CAS 算法
-
并发场景下使用 sum 方法,可能导致计数不准
CompletableFuture
再次声明
【本文参考了很多文章,部分图片及代码片段也取自参考文章,如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
【如果构成侵权,请联系我进行修改/删除】
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









