







Hadoop分布式集群搭建
环境说明:
Hadoop分布式集群架构是主从架构,这里要搭建一个3台服务器的集群
三台centos7主机,其中一个主节点master,两个从节点服务器slave
用户名都为root,主机名分别为master,slave1,slave2
步骤如下:
1.安装CentOS7
-
- 创建虚拟机
单击左上角文件→新建虚拟机,创建虚拟机

-
- 选择指定的Centos7系统镜像文件

-
- 填写虚拟机信息


-
- 默认一直下一步即可,之后点击完成系统会自动重启,等待安装

-
- 安装完成,进行登入

出现此界面,说明安装成功

2.配置master主机
更改主机名为master

date命令查看时间,发现时间不同步
同步时间
方法1:进入root用户,执行以下命令

配置防火墙设置
查看防火墙状态:
systemctl status firewalld.service

关闭防火墙
systemctl stop firewalld.service

开机禁用防火墙
systemctl disable firewalld.service
配置selinux设置
查看selinux状态
getenforce
临时关闭selinux
setlinux 0

永久关闭
vim /etc/sysconfig/selinux
更改内容为SELINUX=disable
![]()

3.配置salve主机
将刚配置好的master节点通过VMware克隆两台主机

. 
4. master网络配置
先查看本机的网关地址,这里网关为192.168.111.2

配置网络ip(三台主机要配置不同的ip)
vim /etc/sysconfig/network-scripts/ifcfg-ens33

使用 service network restart 命令重启网络
service network restart
设置完master主机的网络之后,随即配置两台slave的网络
这里我将ip网络配置为
master 192.168.111.100
slave1 192.168.111.101
slave2 192.168.111.102
根据自己的网络IP进行配置
.
5.slave1网络配置
同master方法一致

6.slave2网络配置

7.配置hosts
三台机器都要进行配置IP地址和主机的映射关系
vim /etc/hosts

将IP地址和主机名相映射,目的是为了方便三台主机相互通信
能够相互ping通即可

8.配置三台主机的免密登录

可以看出每次要与slave建立连接每次都需要输入密码,则需要配置ssh免密登录操作
依次执行以下命令
ssh-keygen -t rsa #然后按四下回车
cd .ssh #进入ssh目录
cat id_rsa.pub >> authorized_keys #将master密钥追加authorized_keys文件中
将master的authorized_keys复制到slave1中,以下命令完成
scp authorized_keys root@slave1:/root/.ssh/ authorized_keys
scp authorized_keys root@slave2:/root/.ssh/ authorized_keys
配置好效果如下

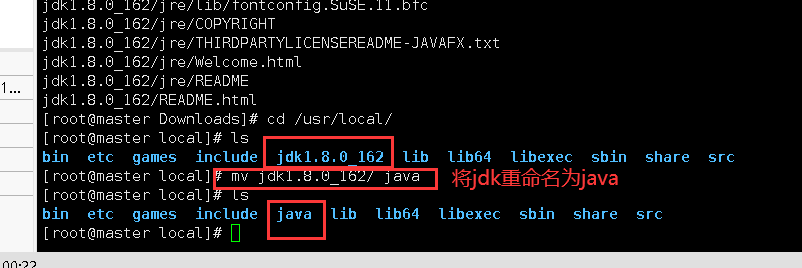
9.安装Java环境和Hadoop前提准备
进入jdk和hadoop官网,在分别下载好Linux版的压缩包
yum -y install lrzsz #安装lrzsz,用于文件的上传下载
通过xshell远程连接,输入rz -E命令将本地下载好的jdk和hadoop文件压缩包上传至服务器master
rz -E

查看文件是否上传成功
10.安装并配置Java环境
(三台机器都需要)
删除原有的jdk
查询系统是否已安装java
rpm -qa | grep java
如果存在,删除卸载
yum remove jdk名称
验证是否还存在jdk
java -version
出现以下情况说明卸载完成

使用tar解压命令对jdk进行解压
tar -zxvf jdk-8u162-linux-x64.tar.gz -C /usr/local/

Java环境变量的配置
进入root家目录,编辑.bashrc配置文件
命令:vim ~/.bashrc
vim ~/.bashrc

配置完之后,ESC+:wq保存退出
使用source ~/.bashrc命令使配置好的环境变量立即生效
source ~/.bashrc
依次使用java,javac,java -version命令检查是否安装成功

将配置好的java拷贝到两台slave上
使用scp命令
scp -r /usr/local/java/ root@slave1:/usr/local
scp -r /usr/local/java/ root@slave2:/usr/local
分别在slave1和slave2检验java环境是否配置好
11.安装并配置Hadoop
将下载好的hadoop压缩文件进行解压
我们的hadoop压缩文件放在Downlodas
解压
tar -zxvf Downloads/hadoop-3.1.3.tar.gz -C /usr/local

同java配置环境一样,对hadoop进行配置
vim ~/.bashrc

配置完成进行source命令使其生效
source ~/.bashrc
之后使用hadoop version查看是否安装成功
hadoop version

修改文件workers
将之前的内容localhost改成slave1和slave2

修改文件core-site.xml
请把core-site.xml文件修改为如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>

修改文件hdfs-site.xml
对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。但是,这里只有两个Slave节点作为数据节点,即集群中只有两个数据节点,数据保存两份,所以 ,dfs.replication的值还是设置为 2。hdfs-site.xml具体内容如下:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>

修改文件mapred-site.xml
“/usr/local/hadoop/etc/hadoop”目录下有一个mapred-site.xml.template,需要修改文件名称,把它重命名为mapred-site.xml,然后,把mapred-site.xml文件配置成如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
修改文件 yarn-site.xml
请把yarn-site.xml文件配置成如下内容:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

将Hadoop分发至各个节点
上述5个文件全部配置完成以后,需要把master节点上的“/usr/local/hadoop”文件夹复制到各个节点上。如果之前已经运行过伪分布式模式,建议在切换到集群模式之前首先删除之前在伪分布式模式下生成的临时文件。具体来说,需要首先在master节点上执行如下命令:
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz slave1:/root/hadoop
scp ./hadoop.master.tar.gz slave1:/root/Hadoop

在两台slave中解压hadoop至/usr/local下
tar -zxvf hadoop -C /usr/local
再将master上配置好的.bashrc文件一并分发给slave上,并分在slave1和slave2使用source命令使其生效
之后分别在slave1和slave2依次执行java -version和hadoop version命令,检验是否安装并配置成功.


准备启动Hadoop
第一次完成安装配置需要在master使用hdfs namenode -format命令进行格式化,之后启动hadoop不需要再进行格式化操作
依次使用以下命令启动Hadoop服务
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
启动完成使用jps查看进程,分别在三台服务器jps查看进程
通过命令jps可以查看各个节点所启动的进程。如果已经正确启动,则在master节点上可以看到NameNode、ResourceManager、SecondrryNameNode和JobHistoryServer进程,如下图所示。在slave节点可以看到DataNode和NodeManager进程,如下图所示。

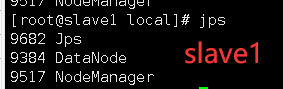

缺少任一进程都表示出错。另外还需要在master节点上通过命令“hdfs dfsadmin -report”查看数据节点是否正常启动,如果屏幕信息中的“Live datanodes”不为 0 ,则说明集群启动成功。由于本教程只有1个Slave节点充当数据节点,因此,数据节点启动成功以后,会显示如下图所示信息。
hdfs dfsadmin -report


也可以在Linux系统的浏览器中输入地址“http://master:9870/”,通过 Web 页面看到查看名称节点和数据节点的状态。

出现的问题
配置好静态ip重启网络出现
Job for network.service failed because the control process exited with error code. See "systemctl status network.service" and "journalctl -xe" for details.
解决方案
systemctl stop NetworkManager
systemctl disable NetworkManager
然后再重启命令就可以了
出现右上角没有网络图标
解决:
依次执行以下命令
mv /var/lib/NetworkManager /var/lib/NetworkManager.bak
systemctl stop NetworkManager
systemctl start NetworkManager
启动Hadoop出错
[root@master ~]# start-dfs.sh
Starting namenodes on [master]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [master]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.

解决方法:
在Hadoop安装目录下找到sbin文件夹
在里面修改四个文件
对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
vim start-dfs.sh
vim stop-dfs.sh
添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
vim start-yarn.sh
vim stop-yarn.sh
添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root修改完成后复制到slave上

再重新启动Hadoop
在 master主机上远程拷贝 /etc/hosts 文件到 slave1 主机上,出现下面的错误提示:
Permission denied, please try again.
解决方法
sudo gedit /etc/ssh/sshd_config
注释掉 PermitRootLogin without-password,添加 PermitRootLogin yes:
# PermitRootLogin without-password
PermitRootLogin yes 保存,退出
重启 ssh 服务
sudo service ssh restart
出现权限问题
visudo:编辑sudo命令的配置
编辑第98行
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
用户名 登录的主机=(以什么样的身份运行) 可以执行什么命令
如果想让ghh用户也居于root相关权限。。
ghh ALL=(root) NOPASSWD:service iptables status
ghh ALL=(root) NOPASSWD:service iptables start
推荐用法
ghh ALL=(root) NOPASSWD:ALL
















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











