






目录
高级客户端
环境准备
创建Maven项目ElasticSearch-Demo
导入依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.2.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--引入es的坐标-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.4.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.4</version>
</dependency>
</dependencies>① 在 resource 文件夹下面创建 application.yml 文件
elasticsearch:
host: 127.0.0.1
port: 9200② 创建启动类
package com.Zh;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author OZH
* @Description:
* @date 2022/1/24 10:03
*/
@SpringBootApplication
public class ElasticsearchDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ElasticsearchDemoApplication.class, args);
}
}
创建配置类
package com.Zh.Config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
/**
* @author OZH
* @Description:
* @date 2022/1/24 10:06
*/
@SpringBootConfiguration
@ConfigurationProperties(prefix = "elasticsearch")//这个会把yml里面的值注入
public class ElasticSearchConfig {
private String host;
private int port;
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public int getPort() {
return port;
}
public void setPort(int port) {
this.port = port;
}
@Bean
public RestHighLevelClient client() {
return new RestHighLevelClient(RestClient.builder(new HttpHost(host, port)));
}
}
创建测试类ElasticsearchTest
package com.Zh.test;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
/**
* @author OZH
* @Description:
* @date 2022/1/24 10:13
*/
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElasticsearchTest {
@Autowired
RestHighLevelClient restHighLevelClient;
@Test
public void contextLoads() {
System.out.println(restHighLevelClient);
}
}
运行

环境搭好了
索引操作
创建一个索引
//创建一个索引
@Test
public void createIndex() throws IOException {
IndicesClient indicesClient = client.indices();
//1.创建请求对象
CreateIndexRequest request = new CreateIndexRequest("twitter");
//2.执行同步请求创建索引
// RequestOptions.DEFAULT 默认请求头信息
CreateIndexResponse createIndexResponse = indicesClient.create(request, RequestOptions.DEFAULT);
//打印结果,用插件可以看到twitter这个索引库已经创建了
boolean acknowledged = createIndexResponse.isAcknowledged();
boolean shardsAcknowledged = createIndexResponse.isShardsAcknowledged();
System.out.println("acknowledged="+acknowledged);
System.out.println("shardsAcknowledged="+shardsAcknowledged);
}
添加索引和映射

/**
* 添加索引和映射
*/
@Test
public void addIndexAndMapping() throws IOException {
//1.使用client获取操作索引的对象
IndicesClient indicesClient = client.indices();
//2.具体操作,获取返回值
CreateIndexRequest createRequest = new CreateIndexRequest("aaa");
//2.1 设置mappings
String mapping = "{\n" +
" \"properties\" : {\n" +
" \"address\" : {\n" +
" \"type\" : \"text\",\n" +
" \"analyzer\" : \"ik_max_word\"\n" +
" },\n" +
" \"age\" : {\n" +
" \"type\" : \"long\"\n" +
" },\n" +
" \"name\" : {\n" +
" \"type\" : \"keyword\"\n" +
" }\n" +
" }\n" +
" }";
createRequest.mapping(mapping, XContentType.JSON);
CreateIndexResponse response = indicesClient.create(createRequest, RequestOptions.DEFAULT);
//3.根据返回值判断结果
System.out.println(response.isAcknowledged());
}查询索引
@Test
public void queryIndex() throws IOException {
IndicesClient indicesClient = client.indices();
GetIndexRequest getReqeust = new GetIndexRequest("aaa");
GetIndexResponse response = indicesClient.get(getReqeust, RequestOptions.DEFAULT);
//获取结果
Map<String, MappingMetaData> mappings = response.getMappings();
for (String key : mappings.keySet()) {
System.out.println(key+":" + mappings.get(key).getSourceAsMap());
}
}删除索引
@Test
public void deleteIndex() throws IOException {
IndicesClient indicesClient = client.indices();
DeleteIndexRequest deleteRequest = new DeleteIndexRequest("aaa");
AcknowledgedResponse response = indicesClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}判断索引是否存在
@Test
public void existIndex() throws IOException {
IndicesClient indicesClient = client.indices();
GetIndexRequest getRequest = new GetIndexRequest("aaa");
boolean exists = indicesClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}文档操作
Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。
添加文档,使用map作为数据
/**
* 添加文档,使用map作为数据
*/
@Test
public void addDoc() throws IOException {
//数据对象,map
Map data = new HashMap();
data.put("address","广东xxx");
data.put("name","张三");
data.put("age",20);
//1.获取操作文档的对象
IndexRequest request = new IndexRequest("aaa").id("2").source(data);
//添加数据,获取结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//打印响应结果
System.out.println(response.getId());
}添加文档,使用对象作为数据
/**
* 添加文档,使用对象作为数据
*/
@Test
public void addDoc2() throws IOException {
//数据对象,javaObject
Person p = new Person();
p.setId("3");
p.setName("李四");
p.setAge(30);
p.setAddress("中国某个城市");
//将对象转为json
String data = JSON.toJSONString(p);
//1.获取操作文档的对象
IndexRequest request = new IndexRequest("aaa").id(p.getId()).source(data,XContentType.JSON);
//添加数据,获取结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//打印响应结果
System.out.println(response.getId());
}修改文档:添加文档时,如果id存在则修改,id不存在则添加
@Test
public void updateDoc() throws IOException {
//数据对象,javaObject
Person p = new Person();
p.setId("3");
p.setName("修改的名字");
p.setAge(30);
p.setAddress("修改的地址");
//将对象转为json
String data = JSON.toJSONString(p);
//1.获取操作文档的对象
IndexRequest request = new IndexRequest("aaa").id(p.getId()).source(data,XContentType.JSON);
//添加数据,获取结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
//打印响应结果
System.out.println(response.getId());
}根据id查询文档
@Test
public void findDocById() throws IOException {
GetRequest getReqeust = new GetRequest("aaa","1");
//getReqeust.id("1");
GetResponse response = client.get(getReqeust, RequestOptions.DEFAULT);
//获取数据对应的json
System.out.println(response.getSourceAsString());
}根据id删除文档
@Test
public void delDoc() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("aaa","1");
DeleteResponse response = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(response.getId());
System.out.println(response.getResult());
}批量操作 bulk
Bulk 批量操作是将文档的增删改查一些列操作,通过一次请求全都做完。减少网络传输次数。
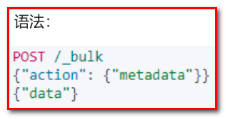
GET person/_search
# 批量操作
# 1 删除1号记录
# 2 添加8号记录
# 3 修改2号记录 名称为二号
POST _bulk
{"delete":{"_index":"person","_id":"1"}}
{"create":{"_index":"person","_id":"8"}}
{"name":"8号","age":80,"address":"北京"}
{"update":{"_index":"person","_id":"2"}}
{"doc":{"name":"2号"}}
java代码
/**
* 1. 批量操作 bulk
*/
@Test
public void testBulk() throws IOException {
//创建bulkrequest对象,整合所有操作
BulkRequest bulkRequest = new BulkRequest();
/*
1. 删除1号记录
2. 添加6号记录
3. 修改3号记录 名称为 “三号”
*/
//添加对应操作
//1. 删除1号记录
DeleteRequest deleteRequest = new DeleteRequest("person","1");
bulkRequest.add(deleteRequest);
//2. 添加6号记录
Map map = new HashMap();
map.put("name","六号");
IndexRequest indexRequest = new IndexRequest("person").id("6").source(map);
bulkRequest.add(indexRequest);
Map map2 = new HashMap();
map2.put("name","三号");
//3. 修改3号记录 名称为 “三号”
UpdateRequest updateReqeust = new UpdateRequest("person","3").doc(map2);
bulkRequest.add(updateReqeust);
//执行批量操作
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
RestStatus status = response.status();
System.out.println(status);
}批量导入MySQL到ES中
将数据库中Goods表的数据导入到ElasticSearch中
① 将数据库中Goods表的数据导入到ElasticSearch中
② 创建索引
Kibanan控制台操作
PUT goods
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart"
},
"price": {
"type": "double"
},
"createTime": {
"type": "date"
},
"categoryName": {
"type": "keyword"
},
"brandName": {
"type": "keyword"
},
"spec": {
"type": "object"
},
"saleNum": {
"type": "integer"
},
"stock": {
"type": "integer"
}
}
}
}# 查询索引
GET goods
- title:商品标题
- price:商品价格
- createTime:创建时间
- categoryName:分类名称。如:家电,手机
- brandName:品牌名称。如:华为,小米
- spec: 商品规格。如: spec:{“屏幕尺寸”,“5寸”,“内存大小”,“128G”}
- saleNum:销量
- stock:库存量
添加文档数据
POST goods/_doc/1
{
"title":"小米手机",
"price":1000,
"createTime":"2019-12-01",
"categoryName":"手机",
"brandName":"小米",
"saleNum":3000,
"stock":10000,
"spec":{
"网络制式":"移动4G",
"屏幕尺寸":"4.5"
}
}
# 查询文档数据
GET goods/_search
添加依赖坐标
<!--mybatis-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>添加 application.yml 配置文件
# datasource
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/elasticsearchgoods?serverTimezone=UTC
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# mybatis
mybatis:
mapper-locations: classpath:/mapper/*Mapper.xml
type-aliases-package: com.zh.domain添加 javabean
package com.Zh.domain;
import java.io.Serializable;
import java.util.Date;
import java.util.Map;
/**
* @author OZH
* @Description:
* @date 2022/1/24 13:48
*/
public class Goods implements Serializable {
private int id;
private String title;
private double price;
private int stock;
private int saleNum;
private Date createTime;
private String categoryName;
private String brandName;
private Map spec;
// @JSONField(serialize = false)//在转换JSON时,忽略该字段
private String specStr;//接收数据库的信息 "{}"
// 生成set get 和 toString方法
@Override
public String toString() {
return "Goods{" +
"id=" + id +
", title='" + title + '\'' +
", price=" + price +
", stock=" + stock +
", saleNum=" + saleNum +
", createTime=" + createTime +
", categoryName='" + categoryName + '\'' +
", brandName='" + brandName + '\'' +
", spec=" + spec +
", specStr='" + specStr + '\'' +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public int getStock() {
return stock;
}
public void setStock(int stock) {
this.stock = stock;
}
public int getSaleNum() {
return saleNum;
}
public void setSaleNum(int saleNum) {
this.saleNum = saleNum;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public String getCategoryName() {
return categoryName;
}
public void setCategoryName(String categoryName) {
this.categoryName = categoryName;
}
public String getBrandName() {
return brandName;
}
public void setBrandName(String brandName) {
this.brandName = brandName;
}
public Map getSpec() {
return spec;
}
public void setSpec(Map spec) {
this.spec = spec;
}
public String getSpecStr() {
return specStr;
}
public void setSpecStr(String specStr) {
this.specStr = specStr;
}
}
创建dao
package com.Zh.dao;
import com.Zh.domain.Goods;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
/**
* @author OZH
* @Description:
* @date 2022/1/24 13:52
*/
@Mapper
public interface GoodsMapper {
public List<Goods> findAll();
}
在 resource 文件夹下面 创建 mapper/GoodsMapper.xml 配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.Zh.dao.GoodsMapper">
<select id="findAll" resultType="com.Zh.domain.Goods">
select
`id`,
`title`,
`price`,
`stock`,
`saleNum`,
`createTime`,
`categoryName`,
`brandName`,
`spec` as specStr
from goods
</select>
</mapper>添加测试方法
@Autowired
private GoodsMapper goodsMapper;
@Test
public void report() throws IOException {
//1.查询Mysql数据库中goods表所有数据
List<Goods> all = goodsMapper.findAll();
//2.创建批量请求对象
BulkRequest bulkRequest = new BulkRequest();
for (Goods goods : all) {
//做特殊化处理
String specStr = goods.getSpecStr();//{"机身内存":"16G","网络":"移动3g"}
Map spec = JSON.parseObject(specStr, Map.class);
goods.setSpec(spec);
goods.setSpecStr(null);
//将实体对象转换成json串
String jsonString = JSON.toJSONString(goods);
IndexRequest indexRequest = new IndexRequest("goods").id(goods.getId() + "").source(jsonString, XContentType.JSON);
bulkRequest.add(indexRequest);
}
//执行批量操作
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
RestStatus status = response.status();
System.out.println(status);
}查询数据是否导入
GET goods/_search
查询所有matchAll查询
matchAll查询:查询所有文档
kibana 演示
# 查询
GET goods/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 100
} /**
* 查询所有
* 1. matchAll
* 2. 将查询结果封装为Goods对象,装载到List中
* 3. 分页。默认显示10条
*/
@Test
public void testMatchAll() throws IOException {
//2. 构建查询请求对象,指定查询的索引名称
SearchRequest searchRequest = new SearchRequest("goods");
//4. 创建查询条件构建器SearchSourceBuilder
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//6. 查询条件
QueryBuilder query = QueryBuilders.matchAllQuery();//查询所有文档
//5. 指定查询条件
sourceBuilder.query(query);
//3. 添加查询条件构建器 SearchSourceBuilder
searchRequest.source(sourceBuilder);
// 8 . 添加分页信息
sourceBuilder.from(0);
sourceBuilder.size(100);
//1. 查询,获取查询结果
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7. 获取命中对象 SearchHits
SearchHits searchHits = searchResponse.getHits();
//7.1 获取总记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
//7.2 获取Hits数据 数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
//获取json字符串格式的数据
String sourceAsString = hit.getSourceAsString();
//转为java对象
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
} term 查询
term查询:不会对查询条件进行分词。
kibana 演示
GET goods
# term 查询
GET goods/_search
{
"query": {
"term": {
"categoryName": {
"value": "手机"
}
}
}
}/**
* termQuery:词条查询
*/
@Test
public void testTermQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
QueryBuilder query = QueryBuilders.termQuery("title","华为");//term词条查询
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
} matchQuery:词条分词查询
match查询:
• 会对查询条件进行分词。
• 然后将分词后的查询条件和词条进行等值匹配
• 默认取并集(OR)

kibana 演示
# match 查询 "title": "手机"
GET goods/_search
{
"query": {
"match": {
"title": "华为"
}
}
}
# match 查询 "operator": "or"
GET goods/_search
{
"query": {
"match": {
"title": {
"query": "华为手机",
"operator": "and"
}
}
}
} /**
* matchQuery:词条分词查询,分词之后的等值匹配
*/
@Test
public void testMatchQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
MatchQueryBuilder query = QueryBuilders.matchQuery("title", "华为手机");
query.operator(Operator.AND);//求并集
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}模糊查询-脚本
wildcard查询:会对查询条件进行分词。还可以使用通配符 ?(任意单个字符) 和 * (0个或多个字符)
prefix查询:前缀查询
# wildcard 查询。查询条件分词,模糊查询 华为,华,*华*
GET goods/_search
{
"query": {
"wildcard": {
"title": {
"value": "华*"
}
}
}
}
# 前缀查询
GET goods/_search
{
"query": {
"prefix": {
"brandName": {
"value": "三"
}
}
}
} /**
* 模糊查询:WildcardQuery
*/
@Test
public void testWildcardQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
WildcardQueryBuilder query = QueryBuilders.wildcardQuery("title", "华*");
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}
/**
* 模糊查询:perfixQuery
*/
@Test
public void testPrefixQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
PrefixQueryBuilder query = QueryBuilders.prefixQuery("brandName", "三");
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}范围查询-脚本
range 范围查询:查找指定字段在指定范围内包含值
# 范围查询 gte 大于等于 lte小于等于
GET goods/_search
{
"query": {
"range": {
"price": {
"gte": 2000,
"lte": 3000
}
}
}
}
# 范围查询 gte 大于等于 lte小于等于
GET goods/_search
{
"query": {
"range": {
"price": {
"gte": 2000,
"lte": 3000
}
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
/**
* 1. 范围查询:rangeQuery
* 2. 排序
*/
@Test
public void testRangeQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
//范围查询
RangeQueryBuilder query = QueryBuilders.rangeQuery("price");
//指定下限 gte大于等于
query.gte(2000);
//指定上限 小于等于
query.lte(3000);
sourceBulider.query(query);
//排序
sourceBulider.sort("price", SortOrder.DESC);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}queryString查询-脚本
queryString:
• 会对查询条件进行分词。
• 然后将分词后的查询条件和词条进行等值匹配
• 默认取并集(OR)
• 可以指定多个查询字段

# queryString
GET goods/_search
{
"query": {
"query_string": {
"fields": ["title","categoryName","brandName"],
"query": "华为手机"
}
}
}/**
* queryString
*/
@Test
public void testQueryStringQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
//queryString
QueryStringQueryBuilder query = QueryBuilders.queryStringQuery("华为手机")
.field("title")
.field("categoryName")
.field("brandName")
.defaultOperator(Operator.AND);
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}布尔查询
boolQuery:对多个查询条件连接。连接方式:
• must(and):条件必须成立
• must_not(not):条件必须不成立
• should(or):条件可以成立
• filter:条件必须成立,性能比must高。不会计算得分

GET goods/_search
{
"query": {
"match": {
"title": "华为手机"
}
},
"size": 500
} 
# 计算得分
GET goods/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"brandName": {
"value": "华为"
}
}
}
]
}
}
}
# 不计算得分
GET goods/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"brandName": {
"value": "华为"
}
}
}
]
}
}
}
# 计算得分 品牌是三星,标题还得电视
GET goods/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"brandName": {
"value": "三星"
}
}
}
],
"filter": {
"term": {
"title": "电视"
}
}
}
}
} /**
* 布尔查询:boolQuery
* 1. 查询品牌名称为:华为
* 2. 查询标题包含:手机
* 3. 查询价格在:2000-3000
*/
@Test
public void testBoolQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
//1.构建boolQuery
BoolQueryBuilder query = QueryBuilders.boolQuery();
//2.构建各个查询条件
//2.1 查询品牌名称为:华为
QueryBuilder termQuery = QueryBuilders.termQuery("brandName","华为");
query.must(termQuery);
//2.2. 查询标题包含:手机
QueryBuilder matchQuery = QueryBuilders.matchQuery("title","手机");
query.filter(matchQuery);
//2.3 查询价格在:2000-3000
QueryBuilder rangeQuery = QueryBuilders.rangeQuery("price");
((RangeQueryBuilder) rangeQuery).gte(2000);
((RangeQueryBuilder) rangeQuery).lte(3000);
query.filter(rangeQuery);
//3.使用boolQuery连接
sourceBulider.query(query);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}聚合查询
• 指标聚合:相当于MySQL的聚合函数。max、min、avg、sum等
• 桶聚合:相当于MySQL的 group by 操作。不要对text类型的数据进行分组,会失败。
# 查询最贵的华为手机,max_price命名随便取,取一个有意义的名字
GET goods/_search
{
"query": {
"match": {
"title": "华为手机"
}
},
"aggs": {
"max_price":{
"max": {
"field": "price"
}
}
}
}
# 桶聚合 分组
GET goods/_search
{
"query": {
"match": {
"title": "电视"
}
},
"aggs": {
"goods_brands": {
"terms": {
"field": "brandName",
"size": 100
}
}
}
} /**
* 聚合查询:桶聚合,分组查询
* 1. 查询title包含手机的数据
* 2. 查询品牌列表
*/
@Test
public void testAggQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
// 1. 查询title包含手机的数据
MatchQueryBuilder query = QueryBuilders.matchQuery("title", "手机");
sourceBulider.query(query);
// 2. 查询品牌列表
/* 参数:
1. 自定义的名称,将来用于获取数据
2. 分组的字段
*/
AggregationBuilder agg = AggregationBuilders.terms("goods_brands").field("brandName").size(100);
sourceBulider.aggregation(agg);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
// 获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Map<String, Aggregation> aggregationMap = aggregations.asMap();
//System.out.println(aggregationMap);
Terms goods_brands = (Terms) aggregationMap.get("goods_brands");
List<? extends Terms.Bucket> buckets = goods_brands.getBuckets();
List brands = new ArrayList();
for (Terms.Bucket bucket : buckets) {
Object key = bucket.getKey();
brands.add(key);
}
for (Object brand : brands) {
System.out.println(brand);
}
}高亮查询
高亮三要素:
• 高亮字段
• 前缀
• 后缀

GET goods/_search
{
"query": {
"match": {
"title": "电视"
}
},
"highlight": {
"fields": {
"title": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>"
}
}
}
} /**
*
* 高亮查询:
* 1. 设置高亮
* * 高亮字段
* * 前缀
* * 后缀
* 2. 将高亮了的字段数据,替换原有数据
*/
@Test
public void testHighLightQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("goods");
SearchSourceBuilder sourceBulider = new SearchSourceBuilder();
// 1. 查询title包含手机的数据
MatchQueryBuilder query = QueryBuilders.matchQuery("title", "手机");
sourceBulider.query(query);
//设置高亮
HighlightBuilder highlighter = new HighlightBuilder();
//设置三要素
highlighter.field("title");
highlighter.preTags("<font color='red'>");
highlighter.postTags("</font>");
sourceBulider.highlighter(highlighter);
// 2. 查询品牌列表
/*
参数:
1. 自定义的名称,将来用于获取数据
2. 分组的字段
*/
AggregationBuilder agg = AggregationBuilders.terms("goods_brands").field("brandName").size(100);
sourceBulider.aggregation(agg);
searchRequest.source(sourceBulider);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
//获取记录数
long value = searchHits.getTotalHits().value;
System.out.println("总记录数:"+value);
List<Goods> goodsList = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
//转为java
Goods goods = JSON.parseObject(sourceAsString, Goods.class);
// 获取高亮结果,替换goods中的title
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField HighlightField = highlightFields.get("title");
Text[] fragments = HighlightField.fragments();
//替换
goods.setTitle(fragments[0].toString());
goodsList.add(goods);
}
for (Goods goods : goodsList) {
System.out.println(goods);
}
}重建索引
随着业务需求的变更,索引的结构可能发生改变。
ElasticSearch的索引一旦创建,只允许添加字段,不允许改变字段。因为改变字段,需要重建倒排索引,影响内部缓存结构,性能太低。
那么此时,就需要重建一个新的索引,并将原有索引的数据导入到新索引中。
原索引库 :student_index_v1
新索引库 :student_index_v2
# 新建student_index_v1索引,索引名称必须全部小写
PUT student_index_v1
{
"mappings": {
"properties": {
"birthday":{
"type": "date"
}
}
}
}
# 查询索引
GET student_index_v1
# 添加数据
PUT student_index_v1/_doc/1
{
"birthday":"2020-11-11"
}
# 查询数据
GET student_index_v1/_search
# 随着业务的变更,换种数据类型进行添加数据,程序会直接报错
PUT student_index_v1/_doc/1
{
"birthday":"2020年11月11号"
}
# 业务变更,需要改变birthday数据类型为text
# 1:创建新的索引 student_index_v2
# 2:将student_index_v1 数据拷贝到 student_index_v2
# 创建新的索引
PUT student_index_v2
{
"mappings": {
"properties": {
"birthday":{
"type": "text"
}
}
}
}
DELETE student_index_v2
# 2:将student_index_v1 数据拷贝到 student_index_v2
POST _reindex
{
"source": {
"index": "student_index_v1"
},
"dest": {
"index": "student_index_v2"
}
}
# 查询新索引库数据
GET student_index_v2/_search
# 在新的索引库里面添加数据
PUT student_index_v2/_doc/2
{
"birthday":"2020年11月13号"
}Spring Data ElasticSearch
Spring Data ElasticSearch简介
(1)SpringData介绍
Spring Data是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的开源框架。
其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务。
Spring Data可以极大的简化JPA(Elasticsearch…)的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。
Spring Data的官网:Redirecting…
Spring Data常用的功能模块如下:


(2)SpringData Elasticsearch介绍
Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装 。
Spring Data为Elasticsearch项目提供集成搜索引擎。
官方网站:Redirecting…
Spring Data Elasticsearch入门
搭建工程
(1)搭建工程
创建项目 ElasticSearch-SpringData-es
(2)pom.xml依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.2.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>创建启动类
package com.Zh.test;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author OZH
* @Description:
* @date 2022/1/25 10:51
*/
@SpringBootApplication
public class SpringDataEsApplication {
public static void main(String[] args) {
SpringApplication.run(SpringDataEsApplication.class, args);
}
}
配置文件
# es服务地址
elasticsearch.host=127.0.0.1
# es服务端口
elasticsearch.port=9200
# 配置日志级别,开启debug日志
logging.level.com.Zh=debug编写实体类
package com.Zh.test.pojo;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
/**
* @author OZH
* @Description:
* @date 2022/1/25 10:26
*/
//实体类跟那个文档做映射
@Document(indexName = "item",shards = 1, replicas = 1)//索引名,主分片,副本分配
public class Item implements Serializable {
@Id
private Long id;//主键
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title; //标题
@Field(type = FieldType.Keyword)
private String category;// 分类
@Field(type = FieldType.Keyword)
private String brand; // 品牌
@Field(type = FieldType.Double)
private Double price; // 价格
@Field(index = false, type = FieldType.Keyword)
private String images; // 图片地址
public Item() {
}
public Item(Long id, String title, String category, String brand, Double price, String images) {
this.id = id;
this.title = title;
this.category = category;
this.brand = brand;
this.price = price;
this.images = images;
}
//get/set/toString…
@Override
public String toString() {
return "Item{" +
"id=" + id +
", title='" + title + '\'' +
", category='" + category + '\'' +
", brand='" + brand + '\'' +
", price=" + price +
", images='" + images + '\'' +
'}';
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
public String getImages() {
return images;
}
public void setImages(String images) {
this.images = images;
}
}编写配置类
package com.Zh.test.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
/**
* @author OZH
* @Description:
* @date 2022/1/25 10:36
*/
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")//这个能导入配置类的属性
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {
private String host;
private int port;
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public int getPort() {
return port;
}
public int setPort(int port) {
return this.port = port;
}
@Override
public RestHighLevelClient elasticsearchClient() {//继承父类后生成高级客户端,框架自动生成ElasticSearchTemplate,到Spring容器
return new RestHighLevelClient(RestClient.builder(new HttpHost(host, port)));
}
}
测试
package com.Zh.a;
import com.Zh.test.SpringDataEsApplication;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.test.context.junit4.SpringRunner;
/**
* @author OZH
* @Description:
* @date 2022/1/25 10:45
*/
@RunWith(SpringRunner.class)
@SpringBootTest(classes = SpringDataEsApplication.class)
public class TestSpringDataEs {
@Autowired(required = false)
RestHighLevelClient restHighLevelClient;
// ElasticsearchTemplate 基于TransPortClient客户端,过时,不建议用
@Autowired
ElasticsearchRestTemplate elasticsearchRestTemplate;//基于RestHighLevelClient客户端,推荐
@Test
public void testInit() {
System.out.println("restHighLevelClient = " + restHighLevelClient);
System.out.println("elasticsearchRestTemplate = " + elasticsearchRestTemplate);
}
}
创建索引和mapping映射
/**
* 创建索引和mapping映射
*/
@Test
public void testCreate() {
elasticsearchRestTemplate.createIndex(Item.class);//也可以根据字符串创建
elasticsearchRestTemplate.putMapping(Item.class);//mapping
}删除索引
/**
* 删除索引
*/
@Test
public void delIndex() {
boolean zh168 = elasticsearchRestTemplate.deleteIndex("zh168");//可以可以根据类来删除
System.out.println("zh168 = " + zh168);
}
文档操作
编写Dao接口
package com.Zh.es.dao;
import com.Zh.es.pojo.Item;
import org.springframework.data.domain.Sort;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
/**
* @author OZH
* @Description:
* @date 2022/1/25 12:36
*/
public interface ItemDao extends ElasticsearchRepository<Item, Long> {
}
@Autowired
private ItemDao itemDao;
//增加文档
@Test
public void testAdd() {
Item item = new Item(2L, "小米手机8", " 手机", "小米", 3499.00, "http://image.leyou.com/13123.jpg");
itemDao.save(item);
boolean b = itemDao.existsById(1l);
System.out.println(b);
}
//修改id存在就是修改,否则就是插入
@Test
public void testUpdate() {
Item item = new Item(2L, "修改", " 手机修改", "小米修改", 3499.00, "http://image.leyou.com/13123.jpg");
Item save = itemDao.save(item);
System.out.println("save = " + save);
}
//批量新增
@Test
public void indexList() {
List<Item> list = new ArrayList<>();
list.add(new Item(4L, "坚果手机R1", " 手机", "锤子", 200.00, "http://image.leyou.com/123.jpg"));
list.add(new Item(3L, "华为META10", " 手机", "华为", 4499.00, "http://image.leyou.com/3.jpg"));
Iterable<Item> items = itemDao.saveAll(list);
System.out.println("items = " + items);
}
//删除操作
@Test
public void delTest() {
itemDao.deleteById(1l);
}
//根据id查询
@Test
public void qureyById() {
Optional<Item> byId = itemDao.findById(2l);
Item item = byId.get();
System.out.println("item = " + item);
}
//查询全部并按照价格排序
@Test
public void testFind() {
//查询全部,并按照价格降序
// 查询全部,并按照价格降序排序
Iterable<Item> items = itemDao.findAll(Sort.by(Sort.Direction.DESC, "price"));
items.forEach(item-> System.out.println(item));
System.out.println("-----------------------------------------");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
Item next = iterator.next();
System.out.println(next);
}
System.out.println("-----------------------------------------");
PageRequest of = PageRequest.of(0, 2,Sort.by(Sort.Direction.ASC, "price"));
Page<Item> all = itemDao.findAll(of);
Stream<Item> itemStream = all.get();
Object[] objects = itemStream.toArray();
for (Object object : objects) {
System.out.println(object);
}
}自定义方法
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
当然,方法名称要符合一定的约定:
| Keyword | Sample | Elasticsearch Query String |
| And | findByNameAndPrice | {"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
| Or | findByNameOrPrice | {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
| Is | findByName | {"bool" : {"must" : {"field" : {"name" : "?"}}}} |
| Not | findByNameNot | {"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
| Between | findByPriceBetween | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
| LessThanEqual | findByPriceLessThan | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
| GreaterThanEqual | findByPriceGreaterThan | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
| Before | findByPriceBefore | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
| After | findByPriceAfter | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
| Like | findByNameLike | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
| StartingWith | findByNameStartingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
| EndingWith | findByNameEndingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
| Contains/Containing | findByNameContaining | {"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
| In | findByNameIn(Collection<String>names) | {"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
| NotIn | findByNameNotIn(Collection<String>names) | {"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
| Near | findByStoreNear | Not Supported Yet ! |
| True | findByAvailableTrue | {"bool" : {"must" : {"field" : {"available" : true}}}} |
| False | findByAvailableFalse | {"bool" : {"must" : {"field" : {"available" : false}}}} |
| OrderBy | findByAvailableTrueOrderByNameDesc | {"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
在ItemDao增加一个方法
package com.Zh.es.dao;
import com.Zh.es.pojo.Item;
import org.springframework.data.domain.Sort;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
/**
* @author OZH
* @Description:
* @date 2022/1/25 12:36
*/
public interface ItemDao extends ElasticsearchRepository<Item, Long> {
List<Item> findByPriceBetween(double v, double v1);
}
添加测试数据
@Test
public void indexList2() {
List<Item> list = new ArrayList<>();
list.add(new Item(1L, "小米手机7", "手机", "小米", 3299.00, "http://image.leyou.com/13123.jpg"));
list.add(new Item(2L, "坚果手机R1", "手机", "锤子", 3699.00, "http://image.leyou.com/13123.jpg"));
list.add(new Item(3L, "华为META10", "手机", "华为", 4499.00, "http://image.leyou.com/13123.jpg"));
list.add(new Item(4L, "小米Mix2S", "手机", "小米", 4299.00, "http://image.leyou.com/13123.jpg"));
list.add(new Item(5L, "荣耀V10", "手机", "华为", 2799.00, "http://image.leyou.com/13123.jpg"));
// 接收对象集合,实现批量新增
itemDao.saveAll(list);
}不需要写实现类,然后我们直接去运行:
// 不需要写实现类,然后我们直接去运行:
@Test
public void queryByPriceBetween(){
List<Item> list = this.itemDao.findByPriceBetween(2000.00, 3500.00);
for (Item item : list) {
System.out.println("item = " + item);
}
}虽然基本查询和自定义方法已经很强大了,但是如果是复杂查询(模糊、通配符、词条查询等)就显得力不从心了。此时,我们只能使用原生查询。

















 2977
2977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











