







一、有了数据库查询为什么还要ElasticSearch?
数据库一般只适合保存搜索结构化的数据,对于非结构化的数据( 比如文章内容),只能通过like%%模糊查询,但是在大量的数据面前,like%%有两个弊端:
1)搜索效率会很差,因为是做一个全表扫描(like%%会让索引失效)
2)搜索没办法通过相关度匹配排序(可能返回的是用户不关心的结果)
ElasticSearch就可以解决这些问题
二、什么叫全文检索
全文检索 将非结构化数据中的一部分信息提取出来,重新组织,使其变得具有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
什么叫非结构化数据:列如一篇文章内容中,涵盖了中文英文等,无法从文章中找出能组织起文章的结构的具体实例。
索引:字典的拼音表和部首检字表就相当于字典的索引,通过查找拼音表或者部首检字表就可以快速的查找到我们要查的字。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
三、全文检索的流程
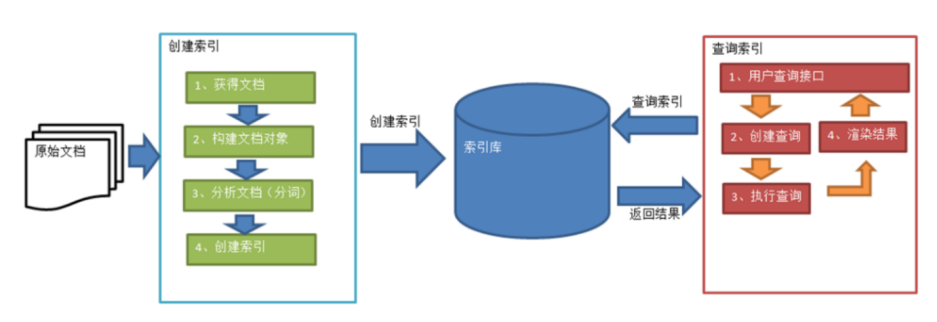
获取到原始文档之后,通过相关的处理,放入到索引库中(索引库主要用于存储索引),用户再通过索引库进行搜索,查询出结果
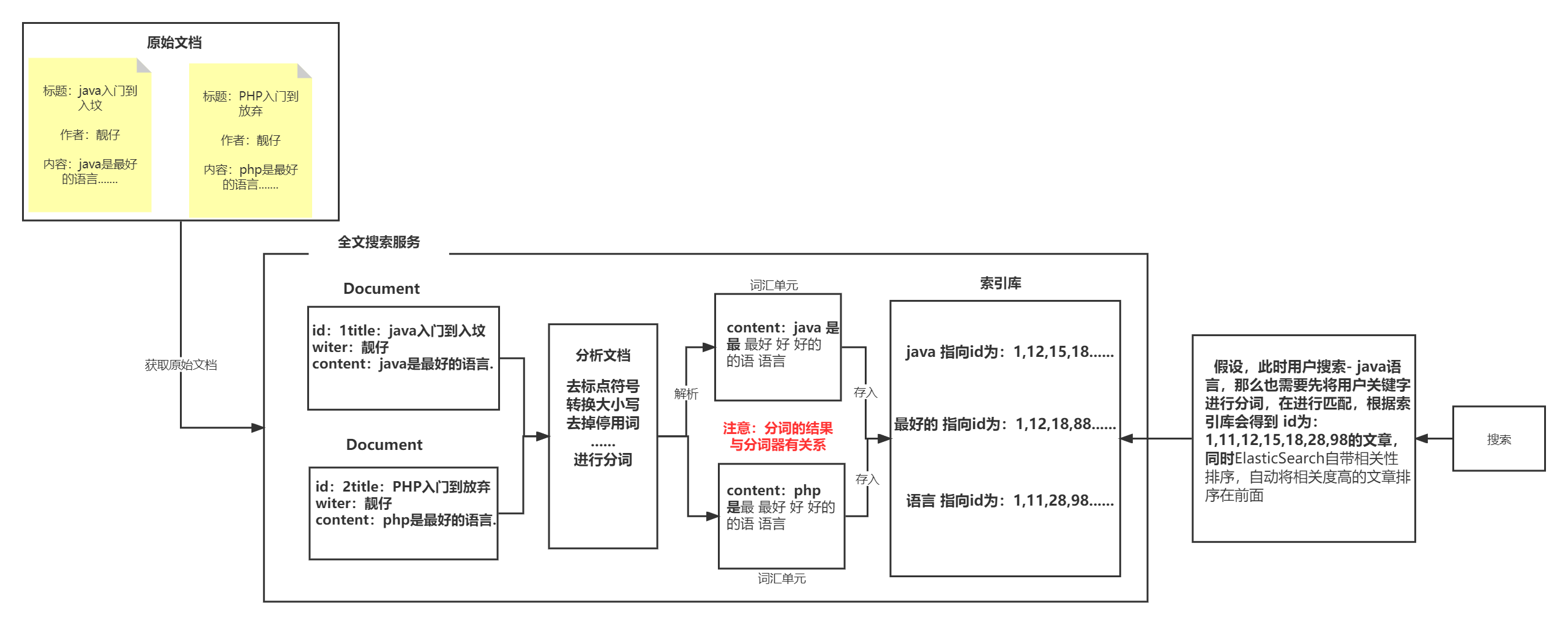
四、创建文档的过程
1.获得原始文档
原始文档是指要索引和搜索的内容,文档的来源不限。
2.创建文档对象(Document)
获取原始文档的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
3.分析文档(分词)
将原始内容创建为包含域(Field)的文档(document),需要再对域中的内容进行分析,分析的过程是经过对原始文档提取单词、将字母转为小写、去除标点符号、去除停用词等过程生成最终的语汇单元。
4.创建索引
创建索引是对语汇单元索引。
根据文字,与以下流程图一起理解
4.1正排排索引
简单来说,正向索引就是根据文件ID找到该文件的内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大、搜索慢
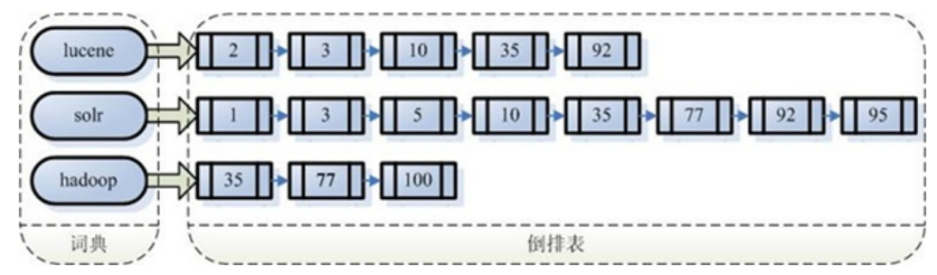
4.2倒排索引
倒排索引和正向索引刚好相反,是根据内容(词语)找文档
五、ElasticSearch(DB - NoSQL数据库 - 非关系型数据库)
5.1索引库(index)
索引库是ElasticSearch存放数据的地方,可以理解为关系型数据库中的一个数据库。我们操作的数据被存储和索引在分片(shards)中,索引只是一个把一个或多个分片分组在一起的逻辑空间。
5.2 映射类型(type)
映射类型用于区分同一个索引下不同的数据类型,相当于关系型数据库中的表。
注意:在 6.0 的index下是无法创建多个type,并且会在 7.0 中完全移除。
5.3 文档(documents)
文档是ElasticSearch中存储的实体,类比关系型数据库,每个文档相当于数据库表中的一行数据。
5.4 字段(fields)
文档由字段组成,相当于关系数据库中列的属性。
5.5 分片与副本
如果一个索引具有很大的数据量,它的数据量可能会超出单个节点的容量限制(硬盘容量),而且单个节点数据量过大,执行性能也会随之下降,每个搜索请求的执行效率都会降低。 为了解决上述问题, Elasticsearch 提出了分片的概念,索引将划分成多份,称为分片。每个分片都可以创建对应的副本,以便保证服务的高可用性。
5.6分词器
这里我使用的是中文分词器和拼音分词器
中文分词器:
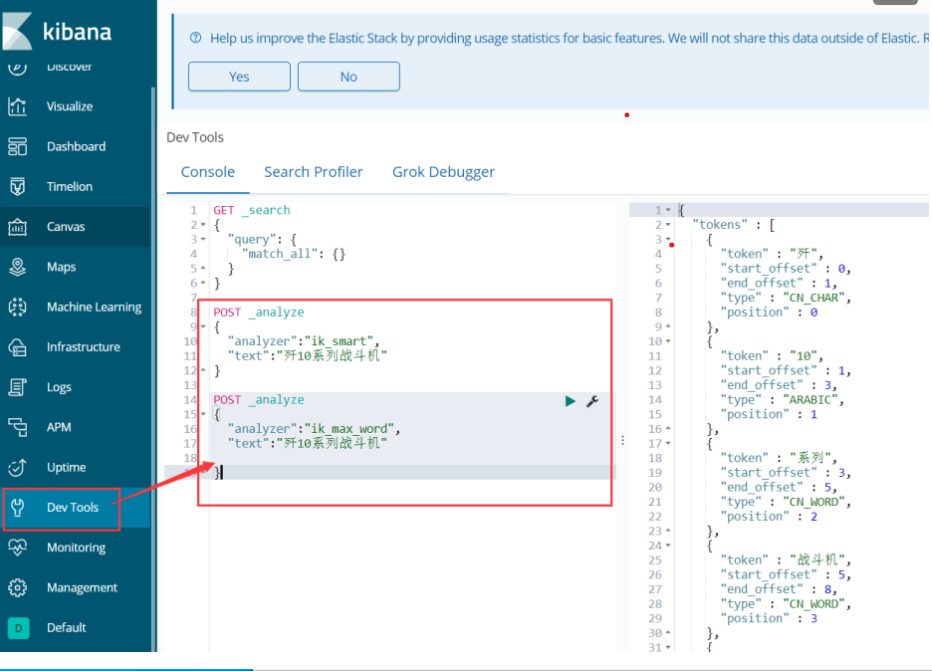
拼音分词器:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









