







在自然语言处理领域,大型语言模型(LLMs)虽然在众多任务上展现出了卓越的能力,但在处理长文本上下文时却遭遇了瓶颈。由于自注意力机制导致的计算和内存开销随序列长度呈二次方增长,使得这些模型在面对长文本时力不从心。尤其是在需要理解和推理大量信息的场景,如长篇文档问答,LLMs往往难以有效应对。
针对这一问题,加州大学伯克利分校的研究团队提出了LLoCO技术,这是一种针对LLaMA2-7B模型的创新扩展。LLoCO通过离线学习和参数高效的微调方法,使得模型能够处理远超传统上下文窗口限制的长文本。LLoCO利用上下文压缩技术将长文本转化为简洁的摘要嵌入,并通过LoRA(Low-Rank Adaptation)技术对这些摘要进行微调,从而在不牺牲性能的前提下显著提升了模型处理长文本的能力。这项技术不仅在多个长文本问答数据集上显示出了卓越的性能,还大幅减少了推理时所需的令牌数量,为长文本处理提供了一个高效且经济的解决方案。
架构
LLoCO技术的架构由两个主要部分组成:上下文编码器和LLM解码器。上下文编码器的作用是将长篇文本转换成较短的摘要嵌入,这些嵌入能够捕捉原文的核心信息,大大减少模型需要处理的令牌数量。这一过程类似于为模型创建一个“作弊纸”,使其能够在有限的空间内高效地存储和检索大量信息。
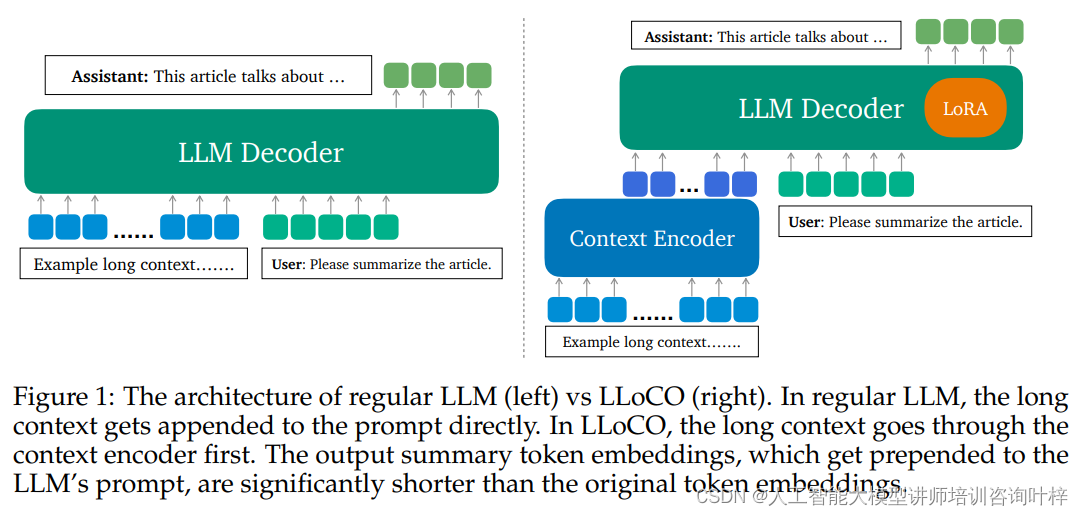
常规LLM架构(图一左侧): 在传统的大型语言模型中,长文本上下文直接附加到提示(prompt)上。模型需要在每次生成输出时处理整个长文本,这不仅增加了计算负担,也使得模型难以捕捉和记忆文本中的关键信息。随着上下文长度的增加,模型的自注意力机制会导致计算和内存开销呈二次方增长,这限制了模型处理长文本的能力。
LLoCO架构(图一右侧): 与常规LLM不同,LLoCO引入了一个上下文编码器来预处理长文本。在LLoCO架构中,长文本首先通过上下文编码器,该编码器负责将长文本转换成较短的摘要嵌入(summary token embeddings)。这些摘要嵌入是原始文本的压缩表示,它们能够捕捉文本的主要信息,并且显著减少了模型需要处理的令牌数量。
这些摘要嵌入被放置在LLM的提示前(即被prepended),作为输入的一部分。这样,LLM在生成回答时,不是直接处理整个长文本,而是处理这些已经压缩的信息。这不仅减少了计算和内存需求,也使得模型能够更有效地定位和利用文本中的关键信息。
优势:
- 减少令牌数量: 摘要嵌入比原始文本中的令牌数量少得多,从而减少了模型在每次推理中需要处理的输入量。
- 提高效率: 通过预处理和压缩上下文,LLoCO减少了模型的计算负担,提高了处理速度。
- 增强信息检索: 摘要嵌入帮助模型更快地定位到相关信息,提高了长文本问答的准确性。
LLoCO的这种设计有效地扩展了模型处理长文本的能力,同时保持了高效的计算性能,这对于长文本的自然语言处理任务具有重要意义。
LLoCO的学习流程包含三个关键阶段:预处理、微调和服务。
预处理阶段涉及将长文本文档转换成“作弊纸”。这一步骤通过上下文编码器实现,它将文档分割成多个小块,并为每一块生成一个摘要嵌入。这些嵌入随后被存储在向量数据库中,为后续的检索和使用做好准备。
微调阶段中,LLoCO利用LoRA技术对模型进行参数高效的微调。这一过程在文档分组的基础上进行,每组文档共享一个LoRA适配器,该适配器在微调后能够提高模型对压缩上下文的理解能力。
服务阶段则是在模型部署和实际应用中进行的。在这个阶段,系统使用检索增强方法来检索与用户问题最相关的压缩文档和对应的LoRA模块,并将它们应用于LLM解码器以生成回答。
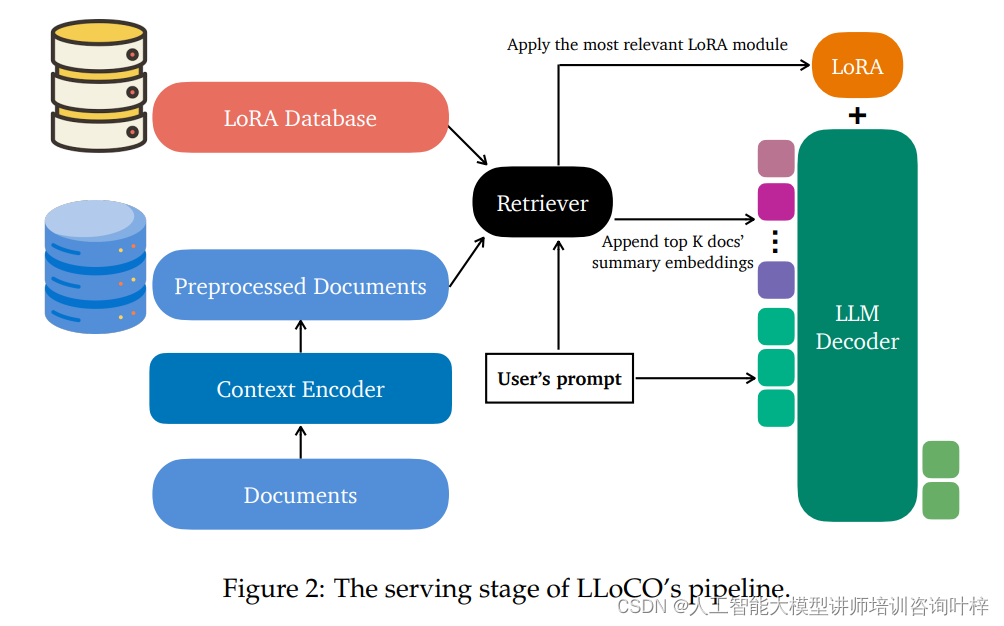
Figure 2为LLoCO技术的服务流程,这一流程优化了传统LLMs处理长文本的方式。在LLoCO中,系统不直接检索文本段落,而是检索由上下文编码器生成的压缩令牌嵌入。这些嵌入捕捉了原文的关键信息,并且大大减少了模型需要处理的数据量。然后这些嵌入被连接并前置到LLM解码器的输入中,以便模型能够快速访问和理解长文本的核心内容。系统还会选择一个与检索到的文本最匹配的LoRA适配器,以最小的系统开销将其应用于解码器,进一步提升模型的性能和适应性。
通过这三个阶段,LLoCO不仅提高了模型处理长文本的能力,同时也优化了模型的效率和响应速度,为长文本的自然语言处理任务提供了一个创新且实用的解决方案。
实验
为了验证LLoCO技术在处理长文本问答任务上的有效性,研究者选择了QuALITY、Qasper、NarrativeQA和HotpotQA等专门的长文本问答数据集进行实验。实验结果表明,LLoCO不仅在各个数据集上均显著超越了传统的基线方法,而且在NarrativeQA数据集上,通过压缩上下文至约2600个令牌,实现了与原始上下文长度相比30倍的令牌减少,同时保持了出色的F1分数。
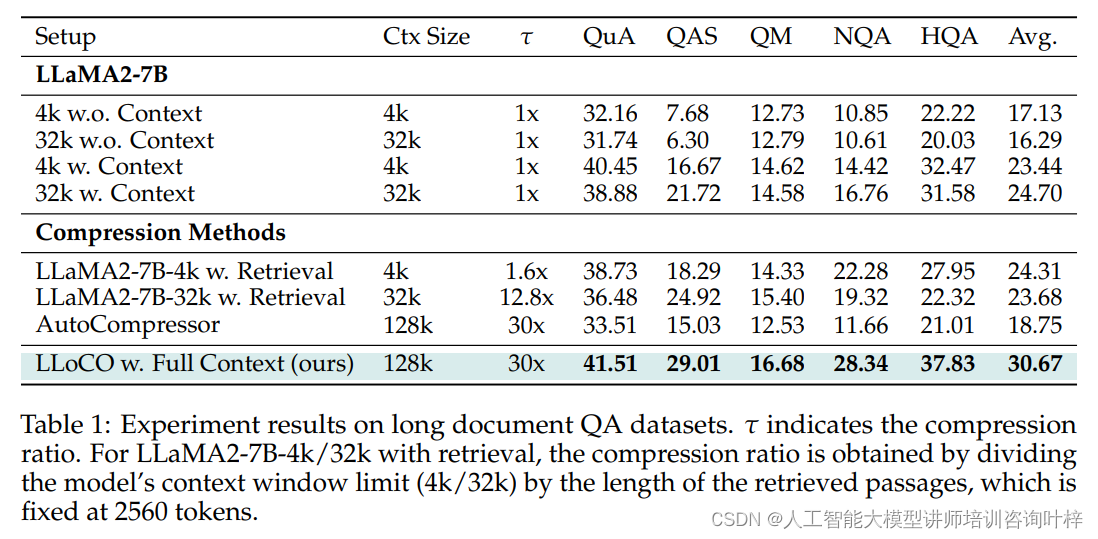
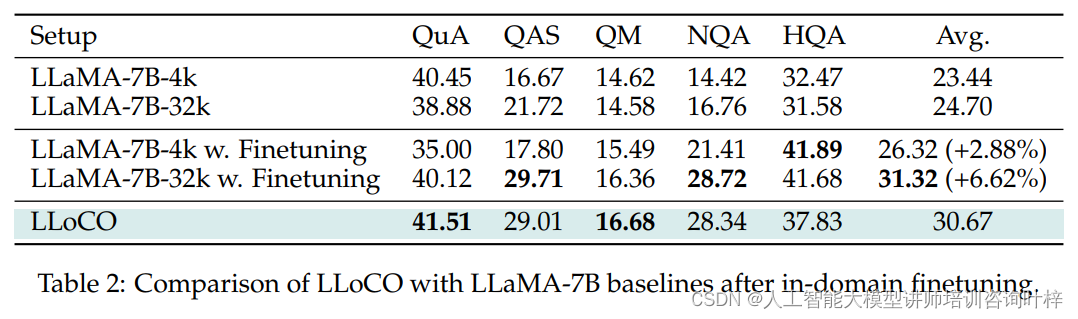
在消融研究中研究者使用原始上下文进行LoRA微调的效果进行了深入分析,并与LLoCO方法进行了对比。研究发现,尽管原始上下文微调后的模型性能有所提升,但LLoCO方法在压缩上下文上的微调同样有效,且在推理时使用的令牌数量大幅减少,显示出更高的成本效益。
LongBench基准测试进一步证实了LLoCO在长文本处理任务上的卓越性能。研究者专注于单文档问答、多文档问答和摘要任务,这些任务覆盖了不同的数据集和应用场景。LLoCO在多数任务中均优于基线模型,尤其是在多文档问答任务中表现突出。
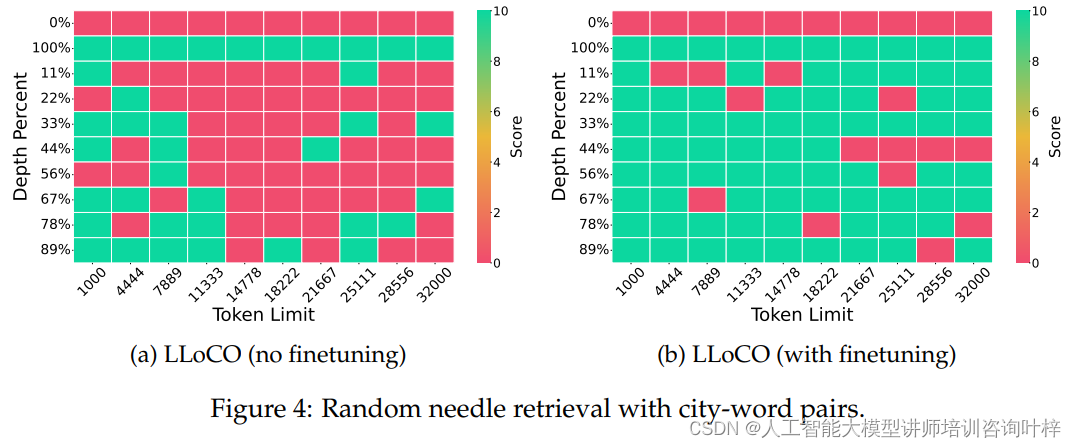
为了测试LLoCO在复杂环境中检索信息的能力,研究者采用了“针堆中寻针”任务。LLoCO在不同上下文窗口长度下均展现出了强大的检索能力,即使在面对随机变化的“针”时,通过持续的微调,LLoCO能够快速适应并保持高成功率。

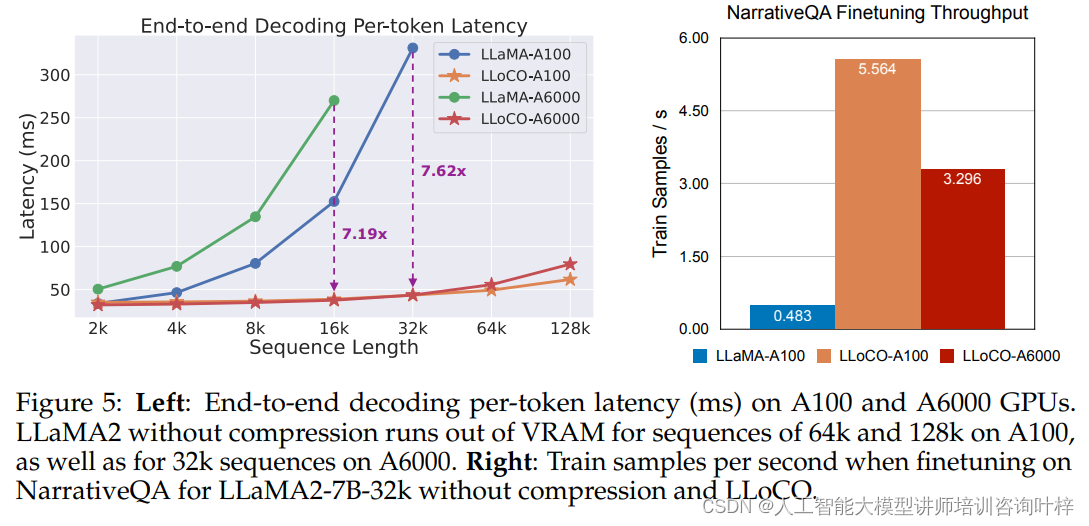
在推理延迟和微通过量的评估中,LLoCO显示出了显著的性能提升。实验结果表明,LLoCO在保持相同上下文条件的情况下,与未压缩的LLaMA2-7B基线相比,在A100和A6000 GPU上分别实现了7.62倍和7.19倍的速度提升。在NarrativeQA数据集上的微通过量测试中,LLoCO也展现了更高的训练效率。
通过这些详细的实验,不仅验证了LLoCO技术的有效性,还展示了其在不同方面的性能优势,特别是在处理长文本时的高效率和低成本。这些实验结果为LLoCO技术的进一步应用和发展提供了坚实的基础。
论文链接:https://arxiv.org/abs/2404.07979















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









