







文章目录
前言
论文题目:TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems
论文原文:
论文来源:IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY CCF A SCI 1 区
发表时间:2022

摘要
深度神经网络(DNN),无论其令人印象深刻的性能,都容易受到来自对抗性输入的攻击,最近,特洛伊木马会误导或劫持模型的决策。我们通过探索空间有界的对抗示例空间的超集和生成对抗网络中的自然输入空间,揭示了一类有趣的空间有界的、物理上可实现的对抗示例的存在——通用自然对抗补丁——我们称之为nt。现在,对手可以用一个自然的、不那么恶意的、物理上可实现的、高效的、实现高攻击成功率的、通用的补丁来武装自己。TnT是通用的,因为场景中任何用TnT捕获的输入图像都会:i)误导网络(非目标攻击);或者ii)强迫网络做出恶意的决定(目标攻击)。有趣的是,现在,一个对抗性补丁攻击者有可能施加更大程度的控制——独立选择位置的能力,自然外观的补丁作为触发器,而不是受噪声干扰的约束——迄今为止,这种能力只可能与特洛伊木马攻击方法相结合,需要干扰模型构建过程,以便在发现风险时嵌入后门;但是,仍然实现了在物理世界中可部署的补丁。通过大规模视觉分类任务的大量实验,ImageNet对其50,000张图像的整个验证集进行评估,我们展示了来自tnt的现实威胁和攻击的鲁棒性。我们展示了攻击的泛化,以创建补丁,实现比现有最先进的方法更高的攻击成功率。我们的研究结果表明,该攻击对不同的视觉分类任务(CIFAR-10、GTSRB、PubFig)和多个最先进的深度神经网络(如WideResnet50、Inception-V3和VGG-16)具有普遍性。
一、介绍
1、背景
深度神经网络(DNN)在自动驾驶、疾病诊断和人脸识别等关键任务中表现卓越,但其安全性面临重大挑战。攻击者可通过两类主要手段破坏DNN系统:
- 推理阶段攻击:如对抗性样本(Adversarial Examples)和对抗性补丁(Adversarial Patches)。这些方法通过添加特定噪声或局部扰动误导模型预测。
- 训练阶段攻击:如后门攻击(Trojan Attacks),通过在训练数据中植入触发模式(Trigger),使模型在推理阶段对特定输入产生恶意行为。
现有对抗性补丁(如AdvPatch和LaVAN)虽然能实现通用攻击(Universal Attack),但依赖明显的噪声扰动,在物理环境中易受光照、角度等干扰,且外观不自然,容易被察觉。而传统后门攻击需干预模型训练过程,存在被检测的风险。
2、现有研究的不足
对抗性补丁的局限性:
补丁通常为噪声模式,难以在物理世界隐蔽部署。
空间位置敏感,轻微移动可能导致攻击失效。
后门攻击的局限性:
需控制训练过程,实际攻击中难以实现。
触发模式虽自然(如花朵),但依赖模型内部后门,无法直接攻击已部署模型。
3、研究动机
作者提出一个关键问题:能否找到一种自然、隐蔽且物理可实现的对抗性补丁,既能像后门触发模式一样自然,又无需修改模型训练过程?
这种补丁需满足:
自然性:与真实物体(如花朵)外观一致,避免引起怀疑。
通用性:单一补丁可攻击任意输入(输入无关)。
鲁棒性:对补丁位置、光照等物理条件变化不敏感。
4、贡献
本文提出TnT(Universal Naturalistic Adversarial Patches)攻击方法,核心贡献如下:
- 自然对抗补丁的生成:通过生成对抗网络(GAN)探索自然图像空间与对抗扰动空间的交集,生成外观自然的补丁(如花朵)。
- 高攻击成功率:在ImageNet等大规模数据集上,对多种DNN模型(如VGG-16、Inception-V3)实现超过95%的攻击成功率。
- 物理可部署性:补丁可打印并部署于真实场景,在复杂光照、角度下仍有效。
- 通用性与鲁棒性:补丁位置无关,即使置于图像角落仍有效;且可跨任务(如交通标志识别、人脸识别)和模型迁移攻击。
二、GAN的简要背景
1、生成对抗网络(GAN)基础
生成对抗网络(GAN)由生成器(Generator)和判别器(Discriminator)组成,通过对抗训练生成逼真数据:
- 生成器(G):将随机噪声向量 z(通常服从高斯分布)映射为合成图像 x̃ = G(z),目标是生成与真实数据分布相似的图像。
- 判别器(D):区分真实图像 x(来自真实数据分布 ℙ_r)和生成图像 x̃(来自生成器分布 ℙ_g),输出为图像真实性的概率。
传统GAN的优化目标是一个极小极大博弈:
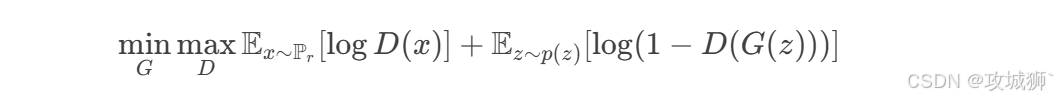
但传统GAN存在训练不稳定、模式崩溃(生成多样性低)等问题。
2、WGAN-GP
Wasserstein GAN with Gradient Penalty(WGAN-GP)
为解决传统GAN的缺陷,WGAN-GP引入Wasserstein距离和梯度惩罚:
- Wasserstein距离:衡量生成分布 ℙ_g 与真实分布 ℙ_r 之间的距离,优化目标更平滑。
- 梯度惩罚:强制判别器满足Lipschitz连续性约束,避免梯度爆炸或消失。
WGAN-GP的优化目标:
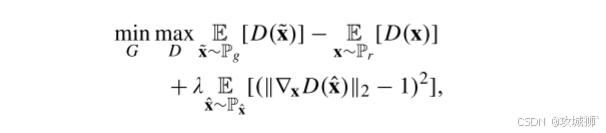
前两项: 判别器所需最大化真实样本得分与生成样本得分的差距。
第三项(梯度惩罚): 在真实与生成样本的插值点 x̂ 上,约束判别器梯度范数接近1(Lipschitz条件)。
通过WGAN-GP,生成器能更稳定地学习真实数据分布,生成高质量自然图像。
3、GAN在TnT攻击中的核心作用
在TnT攻击中,GAN被用于生成自然对抗补丁:
- 自然图像空间: GAN的生成器已学习真实自然图像的分布(如花朵),确保生成的补丁外观自然。
- 对抗扰动空间: 通过优化潜在向量 z,使生成的补丁兼具自然性和对抗性(即误导分类器)。
关键步骤:
训练GAN生成自然图像: 使用无标签花朵图像集训练WGAN-GP,生成器学会合成逼真花朵。
搜索对抗潜在向量: 在GAN的潜在空间 z 中,通过梯度下降调整 z,使得生成的补丁 G(z) 添加到图像后能最大化分类器损失(图2)。
三、方法
1、攻击模型(Threat Model)
攻击模型定义了攻击者的能力、目标和攻击场景。本文主要考虑两类攻击者:
白盒攻击者(White-Box Attacker):
能力: 完全掌握目标模型的架构、参数及训练数据。
目标: 生成针对特定模型的对抗补丁,最大化攻击成功率(ASR)。
场景: 即使无法直接访问模型,攻击者可通过模型逆向工程(如模型提取攻击)获取近似模型进行攻击。
黑盒攻击者(Black-Box Attacker):
能力: 无法获取目标模型的内部信息,仅能通过查询输入输出关系进行攻击。
目标: 利用在其他模型(同任务)上生成的对抗补丁,迁移攻击目标模型。
场景: 例如,使用ImageNet上训练的VGG-16生成的补丁,攻击未知的ResNet模型。
攻击目标:
定向攻击(Targeted Attack): 强制模型将任何输入预测为指定目标类别(如将“狗”误分类为“猫”)。
非定向攻击(Untargeted Attack): 仅需导致模型预测错误,不限定目标类别。
2、 核心假设(Hypothesis)
作者提出两个关键假设作为攻击方法的理论基础:
假设1: DNN的决策边界存在与自然图像空间重叠的区域,即存在自然图像本身具有对抗性。
依据: Hendrycks等人的研究表明,未经修改的自然图像也可能导致分类错误(“自然对抗样本”)。
假设2: 通过GAN的潜在空间搜索,可高效找到既自然又具对抗性的补丁。
依据: GAN生成的图像分布覆盖真实自然图像空间,潜在空间维度低,易于优化。
3、攻击方法概述
TnT攻击的核心流程分为三个阶段(如图2所示):
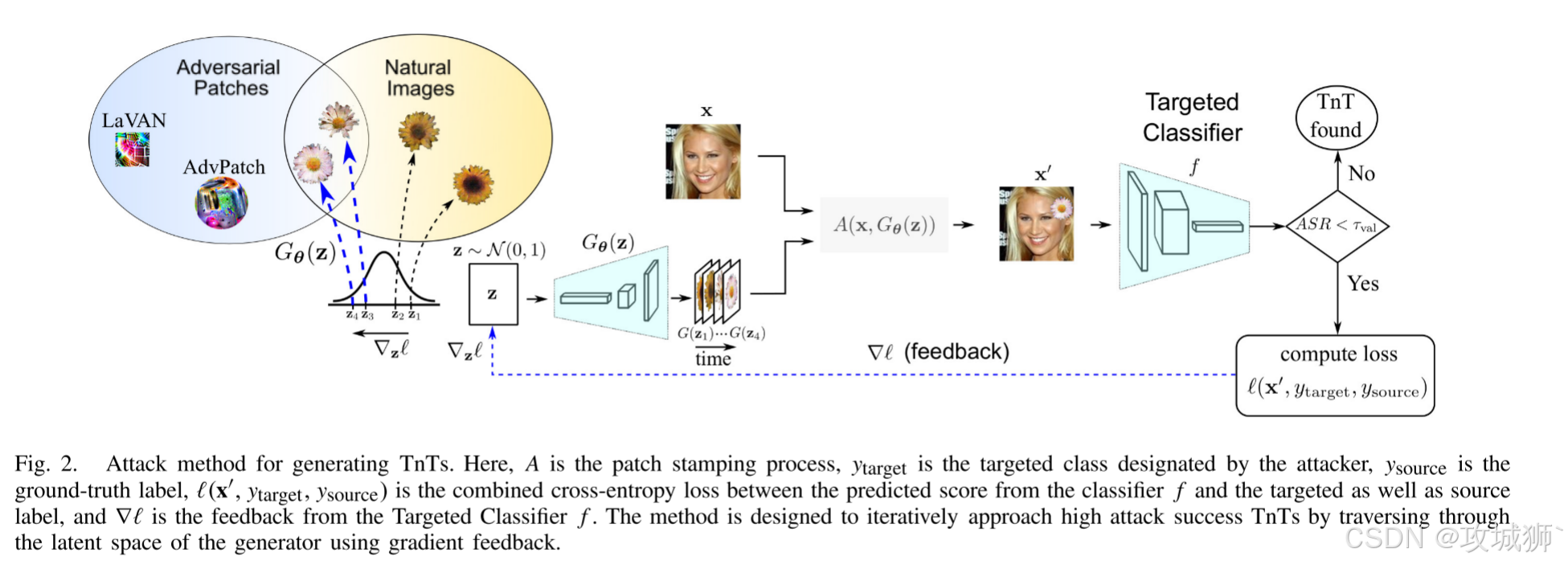
- 由于 GAN 设计用于将已知(潜在)分布映射到真实图像分布,如图2 所示,我们考虑生成器从其中生成图像的潜在空间 z - G θ (z),而不是搜索所有自然外观图像补丁的无限空间;即标准高斯分布 N (0,1),并且具有较低的维度,其中遍历更容易。
- 通过从下游分类器获得反馈(∇),我们可以遵循梯度反馈遍历潜在空间,以寻找可以生成潜在 TnT 的潜在向量。
阶段1:训练自然图像生成器(GAN)
数据收集:使用无标签自然图像(如花朵)训练GAN。例如,从Google Images爬取945张花朵图像。
GAN架构:采用WGAN-GP框架,确保生成图像质量高且训练稳定。
输出:生成器 G 能够将潜在向量 z∼N(0,1) 映射为自然花朵图像 G(z)。
阶段2:潜在空间对抗优化
对抗补丁生成:
对输入图像 x,将生成的补丁 δ=G(z) 粘贴到指定位置(如右下角),生成对抗样本 x′ :
四、TnT 生成器
本节详细阐述了如何通过生成对抗网络(GAN)生成自然且具有对抗性的补丁(TnT)。核心思想是利用GAN的生成能力合成自然图像(如花朵),并通过优化潜在空间(Latent Space)中的向量,使生成的图像同时具备对抗性。以下是关键内容分解:
1、训练生成器
- GAN 的一个优点是它们是无监督模型,只需要未标记的数据,这些数据可以廉价地获得。
- 在这项研究中,我们从开源的 Google Images [32] 收集了一个随机、未标记的花卉图像数据集,用于构建花卉数据集以学习自然花卉分布。
- 我们选择了 WGAN-GP 损失函数,因为它已被证明可以稳定 GAN 的训练过程。
2、转为TnT生成器
-
为了实现 TnT(在我们的攻击场景中代表花卉补丁),我们需要从我们合成的花卉分布中搜索具有对抗性效果的花卉。在这里,我们假设 GAN 已经学习了图2 所示的自然外观图像和对抗性的超集;因此,通过搜索这个合成的分布,我们期望找到结构化的、自然外观的扰动,而不是随机的噪声扰动。
-
1、首先,我们正式定义 TnT 的符号,然后提出实现 TnT 的方法。
- y_source 是给定图像 x 的源类标签。
- y_target 是攻击者指定的目标类。
- 损失是预测和标签之间的损失(x, y_source)对于非目标攻击和(x, y_target)对于目标攻击 - 神经网络的交叉熵损失函数,给定图像 x 和类标签 y。
- 值得注意的是,我们在成本函数中故意省略了网络权重(θ)和其他参数,因为我们假设它们是固定的,并且在网络训练后保持不变。
-
2、现在,更正式地说,攻击者使用一个预训练好的模型 M,该模型预测类成员资格概率 p_M(y | x) 以输入图像 x ∈ R^(w×h×c)。我们用 y = p_M(x) 表示所有类概率的向量,并用 y_argmax = arg max_y p_M(y = y | x) 表示输入 x 的最高评分类(分类器对源类的预测)。
攻击者寻求一个图像 x 用来欺骗网络,使得 y = y_source 或 y = y_target 为 y = arg max_y p_M(y = y | x)。图像 x 由原始图像和贴在其上的自然补丁组成。我们将这个过程表示为函数 A(x, G(z))。
3、TnT生成过程
1.采样潜在向量: 首先,我们从 p(z) 中采样一个向量 z ∼ p(z),其中 z ∈ R^N,N =128。这个潜在向量将输入到我们在第 IV-A 节中预训练的生成器中,以生成花卉补丁 δ = G(z),其中 G : R^N → R^(w×h×c)。
2. 裁剪和粘贴: 将花卉补丁贴在图像的右下角,以避免遮挡图像的主要特征,这与以前工作中的意图一致 [34]、[49]。稍后,在第 VI-B 节中,我们还评估了花卉补丁在九个不同随机位置上的有效性。
2. 图像掩模: 补丁的大小可以根据攻击者的目标确定,以达到他们的目标(有关攻击成功率和 TnT 大小的讨论将在第 VIII-B 节中详细介绍)。
4.更新潜在向量: 基于预定义的位置和补丁大小,我们使用 OpenCV [42] 的图像阈值方法来确定图像的二元掩模 m,其中 m_i,j ∈ {0,1} 是图像第 i 行第 j 列像素的掩模,以去除 δ 的背景。然后将此补丁粘贴到输入图像上,以获得对抗性样本 x ,即: x = A(x, G(z)) = x * (1 - m) + δ * m 其中 * 表示元素-wise乘积。
5.分类器反馈: 为了确定 x 作为对抗性样本的能力并接收反馈以选择更好的潜在变量,我们使用训练好的神经网络分类器对其进行测试。将样本 x 输入到分类器中,以获得每个类的预测分数。
6.损失函数: 计算预测分数和目标标签 y_target之间的损失(x’, y_target)以及源标签 y_source之间的损失(x’, y_source)(例如,使用交叉熵)。
7. 梯度下降: 然后,计算损失相对于潜在变量 z 的梯度,即 ∇_z (x’, y_target, y_source)。然后,我们使用梯度下降在最小化损失的方向上更新潜在变量 z。注意,这不会改变分类器或 GAN 参数,而只会更新潜在变量以增加攻击成功的可能性。
8.评估 TnT通用性: 在 TnT 生成过程中,对于随机输入集,如果阈值百分比的输入 x 能够欺骗网络,则认为 TnT 是通用的。在这里设置阈值的原因是为了提高算法的速度,因此,如果攻击在一批输入上成功,那么我们将测试它是否可以推广到验证集 X_val。
五、实验
1、ImageNet验证集的攻击有效性
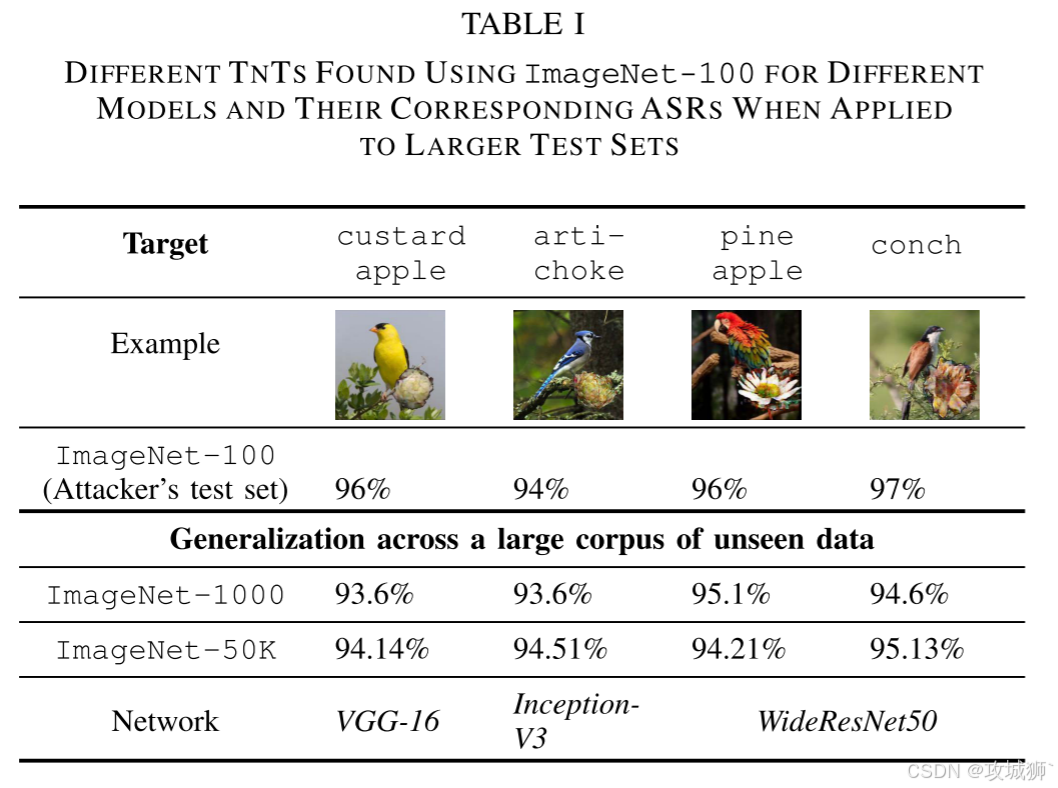
我们只使用少量样本(100张图像)来寻找tts。在100张图像的小样本量下,我们成功地实现了多个不同的TnT,它们以高于90%的攻击成功率欺骗分类器(在100张随机调查的图像上),同时仍然保持了TnT生成器产生的花块的自然性。
我们还进一步验证了从100张图像的小样本中发现的发现的tnt的泛化性,以攻击ImageNet中更大的样本。结果如表1所示。
2、对补丁位置变化的鲁棒性
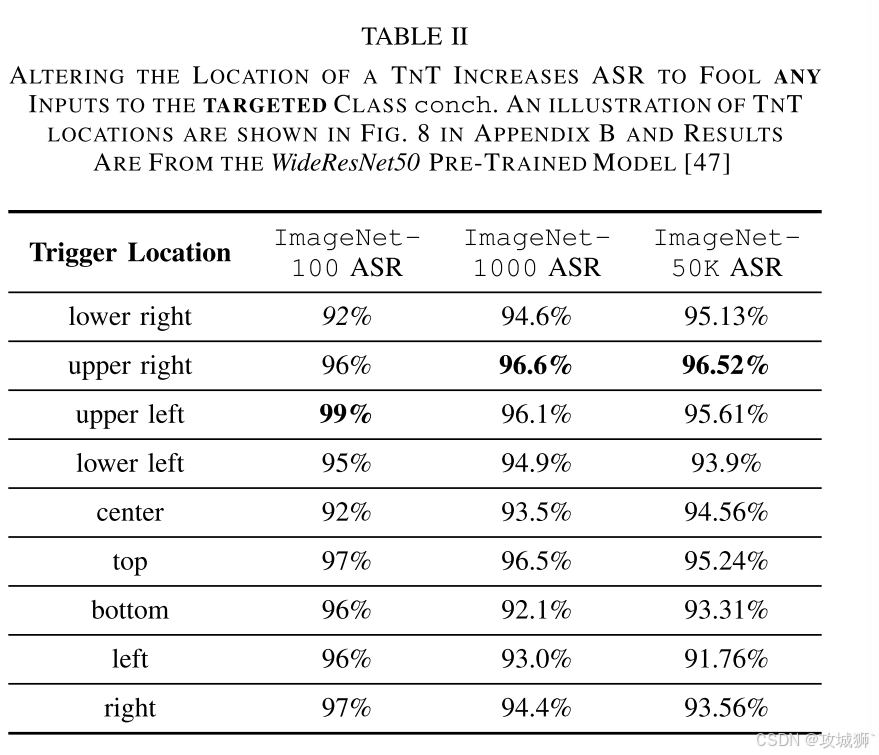
3、黑盒攻击——tnt的可转移性
我们已经研究了迄今为止的攻击,都是在白盒攻击模型下进行的;攻击者需要完全了解他们攻击的目标模型。鉴于前面实验中展示的 TnTs的高泛化性,在本节中,我们旨在评估在黑盒设置中,在任务中发现 TnTs 是否可以迁移到另一个网络以进行攻击。
黑盒攻击者只需要访问源模型即可对源模型进行白盒攻击以提取 TnTs。然后,攻击者可以将发现的 TnTs 盲目地应用于执行相同任务和数据集的任何其他网络。在这种设置中,我们在 ImageNet 上使用视觉识别任务,在源模型上攻击目标网络。
值得注意的是,在 [6]、[34] 中没有黑盒攻击的定性结果,并且在 [4] 中已经表明目标攻击的迁移性具有挑战性。因此,根据 [41] 中的设置,我们评估了 TnTs 在非目标攻击设置中的迁移性。黑盒攻击的详细结果如表 XIII(附录 E)所示。在源模型上实现的 TnT 高度迁移到另一个网络。一般来说,我们发现,在任务上对网络更准确(例如 SqueezeNet)实现的 TnT(即使源攻击成功率为 99%)不能很好地推广到其他网络(例如 WideResNet50)(攻击成功率为 36%)。相反,从对任务更准确(例如 WideResNet50)(攻击成功率为 97%)的网络中实现的 TnT 具有很高的泛化性,并且在其他网络上的攻击成功率达到 60% 以上。
4、 攻击效果和在其他任务上的泛化
我们进一步研究了 TnTs 在以下三个对比任务上的有效性。
- 场景分类任务 (CIFAR-10): 该任务的目标是生成 TnT 花卉,能够愚弄分类器将带有 TnT 花卉的任何场景误识别为目标类,这里我们选择随机标签(汽车)作为目标类。结果显示,生成的 TnT 可以将任何输入错误分类为目标标签,具有高达 90.12% 的攻击成功率。
- 交通标志识别任务 (GTSRB): 这是一个具有挑战性的任务,因为训练数据集包括各种物理和环境变化,包括不同的距离、照明或遮挡条件。尽管如此,发现的 TnTs 仍然在非目标攻击设置中实现了高达 95.75% 的显着攻击成功率,与表 III 中相同大小的随机颜色补丁遮挡引起的 20.73% 的攻击成功率相比显着增加。在附录 B 的表 VII 中显示了实现的 TnT 样本和相应的攻击成功率。
- 人脸识别任务 (PubFig): 在这项任务中,网络学习到的显着特征大多在脸上,并且网络学习忽略背景信息。在没有遮挡脸部主要特征的情况下,愚弄网络以将特定目标识别为特定目标是一个有趣且具有挑战性的任务。附录 B 中的表 VII 展示了一些非目标攻击的结果。对于针对指定目标(例如我们在评估中使用的奥巴马)的目标攻击,我们在图像的右下角实现了覆盖 20% 的图像的 TnTs(与我们第 VI-E 节中消融研究中使用的覆盖范围相似)。我们成功地愚弄了网络,以高达 97.28% 的攻击成功率将带有 TnT 的任何人错误分类为着名的目标人物(例如我们在评估中使用的奥巴马)。图 3 中展示了成功 TnTs 的示例。
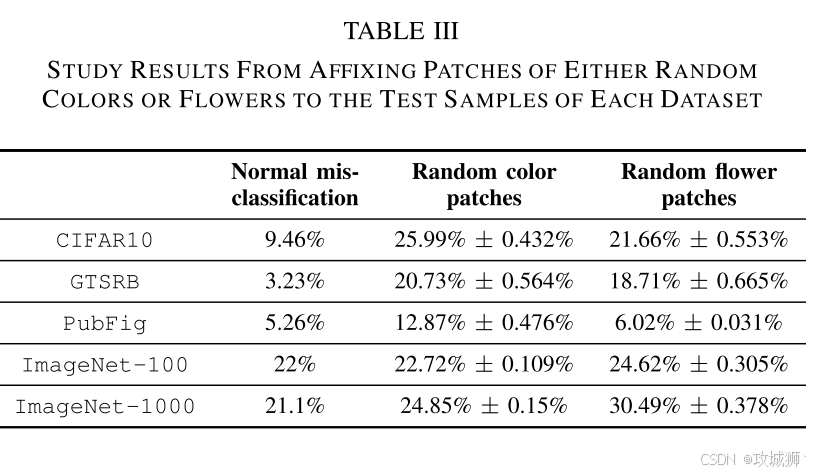
5、攻击成功的解释
在本节中,我们将使用随机补丁(随机花卉或颜色)来检查 DNN 系统的错误分类,以研究补丁可能对视觉任务攻击成功率的影响。此外,我们还利用随机花卉补丁来调查我们观察到的行为是否可以解释为网络对花卉图像的偏见,以及随机发现一个能够以高攻击成功率愚弄分类器的自然外观花卉的可能性。
-
补丁大小: 为了检查潜在的影响,我们选择的彩色和花卉补丁将遮挡我们有意为攻击方法选择的尽可能大的区域(大约 20% 的图像)。
-
随机颜色补丁: 我们使用 256 个随机颜色补丁,并使用我们在公式 1 中描述的方法将补丁数字地盖在输入上,作为触发器,位于图像的右下角,目的是不遮挡图像的主要对象,但评估颜色补丁造成的错误分类。
-
随机花卉补丁: 我们遵循颜色补丁的方法,但使用从我们用于训练生成器的花卉数据集中随机选择的花卉。特别是,我们使用 256 个随机选择的花卉,并测量花卉补丁可以对分类器造成的攻击成功率。
-
结果: 在表 III 中,我们报告了不同任务中补丁的攻击成功率的平均值和标准差。总的来说,与使用 TnTs(见表 I 和 VII)展示的攻击成功率相比,实现的攻击成功率显着较低。重要的是,我们观察到所有任务的标准差都很低;这表明没有特殊的颜色或花卉补丁可以比其他补丁实现显着更高的攻击成功率。然而,这些结果远非理想的攻击成功率,无法成为真正的威胁,但是我们的调查表明,利用自然外观补丁愚弄网络是一个具有挑战性的任务,我们观察到的现象不能通过遮挡或网络对花卉或颜色的偏见来解释;因此,我们的攻击方法是一种实现此类 TnTs 的有效方法。
后面作者还做了其他的实验包括与其他攻击方法的比较,以及TnT在物理世界中的应用等等,感兴趣的小伙伴可以去下载原文查阅。
总结
TnT 攻击的优势:
- 通用性: TnT 攻击具有通用性,即一个 TnT 补丁可以愚弄任何输入图像,使其被错误分类为目标类别。
- 自然主义: TnT 补丁具有自然外观,与现有的对抗性攻击方法(如噪声扰动)相比,更难以被发现。
- 有效性: TnT 攻击具有高攻击成功率,即使在面对防御措施的情况下也能有效地愚弄 DNN。
TnT 攻击的原理:
- TnT 攻击利用 GAN 的能力生成自然图像,并通过在 GAN 的潜在空间中搜索,找到能够生成对抗性效果的潜在向量。
- 攻击者可以通过调整潜在向量来控制 TnT 补丁的外观和攻击目标。
TnT 攻击的应用:
- TnT 攻击可以应用于各种 DNN 任务,包括图像分类、交通标志识别和人脸识别等。
- TnT 攻击可以用于攻击各种 DNN 模型,包括 WideResNet50、Inception-V3 和 VGG-16 等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









