







目录
一、设计方案概述
主要网络模型设计:
设计所使用网络模型为TextCNN,由于其本身就适用于短中句子,在标题分类这一方面应该能发挥其优势。
TextCNN是Yoon Kim在2014年提出的模型,开创了用CNN编码n-gram特征的先河
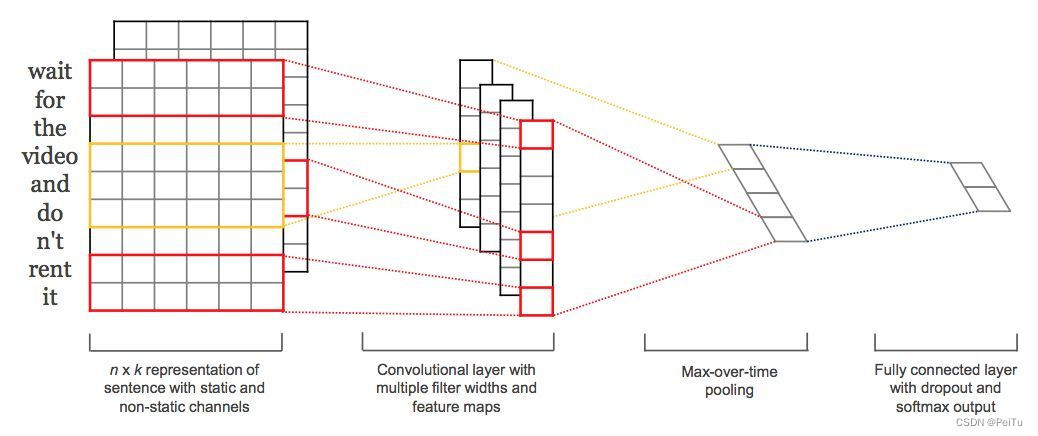
图1-1
模型结构如图,图像中的卷积都是二维的,而TextCNN则使用「一维卷积」,即filter_size * embedding_dim,有一个维度和embedding相等。这样就能抽取filter_size个gram的信息。以1个样本为例,整体的前向逻辑是:
对词进行embedding,得到[seq_length, embedding_dim]
用N个卷积核,得到N个seq_length-filter_size+1长度的一维feature map
对feature map进行max-pooling(因为是时间维度的,也称max-over-time pooling),得到N个1x1的数值,拼接成一个N维向量,作为文本的句子表示
将N维向量压缩到类目个数的维度,过Softmax
网络结构图:
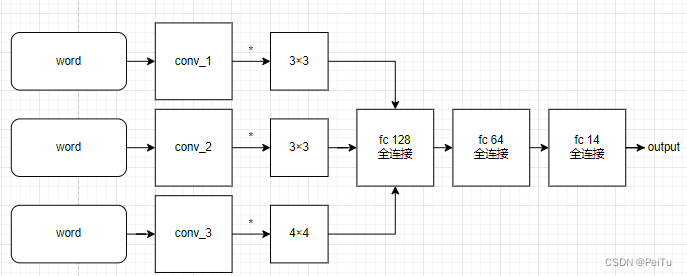
图1-2
在TextCNN的实践中,有很多地方可以优化。
Filter尺寸:这个参数决定了抽取n-gram特征的长度,这个参数主要跟数据有关,平均长度在50以内的话,用10以下就可以了,否则可以长一些。在调参时可以先用一个尺寸grid search,找到一个最优尺寸,然后尝试最优尺寸和附近尺寸的组合
Filter个数:这个参数会影响最终特征的维度,维度太大的话训练速度就会变慢。使用100-600之间即可
CNN的激活函数:选择Identity、ReLU、tanh
正则化:指对CNN参数的正则化,可以使用dropout或L2,但能起的作用很小,可以试下小的dropout率(<0.5),L2限制大一点
Pooling方法:根据情况选择mean、max、k-max pooling,大部分时候max表现就很好,因为分类任务对细粒度语义的要求不高,只抓住最大特征就好了。
Embedding表:中文选择char或word级别的输入,也可以两种都用,会提升些效果。如果训练数据充足(10w+),也可以从头训练
蒸馏BERT的logits,利用领域内无监督数据。
加深全连接:加到3、4层左右效果会更好。
TextCNN是很适合中短文本场景的强baseline,但不太适合长文本,因为卷积核尺寸通常不会设很大,无法捕获长距离特征。同时max-pooling也存在局限,会丢掉一些有用特征。
简单流程图:
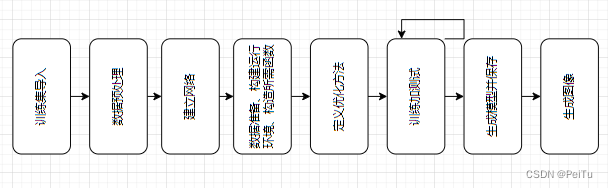
图1-3
二、具体实现
完整代码:
import os
from multiprocessing import cpu_count
import numpy as np
import paddle
import paddle.fluid as fluid
import matplotlib.pyplot as plt
paddle.enable_static()
data_root_path='./data/'
#创建数据集
def create_data_list(data_root_path):
with open(data_root_path + 'test_list.txt', 'w') as f:
pass
with open(data_root_path + 'train_list.txt', 'w') as f:
pass
with open(os.path.join(data_root_path, 'dict_txt.txt'), 'r', encoding='utf-8') as f_data:
dict_txt = eval(f_data.readlines()[0])
with open(os.path.join(data_root_path, 'data/Train.txt'), 'r', encoding='utf-8') as f_data:
lines = f_data.readlines()
i = 0
for line in lines:
title = line.split('\t')[-1].replace('\n', '')
l = line.split('\t')[0]
labs = ""
if i % 10 == 0:
with open(os.path.join(data_root_path, 'test_list.txt'), 'a', encoding='utf-8') as f_test:
for s in title:
lab = str(dict_txt[s])
labs = labs + lab + ','
labs = labs[:-1]
labs = labs + '\t' + l + '\n'
f_test.write(labs)
else:
with open(os.path.join(data_root_path, 'train_list.txt'), 'a', encoding='utf-8') as f_train:
for s in title:
lab = str(dict_txt[s])
labs = labs + lab + ','
labs = labs[:-1]
labs = labs + '\t' + l + '\n'
f_train.write(labs)
i += 1
print("数据列表生成完成!")
#把下载得数据生成一个字典
def create_dict(data_path, dict_path):
dict_set = set()
# 统计有多少种类别,分别对应的id,并显示出来以供后面的预测应用
id_and_className = {}
# 读取已经下载得数据
with open(data_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
# 把数据生成一个元组
for line in lines:
lineList = line.split('\t')
title = lineList[-1].replace('\n', '')
classId = lineList[0]
if classId not in id_and_className.keys():
id_and_className[classId] = lineList[1]
for s in title:
dict_set.add(s)
# 把元组转换成字典,一个字对应一个数字
dict_list = []
i = 0
for s in dict_set:
dict_list.append([s, i])
i += 1
# 添加未知字符
dict_txt = dict(dict_list)
end_dict = {"<unk>": i}
dict_txt.update(end_dict)
# 把这些字典保存到本地中
with open(dict_path, 'w', encoding='utf-8') as f:
f.write(str(dict_txt))
print("数据字典生成完成!")
print('类Id及其类别名称:', id_and_className)
# 获取字典的长度
def get_dict_len(dict_path):
with open(dict_path, 'r', encoding='utf-8') as f:
line = eval(f.readlines()[0])
return len(line.keys())
def data_mapper(sample):
data, label = sample
dataList=[]
for e in data.split(','):
if e=='':
print('meet blank')
else:
dataList.append(np.int64(e))
return dataList, int(label)
# 创建数据读取器train_reader
def train_reader(train_list_path):
def reader():
with open(train_list_path, 'r') as f:
lines = f.readlines()
# 打乱数据
np.random.shuffle(lines)
# 开始获取每张图像和标签
for line in lines:
data, label = line.split('\t')
yield data, label
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 1024)
# 创建数据读取器test_reader
def test_reader(test_list_path):
def reader():
with open(test_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
data, label = line.split('\t')
yield data, label
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 1024)
# 网络定义
def CNN_net(data, dict_dim, class_dim=14, emb_dim=128, hid_dim=128, hid_dim2=98):
emb = fluid.layers.embedding(input=data,size=[dict_dim, emb_dim])
conv_1 = fluid.nets.sequence_conv_pool(
input=emb,
num_filters=hid_dim,
filter_size=3,
act="tanh",
pool_type="max")
conv_2 = fluid.nets.sequence_conv_pool(
input=emb,
num_filters=hid_dim,
filter_size=4,
act="tanh",
pool_type="max")
conv_3 = fluid.nets.sequence_conv_pool(
input=emb,
num_filters=hid_dim2,
filter_size=4,
act="tanh",
pool_type="max")
fc1 = fluid.layers.fc(input=[conv_1, conv_2,conv_3], size=128, act='softmax')
bn = fluid.layers.batch_norm(input=fc1, act='relu')
fc2 = fluid.layers.fc(input= bn, size=64, act='softmax')
bn1 = fluid.layers.batch_norm(input=fc2, act='relu')
fc3 = fluid.layers.fc(input= bn1, size=class_dim, act='softmax')
return fc3
# 定义绘制训练过程的损失值和准确率变化趋势的方法draw_train_process
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
# 把生产的数据列表都放在自己的总类别文件夹中
data_path = os.path.join(data_root_path, 'data/Train.txt')
dict_path = os.path.join(data_root_path, "dict_txt.txt")
# 创建数据字典
create_dict(data_path, dict_path)
# 创建数据列表
create_data_list(data_root_path)
words = fluid.layers.data(name='words', shape=[1], dtype='int64', lod_level=1)
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
# 获取数据字典长度
dict_dim = get_dict_len('data/dict_txt.txt')
# 获取卷积神经网络
# 获取分类器
model = CNN_net(words, dict_dim)
# 获取损失函数和准确率
cost = fluid.layers.cross_entropy(input=model, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=model, label=label)
# 获取预测程序
test_program = fluid.default_main_program().clone(for_test=True)
# 定义优化方法
optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.002)
opt = optimizer.minimize(avg_cost)
# 创建一个执行器,CPU训练速度比较慢
# 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
#place = fluid.CPUPlace()
#place = fluid.CUDAPlace(0)
exe = fluid.Executor(place)
# 进行参数初始化
exe.run(fluid.default_startup_program())
train_reader = paddle.batch(reader=train_reader('./data/train_list.txt'), batch_size=128)
test_reader = paddle.batch(reader=test_reader('./data/test_list.txt'), batch_size=128)
feeder = fluid.DataFeeder(place=place, feed_list=[words, label])
EPOCH_NUM=5
model_save_dir = './infer_model/'
# 开始训练
for pass_id in range(EPOCH_NUM):
# 进行训练
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
all_train_iter = all_train_iter + 100
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
if batch_id % 100 == 0:
print('Train Pass:%d, Batch:%d, Cost:%0.5f, Acc:%0.5f' % (pass_id, batch_id, train_cost[0], train_acc[0]))
# 进行测试
test_costs = []
test_accs = []
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
test_costs.append(test_cost[0])
test_accs.append(test_acc[0])
# 计算平均预测损失在和准确率
test_cost = (sum(test_costs) / len(test_costs))
test_acc = (sum(test_accs) / len(test_accs))
print('Test:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, test_cost, test_acc))
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir,
feeded_var_names=[words.name],
target_vars=[model],
executor=exe)
print('训练模型保存完成!')
draw_train_process("training", all_train_iters, all_train_costs, all_train_accs, "trainning cost", "trainning acc")
说明:本次网络仿照TextCNN样式设计,相关参数可自行调试选出最优数值,预测模块已被删除,训练集的选择是经处理的训练集
训练集地址:中文新闻文本标题分类 - 飞桨AI Studio (baidu.com)
三、结果及分析
5轮训练:
![]() 图2-1
图2-1
![]() 图2-2
图2-2
![]() 图2-3
图2-3
![]() 图2-4
图2-4
![]() 图2-5
图2-5
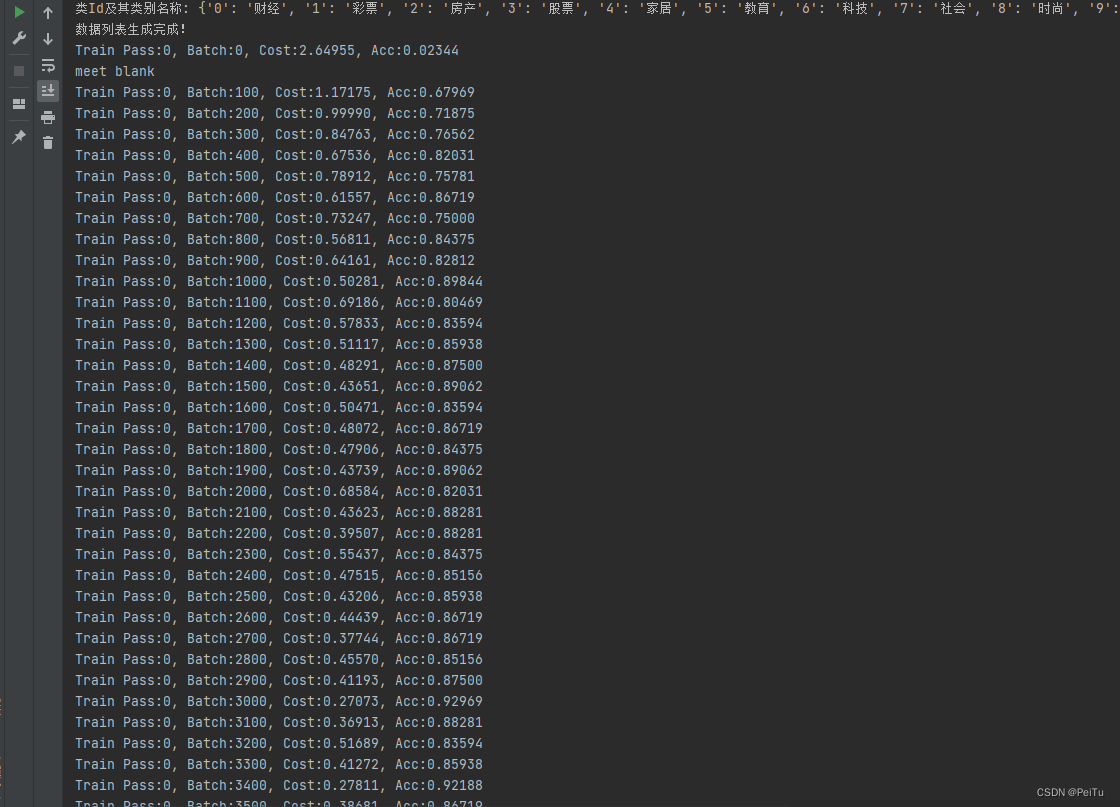
图2-6
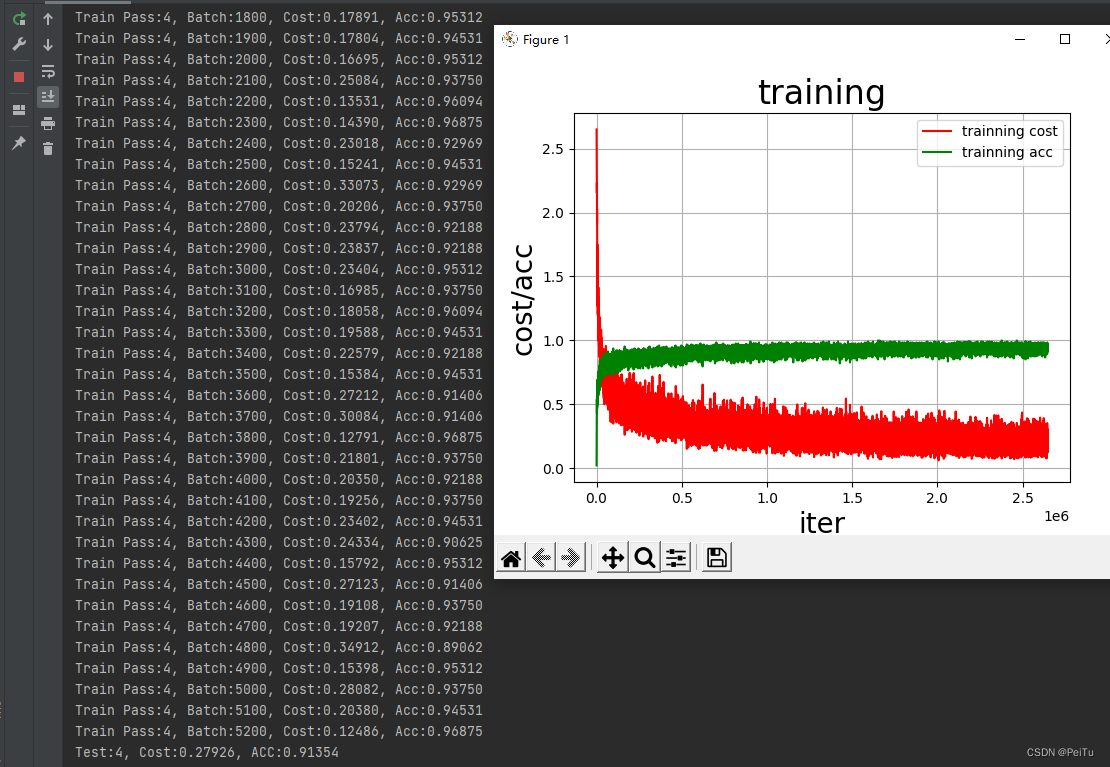
图2-7
分析:从数值变化上来看,从0到0.9所花的训练较少,趋向很快,由于数据集为THUCNews(740000多条数据)新闻标题,作为输入数据的它并没有图片大,所以CNN网络处理的速度一般较快,cpu运行所用时间约1.5-2.5个小时,改用GPU的话速度应该会更快。测试的数值呈线性,并没有发现随着训练的增加而出现数值下降倾向。
从图像(图2-7)上看,一目了然,随着训练量的增加,准确率上升、误差减少,趋向稳定后,准确率在0.9之间波动,而误差(损失值)0.1-0.4之间波动。
四、总结
处理NLP任务首先需要选择合适的网络模型,比如TextCNN、TextRNN、LSTM、GRU、BiLSTM、RCNN、EntNet等等。当然,有些NLP任务也可以用机器学习方法去解决,至于哪种任务用哪种方法,需要根据实际情况去选择。解决一个NLP的任务可能有多种方案,但是哪一个方案更合适需要我们不断地去分析尝试。比如,二次文本分类,可以尝试着去组合多种网络,以求达到最优效果。确定NLP任务后,首先需要对数据进行分析,任务具体是干什么需要什么功能,并且要深入地分析理解数据,知道数据的含义,这样可以帮助制定解决方案,同时也有利于进行数据预处理。数据要采取什么样的处理方式,需要对数据进行深入地分析后才能知道。确定好处理方式后,预处理数据。这一步和前面的数据分析关系很强,很多预处理操作都是基于对数据的分析而来,一般对文本预处理包含分词、去除停用词、训练词向量、文本序列化等等,当然,对于有的任务还包含同义词替换、训练词权重等等。再接着就是搭建模型,具体使用什么模型得根据具体任务来定。最后就是优化模型,常用的操作有调参、更改网络结构、针对评价指标优化等等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









