







目录
1. 导入所需要的python包
import os
import glob
import cv2
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Dense, Flatten主要的版本如下:
python:3.7.10
cv2(opencv): 4.5.3.56
numpy: 1.19.5
tensorflow:2.3.1
matplotlib:3.4.3
注:上面的版本只是参考,代表我用这些能成功运行,你们用自己的版本大概率也是能成功跑起来的,万一不幸出现了版本问题,可以选择参考我这个版本
2. 准备数据集
我使用的数据集包括了2979张佩戴口罩的人脸图片,2994张未佩戴口罩的人脸图片,最重要的是还包括了2994张未正确佩戴口罩的图片(也就是那些戴口罩漏鼻子的)!把这部分也作为未佩戴口罩的数据集,在极高的实际意义。

所有图片均是由人脸识别模块切割出,只包含人脸这一小部分图像,对训练的准确性有极大的提高,还进行了旋转操作实现数据增强
未正确佩戴口罩数据展示:

3. 训练模型
3.1 定义参数变量
# 图片尺寸,在图片裁剪,网络输入层会用到
input_shape = (128, 128, 3)
# 初始学习率
learning_rate = 0.001
# 学习率衰减值
lr_decay = 0.1
# 训练集占总数据集比例
ratio1 = 0.9
# 从训练集中拆分验证集,验证集占的比例
ratio2 = 0.1
# 批处理一次的图片数,一次输入128张图片到神经网络计算
batch_size = 128
# 训练迭代次数
epochs = 12做深度学习很大一部分工作是在调参上,要学会这样把所有可能会有更改的参数列在最前,后面的程序中来调用这些变量名就行。有的参数会在多个地方被调用,在修改时非常不方便,像我这样就只需要在最前面改一次就行,也不会出现漏改某一个的情况。
还有一点,这样写其实更直观,一眼就看完了整个模型的所有参数。
3.2 数据读取与预处理
def split():
# dirdata是你的整个数据集的根目录
dir_data = r"../input/mask-images/Dataset"
# 下面三个路径就分别是我的三种数据的目录,如果你的数据只有戴口罩核没带口罩两种,那就删一个就行
dir_mask = os.path.join(dir_data, 'with_mask')
dir_nomask = os.path.join(dir_data, 'without_mask')
dir_nomask_incorrect = os.path.join(dir_data, "mask_weared_incorrect")
# 遍历文件及,将每一个图片的地址依次存入列表中
path_mask = [os.path.abspath(fp) for fp in glob.glob(os.path.join(dir_mask, '*.png'))]
path_nomask = [os.path.abspath(fp) for fp in glob.glob(os.path.join(dir_nomask, '*.png'))]
# 把未正确佩戴口罩的图片加入到没带口罩的类别
path_nomask = path_nomask + [os.path.abspath(fp) for fp in glob.glob(os.path.join(dir_nomask_incorrect, '*.png'))]
path_all = path_mask + path_nomask
# 生成标签,1代表佩戴了口罩,0代表未佩戴口罩
label_all = [1] * len(path_mask) + [0] * len(path_nomask)
# 十字交叉分割,把所有的图片路径和标签通过shuffle=True打乱顺序,然后分ratio1比例的给训练集图片和训练集标签,剩下的作为测试集
path_train, path_test, label_train, label_test = train_test_split(path_all, label_all, shuffle=True, train_size=ratio1)
return path_train, path_test, label_train, label_test
def createset(path, label):
data_set = []
label_set = []
# 遍历路径列表中的路径以及标签列表里的标签
for (one_path, one_label) in zip(path,label):
# cv2读取图片为numpy矩阵
image = cv2.imread(one_path)
# 缩放图片为指定大小,由于我的数据集是已经全部缩放到了128*128*3,这里就不再需要了
# image_resize = cv2.resize(image, (128, 128), cv2.INTER_AREA)
# cv2读取的矩阵值在0-255,我们选择除以255将图片归一化
image = image/255.
data_set.append(image)
label_set.append(one_label)
# 转为矩阵形式返回
return np.array(data_set), np.array(label_set)3.3 搭建神经网络框架
def MODEL():
model = Sequential()
model.add(Conv2D(filters=64, kernel_size=3, strides=1, padding="same", activation="relu", input_shape=input_shape))
model.add(Conv2D(filters=64, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Conv2D(filters=128, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=128, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Flatten())
model.add(Dense(units=1024, activation="relu"))
model.add(Dense(units=512, activation="relu"))
model.add(Dropout(0.4))
model.add(Dense(units=2, activation="softmax"))
model.compile(optimizer=tf.keras.optimizers.Adam(lr=learning_rate, decay=lr_decay),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
# tf.keras.utils.plot_model(model,to_file="model",show_layer_names=True,show_shapes=True)
return model下面这是通过model.summary()打印出来的网络结构:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 128, 128, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 128, 128, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 64, 64, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 64, 64, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 64, 64, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 32, 32, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 32, 32, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 32, 32, 256) 590080
_________________________________________________________________
conv2d_6 (Conv2D) (None, 32, 32, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 16, 16, 256) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 16, 16, 512) 1180160
_________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 512) 2359808
_________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 8, 8, 512) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 8, 8, 512) 2359808
_________________________________________________________________
conv2d_11 (Conv2D) (None, 8, 8, 512) 2359808
_________________________________________________________________
conv2d_12 (Conv2D) (None, 8, 8, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 4, 4, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 8192) 0
_________________________________________________________________
dense (Dense) (None, 1024) 8389632
_________________________________________________________________
dense_1 (Dense) (None, 512) 524800
_________________________________________________________________
dropout (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 2) 1026
=================================================================
Total params: 23,630,146
Trainable params: 23,630,146
Non-trainable params: 0
_________________________________________________________________
ValueError
Cannot embed the 'model' image format我搭建的网络模型看起来似乎层数很多,其实这恰巧是非常巧妙的地方,我学习了VGG-19模型的思想:卷积全部使用3*3小卷积核,通过反复多次的卷积能达到和大卷积核相同的感受野,但是计算量却更小,两个3*3的卷积层的感受野是等同于一个5*5卷积核;三个3*3的感受野等同7*7。
要想提高卷积神经网络的性能如何选择卷积核核参数呢?其实就是卷积核小而深,单独较小的卷积核也是不好的,只有堆叠很多小的卷积核,模型的性能才会提升。
VGG的论文里提到了许多神经网络搭建与训练技巧,详细的可以参考中文翻译版的论文,强烈建议学习,对自己以后模型搭建训练绝对有帮助!!!
卷积神经网络VGG 论文细读 + Tensorflow实现 - 简书 (jianshu.com)
3.4 结果可视化函数
这两个函数用于最后绘制训练的loss和accuracy曲线
def drawloss():
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss')
plt.plot(range(epochs), valid_loss, label='test_loss')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()
def drawacc():
plt.figure()
plt.plot(range(epochs), train_accuracy, label='train_accuracy')
plt.plot(range(epochs), valid_accuracy, label='test_accuracy',)
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()3.5 训练并测试
if __name__ == '__main__':
path_train, path_test, label_train, label_test = split()
data_train,label_train = createset(path_train, label_train)
data_test, label_test = createset(path_test, label_test)
print("训练集图片数:",int(data_train.shape[0]*0.9))
print("验证集图片数:",int(data_train.shape[0]*0.1))
print("测试集图片数:",data_test.shape[0])
# 初始化网络模型
model = MODEL()
# 进行训练
output = model.fit(x=data_train,
y=label_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=ratio2
)
# 保存网络模型
model.save("mask.h5")
# 可视化训练过程
history_predict = output.history
train_loss = history_predict['loss']
train_accuracy = history_predict['accuracy']
valid_loss = history_predict['val_loss']
valid_accuracy = history_predict['val_accuracy']
drawacc()
drawloss()
# 计算测试集准确率
acc = model.evaluate(data_test,label_test, batch_size=batch_size, verbose=1)
print("test accuracy:", acc[1])训练模型用的函数就是model.fit(),参数解释:
- x: 训练数据的 Numpy 数组(如果模型只有一个输入), 或者是 Numpy 数组的列表(如果模型有多个输入)。 如果模型中的输入层被命名,你也可以传递一个字典,将输入层名称映射到 Numpy 数组。 如果从本地框架张量馈送(例如 TensorFlow 数据张量)数据,
x可以是None(默认)。 - y: 目标(标签)数据的 Numpy 数组(如果模型只有一个输出), 或者是 Numpy 数组的列表(如果模型有多个输出)。 如果模型中的输出层被命名,你也可以传递一个字典,将输出层名称映射到 Numpy 数组。 如果从本地框架张量馈送(例如 TensorFlow 数据张量)数据,y 可以是
None(默认)。 - batch_size: 整数或
None。每次梯度更新的样本数。如果未指定,默认为 32。 - epochs: 整数。训练模型迭代轮次。一个轮次是在整个
x和y上的一轮迭代。 请注意,与initial_epoch一起,epochs被理解为 「最终轮次」。模型并不是训练了epochs轮,而是到第epochs轮停止训练。 - verbose: 0, 1 或 2。日志显示模式。 0 = 安静模式, 1 = 进度条, 2 = 每轮一行
- validation_split: 0 和 1 之间的浮点数。用作验证集的训练数据的比例。 模型将分出一部分不会被训练的验证数据,并将在每一轮结束时评估这些验证数据的误差和任何其他模型指标。 验证数据是混洗之前
x和y数据的最后一部分样本中。
可参考官方文档:
3.6 补充:加载模型对单张图片进行预测
注:我这只是演示如何用代码操作,我读取的这三张图片有可能是被用于训练模型的(我也不知道十字划分中有没有把他们划入训练集),所以理论上是不能选这三张图片进行测试的!!!只能选测试集里的。
可以在你们的数据集的文件夹中单独拎几张出来,留到这里单独使用
再次声明:此段代码仅用于演示如何写代码对单张图片预测,实际不能像我这么选图片
import cv2
import numpy as np
import tensorflow as tf
model =tf.keras.models.load_model('../input/mask-images/mask.h5')
image1 = cv2.imread('../input/mask-images/Dataset/Dataset/with_mask/1.png')/225.
image2 = cv2.imread('../input/mask-images/Dataset/Dataset/without_mask/1.png')/255.
image3 = cv2.imread('../input/mask-images/Dataset/Dataset/mask_weared_incorrect/1.png')/255.
imgs=[image1,image2,image3]
print(model.predict(np.array(imgs)))
print(np.argmax(model.predict(np.array(imgs)),axis=1))xis=1))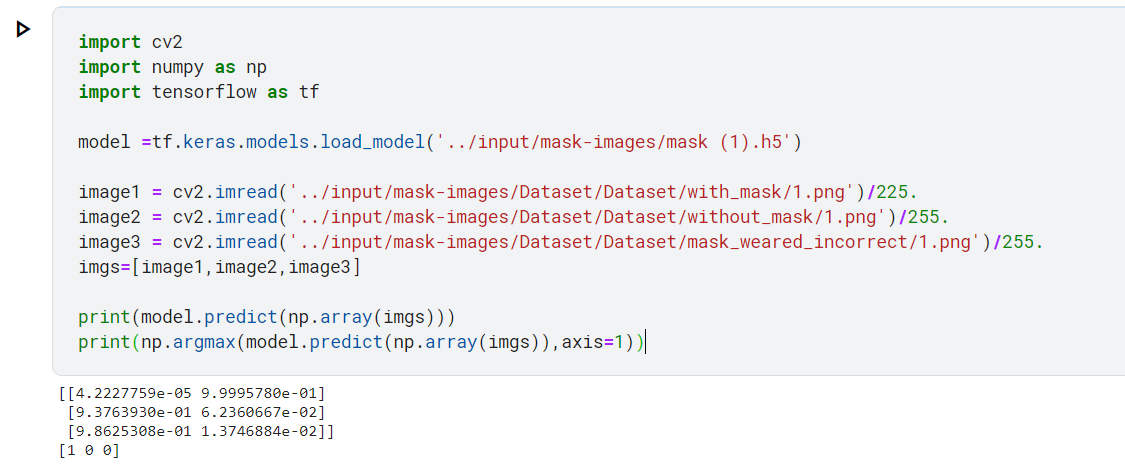
4. 结果展示
4.1 训练过程
4.2 loss和accuracy图像


可以看到,整个训练过程的收敛性是非常好的,最后在验证集的准确率也稳定到了97%左右
4.3 测试集准确率
![]()
对近900张测试集图片在准确率达到了97.5% ,效果已经非常不错了
5. 完整代码
import os
import glob
import cv2
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dropout, Dense, Flatten
# 图片尺寸,在图片裁剪,网络输入层会用到
input_shape = (128, 128, 3)
# 初始学习率
learning_rate = 0.001
# 学习率衰减值
lr_decay = 0.1
# 训练集占总数据集比例
ratio1 = 0.9
# 从训练集中拆分验证集,验证集占的比例
ratio2 = 0.1
# 批处理一次的图片数,一次输入128张图片到神经网络计算
batch_size = 128
# 训练迭代次数
epochs = 12
def MODEL():
model = Sequential()
model.add(Conv2D(filters=64, kernel_size=3, strides=1, padding="same", activation="relu", input_shape=input_shape))
model.add(Conv2D(filters=64, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Conv2D(filters=128, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=128, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=256, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(Conv2D(filters=512, kernel_size=3, strides=1, padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=2, strides=2, padding="same"))
model.add(Flatten())
model.add(Dense(units=1024, activation="relu"))
model.add(Dense(units=512, activation="relu"))
model.add(Dropout(0.4))
model.add(Dense(units=2, activation="softmax"))
model.compile(optimizer=tf.keras.optimizers.Adam(lr=learning_rate, decay=lr_decay),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
#tf.keras.utils.plot_model(model,to_file="model",show_layer_names=True,show_shapes=True)
return model
def split():
# 整个dirdata是你的整个数据集的根目录
dir_data = r"../input/mask-images/Dataset"
# 下面三个路径就分别是我的三种数据的目录,如果你的数据只有戴口罩核没带口罩两种,那就删一个就行
dir_mask = os.path.join(dir_data, 'with_mask')
dir_nomask = os.path.join(dir_data, 'without_mask')
dir_nomask_incorrect = os.path.join(dir_data, "mask_weared_incorrect")
# 遍历文件及,将每一个图片的地址依次存入列表中
path_mask = [os.path.abspath(fp) for fp in glob.glob(os.path.join(dir_mask, '*.png'))]
path_nomask = [os.path.abspath(fp) for fp in glob.glob(os.path.join(dir_nomask, '*.png'))]
# 把未正确佩戴口罩的图片加入到没带口罩的类别
path_nomask = path_nomask + [os.path.abspath(fp) for fp in glob.glob(os.path.join(dir_nomask_incorrect, '*.png'))]
path_all = path_mask + path_nomask
# 生成标签,1代表佩戴了口罩,0代表未佩戴口罩
label_all = [1] * len(path_mask) + [0] * len(path_nomask)
# 十字交叉分割,把所有的图片路径和标签通过shuffle=True打乱顺序,然后分ratio1比例的给训练集图片和训练集标签,剩下的作为测试集
path_train, path_test, label_train, label_test = train_test_split(path_all, label_all, shuffle=True, train_size=ratio1)
return path_train, path_test, label_train, label_test
def createset(path, label):
data_set = []
label_set = []
# 遍历路径列表中的路径以及标签列表里的标签
for (one_path, one_label) in zip(path,label):
# cv2读取图片为numpy矩阵
image = cv2.imread(one_path)
# 缩放图片为指定大小,由于我的数据集是已经全部缩放到了128*128*3,这里就不再需要了
# image_resize = cv2.resize(image, (128, 128), cv2.INTER_AREA)
# cv2读取的矩阵值在0-255,我们选择除以255将图片归一化
image = image/255.
data_set.append(image)
label_set.append(one_label)
# 转为矩阵形式返回
return np.array(data_set), np.array(label_set)
def drawloss():
plt.figure()
plt.plot(range(epochs), train_loss, label='train_loss')
plt.plot(range(epochs), valid_loss, label='test_loss')
plt.legend()
plt.xlabel('epochs')
plt.ylabel('loss')
plt.show()
def drawacc():
plt.figure()
plt.plot(range(epochs), train_accuracy, label='train_accuracy')
plt.plot(range(epochs), valid_accuracy, label='test_accuracy',)
plt.legend()
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
if __name__ == '__main__':
path_train, path_test, label_train, label_test = split()
data_train,label_train = createset(path_train, label_train)
data_test, label_test = createset(path_test, label_test)
print("训练集图片数:",int(data_train.shape[0]*0.9))
print("验证集图片数:",int(data_train.shape[0]*0.1))
print("测试集图片数:",data_test.shape[0])
# 初始化网络模型
model = MODEL()
# 进行训练
output = model.fit(x=data_train,
y=label_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_split=ratio2
)
# 保存网络模型
model.save("mask.h5")
# 可视化训练过程
history_predict = output.history
train_loss = history_predict['loss']
train_accuracy = history_predict['accuracy']
valid_loss = history_predict['val_loss']
valid_accuracy = history_predict['val_accuracy']
drawacc()
drawloss()
# 计算测试集准确率
acc = model.evaluate(data_test,label_test, batch_size=batch_size, verbose=1)
print("test accuracy:", acc[1])
















 7115
7115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











