






Erlang学习笔记
1 如何安装配置Erlang
1.1下载Erlang
进入网站下载http://erlang.org
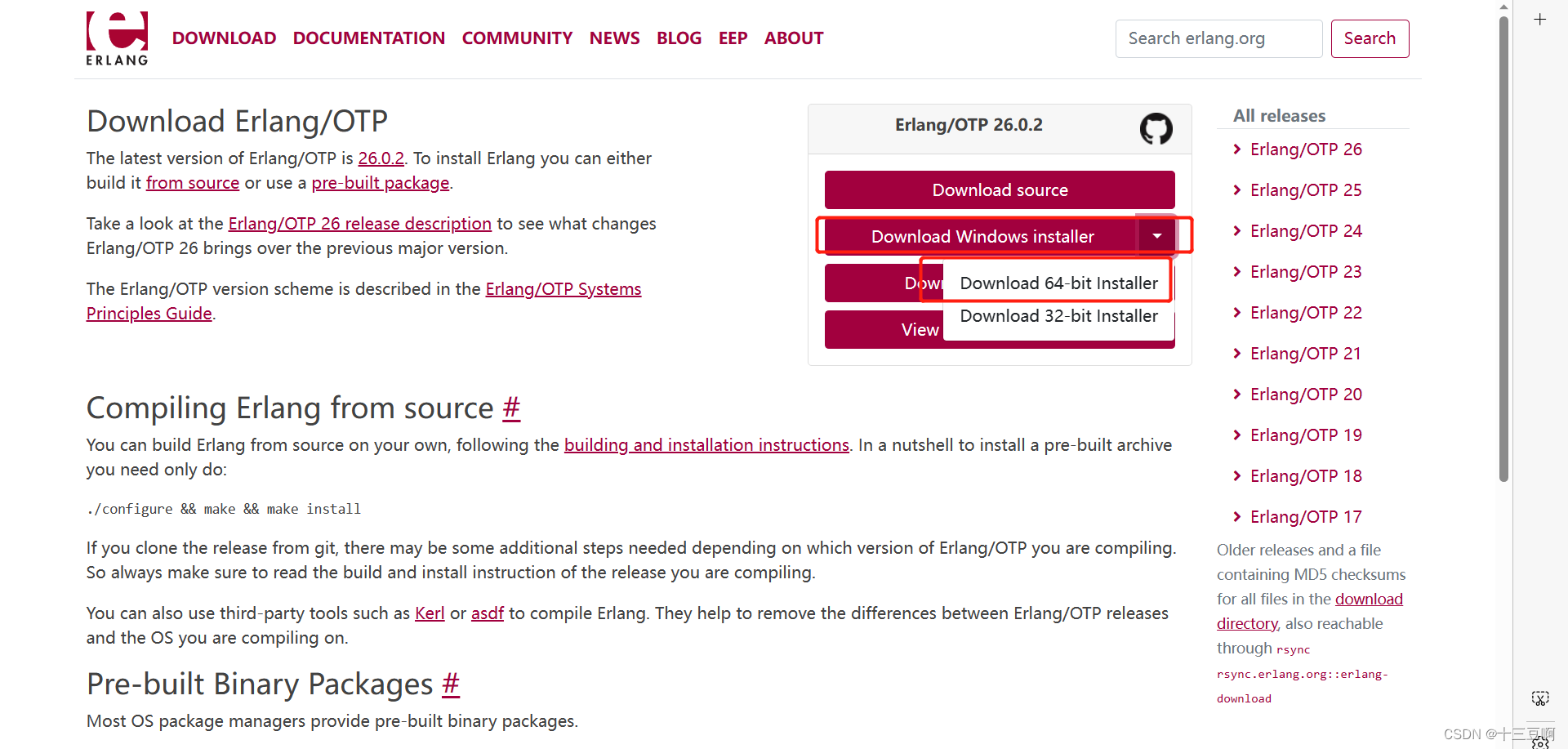
1.2 安装Erlang
选择自己安装的地方
直接安装
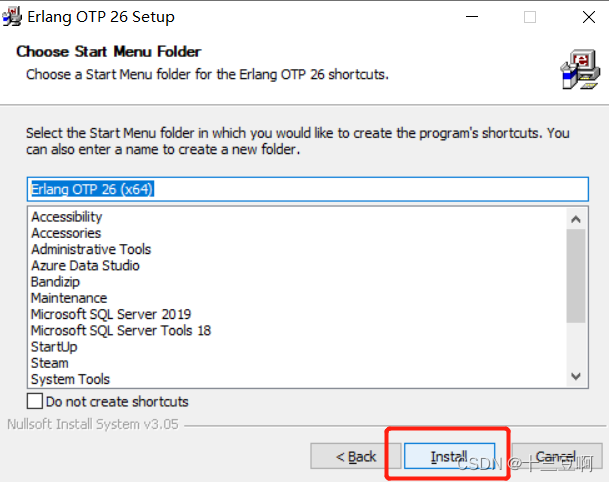
右键单击此电脑 -> 属性-> 高级系统设置-> 环境变量-> 系统变量 ->path-> 新建,把自己erlang的路径复制到path的新建路径中
新增完记得点确定
最后查看是否成功,当出现版本就是成功了
1.3 配置环境
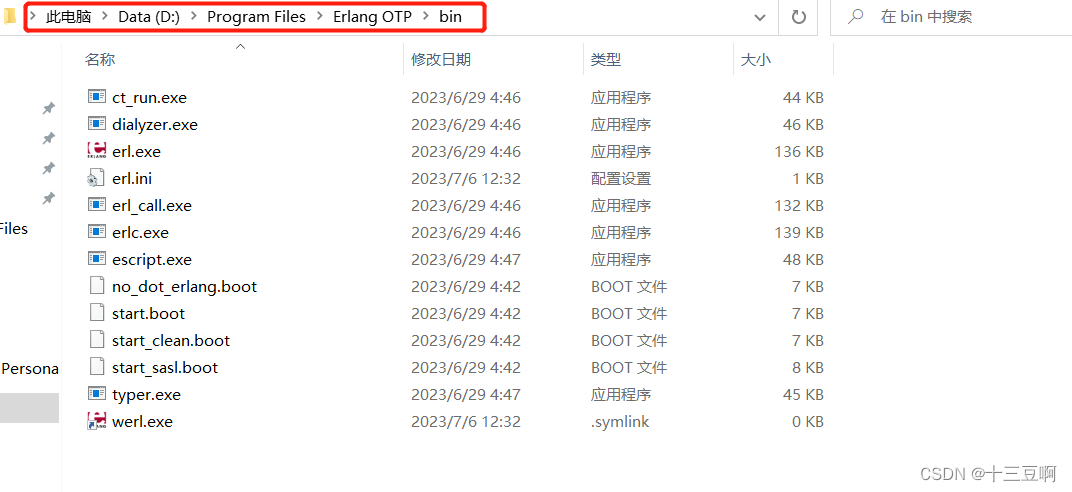
首先找到自己安装Erlang的bin环境下
2 如何使用Erlang
2.1 并发建模
我们现在将散步这一个情景作为我们的例子来进行建模。假设有四个人出去散步,另外还有两条狗和一大群兔子。这些人正在相互交谈,而狗则想要追逐兔子。
如果我们想要用Erlang来模拟这个情景,需要四个模块,分别是person(人)、dog(狗)、rabbit(兔子)和world(世界)。person的代码会放在名为person.erl的文件里,person.erl的结构大概如下。
-module(person).
-export([init/1]).
init(Name)->...
那么我们继续来讲解一下这个结构:
1.第1行-module(person).的意思是此文件包含用于person模块的代码。它应该与文件名一致(除了.erl这个文件扩展名)。模块名必须以一个小写字母开头。
2.模块声明之后是一条导出声明。导出声明指明了模块里哪些函数可以从模块外部进行调用。它们类似于许多编程语言里的public声明。没有包括在导出声明里的函数是私有的,无法在模块外调用。而-export([init/1]).语法的意思是带有一个参数(/1指的就是这个意思,而不是除以1)的函数init可以在模块外调用。方括号[ … ]的意思是“列表”,因此这条声明的意思是我们想要从模块里导出一个函数列表。
2.2 开始模拟
要启动程序,可以调用world:start()。它定义在一个名为world的模块里,这个模块的开头部分就像这样:
-module(world).
-export([start/0]).
start()->
Zhangsan=spawn(person, init, [”zhangsan“]),
Lisi=spawn(person, init, [”Lisi“]),
Caixukun=spawn(person, init, [”caixukun“]),
Shisandou=spawn(person, init, [”shisandou“]),
Dog=spawn(dog, init, [”shisandou“]),
Rabbit=spawn(person, init, [”Rabbit“]),
其中spawn是一个Elang基本函数,它会创建一个并发进程并返回一个进程标识符,spawn主要结构如下:
spawn(ModName, FuncName, [”Arg1, Arg2,...,ArgN“]),
当Erlang运行时系统执行spawn时,它会创建一个新进程(不是操作系统的进程,而是一个由Erlang系统管理的轻量级进程)。当进程创建完毕后,它便开始执行参数所指定的代码。ModName是包含想要执行代码的模块名。FuncName是模块里的函数名,而[Arg1, Arg2, …]是一个列表,包含了想要执行的函数参数。
2.3 发送消息
启动模拟之后,我们希望在程序的不同进程之间发送消息。在Erlang里,各个进程不共享内存,只能通过发送消息来与其他进程交互。这就是现实世界里的物体行为。
假设Zhangsan想对Caixukun说jinitaimei,我们可以这样子写代码:
Caixukun ! {self(Zhangsan), "jinitaimei"}
Pid ! Msg语法的意思是发送消息Msg到进程Pid。大括号里的self()参数标明了发送消息的进程(在此处是Zhangsan)。
2.4 接收消息
Caixukun要想收到Zhangsan的消息,首先他要这样子写代码:
receive
{from, message}->
...
end
当Caixukun的进程接收到一条消息时,变量From会绑定为Zhangsan,这样Caixukun就知道消息来自何处,变量Message则会包含此消息。
3.Erlang速览
接下来,我们学习如何制作一个文件服务器,使其拥有两个并发进程:一个进程代表服务器,另一个代表客户端
3.1Shell
我们大多数时间会花费在Erlang的shell里。输入一条表达式,shell就会执行这条表达式并显示出结果,我们在操作系统的$中输入erl启动了Erlang shell。Erlang shell以横幅信息和计数提示符1>作为响应。然后输入一个表达式,并得到了执行和显示。
3.1.1 =
可以用=操作符给变量赋值(严格来说是给变量绑定一个值),要注意的是不能重新绑定变量。Erlang是一种函数式语言,所以一旦定义了
X = 123,那么X永远就是123,不允许改变。
3.1.2 变量和原子
Erlang的变量以大写字母开头。所以X、This和A_long_name都是变量。以小写字母开头的名称(比如monday或friday)不是变量,而是符号常量,它们被称为原子(atom)。
3.2 进程、模块和编译
Erlang程序是由许多并行的进程构成的。进程负责执行模块里定义的函数。模块则是扩展名为.erl的文件,运行前必须先编译它们。编译某个模块之后,就可以在shell或者直接从操作系统环境的命令行里执行该模块中的函数了。
3.2.1 编译并运行 Hello World
现在我创建一个含有以下内容的erl文件
-module(hello).
-export([start/0]).
start() ->
io:format("Hello world~n").

为了编译并运行它,我们从保存hello.erl的目录里启动Erlang shell,然后执行下面的操作:
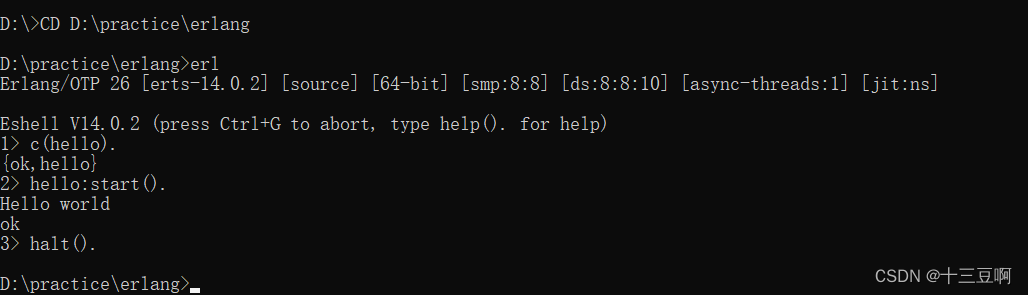
c(hello)命令编译了hello.erl文件里的代码。{ok, hello}的意思是编译成功。现在代码已准备好运行了。第2行里执行了hello:start()函数。第3行里停止了Erlang shell
并且我们会发现多了在原来的文件中多出了一个文件

3.3 并发
我们已经了解了如何编译单个模块。那么如何编写并发程序呢?Erlang的基本并发单元是进
程(process)。一个进程是一个轻量级的虚拟机,只能通过发送和接收消息来与其他进程通信。
如果你想让一个进程做点什么,就要给它发送一个消息,还可能需要等待答复。将要编写的第一个并发程序是一个文件服务器。要在两台机器之间传输文件,需要两个程序:
第一台机器上运行的客户端和第二台机器上运行的服务器。为了实现这一点,我们将制作两个模
块:afile_client和afile_server。
3.3.1 服务器代码
文件服务器由一个名为afile_server的模块实现。这里再提醒一下,进程和模块类似于对
象和类。用于进程的代码包含在模块里,要创建一个进程,需要调用spawn(…),创建进程的
实际操作由这个基本函数完成
-module(afile_server).
-export([start/1, loop/1]).
start(Dir)-> spawn(afile_server, loop, [Dir]).
loop(Dir)->
receive
{Client, list_dir}->
Client ! {self(), file:list_dir(Dir)};
{Client, {get_file, File}}->
Full = filename:join(Dir, File),
Client ! {self(), file:read_file(Full)}
end,
loop(Dir).
其实架构主要是这样子的
loop(Dir)->
等待指令
receive
command->
做什么
end,
loop(Dir).
这就是用Erlang编写无限循环的方法。变量Dir包含了文件服务器当前的工作目录。我们在
这个循环内等待指令,接收到指令时我们会遵从,然后再次调用自身来获取下一个指令。
另一点要注意的是,loop函数永远不会返回。在顺序编程语言里,必须要极其小心避免无
限循环,因为只有一条控制线,如果这条线卡在循环里就有麻烦了。Erlang则没有这个问题。服
务器只是一个在无限循环里处理请求的程序,与我们想要执行的其他任务并行运行。
现在仔细查看接收语句。回忆一下,它看起来就像这样:
receive
{Client, list_dir}->
Client ! {self(), file:list_dir(Dir)};
{Client, {get_file, File}}->
Full = filename:join(Dir, File),
Client ! {self(), file:read_file(Full)}
end,
这段代码的意思是如果接收到{Client, list_dir}消息,就应该回复一个文件列表;如果
接收到的消息是{Client, {get_file, File}},则回复这个文件。作为模式匹配过程的一部分,
Client变量在收到消息时会被绑定,其中要注意以下三点:1.回复给谁,2.self()的用法,在这里self()是服务器的标识符, 模式匹配被用于选择消息
这里需要再说一下receive语句的两种模式:
receive
pattern1->
Action1;
pattern2->
action2;
Erlang编译器和运行时系统会正确推断出如何在收到消息时运行适当的代码。不需要编写任
何的if-then-else或switch语句来设定该做什么。这是模式匹配带来的乐趣之一,会为你节省
大量工作
接下来可以测试一下写的这段代码有没有问题
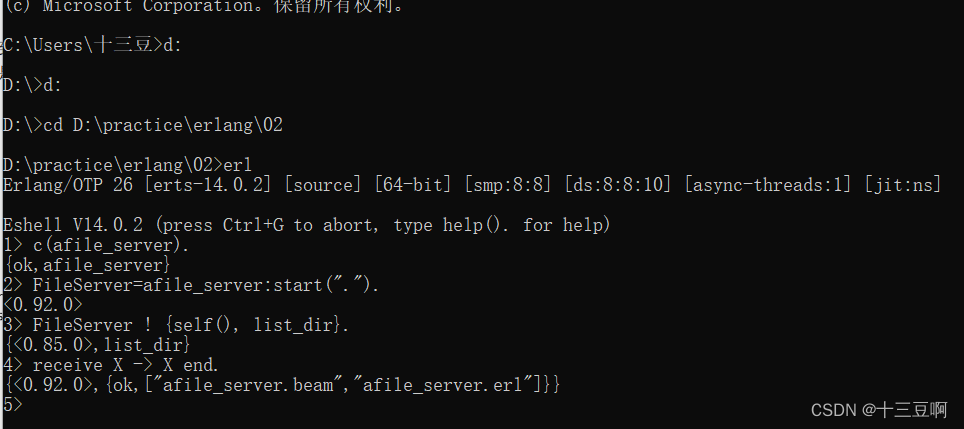
(1)1.1> c(afile_server).用来编译模块
(2)2> FileServer=afile_server:start(“.”).
<0.92.0>是用来执行函数并且返回进程标识符
(3)3> FileServer ! {self(), list_dir}.
{<0.85.0>,list_dir}
这里面FileServer是pid,{<0.85.0>,list_dir}是message,<0.85.0>是文件服务器回复的对象
(4)4> receive X -> X end.
{<0.92.0>,{ok,[“afile_server.beam”,“afile_server.erl”]}}
receive X -> X end接收文件服务器发送的回复。它返回元组{<0.47.0>, {ok, …}。
该元组的第一个元素<0.47.0>是文件服务器的进程标识符。第二个参数是file:list_dir(Dir)
函数的返回值,它在文件服务器进程的接收循环里得出。
3.3.2 客户端代码
-module(afile_client).
-export([ls/1, get_file/2]).
ls(Server) ->
Server ! {self(), list_dir},
receive
{Server, FileList}->
FileList
end.
get_file(Server, File)->
Server ! {self(), {get_file, File}},
receive
{Server, Content} ->
Content
end.
如果对比afile_clien与afile_server的代码,就会发现一种美妙的对称性。只要客户端
里有Server ! …这类send语句,服务器里就会有receive模式,反之亦然
receive
{Client,pattern}->
...
end
现在要重启shell并重新编译所有代码,展示客户端和服务器如何共同工作
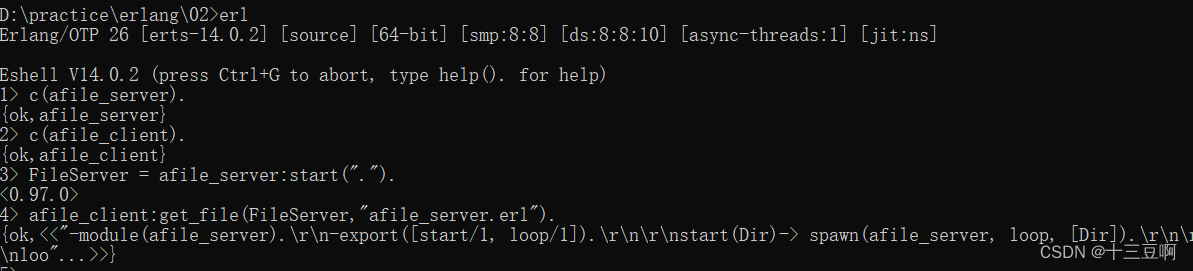
现在在shell里运行的代码和之前代码的唯一区别,是把接口程序抽象出来放入单独的模块
里。我们隐藏了客户端和服务器之间消息传递的细节,因为没有其他程序对此感兴趣。
到目前为止,你看到了一个完整文件服务器的基础部分,但它尚未完成。还有很多的细节问
题,涉及启动和停止服务器、连接某个套接字(socket)等,在这里不会提及。
从Erlang的角度看,如何启动和停止服务器,连接套接字,从错误中恢复等都是琐碎的细节。
问题的本质在于创建并行进程,以及发送和接收消息。
4.Erlang基础
4.1 启动和停止 Erlang shell
在Unix系统(包括Mac OS X)里,需要从命令提示里启动Erlang shell;在Windows系统里则
是点击Window开始菜单里的Erlang图标。

停止系统最简单的方式是按Ctrl+C(Windows里是Ctrl+Break①)后接a(“abort”的简写),
就像Ctrl+C会变成下面这样:

输入a会立即停止系统,这可能导致某些数据的损坏。要实现受控关闭,可以输入q()(“quit”
的简写)。

这样就以一种受控的方式停止了系统。所有打开的文件都被刷入缓存并关闭,数据库(如果
正在运行的话)会被停止,所有的应用程序都以有序的方式关停。q()是init:stop()命令在shell
里的别名。要立即停止系统,应执行表达式erlang:halt()。
4.1.1 在shell里执行命令
当shell准备好接受表达式时,会打印出命令提示。
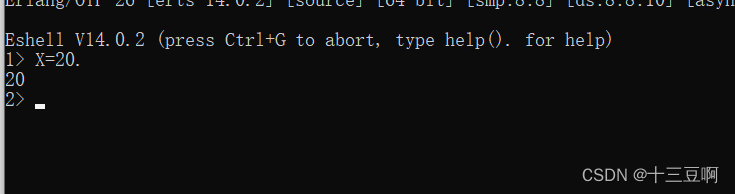
这次对话从命令1开始(也就是shell打印出的1>)。它的意思是启动了一个新的Erlang shell。
每当在本书里看到以1>开头的对话时,就必须启动一个新的shell才能准确再现本书里的示例。当
某个示例以大于1的提示数字开头时,就暗示此shell会话是之前示例的延续,此时无需启动新
shell。
在提示处输入一个表达式。shell执行了这个表达式并打印出结果

shell又打印出了一个提示,这一次是用于表达式2(因为每次输入一个新表达式,命令数字
就会增加)。
在第2行里,百分号字符(%)代表一段注释的起点。从百分号到行尾的所有文字都被当作
注释,shell和Erlang编译器会忽略它们。
4.2 简单的整数运算
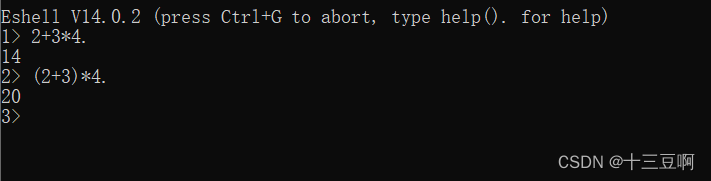
Erlang可以用任意长度的整数执行整数运算。在Erlang里,整数运算是精确的,因此无需担
心运算溢出或无法用特定字长(word size)来表示某个整数。
4.3 变量
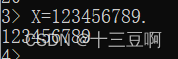
请注意所有变量名都必须以大写字母开头。
如果想知道一个变量的值,只需要输入变量名。
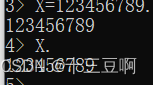
X既然已经有一个值了,就可以使用它
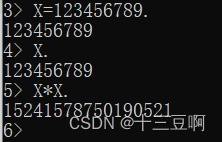
但是,如果试图给变量X指派一个不同的值,就会得到一条错误消息。

这个错误的原因是因为在这里面=不是用来赋值的,而是一个模式匹配操作符
4.3.1 Erlang的变量不会变
Erlang的变量是一次性赋值变量(single-assignment variable)。顾名思义,它们只能被赋值一
次。如果试图在变量被设置后改变它的值,就会得到一个错误(事实上,你将得到的是我们刚
才看到的“badmatch”,即不匹配错误)。已被指派一个值的变量称为绑定变量,否则称为未绑定
变量。X在绑定前可以接受任何值,它只是一个等待填充的空槽。但是,一旦得到一个值,就会
永远保留它。
4.3.2 变量绑定和模式匹配
在Erlang里,变量获得值是一次成功模式匹配操作的结果。
在大多数语言里,=表示一个赋值语句。而在Erlang里,=是一次模式匹配操作。Lhs = Rhs
的真正意思是:计算右侧(Rhs)的值,然后将结果与左侧(Lhs)的模式相匹配
4.3.3 为什么要使用一次性赋值?
在Erlang里,变量只不过是对某个值的引用:Erlang的实现方式用指针代表绑定变量,指向
一个包含值的存储区。这个值不能被修改。
程序出错的一个常见发现方式是我们看到某个变量有着意料之外的值。一旦知道是哪个变量出了错,就必须检查程序,找到绑定变量的地方。因为Erlang的变量是不可变的,所以生成此变量的代码必然是错误的。而在命令式语言里,变量可以被多次修改,因此每一个修改变量的地方
都有可能是错误发生之处。在Erlang里则只需要查看一处。
4.4 浮点数
让我们试着用浮点数做一些计算。

第1行的行尾数字是整数3。点表示表达式的结束,而不是小数点。如果我想写的是浮点数,
我会写作3.0
尽管4能被2整除,但是结果仍然是一个浮点数,而不是整数。要从除法里获得整数结果,
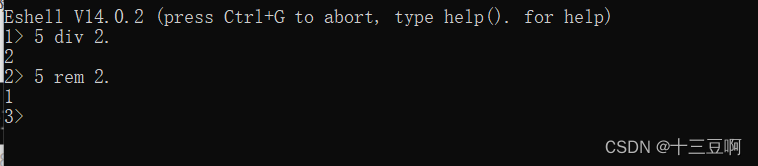
我们必须使用操作符div和rem

N div M是让N除以M然后舍去余数。N rem M是N除以M后剩下的余数
4.5 原子
在Erlang里,原子被用于表示常量值。类似于Java语言里面的枚举型
在Erlang里,原子是全局性的,而且不需要宏定义或包含文件就能实现。
假设想要编写一个对星期几进行操作的程序。要实现它,我们会用monday(星期一)和
tuesday(星期二)等原子来代表它们。
原子以小写字母开头,后接一串字母、数字、下划线(_)或at(@)符号,例如red、december、cat、meters、yards、joe@somehost和a_long_name。
原子还可以放在单引号(‘)内。可以用这种引号形式创建以大写字母开头(否则会被解释
成变量)或包含字母数字以外字符的原子,例如’Monday’、‘Tuesday’、‘+’、'*‘和’an atom
with spaces’。甚至可以给无需引号的原子加上引号,因此’a’和a的意思完全一致。在某些语
言里,单引号和双引号可以互换使用。Erlang里不是这样。单引号的用法如前面所示,双引号用
于给字符串字面量(string literal)定界。
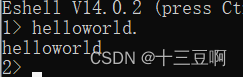
一个原子的值就是它本身。所以,如果输入一个原子作为命令,Erlang shell就会打印出这个
原子的值
4.6 元组
如果想把一些数量固定的项目归组成单一的实体,就会使用元组(tuple)。创建元组的方法
是用大括号把想要表示的值括起来,并用逗号分隔它们。
4.6.1 创建元组
元组会在声明它们时自动创建,不再使用时则被销毁。
Erlang使用一个垃圾收集器来回收所有未使用的内存,这样就不必担心内存分配的问题了。
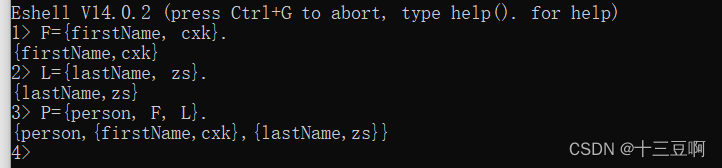
如果在构建新元组时用到变量,那么新的元组会共享该变量所引用数据结构的值。下面是一
个例子
4.6.2 提取元组的值
如果我们想要提取元组的值,我们得去使用=这个模式匹配方式
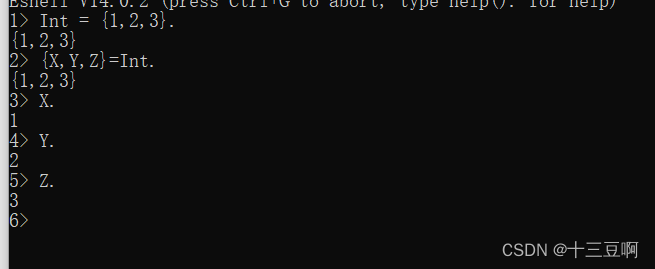
在{X,Y,Z}=Int.里面,X,Y,Z按顺序绑定了Int元组里面的三个值1,2,3
除此之外,我们在前面这个例子中可以将_作为占位符,用于表示不感兴趣的那些变量。符号_被
称为匿名变量。与正规变量不同,同一模式里的多个_不必绑定相同的值。

4.7 列表
列表(list)被用来存放任意数量的事物。创建列表的方法是用中括号把列表元素括起来,
并用逗号分隔它们。
假设想要表示一个图形。如果假定此图形由三角形和正方形组成,就可以用一个列表来表
示它。
列表的第一个元素被称为列表头(head)。假设把列表头去掉,剩下的就被称为列表尾(tail)。
举个例子,如果有一个列表[1,2,3,4,5],那么列表头就是整数1,列表尾则是列表
[2,3,4,5]。请注意列表头可以是任何事物,但列表尾通常仍然是个列表。
访问列表头是一种非常高效的操作,因此基本上所有的列表处理函数都从提取列表头开始,
然后对它做一些操作,接着处理列表尾。
4.7.1 定义列表
如果T是一个列表,那么[H|T]也是一个列表,它的头是H,尾是T。竖线(|)把列表的头与
尾分隔开。[]是一个空列表
无论何时,只要用[…|T]语法构建一个列表,就应该确保T是列表。如果它是,那么新列
表就是“格式正确的”。如果T不是列表,那么新列表就被称为“不正确的列表”。大多数库函数
假定列表有正确的形式,无法用于不正确的列表。
假如现在有这么有个列表

那么就可以这样扩展列表:

4.7.2 提取列表元素
和元组情况一样,我们可以用模式匹配操作来提取某个列表里的元素。如果有一个非空列表
L,那么表达式[X|Y] = L(X和Y都是未绑定变量)会提取列表头作为X,列表尾作为Y。
当我们在商店里,手上拿着购物单ThingsToBuy1时,所做的第一件事就是把这个列表拆成
头和尾。

操作成功,绑定如下:Buy1 = {oranges,4},ThingsToBuy2 = [{newspaper,1},
{apples,10}, {pears,6}, {milk,3}]。于是我们先去买橙子(oranges),然后可以继续拆出
下一对商品。
4.8 字符串
严格来说,Erlang里没有字符串。要在Erlang里表示字符串,可以选择一个由整数组成的列表或者一个二进制型。当字符串表示为一个整数列表时,列表里的每个元素都代表了一个Unicode代码点(codepoint)
可以用字符串字面量来创建这样一个列表。字符串字面量(string literal)其实就是用双引号
(")围起来的一串字符。
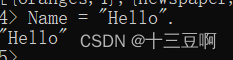
"Hello"其实只是一个列表的简写,这个列表包含了代表字符串里各个字符的整数字符代码,英文字母对应着unicode会进行转换
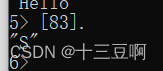
5.模块与函数
5.1 模块是存放代码的地方
模块是Erlang的基本代码单元。模块保存在扩展名为.erl的文件里,而且必须先编译才能运
行模块里的代码。编译后的模块以.beam作为扩展名。编写第一个模块之前,先来回忆一下模式匹配。我们要做的就是创建一对数据结构,分别代表一个长方形和一个正方形。然后将拆开这些数据结构,提取出长方形和正方形的边长。以下是具体做法:

我们在第1行和第2行里创建了长方形(Rectangle)和正方形(Square)。第3行和第6行用模
式匹配提取出长方形和正方形中的字段。第4、5和7行打印出由模式匹配表达式创建的变量绑定。
在第7行之后,shell里的变量绑定是Width = 10、Height = 5和Side = 3。
从shell里的模式匹配到函数里的模式匹配只需要很小的一步。让我们从一个名为area的函数
开始,它将计算长方形和正方形的面积。我们会把它放入一个名为geometry(几何)的模块里,
并把这个模块保存在名为geometry.erl的文件里。整个模块看起来就像这样
-module(geometry).
-export([area/1]).
area({rectangle, Width, Height}) -> Width * Height;
area({square, Side}) -> Side*Side.
文件的第一行是模块声明。声明里的模块名必须与存放该模块的主文件名相同
第二行是导出声明。Name/N这种记法是指一个带有N个参数的函数Name,N被称为函数的元
数(arity)。export的参数是由Name/N项目组成的一个列表。因此,-export([area/1])的意思
是带有一个参数的函数area可以在此模块之外调用。
未从模块里导出的函数只能在模块内调用。已导出函数就相当于面向对象编程语言(OOPL)
里的公共方法,未导出函数则相当于OOPL里的私有方法
area函数有两个子句。这些子句由一个分号隔开,最后的子句以点加空白结束。每条子
句都有一个头部和一个主体,两者用箭头(->)分隔。头部包含一个函数名,后接零个或更多个
模式,主体则包含一列表达式,它们会在头部里的模式与调用参数成功匹配时执行。这些子句会根据它们在函数定义里出现的顺序进行匹配。
简单来说就是:函数->表达式
注意之前用于shell示例里的模式是如何成为area函数定义的一部分的。每个模式都精确对应
一条子句。area函数的第一条子句:
area({rectangle, Width, Height}) -> Width * Height;
告诉我们如何计算长方形的面积。执行函数geometry:area({rectangle, 10, 5})时,
area/1的第一个子句匹配了以下绑定:Width = 10和Height = 5。匹配之后,箭头->后面的
代码会被执行,也就是Width * Height,即10*5等于50。请注意此函数没有显式的返回语句。
它的返回值就是子句主体里最后一条表达式的值(也就是箭头后面表达式的计算出来的值)。现在编译这个模块,然后运行它。
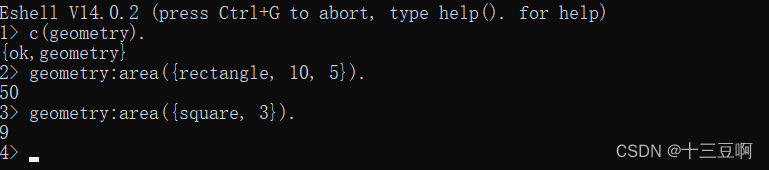
在第1行给出了命令c(geometry),它的作用是编译geometry.erl文件里的代码。编译器返
回了{ok,geometry},意思是编译成功,而且geometry模块已被编译和加载。编译器会在当前
目录创建一个名为geometry.beam的目标代码模块。在第2行和第3行调用了geometry模块里的
函数。请注意,需要给函数名附上模块名,这样才能准确标明想调用的是哪个函数。
5.1.1 测试
如果想要进行测试的话,可以用模式匹配
也就是12=area{rectangle, 3, 4}这种来进行测试
5.1.2 拓展
现在假设想要扩展这个程序,给几何对象添加一个圆。可以这么写
area({rectangle, Width, Height}) -> Width * Height;
area({circle, R})-> 3.14*R*R
area({square, Side}) -> Side*Side.
这个例子里的子句顺序无关紧要。无论子句如何排列,程序都是一个意思,因为子
句里的各个模式是互斥的。这让编写和扩展程序变得非常简单:只要添加更多的模式就行了。不
过一般来说,子句的顺序还是很重要的。当某个函数执行时,子句与调用参数进行模式匹配的顺
序就是它们在文件里出现的顺序。
5.1.3 符号放哪里
1.逗号(,)分隔函数调用、数据构造和模式中的参数。
2. 分号(;)分隔子句。我们能在很多地方看到子句,例如函数定义,以及case、if、
try…catch和receive表达式。
3. 句号(.)(后接空白)分隔函数整体,以及shell里的表达式。
5.2 fun:基本的抽象单元
Erlang是一种函数式编程语言。此外,函数式编程语言还表示函数可以被用作其他函数的参
数,也可以返回函数。操作其他函数的函数被称为高阶函数(higher-order function),而在Erlang中用于代表函数的数据类型被称为fun
fun的使用方式有以下几种:
1.对列表里的每一个元素执行相同的操作。在这个案例里,将fun作为参数传递给lists:map/2和lists:filter/2等函数。fun的这种用法是极其普遍的。
2. 创建自己的控制抽象。这一技巧极其有用。例如,Erlang没有for循环,但我们可以轻松
创建自己的for循环。创建控制抽象的优点是可以让它们精确实现我们想要的做法,而不
是依赖一组预定义的控制抽象,因为它们的行为可能不完全是我们想要的。
3. 实现可重入解析代码(reentrant parsing code)、解析组合器(parser combinator)或惰性求
值器(lazy evaluator)等事物。在这个案例里,我们编写返回fun的函数。这种技术很强
大,但可能会导致程序难以调试
funs是“匿名的”函数。这样称呼它们是因为它们没有名字。你可能会看到其他编程语言称它们为lambda抽象。下面开始试验,首先将定义一个fun并将它指派给一个变量。

定义一个fun后,Erlang shell打印出#Fun<…>,里面的…是一些古怪的数字。现在无需担
心它们。
我们只能对fun做一件事,那就是给它应用一个参数,就像这样:
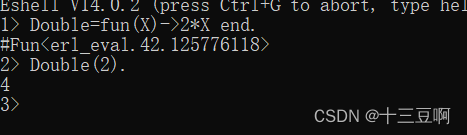
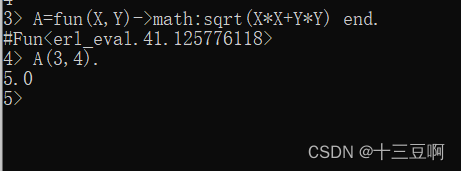
fun可以有任意数量的参数,可以编写一个函数来计算直角三角形的斜边,就像这样:
5.2.1 以fun作为参数的函数
标准库里的lists模块导出了一些以fun作为参数的函数。它们之中最有用的是lists:map(F,
L)。这个函数返回的是一个列表,它通过给列表L里的各个元素应用fun F生成,可以批量操作列表。
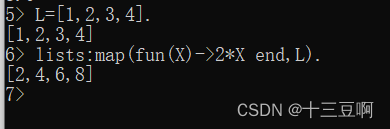
另一个有用的函数是lists:filter(P, L),它返回一个新的列表,内含L中所有符合条件
的元素(条件是对元素E而言P(E)为true)

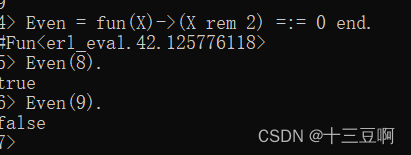
这里的X rem 2会计算出X除以2后的余数,=:=用来测试是否相等。现在可以测试Even,然
后将它用作map和filter的参数了。

map和filter等函数能在一次调用里对整个列表执行某种操作,我们把它们称为一次一列表
(list-at-a-time)式操作。使用一次一列表式操作让程序变得更小,而且易于理解。
5.2.2 返回fun的函数
函数不仅可以使用fun作为参数(例如map和filter),还可以返回fun。
这里有一个例子。假设我有一个包含某种事物的列表,比如说水果:

现在我可以定义一个MakeTest(L)函数,将事物列表(L)转变成一个测试函数,用来检查
它的参数是否在列表L中
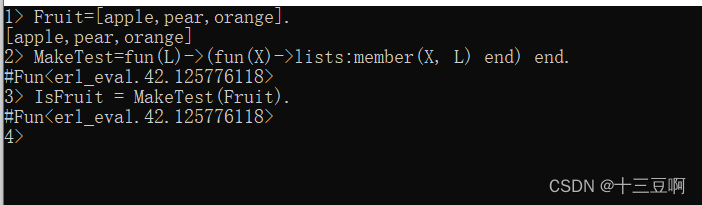
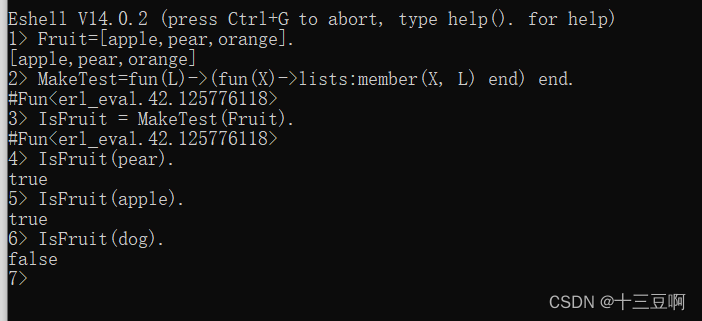
也可以把它用作lists:filter/2的参数

5.2.3 定义你自己的控制抽象
到目前为止,还没有看到任何的if语句、switch语句、for语句或while语句,然而这似乎
没什么问题。所有的一切都是用模式匹配和高阶函数编写的。
如果想要额外的控制结构,可以自己创建。这里有个例子,Erlang没有for循环,所以我们
来创建一个:
for(Max, Max, F) -> [F(Max)];
for(I, Max, F) -> [F(I)|for(I+1, Max, F)].
5.3 简单列表处理
介绍完fun之后,可以继续编写sum和map了。
sum
sum(H|T]) -> H+sum(T);
sum([])->0.
注意,这两个sum子句的顺序并不重要。因为子句1匹配一个非空列表,而子句2匹配空列表,
这两种情况是互斥的。
map
map(_, []) ->[];
map(F, [H|T]) -> [F(H)|map(F,T)].
5.4 列表推导
列表推导(list comprehension)是无需使用fun、map或filter就能创建列表的表达式。它让
程序变得更短,更容易理解。
我们从一个例子开始。假设有一个列表L,

假如我们想要列表中的每个元素加倍,我们就可以用列表推导

[ F(X) || X <- L]标记的意思是“由F(X)组成的列表(X从列表L中提取)”。因此,[2X
|| X <- L ]的意思就是“由2X组成的列表(X从列表L中提取)”
我们可以用列表推导来计算商店里面的金额

5.5 内置函数
内置函数简称为BIF(built-in function),是那些作为Erlang语言定义一部分的函数。有些内
置函数是用Erlang实现的,但大多数是用Erlang虚拟机里的底层操作实现的。
内置函数能提供操作系统的接口,并执行那些无法用Erlang编写或者编写后非常低效的操作。比如,你无法将一个列表转变成元组,或者查到当前的时间和日期。要执行这样的操作,需要调用内置函数。
举个例子,内置函数list_to_tuple/1能将一个列表转换成元组,time/0以{时,分,秒}
的格式返回当前的时间
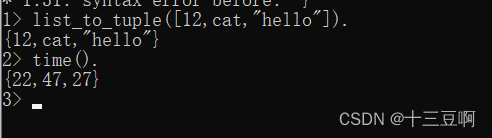
所有内置函数都表现得像是属于erlang模块,但那些最常用的内置函数(例如list_to_
tuple)是自动导入的,因此可以直接调用list_to_tuple(…),而无需用erlang:list_to_
tuple(…)
5.6 关卡
关卡(guard)是一种结构,可以用它来增加模式匹配的威力。通过使用关卡,可以对某个
模式里的变量执行简单的测试和比较。假设想要编写一个计算X和Y之间最大值的max(X, Y)函
数。可以像下面这样用关卡来编写它:
max(X,Y) when X>Y ->X;
max(X,Y) ->Y.
子句1会在X大于Y时匹配,结果是X。
如果子句1不匹配,系统就会尝试子句2。子句2总是返回第二个参数Y。Y必然是大于或等于
X的,否则子句1就已经匹配了。
可以在函数定义里的头部使用关卡(通过关键字when引入),也可以在支持表达式的任何地
方使用它们。当它们被用作表达式时,执行的结果是true或false这两个原子中的一个。如果关
卡的值为true,我们会说执行成功,否则执行失败。
5.7 case 和 if 表达式
到目前为止,所有的问题我们都用模式匹配解决。这让Erlang代码小而一致。但是,为所有
问题都单独定义函数子句有时候很不方便。这时,可以使用case或if表达式。
5.7.1 case表达式
case表达式结构如下:
case Expression of
Pattern1 [when Guard1] -> Expr_seq1;
Pattern2 [when Guard2] -> Expr_seq2;
...
end
case的执行过程如下:首先,Expression被执行,假设它的值为Value。随后,Value轮流
与Pattern1(带有可选的关卡Guard1)、Pattern2等模式进行匹配,直到匹配成功。一旦发现
匹配,相应的表达式序列就会执行,而表达式序列执行的结果就是case表达式的值。如果所有模
式都不匹配,就会发生异常错误(exception)。
5.7.2 if表达式
if
Guard1->
Expr_seq1;
Guard2->
Expr_seq2;
...
end
它的执行过程如下:首先执行Guard1。如果得到的值为true,那么if的值就是执行表达式
序列Expr_seq1所得到的值。如果Guard1不成功,就会执行Guard2,以此类推,直到某个关卡
成功为止。if表达式必须至少有一个关卡的执行结果为true,否则就会发生异常错误。
很多时候,if表达式的最后一个关卡是原子true,确保当其他关卡都失败时表达式的最后
部分会被执行。
5.8 构建自然顺序的列表
构建列表最有效率的方式是向某个现成列表的头部添加元素,因此经常能看到包含以下模式
的代码:
some_function([H|T], ... , Result, ...) ->
H1 = ... H...,
some_function(T,...,[H1|Result], ...);
some_function([], ... , Result, ...)->
{..., Result, ...}.
这段代码会遍历一个列表,提取出列表头H并根据函数的算法计算出某个值(可以称之为
H1),然后把H1添加到输出列表Result里。当输入列表被穷尽后,最后的子句匹配成功,函数返
回输出变量Result。
Result的元素顺序和原始列表的元素顺序是相反的,这也算不上什么问题。如果它们的顺
序是错误的,可以很容易在最后一步里反转过来。
它的基本概念相当简单。
(1) 总是向列表头添加元素。
(2) 从输入列表的头部提取元素,然后把它们添加到输出列表的头部,形成的结果是与输入
列表顺序相反的输出列表。
(3) 如果顺序很重要,就调用lists:reverse/1这个高度优化过的函数。
(4) 避免违反以上的建议。
5.9 归集器
我们经常会想要让一个函数返回两个列表。举个例子,我们可能会想编写一个函数,把某个
整数列表一分为二,分别包含原始列表里的奇数和偶数。下面是一种做法:
adds_and_evensl(L)->
0dds = [X || X<- L, (X rem 2) =:=1],
Evens = [X || X<- L, (X rem 2) =:=0],
{0dds, Evens}.
这段代码的问题在于:遍历了列表两次。如果列表很短则问题不大,但如果列表很长,就可
能是个问题。
要避免遍历列表两次,可以重写代码如下:
odds_and_evensl2(L)->
odds_and_evens_acc(L, {}, {}).
odds_and_evensl_acc(H|T, odds, Evens)->
case(H rem 2) of
1 -> odds_and_evens_acc(T, [H|odds], Evens);
0 -> odds_and_evens_acc(T, odds, [H|Evens]}
end
odds_and_evensl_acc([],odds,Evens)->
{odds, Evens}.
现在程序只遍历列表一次,把奇偶参数分别添加到合适的列表里。这些列表被称为归集器
(accumulator)。这段代码还有一个不太明显的额外的优点:带归集器的版本比[H || filter(H)]
类型结构的版本更节省空间。















 2633
2633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











