






 本文介绍了余弦相似度和欧式距离两种衡量向量间相似性的方法,以及概率统计中的伯努利分布、事件独立性和互斥性。此外,还探讨了正态分布、期望与方差、标准差,并简述了贝叶斯定理、朴素贝叶斯算法以及信息论中的熵和交叉熵等概念。
本文介绍了余弦相似度和欧式距离两种衡量向量间相似性的方法,以及概率统计中的伯努利分布、事件独立性和互斥性。此外,还探讨了正态分布、期望与方差、标准差,并简述了贝叶斯定理、朴素贝叶斯算法以及信息论中的熵和交叉熵等概念。
一、余弦相似度:
余弦相似度(Cosine Similarity)是一种用于衡量两个向量之间相似性的度量方法。它衡量的是两个向量之间的夹角的余弦值,取值范围在-1到1之间。
对于两个非零向量A和B,它们之间的余弦相似度定义为它们的内积除以它们的模的乘积:
cosine_similarity = (A · B) / (||A|| * ||B||)
其中,A · B表示向量A和向量B的点积(内积),||A||和||B||分别表示向量A和向量B的模(范数)。
余弦相似度的值越接近1,表示两个向量越相似;值越接近-1,表示两个向量越不相似;值接近0,则表示两个向量之间没有明显的相似性或相似度较低。
二、欧式距离:
是在几何空间中衡量两个点之间距离的一种常用度量方式。它是计算两个点之间直线距离的方法,基于勾股定理。
欧氏距离可以用于计算任意维度的点之间的距离,它衡量的是点之间在多维空间中的直线距离。较小的欧氏距离表示两个点更接近,而较大的欧氏距离表示两个点更远离。
欧氏距离常用于数据挖掘、模式识别、聚类分析等领域,用于比较和分类数据对象之间的相似性或差异性。

两者之间的关系如下:
-
定义方式:余弦相似度衡量的是两个向量之间的夹角的余弦值,取值范围在-1到1之间;欧氏距离衡量的是两个点之间的直线距离,是非负实数。
-
取值范围:余弦相似度的取值范围在-1到1之间,越接近1表示越相似,越接近-1表示越不相似,接近0表示没有明显的相似性;欧氏距离的取值范围是非负实数,较小的距离表示较接近,较大的距离表示较远离。
-
对数据的敏感度:余弦相似度对向量的长度和尺度不敏感,仅关注方向的一致性;欧氏距离对向量的绝对数值和坐标轴的刻度有影响,较大的数值和维度会对距离产生较大的影响。
-
应用领域:余弦相似度常用于文本相似性比较、推荐系统、聚类分析等领域,尤其适用于高维稀疏数据;欧氏距离常用于数据挖掘、模式识别、聚类分析等领域,适用于测量欧几里德空间中的点之间的距离。
三、概率统计:
1、伯努利分布
概率论中一种离散型的概率分布,它描述了一个随机变量只有两个可能取值的情况,通常取0和1(或者记作False和True)。它是以瑞士数学家雅各布·伯努利命名的。2、
使用案例:
import time import random def coin(count): sum_ = 0 for i in range(count): if random.random() >= 0.5: sum_ += 1 return sum_ count1 = 10000000 a = time.time() sum1 = coin(count1) b = time.time() print(sum1 / count1) print(f"{b - a}秒")
效果图:

2、概率统计:
引入:
P = 概率
E = 事件
Ω**(Omega)** = 样本空间、必然事件、全集
Φ**(Phi)** = 空集**、不可能事件**
Σ**(sigma)** = 总和
希腊字母表:

事件:
事件(Event)指的是可能发生或观察到的某种结果或现象。它是样本空间(Sample Space)中的一个子集,表示具体的情况或状态。
样本空间是指所有可能的结果或样本点的集合,而事件是样本空间的一个子集,包含我们感兴趣的特定结果。事件可以是单个结果,也可以是多个结果的组合。
事件独立性:
事件独立性是指两个或多个事件在发生与否上相互不受影响的性质。如果两个事件之间独立,那么一个事件的发生与否不会对另一个事件的发生概率产生影响。
具体来说,对于两个事件 A 和 B,事件 A 的发生与否不会影响事件 B 的概率,反之亦然。数学上可以表示为:
P(A ∩ B) = P(A) * P(B)
其中,P(A ∩ B) 表示事件 A 和 B 同时发生的概率,P(A) 和 P(B) 分别表示事件 A 和 B 单独发生的概率。
如果上述等式成立,那么事件 A 和 B 是相互独立的。如果事件 A 和 B 不独立,则可以说它们是相互依赖的,即事件 A 的发生与否会对事件 B 的概率产生影响,或者反之。
事件互斥性:
事件互斥性是指两个事件之间的关系,表示这两个事件不能同时发生,即它们的交集为空集。
具体而言,对于两个事件 A 和 B,如果事件 A 发生,那么事件 B 必定不发生;反之,如果事件 B 发生,那么事件 A 必定不发生。这意味着事件 A 和 B 之间不存在共同发生的可能性。
数学上可以表示为:
A ∩ B = ∅
其中,A ∩ B 表示事件 A 和 B 的交集,∅ 表示空集,表示两个事件没有共同的结果。
事件互斥性是事件之间一种特殊的关系,当两个事件互斥时,它们之间不存在重叠或重复的情况。在概率计算和统计推断中,事件互斥性是一个重要的概念,它可以影响到联合概率、条件概率等计算。
需要注意的是,事件互斥性与事件独立性是不同的概念。事件互斥性表示两个事件不能同时发生,而事件独立性表示两个事件的发生与否相互不影响。在某些情况下,事件可能既不互斥也不独立,具体取决于事件的定义和条件。
条件概率、联合概率、边缘概率
-
条件概率(Conditional Probability): 条件概率是指在给定某个条件下,事件发生的概率。记作 P(A|B),表示事件 B 发生的前提下,事件 A 发生的概率。条件概率的计算公式为:
P(A|B) = P(A ∩ B) / P(B)
其中,P(A ∩ B) 表示事件 A 和 B 同时发生的概率,P(B) 表示事件 B 的概率。
-
联合概率(Joint Probability): 联合概率是指多个事件同时发生的概率。记作 P(A ∩ B),表示事件 A 和 B 同时发生的概率。联合概率可以通过条件概率来计算,公式为:
P(A ∩ B) = P(A|B) * P(B) = P(B|A) * P(A)
其中,P(A|B) 和 P(B|A) 分别表示在给定另一个事件的条件下,事件 A 和 B 的概率。
-
边缘概率(Marginal Probability): 边缘概率是指单个事件的概率,不考虑其他事件的影响。对于联合概率 P(A ∩ B),边缘概率可以通过对某个事件求和或求积分得到。例如,对于两个事件 A 和 B 的边缘概率,可以计算为:
P(A) = Σ P(A ∩ B) 或者 P(A) = ∫ P(A, x) dx
其中,Σ 表示求和符号,∫ 表示积分符号。
概率分布图:

期望与方差:
-
期望:
期望是随机变量取值的加权平均值,表示对随机变量的取值进行加权平均的结果。期望的计算方法如下:
-
对于离散型随机变量: 假设随机变量为 X,其可能取值为 x1, x2, ..., xn,对应的概率为 p1, p2, ..., pn。则期望的计算公式为:
E(X) = Σ(xi * pi)
其中,E(X) 表示随机变量 X 的期望,xi 表示随机变量 X 取值为 xi,pi 表示随机变量 X 取值为 xi 的概率。
-
对于连续型随机变量: 假设随机变量为 X,其概率密度函数为 f(x),则期望的计算公式为:
E(X) = ∫(x * f(x)) dx
其中,E(X) 表示随机变量 X 的期望,x 表示随机变量 X 的取值,f(x) 表示随机变量 X 的概率密度函数。
期望的计算过程可以理解为对随机变量的每个取值进行加权求和(对于离散型随机变量)或进行积分(对于连续型随机变量)。权重即对应的概率(或概率密度),通过将取值与概率相乘并累加(或积分)得到期望的结果。
-
-
方差: 方差是衡量随机变量离散程度的指标,它表示随机变量取值与期望之间的差异程度。方差的计算方法如下:
-
对于离散型随机变量: 假设随机变量为 X,其可能取值为 x1, x2, ..., xn,对应的概率为 p1, p2, ..., pn。则方差的计算公式为:
Var(X) = Σ((xi - E(X))^2 * pi)
其中,Var(X) 表示随机变量 X 的方差,E(X) 表示随机变量 X 的期望,xi 表示随机变量 X 取值为 xi,pi 表示随机变量 X 取值为 xi 的概率。
-
对于连续型随机变量: 假设随机变量为 X,其概率密度函数为 f(x),则方差的计算公式为:
Var(X) = ∫((x - E(X))^2 * f(x)) dx
其中,Var(X) 表示随机变量 X 的方差,E(X) 表示随机变量 X 的期望,x 表示随机变量 X 的取值,f(x) 表示随机变量 X 的概率密度函数。
方差的计算过程可以理解为对随机变量取值与期望之间的差异进行平方,并乘以对应的概率(或概率密度),然后将这些差异值加和(对于离散型随机变量)或进行积分(对于连续型随机变量)。方差的结果是一个非负数,方差越大表示随机变量的取值越分散,方差为零表示所有取值都与期望相等
-
正态分布:
1.标准差:
标准差是描述数据分散程度或离散程度的统计量,它衡量了数据点相对于均值的平均偏离程度。标准差越大,数据点相对于均值的偏离程度就越大,表示数据的离散程度较大;标准差越小,数据点相对于均值的偏离程度就越小,表示数据的离散程度较小。
标准差的计算步骤如下:
-
计算每个数据点与均值之差:将每个数据点与均值相减。
-
将差值平方:对每个差值进行平方运算。
-
求平方差的平均值:将平方差值相加,然后除以数据点的个数。
-
取平均值的平方根:将平均平方差值进行平方根运算,得到标准差。
标准差的计算可以用以下公式表示:
σ = √(Σ(x - μ)^2 / N)
其中,σ 表示标准差,x 表示每个数据点,μ 表示均值,Σ 表示求和运算,N 表示数据点的个数。
2.正态分布
正态分布,也被称为高斯分布,是统计学中最常见的概率分布之一。它的特点是呈钟形曲线状,分布的中心对称,因此也被称为钟形曲线或正态曲线。
正态分布由两个参数完全描述:均值(μ)和标准差(σ)。均值决定了分布的中心位置,标准差决定了分布的形状和离散程度。正态分布的概率密度函数(Probability Density Function,简称PDF)可以用以下公式表示:
f(x) = (1 / (σ * √(2π))) * exp(-(x-μ)^2 / (2σ^2))
其中,x 表示随机变量的取值,μ 表示均值,σ 表示标准差,π 是圆周率(约等于3.14159),exp() 表示自然指数函数。
正态分布具有许多重要的特性,其中最重要的是以下几点:
-
对称性:正态分布是关于均值对称的,即在均值处取得最大值,左右两侧的概率相等。
-
中心极限定理:许多随机现象的总体分布近似服从正态分布。根据中心极限定理,当独立随机变量的数量足够大时,它们的平均值会趋向于正态分布。
-
标准正态分布:当均值为0,标准差为1时,称为标准正态分布。许多统计方法和推断都基于标准正态分布。
代码案例:
from scipy import stats import numpy as np import matplotlib.pyplot as plt # 定义随机变量 # 平均值 mean = 0 # 标准差 sd = 8 x = np.arange(-20, 20, 0.1) # 正太分布概率密度函数 y = stats.norm.pdf(x, mean, sd) plt.plot(x, y) plt.title(f"mu:{mean} -- sd:{sd}") plt.grid() plt.show()
运行效果: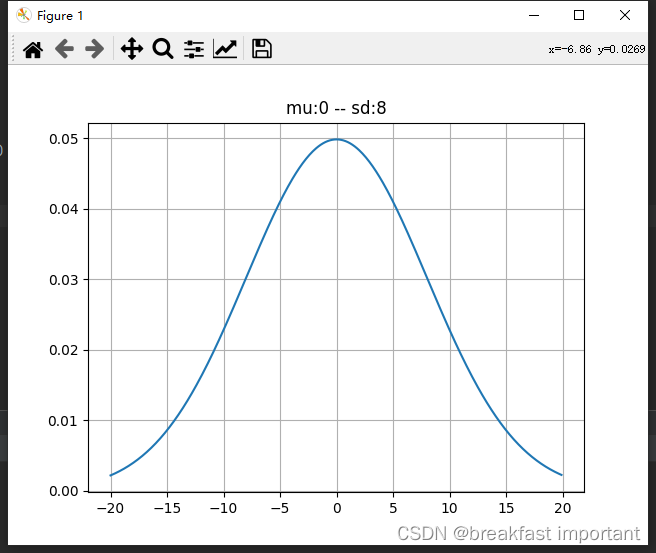
贝叶斯和朴素贝叶斯:
1.先验概率:
先验概率(Prior Probability)是指在考虑任何观测数据之前,根据先前的知识、经验或假设对事件或假设的概率进行的估计。它是在没有任何观测数据的情况下,根据主观或客观的先验信息对事件发生概率进行预估。
先验概率通常基于领域专家的知识、历史数据、先前的研究或一般性的常识。它可以是主观的,基于个人的信念或经验,也可以是客观的,基于统计数据或领域知识。
2.后验概率:
后验概率(Posterior Probability)是在观测到一些数据或证据之后,根据贝叶斯定理计算出来的更新后的概率。它用于根据先验概率和观测数据的条件概率,推断事件或假设的概率。
贝叶斯:
贝叶斯(Bayes)是指基于贝叶斯定理进行推断和决策的方法。贝叶斯定理是概率论中的一个重要定理,描述了如何根据先验知识和新的观测数据来更新对事件发生概率的估计。
贝叶斯定理的数学表达式如下: P(A|B) = (P(B|A) * P(A)) / P(B)
其中,P(A|B)表示在观测到事件B发生的情况下,事件A发生的概率;P(B|A)表示在事件A发生的情况下,观测到事件B发生的概率;P(A)和P(B)分别表示事件A和事件B的边缘概率(不考虑其他条件)。
贝叶斯方法的基本思想是将问题转化为概率的计算,并利用已知的信息进行概率的更新和推断。通过贝叶斯定理,我们可以在观测到一些数据的情况下,根据先验概率和观测数据的条件概率,计算出后验概率。后验概率反映了在观测到数据后,我们对事件发生概率的新的估计。
朴素贝叶斯:
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的简单且有效的分类算法。它被广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。
朴素贝叶斯算法的核心思想是假设特征之间是相互独立的(即朴素独立性假设),这意味着给定类别标签的情况下,每个特征对于分类的贡献是相互独立的。基于这个假设,朴素贝叶斯算法通过计算每个类别的后验概率,选择具有最高后验概率的类别作为预测结果。
朴素贝叶斯算法的训练过程包括统计每个类别的先验概率和每个特征在每个类别下的条件概率。在预测过程中,根据观测数据的特征值,计算每个类别的后验概率,并选择具有最高后验概率的类别作为预测结果。
朴素贝叶斯算法的优点包括简单快速、对于大规模数据集具有较高的效率、对于特征独立性的假设使得模型参数估计更加稳定。然而,朴素贝叶斯算法也有一些限制,例如它无法处理特征之间的相关性,对于特征空间较大或者重要特征缺失的情况可能表现不佳。
四、信息论
熵:
熵(Entropy)是信息论中用于衡量不确定性或信息量的概念。在信息论中,熵用于度量一个随机变量的平均信息量或平均不确定性。
对于一个离散随机变量,其熵的计算公式为:
H(X) = -Σ P(x) log(P(x))
其中,H(X)表示随机变量X的熵,P(x)表示X取值为x的概率。
熵的值越大,表示不确定性或信息量越大;熵的值越小,表示不确定性或信息量越小。
熵具有以下特性:
-
当随机变量的所有取值概率相等时,熵达到最大值,表示最大的不确定性或信息量。
-
当随机变量的某些取值的概率接近于1,而其他取值的概率接近于0时,熵接近于0,表示最小的不确定性或信息量。
代码示例:
import numpy as np
def get_ent(params):
ent = 0.0
for param in params:
ent -= param * np.log(param)
return ent
data = [1 / 7, 1 / 7, 2 / 7, 1 / 21, 2 / 21, 2 / 7]
print(get_ent(data))运行效果:
使用字符串分割计算信息熵:
import numpy as np
def get_ent(params):
ent = 0.0
for param in params:
ent -= param * np.log(param)
return ent
data = [1 / 7, 1 / 7, 2 / 7, 1 / 21, 2 / 21, 2 / 7]
print(get_ent(data))
english = """
Sure! Here's an explanation of the Naive Bayes algorithm:
Naive Bayes algorithm is a simple yet effective classification algorithm based on Bayes' theorem. It assumes that the
features are conditionally independent given the class label. The algorithm calculates the posterior probability of
each class given the observed features and selects the class with the highest probability as the predicted class.
The Bayes' theorem, which forms the basis of Naive Bayes algorithm, is expressed as follows:
"""
english = english.split()
empty_dict = {}
for i in english:
if empty_dict.get(i) is None:
empty_dict[i] = 1
else:
empty_dict[i] += 1
arr = [i / np.sum(list(empty_dict.values())) for i in empty_dict.values()]
print(get_ent(arr))运行效果: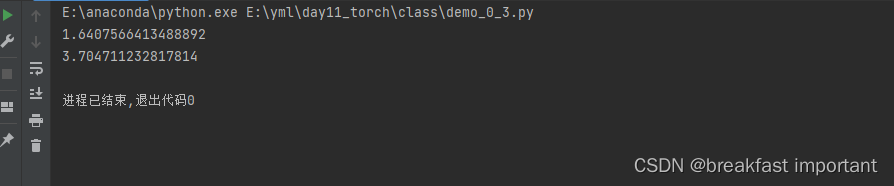
交叉熵:
交叉熵(Cross-Entropy)是一种用于衡量两个概率分布之间差异的度量方式。在机器学习中,交叉熵常用于衡量预测结果与真实标签之间的差异,特别是在分类问题中。
假设有两个概率分布P和Q,交叉熵的计算公式如下:
H(P, Q) = -Σ P(x) log(Q(x))
其中,H(P, Q)表示概率分布P和Q之间的交叉熵,P(x)表示真实标签的概率,Q(x)表示预测结果的概率。
交叉熵的值越小,表示两个概率分布之间越接近,预测结果与真实标签的差异越小。
代码示例:
import numpy as np
import torch
def cross_ent(x, y):
x = np.float_(x)
y = np.float_(y)
return np.sum(x * np.log(1 / y))
data1 = [[[[0.9393, 0.4652, 0.7585],
[0.4650, 0.9463, 0.8633],
[0.5903, 0.7820, 0.2400]],
[[0.0909, 0.6670, 0.7442],
[0.0374, 0.5454, 0.4309],
[0.8527, 0.6040, 0.9753]],
[[0.7881, 0.4886, 0.8478],
[0.5353, 0.4093, 0.6725],
[0.2574, 0.2639, 0.0135]]]]
data2 = [[[[0.2495, 0.5030, 0.9259],
[0.1577, 0.6659, 0.8744],
[0.7846, 0.2522, 0.0376]],
[[0.0660, 0.0311, 0.1221],
[0.0378, 0.3626, 0.1011],
[0.1355, 0.9995, 0.9832]],
[[0.8623, 0.8608, 0.1850],
[0.7813, 0.9024, 0.2274],
[0.9355, 0.2754, 0.3099]]]]
# 获取交叉熵 损失
print(cross_ent(data1, data2))
print(cross_ent(data1, data1))
print(cross_ent(data2, data1))
print(cross_ent(data2, data2))
cross_ent1 = torch.nn.CrossEntropyLoss()(torch.tensor(np.array(data1)), torch.tensor(np.array(data2)))
print(cross_ent1)运行效果: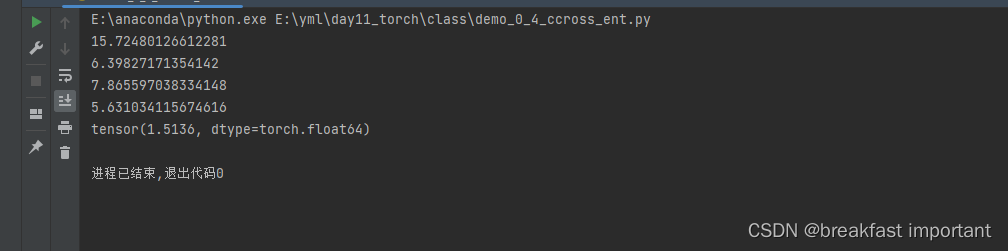
均方差:
均方差(Mean Squared Error,MSE)是一种常用的衡量预测值与真实值之间差异的度量方式。它计算的是预测值与真实值之间差异的平方的平均值。
对于一组预测值y_pred和对应的真实值y_true,均方差的计算公式如下:
MSE = (1/n) * Σ(y_pred - y_true)^2
其中,n表示样本的数量,Σ表示求和操作,y_pred表示预测值,y_true表示真实值。
均方差的值越小,表示预测值与真实值之间的差异越小,模型的拟合程度越好。
代码示例:
import random
import numpy as np
import torch
def cross_ent(x, y):
x = np.float_(x)
y = np.float_(y)
return np.sum(x * np.log(1 / y))
data1 = [[[[0.9393, 0.4652, 0.7585],
[0.4650, 0.9463, 0.8633],
[0.5903, 0.7820, 0.2400]],
[[0.0909, 0.6670, 0.7442],
[0.0374, 0.5454, 0.4309],
[0.8527, 0.6040, 0.9753]],
[[0.7881, 0.4886, 0.8478],
[0.5353, 0.4093, 0.6725],
[0.2574, 0.2639, 0.0135]]]]
data2 = [[[[0.2495, 0.5030, 0.9259],
[0.1577, 0.6659, 0.8744],
[0.7846, 0.2522, 0.0376]],
[[0.0660, 0.0311, 0.1221],
[0.0378, 0.3626, 0.1011],
[0.1355, 0.9995, 0.9832]],
[[0.8623, 0.8608, 0.1850],
[0.7813, 0.9024, 0.2274],
[0.9355, 0.2754, 0.3099]]]]
# 获取均方差 损失
mes = np.mean((np.array(data1) - np.array(data2)) ** 2)
print(mes)
mes = np.mean((np.array(data2) - np.array(data1)) ** 2)
print(mes)
# 使用PyTorch 计算均方差
mes1 = torch.mean((torch.tensor(data1) - torch.tensor(data2)) ** 2)
print(mes1)
mse2 = torch.nn.MSELoss()(torch.tensor(np.array(data1)), torch.tensor(np.array(data2)))
print(mse2)
mse3 = torch.nn.functional.mse_loss(torch.tensor(np.array(data1)), torch.tensor(np.array(data2)))
print(mse3)运行效果: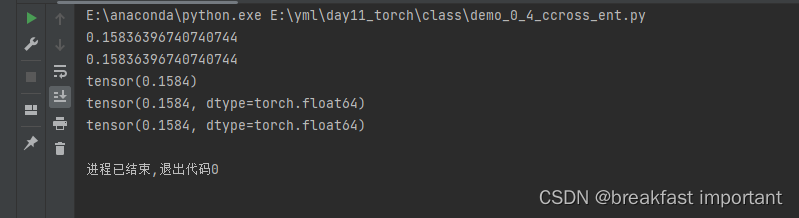
交叉熵与均方差的差异:
交叉熵(Cross-Entropy)和均方差(Mean Squared Error)是两种常用的损失函数,用于衡量预测值与真实值之间的差异,但在应用场景和特点上有一些差异。
-
应用场景:交叉熵常用于分类问题,而均方差常用于回归问题。交叉熵适用于多分类任务,特别是在使用softmax作为激活函数的分类模型中。均方差适用于回归任务,用于衡量连续变量的预测精度。
-
敏感性:交叉熵对于离群值或异常值不敏感,它主要关注分类结果的正确与否。均方差对异常值比较敏感,因为它计算的是差异的平方。
-
损失计算方式:交叉熵通过对预测结果和真实标签进行对数运算,将概率转化为相对差异的度量。均方差计算预测值与真实值之间的差异的平方,并取平均值。
-
模型输出特点:交叉熵损失函数对概率分布的输出敏感,鼓励模型产生概率性的输出。均方差损失函数对于连续数值的输出敏感,更适合用于直接预测数值的情况。
选择使用交叉熵还是均方差取决于具体的问题和任务类型。在分类问题中,交叉熵是常用的选择,可以帮助优化模型参数,使模型更好地拟合分类任务。在回归问题中,均方差通常是一种常用的损失函数,用于衡量回归模型的预测精度。
交叉熵损失函数: 适合分类问题
均方差损失函数: 万能损失函数,适合分类问题和回归问题

















 2127
2127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









