







 https://www.bilibili.com/video/BV12o4y197US?p=5
https://www.bilibili.com/video/BV12o4y197US?p=5本文内容根据以上视频内容所得,跟AlphaGo论文中的内容不完全一样~
原文链接:Mastering the game of Go with deep neural networks and tree search | Nature https://www.nature.com/articles/nature16961Mastering the game of Go without human knowledge | Naturehttps://www.nature.com/articles/nature24270/
https://www.nature.com/articles/nature16961Mastering the game of Go without human knowledge | Naturehttps://www.nature.com/articles/nature24270/
1 背景
1.1 Go game
围棋棋盘大小为19*19。也就是说包含361个交叉点。两名棋手对弈,交替落子,黑白两色。
棋盘上有361个可以放置棋子的位置,因此动作空间是A={1,2,3...,361}。比如a = 94就是在编号
94的位置落子。
 因此,棋盘的状态(state)即为黑白棋子以及空位的排列(一个交叉点要么黑子要么白子要么没下)。
因此,棋盘的状态(state)即为黑白棋子以及空位的排列(一个交叉点要么黑子要么白子要么没下)。
记某点落子为黑子.那么当前棋盘上的状态就可以用一个19*19*2的tensor来表示。
注:实际上AlphaGo 2016版本使用的tensor维度为19*19*48.用于记录其他的信息。
AlphaGo Zero使用19*19*17的tensor来表示一个状态。
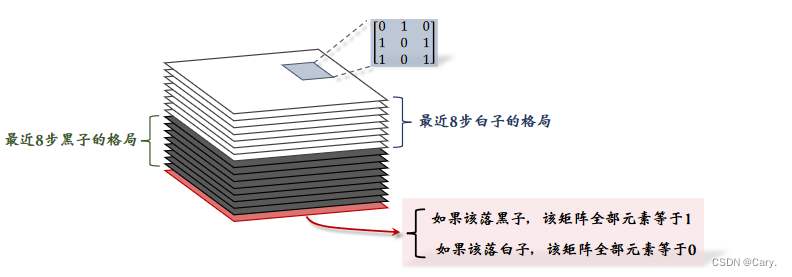
- 张量的每个切片是一个19*19的矩阵,对应与19x19的棋盘大小。一个19*19的矩阵便可以表示棋盘上所有黑子的位置。如果某个位置上有黑子,则对应的元素即为1,否则为0。同理,另一个19*19的矩阵来表示白子的位置情况。
- tensor中一共包含17个19*19的矩阵。(up主理解)8个矩阵用于记录8步棋盘上黑子的位置,同理白子位置也需要8个矩阵记录。还需要一个矩阵来表示哪方下棋,如果下黑子,则该矩阵元素全为1,若下白子则全为0。
由此可见围棋游戏的复杂度非常高,每一步都有许多位置可供选择。而且一句围棋游戏都需要进行
几百步才可以结束。(10的170次方数量级)因此之前用于解决棋类游戏(国际象棋)的暴力搜索
方法便不再适用。
1.2 AlphaGo的主要思路
训练分为3步:
- behavior cloning(一种模仿学习,agent在16万条游戏记录中,模仿人类玩家进行学习,得到一个策略网络)。behavior cloning并非强化学习,只是AlphaGo用于初步学习一个policy network。
- 用强化学习算法(策略梯度算法)进一步训练上一步得到的network。(Two police networks play against each other)。
- 训练一个价值网络(类似于actor-critic方法但不是!actor-critic需要同时训练两个网络,AlphaGo并没有同时训练。)先训练策略网络,然后利用策略网络训练价值网络。
AlphaGo在实战中利用训练好的两个网络进行蒙特卡洛树搜索算法。
2 策略网络、价值网络
2.1 策略网络
2.1.1 网络架构
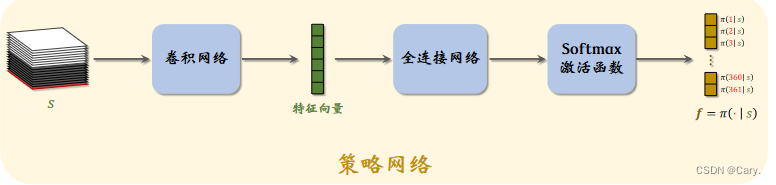
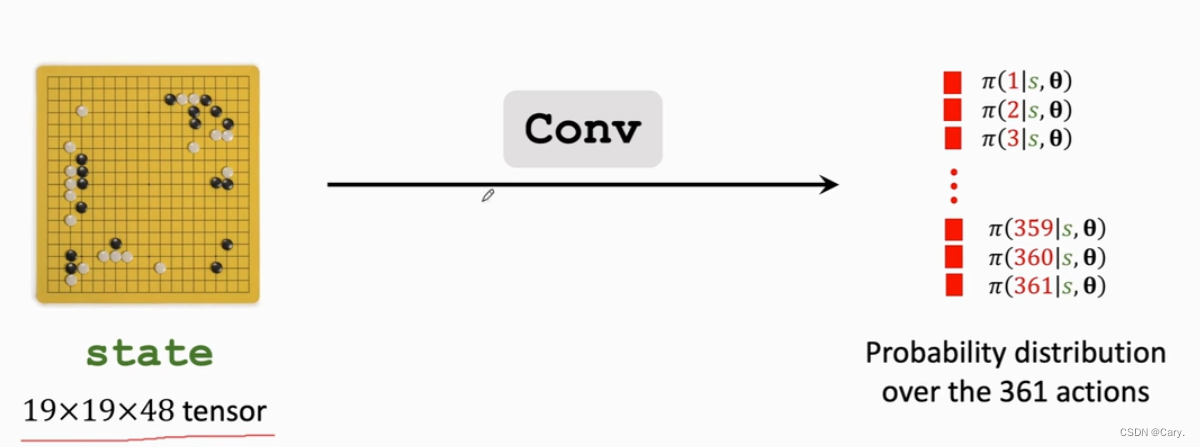
策略网络π(a|s;θ 的结构如上所示,输入是19*19*17的状态s。输出为361维的向量f。该向量每一个元素对应一种动作。即在棋盘哪个位置落子,经过softmax层,使得其加和为1。
注:AlphaGo 2016版的策略网络与上面的网络不同:
2.1.2 训练
第一步:behavior cloning
就是前文提到的从人类玩家的经验中进行学习。最初,网络的参数随机初始化,然后随着agent与
玩家的对局逐渐增多而学习。(视频中的KGS平台)
首先需要强调的是:behavior cloning 并不是强化学习,强化学习依靠agent与环境交互所得的奖励
(reward)进行训练,而behavior cloning是一种模仿学习,是一种分类/回归方法。agent看不到奖
励也不需要奖励。它只需要policy network模仿人类动作就好。
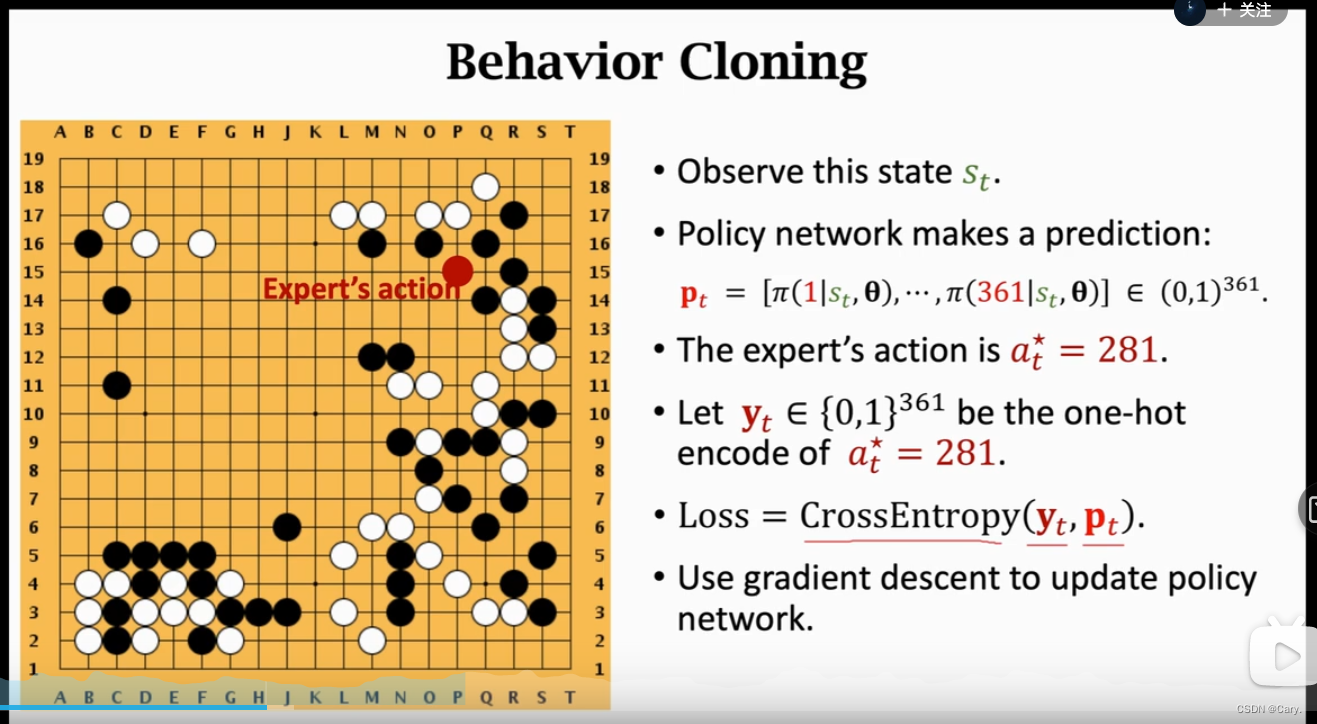
在behavior cloning中,输入是当前状态St,policy network会输出一个361维的向量Pt来表示采取
某一具体动作的概率。比如下在某一个位置的概率为0.4.
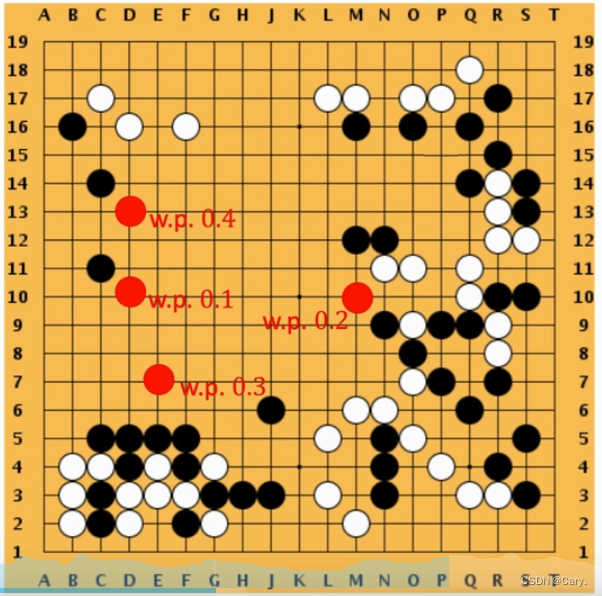
![]() 表示人类真实的动作,例子中表示将棋子下于第281个位置。将其进行独热编码,使之变为一
表示人类真实的动作,例子中表示将棋子下于第281个位置。将其进行独热编码,使之变为一
个与神经网络输出同维度的向量yt,然后求输出Pt与yt的交叉熵损失。通过loss的梯度下降来更新
网络。类似于多分类。
通过学习,我们已经得到了一个可以战胜新手的agent。但是通过behavior cloning学习的效果多样
性差,可以理解为中规中矩,如果遇到160K之外的棋局,模型就不能给出比较好的action了,这时
候就需要RL来进一步提高模型的准确度。
也就是说,behavior cloning仅仅是在“背棋谱”,当其遇到没有遇见过的情况时,效果就会变差,而
RL通过探索与利用的trade-off。会探索没遇见过的情境,通过一步步试错来不断进步。加之围棋游
戏的复杂度极高,因此behavior cloning得到的结果并不是很理想。
第二步:
利用强化学习算法来进一步训练policy network。

AlphaGo使用两个policy network互相博弈,player与opponent。
player网络的参数根据每一局游戏输赢得到的奖励来更新参数。opponent相当于陪玩,其网络参数
不需要学习,随机选取一组参数即可。
AlphaGo使用策略梯度算法(policy gradient)来学习策略网络:

没结束一局游戏,就会得到一个ut,我们就可以得到一个近似的策略梯度。
总结一下policy gradient的训练:


虽然 此时的policy network已经得到了不错的效果但是结果还是不太稳定,因此可以使用蒙特卡洛树搜索算法(MCTS)。
为了使用MCTS,我们还需要学习另一个网络:value network
2.2 价值网络
2.2.1 网络架构
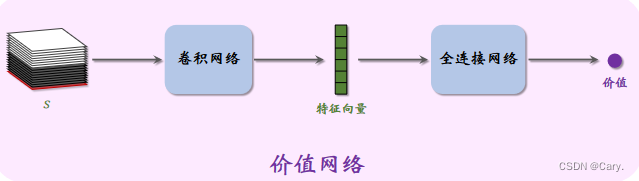
价值网络v(s;w),它是对状态价值函数Vπ(s)的近似,其输入为19*19*17的状态s,输出是一个实数,其大小评价当前状态s的好坏(和actor-critic好像~)
回顾一下状态价值函数:

AlphaGo Zero共享了一些卷积层:
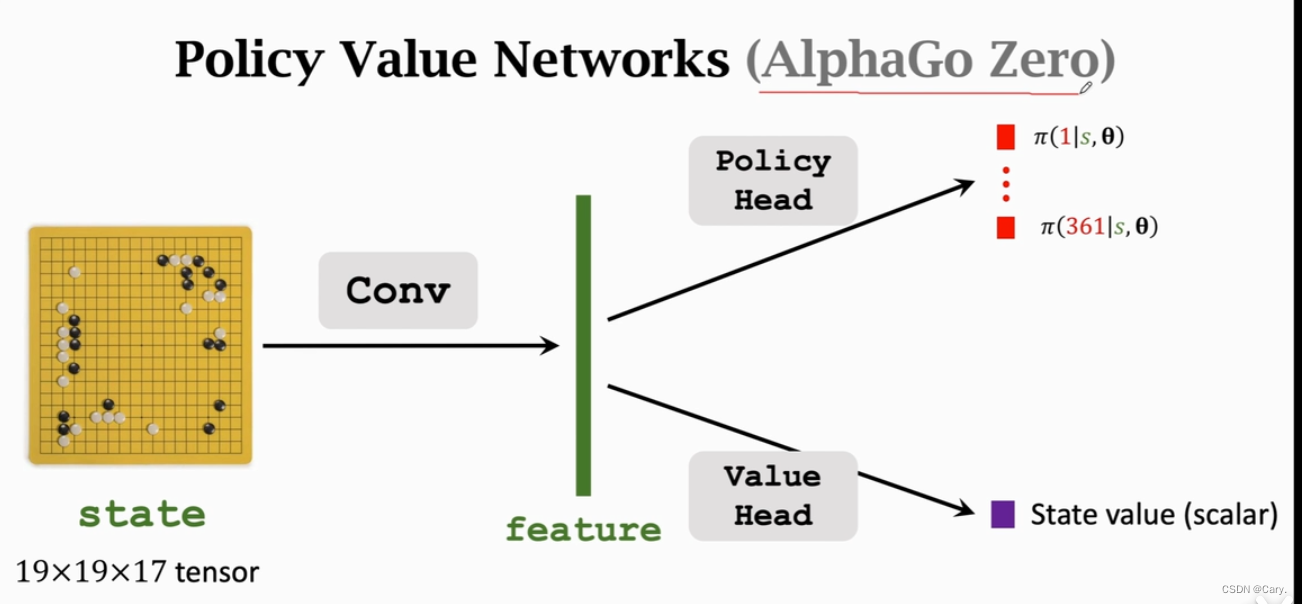
AlphaGo首先训练策略网络,再训练价值网络。(并不是actor-critic方法)
2.2.2 训练
类似于policy network的训练,value network的训练也是利用两个网路进行博弈。每一局游戏结束
得到一个ut,类比于回归问题,将ut视为target,同理使用loss的梯度下降来训练网络:

3 蒙特卡洛树搜索(MCTS)
AlphaGo真正跟人下棋时,做决策的并不是以上训练的两个网络,而是蒙特卡洛树搜索
MCTS不需要训练,可以直接做决策。训练策略网咯和价值网络的目的是辅助MCTS。
3.1 MCTS的基本思想
MCTS 的基本原理就是向前看,模拟未来可能发生的情况,从而找出当前最优的动作。
AlphaGo 每走一步棋,都要用 MCTS 做成千上万次模拟,从而判断出哪个动作的胜算最大。
做模拟的基本思想如下。假设当前有三种看起来很好的动作。每次模拟的时候从三种动作中选出一
种,然后将一局游戏进行到底,从而知晓胜负。(只是计算机做模拟而已,不是真的跟对手下完一
局。)重复成千上万次模拟,统计一下每种动作的胜负频率,发现三种动作胜率分别是 48%、
56%、52%。那么 AlphaGo 应当执行第二种动作,因为它的胜算最大。以上只是 MCTS 的基本想
法,实际做起来有很多难点需要解决。
类似于你在下五子棋时,提前想好对手下一次之后的对局情况(并不是真的下)
3.1.1 主要思想

3.2 MCTS的四个步骤

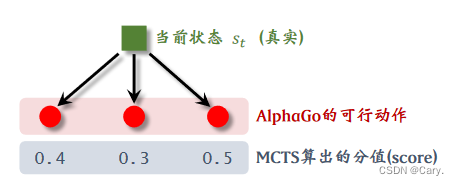
3.2.1 selection 选择
观测棋盘上的格局,找到所有未落子的空位判断其是否符合游戏规则。每个符合规则的位置都对应
一个动作。而每一步至少有几十个以上的动作,如果暴力搜索评估这些可行的动作,代价很大。因
此我们需要找出一些胜算较高的动作,进而只关注这些动作。
那么如何判断某一动作的好坏呢?两个指标:(1)动作a的胜率;(2)策略网络对a的评分。
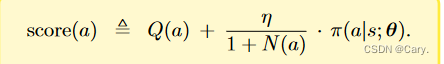
 N(a)是动作a已经被访问过的次数。初始的时候,对于所有a,令N(a)<—0,动作a每被选中一次,N(a)加一。
N(a)是动作a已经被访问过的次数。初始的时候,对于所有a,令N(a)<—0,动作a每被选中一次,N(a)加一。- Q(a)是之前N(a)次模拟算出来的动作价值,主要由胜率和价值函数决定。其初始值为0,动作a每被选中一次就会更新一次Q(a)。(后文详解)
我们可以这样理解上述公式:
- 如果动作a未被选中过,则N(a)和Q(a)都为0:
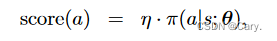
也就是说此时完全由策略网络评价动作a的好坏。
- 如果a被选中了好多次,则N(a)会很大,导致策略网络评分所占比例下降,即有:
此时,主要基于Q(a)判断a的好坏,策略网络作用不大。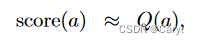
- 系数
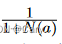 的另一个作用是鼓励探索,也就是说让选中次数少的一些动作有更大可能被选中,加入有两个动作的Q分数和v分数相近,那么选中次数少的动作score更高。
的另一个作用是鼓励探索,也就是说让选中次数少的一些动作有更大可能被选中,加入有两个动作的Q分数和v分数相近,那么选中次数少的动作score更高。
MCTS根据公式算出所有动作的分数并选择分数最高的动作:
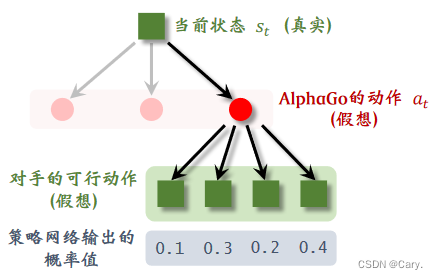
3.2.2 expansion扩展
将第一步选中的动作记为at,该动作并不是AlphaGo真正执行的动作。AlphaGo会考虑:如果自己
执行at,那么对手会执行什么动作?因此它用策略网络模拟对手,根据策略网络随机抽样一个动
作:
![]()
此时状态s'是站在对手的角度观测到的棋局。动作a't是(假想)对手选择的动作,假如对手有四种
可行的动作,AlphaGo就会用policy network算出每个动作的概率值,然后根据概率值随机抽样一
个(对手的)动作。也就是说,假设对手有四种可行的动作,AlphaGo 根据概率值做随机抽样,
替对手选中了第二种动作。对手的动作就是 AlphaGo 眼里的新的状态。
AlphaGo会在一个类似模拟器的环境中完成一局对局的模拟。它每执行一个动作ak,环境就会返回一个新状态Sk+1,因此使用正确的状态转移函数![]() 是构建一个好环境的关
是构建一个好环境的关
键。
AlphaGo模拟器利用了围棋游戏的对称性:AlphaGo的策略,在对手看来是状态转移函数,对
手的策略在AlphaGo看来也是状态转移函数。最理想的是。模拟器的状态转移函数是对手的真实策
略,而AlphaGo并不知情。但是事实是,AlphaGo只能用自己训练出来的policy network来代替对手
的策略,作为模拟器的状态转移函数。

3.2.3 evaluation求值
从状态St+1开始,双方都用policy network进行决策,在模拟器中交替落子,直至分出胜负。称这个过程为fast rollout:
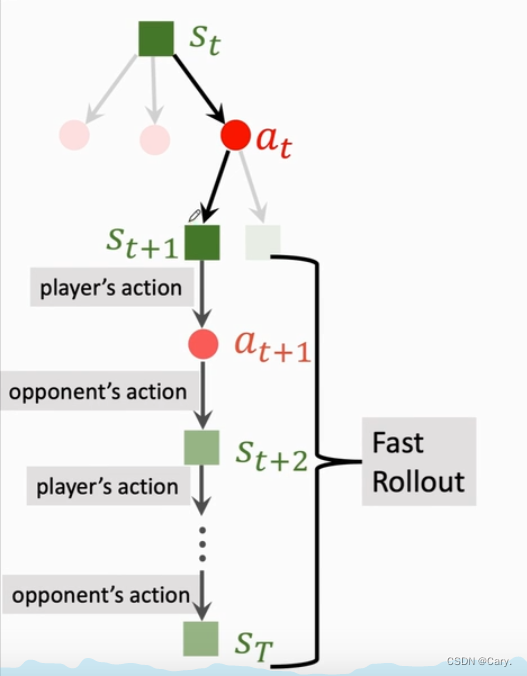
AlphaGo基于状态Sk,根据policy network抽样得到动作: ![]()
对手基于状态Sk'(对手角度观测棋局),根据policy network得到动作:![]()
当这局游戏结束,可以观测到奖励r,若AlphaGo胜,则r = +1,否则r = -1。
回顾一下:棋盘的真实状态是St,AlphaGo在模拟器中执行的动作是at,模拟器中的对手执行动作
at',跳转到新状态St+1,状态St+1越好,该局游戏胜算越大。
- 如果 AlphaGo 赢得这局模拟 (r = +1),则说明 st+1 可能很好; 如果输了 (r = −1),则说明 st+1 可能不好。因此,奖励 r 可以反映出 st+1 的好坏。
- 此外,还可以用价值网络 v 评价状态 st+1的好坏。价值 v(st+1; w) 越大,则说明状态 st+1 越好。
奖励 r 是模拟获得的胜负,是对 st+1 很可靠的评价,但是随机性太大。价值网络的评价
v(st+1; w) 没有 r 可靠,但是价值网络更稳定、随机性小。AlphaGo 的解决方案是把奖励 r 与价值
网络的输出 v(st+1; w) 取平均,记作:
![]()
将其作为对状态St+1的评价。
实际实现的时候,AlphaGo 还训练了一个更小的神经网络,它做决策更快。MCTS 在第一步
和第二步用大的策略网络,第三步用小的策略网络。那为什么在且仅在第三步用小的策略网络呢?
第三步两个策略网络交替落子,通常要走一两百步,导致第三步成为 MCTS 的瓶颈。用小的策略
网络代替大的策略网络,可以大幅加速 MCTS。

3.2.4 backup回溯
第三步中算出了第t+1步某一状态的价值,记作V(St+1),每一次模拟都会得到很多这样的价值,并
且记录下来。
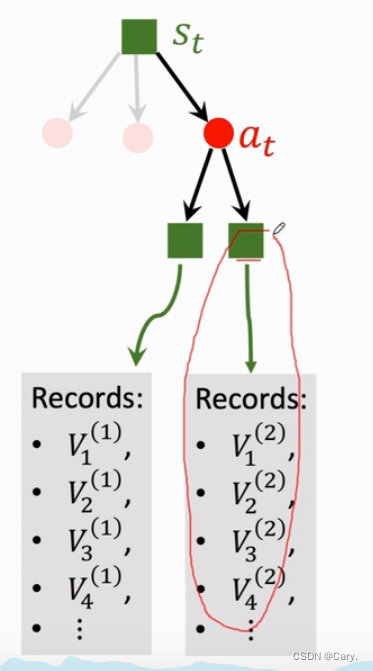
模拟会重复很多次,于是第t + 1 步每一种状态下面可以有多条记录。
将at下面所有的记录做一个平均记为价值Q(at),它可以反应动作at的好坏:

给定棋盘上的真实状态 st,有多个动作 a 可供选择。对于所有的 a,价值 Q(a) 的初始值是零。动
作 a 每被选中一次(成为 at),它下面就会多一条记录,我们就对 Q(a) 做一次更新。
3.2.5 回顾第一步—选择
基于棋盘上真实的状态 st,MCTS 需要从可行的动作中选出一个,作为 at。MCTS 计算每一个动
作 a 的分数:
![]()
然后选择分数最高的 a。这就是MCTS 求出的 Q(a)的用途。
3.3 MCTS的决策
MCTS 想要真正做出一个决策(即往真正的棋盘上落一个棋子),需要做成千上万次模拟。在做了
无数次模拟之后,MCTS 做出真正的决策:(选中N值最大的动作并执行)
![]()
此时 AlphaGo 才会真正往棋盘上放一个棋子。
那为什么要依据 N (a) 来做决策呢?在每一次模拟中,MCTS 找出所有可行的动作 {a},计算
它们的分数 score(a),然后选择其中分数最高的动作,然后在模拟器里执行。如果某个动作 a 在模
拟中胜率很大,那么它的价值 Q(a) 就会很大,它的分数 score(a) 会很高,于是它被选中的几率就
大。也就是说如果某个动作 a 很好,它被选中的次数 N (a) 就会大。
当观测到棋盘上当前状态 st,MCTS 做成千上万次模拟,记录每个动作 a 被选中的次
数 N (a),最终做出决策 at = argmaxa N (a)。到了下一时刻,状态变成了 st+1。MCTS把所有动
作 a 的 Q(a)、N (a) 全都初始化为零,然后从头开始做模拟,而不能利用上一次的结果。

总结:
AlphaGo 下棋非常“暴力”:每走一步棋之前,它先在“脑海里”模拟几千、几万局,它可以预知
它每一种动作带来的后果,对手最有可能做出的反应都在 AlphaGo 的算计之内。由于计算量差距
悬殊,人类面对 AlphaGo 时不太可能有胜算。这样的比赛对人来说是不公平的;假如李世石下每
一颗棋子之前,先跟柯洁模拟一千局,或许李世石的胜算会大于 AlphaGo。
4 AlphaGo Zero版本的训练
AlphaGo Zero 与 2016 版本的最大区别在于训练策略网络 π(a|s; θ) 方式。训练 π 的时候,不再从
人类棋谱学习,也不用 REINFORCE 方法,而是向 MCTS 学习。其实可以把 AlphaGo Zero 训
练 π 的方法看做是模仿学习,被模仿对象是 MCTS。
4.1 自我博弈
用 MCTS 控制两个玩家对弈。每走一步棋,MCTS 需要做成千上万次模拟,并记录下每个动作被
选中的次数 N (a),∀ a ∈ {1, 2, · · · , 361}。设当前是 t 时刻,真实棋盘上当前状态是 st。现在执
行 MCTS,完成很多次模拟,得到 361 个整数(每种动作被选中的次数):
![]()
对这些 N 做归一化,得到的 361 个数,它们相加等于 1;把这 361 个数记作 361 维的向量:
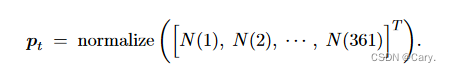
设这局游戏走了 n 步之后游戏分出胜负;奖励 rn 要么等于 +1,要么等于 −1,取决于游戏的胜
负。在游戏结束的时候,得到回报 u1 = · · · = un = rn。记录下这些数据:
![]()
用这些数据更新策略网络 π 和价值网络 v;注意这里对 π 和 v 的更新同时进行。
4.2 更新policy network
之前说过,MCTS 做出的决策优于策略网络 π 的决策,这就是为什么 AlphaGo 用 MCTS 做决
策,而 π 只是用来辅助 MCTS。既然 MCTS 比 π 更好,那么可以把 MCTS 的决策作为目标,
让 π 去模仿。这其实是行为克隆,被模仿的对象是MCTS。我们希望 π 做出的决策:
![]()
尽量接近Pt,也就是让交叉熵H(Pt,ft)尽量小,因此可以对以下目标进行优化:
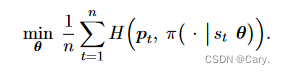
设π当前参数是θnow,进行梯度下降更新:(β为学习率)
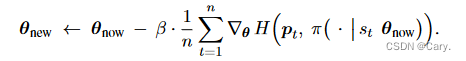

4.3 更新value network
训练价值网络的方法与 AlphaGo 2016 版本基本一样,都是让 v(st; w)拟合回报 ut。定义回归问
题:
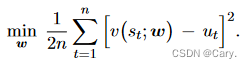
设价值网络的当前参数为Wnow,用价值网络做预测:![]()
梯度下降更新:
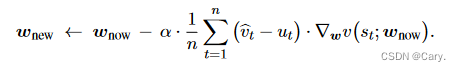
后面会详细写一下对蒙特卡洛树搜索算法的理解~

















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









