







NodeJS爬虫
需求背景
目前需要获取一些网文网站上的数据加载到本地作为数据源展示,包括图书的名称、概述、作者以及图片封面信息。故在此记录如何使用NodeJS来爬取网站信息加载到本地
准备工作
- 获取数据元素位置并找到所在div位置
首先,找到获取信息的网址:https://www.qidian.com/lishi. 这是起点中文网历史板块下的网文展示,爬取该路径下的图书信息。
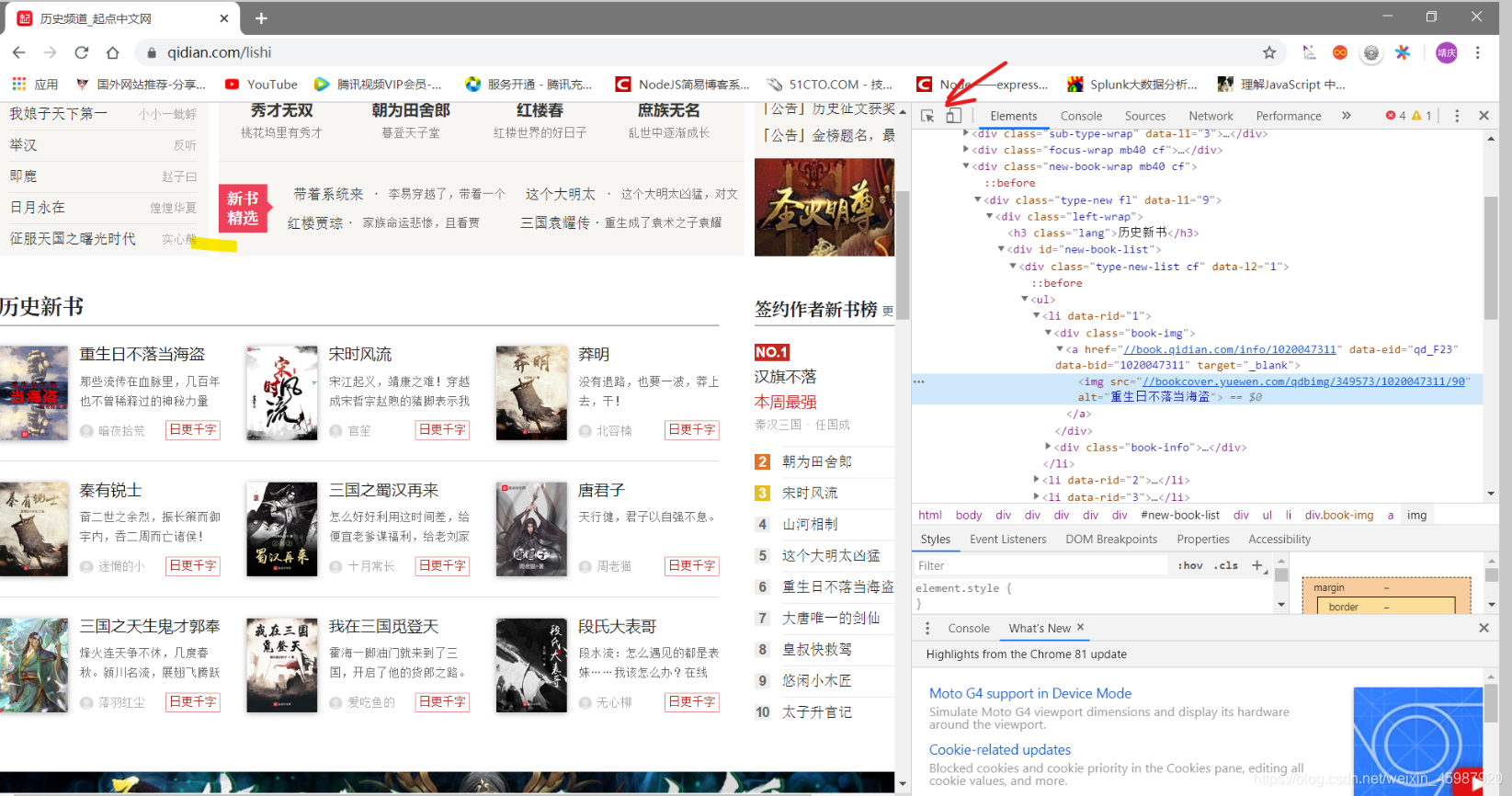
在chrome中F12打开开发者模式,点击箭头所示按钮,鼠标在网页想要爬取到本地的数据上悬停,在控制台的elements模块下会显示对应的元素信息。从该元素逐级向上找到该元素信息的祖先div(有id名称的div即可),就是所需数据存储的div位置。

可以看到,所有图书信息都存储在id名为new-book-list的div下,名称在<h4/>的<a/>标签内,概述在<p/>标签内,作者名在另一个<a/>标签内,而图片的url则写在了标签的href属性中。
到此对于网页的分析就结束了,接下来就是通过NodeJS代码来获取这些数据存储到本地了
方法步骤
-
安装爬虫所需模块
const superagent = require('superagent')const cheerio = require('cheerio')superagent是一个http方面的库,可以代替我们在浏览器中手动的去发起get或post请求。
cheerio是一个类似于jQuery的库,我们用它来对获取的html数据进行分析和处理
-
获取该网址路径的html返回信息
let bookDetails = [] superagent.get('https://www.qidian.com/lishi').end((err, res) => { if (err) { console.log(err); } else { //res为返回的信息,在getBookDetials中进行处理 bookDetails = getBookDetails(res) } }) -
处理信息,使用cheerio模块加载ret.text,其包含响应中的html内容,并且按照jQuery的命名习惯将其命名为$,然后基本就是使用jQuery的语法来分析处理数据了
let $ = cheerio.load(res.text) let bookName = [], bookDescription = [], author = [],pictureUrl = [] //找到其中名为new-book-list的div,将获取到的不同数据分别存入不同的数组中 $('div#new-book-list').each((idx, ele) => { //在名字为new-book-list的div下找到<h4></h4>包含的文本(书籍名称) $(ele).find('h4').each((idx, ele) => { bookName.push($(ele).text()) }) //在名字为new-book-list的div下找到<p></p>标签包含的内容(图书描述) $(ele).find('p').each((idx, ele) => { bookDescription.push($(ele).text()) }) //在名字为new-book-list的div下找到class为state-box的div,取出<a></a>包含的内容(作者),以及<a href="..."></a>中href包含内容(图片索引地址) $(ele).find('div.state-box').find('a').each((idx, ele) => { author.push($(ele).text()) }) $(ele).find('div.book-img').find('img').each((idx, ele) => { pictureUrl.push($(ele).attr('src')) }) }) -
此时打印各个数组信息,就能得到自己想要的数据了

下载图片
上面完成文字信息的获取,只获取了图片的url,还没有下载图片,下面开始完成图片下载的工作
-
首先第一步还是获取所依赖的库
const https = require('https')const fs = require('fs')分别是完成发送http请求和文件写入的功能
-
对于获取到图片url数据进行遍历,传入url和路径,在方法中完成图片的下载和命名
获取到图片为
//bookcover.yuewen.com/qdbimg/349573/1020209083/90这种格式,虽然复制到浏览器中可以直接打开看到图片,但是通过https.get的方法似乎不行,所以我们需要将其转化为其可以识别的请求地址路径,也就是https请求协议。猜测原因可能是因为在通过浏览器请求访问时会自动的添加在https请求协议,但是代码模块中路径没有写明该协议则无法访问。于是我们可以拼接得到如下的请求地址:https://bookcover.yuewen.com/qdbimg/349573/1020209083/90//pictureUrl为前面获取到的图片url数组,bookName为书籍名称 pictureUrl.forEach((pictureUrl, index) => { downloadPic(pictureUrl, bookName[index]) }) //根据图片地址下载图片到本地方法 function downloadPic(pictureUrl, bookName) { pictureUrl = 'https:' + pictureUrl; //增加https请求协议 let location = fs.createWriteStream('./bookPic/' + bookName + '.jpg') //指定图片下载位置和文件名称 //下载图片并存入对应location中 https.get(pictureUrl, (res) => { res.pipe(location) }) console.log(`${bookName}下载完成`); } -
通过fs的createWriteStream方法创建并写入文件,文件命名在当前文件夹的/bookPic/子目录下,文件名即为书籍名称,文件后缀为jpg格式
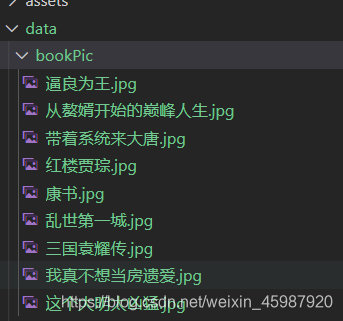
至此,书籍信息的爬取就大功告成了。
完整代码如附
/**
* 爬虫获取小说封面、名称、作者、简介、类别等信息
*/
const superagent = require('superagent')
const cheerio = require('cheerio')
const https = require('https')
const fs = require('fs')
/**
* @description 入口函数:获取报文数据
* @param {string} websiteURL 网址
* @param {string} bookType 书籍类型
*/
function getBookInfo(websiteURL,bookType) {
let bookUrl = []
//新建文件夹
mkdir(bookType)
superagent.get(websiteURL).end((err, res) => {
if (err) {
console.log(err);
} else {
bookUrl = getBookURL(res,bookType) //获取子路径
console.log(bookUrl);
getDetailInfo(bookUrl,bookType) //获取子路径的数据
}
})
}
//根据新获取到url找到对应路径的数据
function getBookURL(res, bookType) {
let bookUrl = []
let $ = cheerio.load(res.text);
console.log($('div.new-rec-wrap').length);
if(bookType==='newBook'){
//新书推荐
$('div.new-rec-wrap').find('.center-book-list').find('.book-info').each((idx,ele)=>{
bookUrl.push('https:' + $(ele).find('h3').find('a').attr('href'))
})
$('div.new-rec-wrap').find('div.rank-list').find('.book-list').find('li').each((idx, ele)=>{
bookUrl.push('https:' + $(ele).find('a').attr('href'))
})
return bookUrl
}else if(bookType==='lastUpdated'){
//最近更新
$('div#update-list').find('tr').each((idx, ele)=>{
bookUrl.push('https:'+$(ele).children('td').eq(1).children('a').attr('href'))
})
return bookUrl
}else{
//种类书籍
//本周强推10本
$("div.rec-list").find('em').find('a').each((idx, ele) => {
bookUrl.push('https:' + $(ele).attr('href'))
})
//导航栏5本
$("div.big-list").find('div.img-box').find('a').each((idx, ele) => {
bookUrl.push('https:' + $(ele).attr('href'))
})
return bookUrl
}
}
//循环获取详细数据
let getDetailInfo = async (bookUrl, bookType) => {
var bookName = [], author = [], pictureUrl = [], category = [], bookDescription = [];
await bookUrl.forEach(async function (value, index, array) {
await superagent.get(value).end((err, res) => {
if (err) {
console.log(err);
return
} else {
let $ = cheerio.load(res.text);
bookName.push($('div.book-info').find('h1').find('em').text())
author.push($('div.book-info').find('h1').find('a').text())
bookDescription.push($('div.book-intro p').text().replace(/\s/g, ''))
category.push($('p.tag a').last().text())
pictureUrl.push($('div.book-information a').first().find('img').attr('src').replace('\n', ''))
}
})
});
setTimeout(() => {
let bookInfoObj = []
//所有信息封装成对象数组
bookName.forEach((value, index, array) => {
bookInfoObj.push({
bookName: value,
author: author[index],
bookDescription: bookDescription[index],
category: category[index],
pictureUrl: pictureUrl[index]
})
});
console.log(bookInfoObj);
//下载图片
bookName.forEach((value, index, array) => {
downloadPic(pictureUrl[index], value,bookType)
})
//写入文件
writeFile(bookInfoObj,bookType)
}, 3000);
}
//新建文件夹存放数据和图片
let mkdir = async(bookType)=>{
//若该文件夹不存在则新建,否则不进行任何操作
await fs.exists('/'+bookType+'Pic/',function(exists){
if(!exists){
fs.mkdir('./'+bookType+'Pic/',function(err){
if(err){
console.log(`${bookType}Pic文件夹已存在`);
}else{
console.log(`${bookType}Pic文件夹创建成功`);
}
})
}else{
console.log('无需新建文件夹');
}
})
}
//根据图片地址下载图片到本地方法
function downloadPic(pictureUrl, bookName, bookType) {
//准备下载图片
console.log('准备下载图片');
pictureUrl = 'https:' + pictureUrl; //增加https请求协议
let location = fs.createWriteStream('./'+bookType+'Pic/' + bookName + '.jpg') //指定图片下载位置和文件名称
https.get(pictureUrl, (res) => {
res.pipe(location);
console.log(`${bookName}下载完成`);
})
}
//将获取到的数据信息写入文件
function writeFile(book,bookType) {
//将获取到的数据写入一个新的文件
let cws = fs.createWriteStream('./'+bookType+'Pic/'+bookType+'Data.js') // ./histroryPic/historyData.js
let bookData = JSON.stringify(book);
bookData = bookData.replace(/"bookName"/g, 'bookName')
bookData = bookData.replace(/"bookDescription"/g, 'bookDescription')
bookData = bookData.replace(/"author"/g, 'author')
bookData = bookData.replace(/"category"/g, 'category')
bookData = bookData.replace(/"pictureUrl"/g, 'pictureUrl')
cws.write('let bookData =' + bookData + ' \nmodule.exports = bookData')
}
//main方法 获取科幻书信息
// getBookInfo('https://www.qidian.com/kehuan','kehuan')
//main方法 获取悬疑书信息
// getBookInfo('https://www.qidian.com/lingyi','suspense')
//main方法 获取历史书信息
// getBookInfo('https://www.qidian.com/lishi', 'history')
//main方法 获取都市书信息
// getBookInfo('https://www.qidian.com/dushi','urban')
//main方法 获取现实书信息
// getBookInfo('https://www.qidian.com/youxi','game')
// getBookInfo('https://www.qidian.com/','newBook') //热门书籍
getBookInfo('https://www.qidian.com/','lastUpdated')//最近更新














 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









