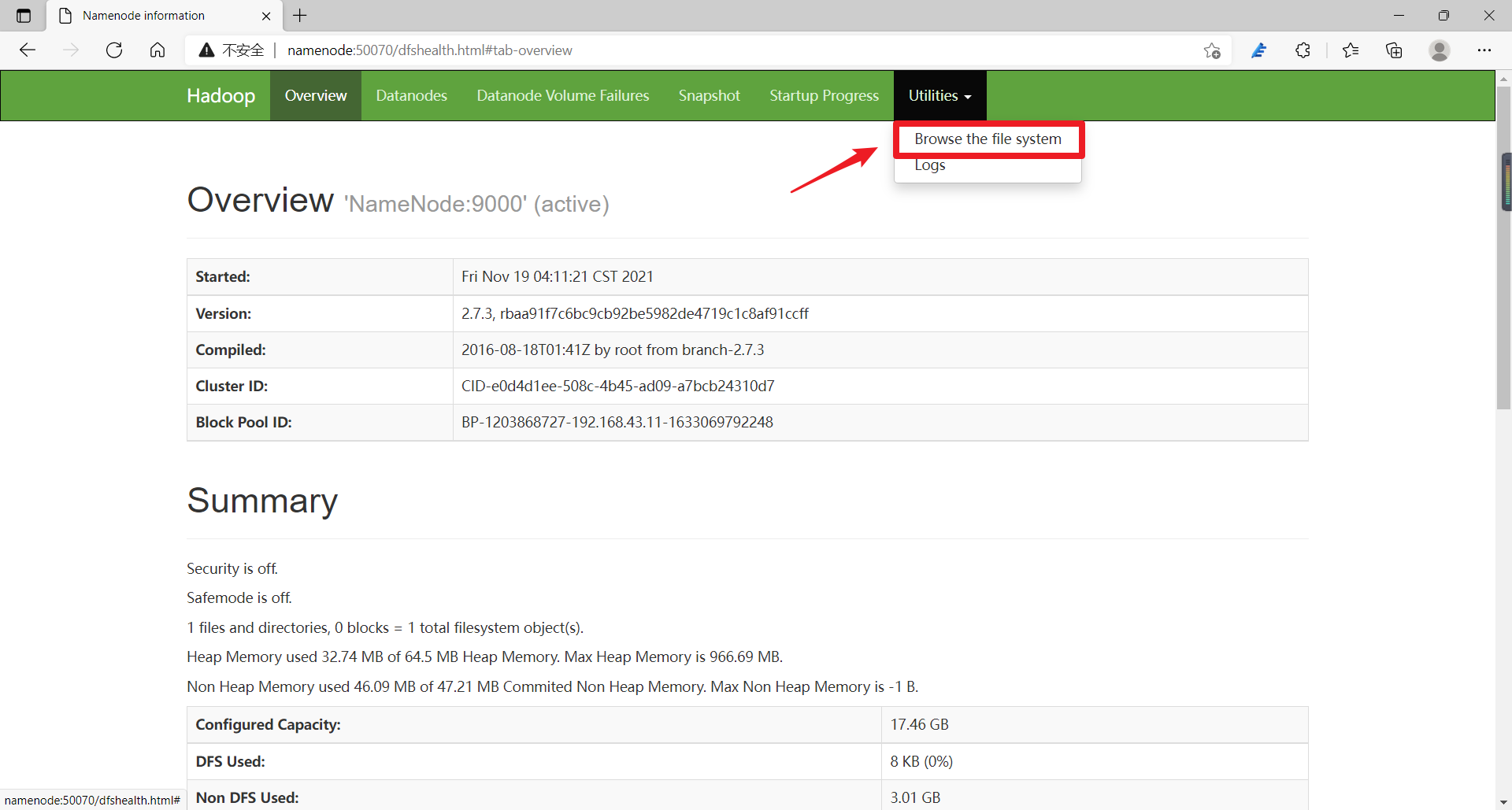
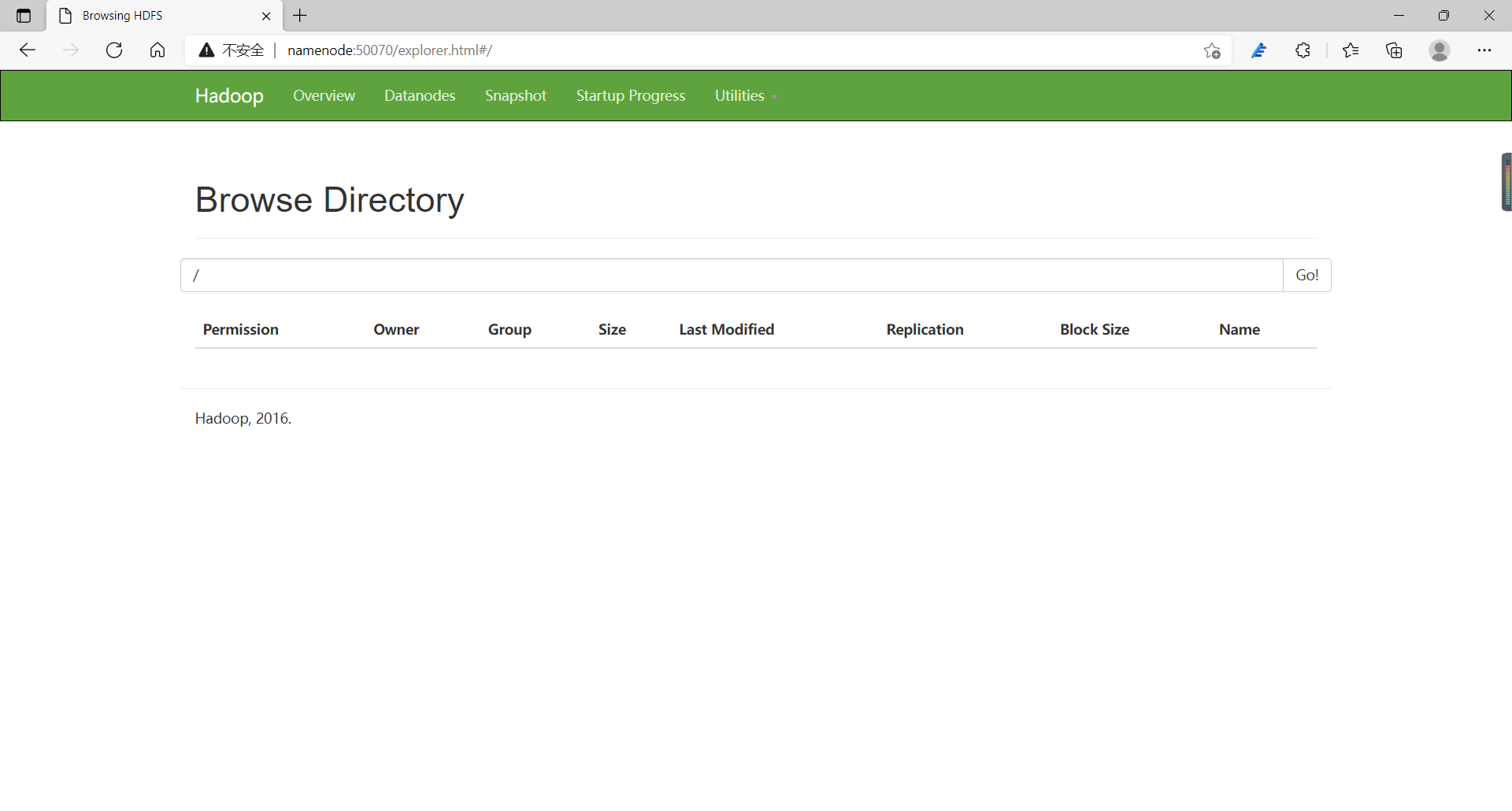
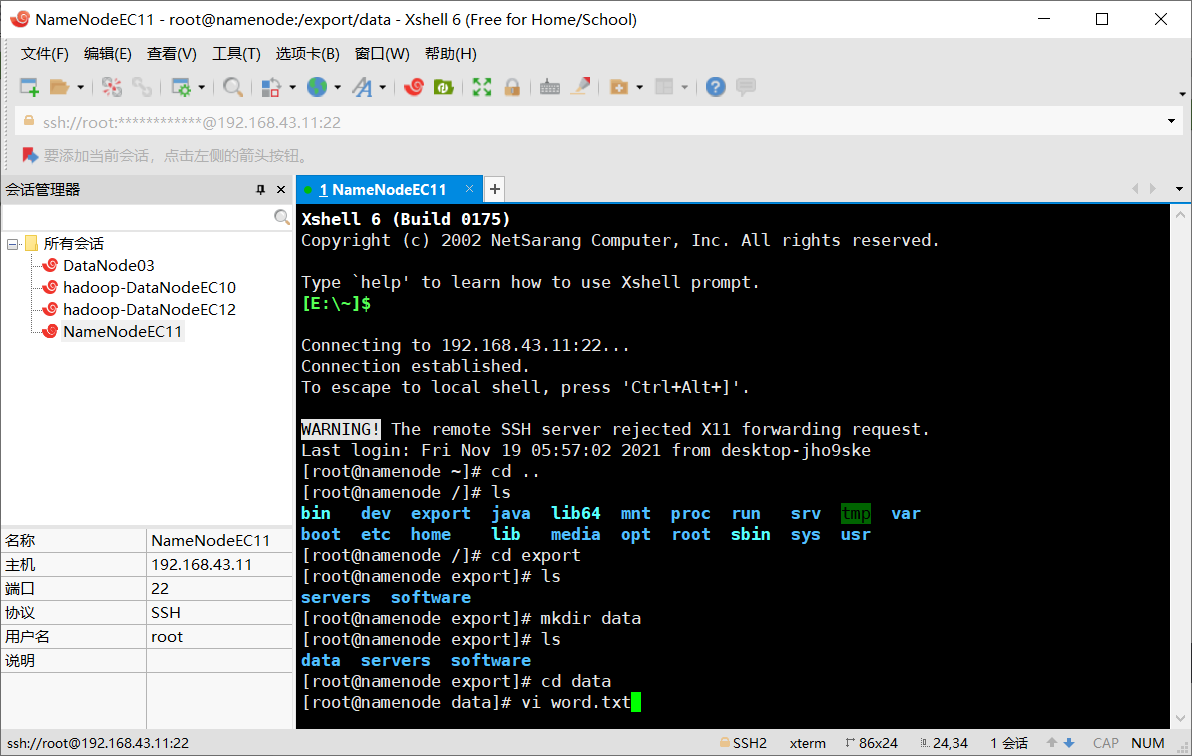
通过 Hadoop经典案例——单词统计,来演示 Hadoop集群的简单使用。 (1)打开 HDFS 的 UI,选择Utilities→Browse the file system查看分布式文件系统里的数据文件,可以看到新建的HDFS上没有任何数据文件。 (2)先在集群主节点namenode上的/export/data/目录下,执行“vi word. txt”指令新建一个 word. txt文本文件,并编写一些单词内容。 [root@namenode data]# vi word.txt


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1654
1654







