









Hadoop与数据仓库
传统数据仓库一般建立在Oracle、MySQL这样的关系数据库系统之上。关系数据库主要的问题是不好扩展,但Hadoop的数据和计算都是分布式的,可以处理海量数量。
Hadoop的核心观点是:如果一个计算可以被分成小的部分,每一部分工作在独立的数据子集上,并且计算的全局结果是独立部分结果的联合,那么此计算就可以分布在多台计算机中并行执行。
关系数据库的可扩展性瓶颈
可扩展性就是能够通过增加资源来提升容量,并保持系统性能的能力。可扩展性可分为向上扩展(Scale up)和向外扩展(Scale out)。
向上扩展
向上扩展有时也称为垂直扩展,它意味着采用性能更强劲的硬件设备,比如通过增加CPU、内存、磁盘等方式提高处理能力,或者购买小型机或高端存储来保证数据库系统的性能和可用性。
向外扩展
向外扩展有时也称为横向扩展或水平扩展,由多台廉价的通用服务器实现分布式计算,分担某一应用的负载。关系数据库的向外扩展主要有Shared Disk和Shared Nothing两种实现方式。
Shared Disk 的各个处理单元使用自己的私有CPU和内存,共享磁盘系统,典型的代表是Oracle RAC。
Shared Nothing 的各个处理单元都有自己私有的CPU、内存和硬盘,不存在共享资源,各处理单元之间通过协议通信,并行处理和扩展能力更好。
1.Oracle RAC
Oracle RAC是Oracle的集群解决方案。 其架构的最大特点是共享存储架构(Shared disk),整个RAC集群建立在一个共享的存储设备之上,节点之间采用高速网络互连。Oracle RAC提供了较好的高可用特性,比如负载均衡和透明应用切换。其最大优势在于对应用完全透明,应用无须修改便可以从单机数据库切换到RAC集群。
缺点:
RAC的扩展能力有限,32个节点的RAC已算非常庞大了。随着节点数的不断增加,节点间通信的成本也会随之增加,当到达某个限度时,增加节点不会再带来性能上的提高,甚至可能造成性能下降。
另外一个问题是,整个集群都依赖于底层的共享存储,因此共享存储的I/O能力和可用性决定了整个集群可以提供的能力。
2.MySQL Fabric
MySQL Fabric架构为MySQL提供了高可用和横向扩展的特性。可以单独使用高可用或横向扩展,也可以同时启用这两个特性。
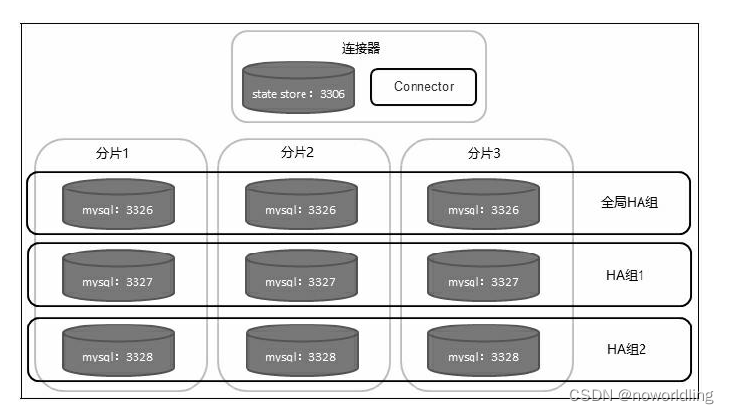
MySQL Fabric有一个HA组的概念。HA组是由两个或两个以上的MySQL服务器组成的服务器池。在任一时间点,HA组中有一个主服务器,其他的都是从服务器。HA组的作用是确保该组中的数据总是可访问的。 MySQL通过把数据复制多份提供数据安全性。
当单个MySQL服务器(或HA组)的写性能达到极限时,可以使用Fabric把数据分布到多个MySQL服务器组。管理员通过建立一个分片映射,定义数据如何在多个服务中分片。 一个分片映射作用于一个或多个表,由管理员指定每个表上的哪些列作为分片键,MySQL Fabric使用分片键计算一个表的特定行应该存在于哪个分片上。当多个表使用相同的映射和分片键时,这些表上包含相同列值(用于分片的列)的数据行将存在于同一个分片。单一事务可以访问一个分片中的所有数据。目前Fabric提供两种用分片键计算分片号的方法:HASH和RANGE。
HASH:在分片键上执行一个哈希函数生成分片号。如果作为分片键的列只有很少的重复值,那么哈希函数的结果会平均分布在多个分片上。
RANGE:管理员显式定义分片键的取值范围和分片之间的映射关系。这可以尽可能让用户控制数据分片,并确定哪一行被分配到哪一个分片。
Fabric连接器会应用正确的范围或哈希映射,并将事务路由到正确的分片。当需要更多的分片时,MySQL Fabric可以把现有的一个分片分成两个,同时修改状态存储和连接器中缓存的路由数据。
下图所示的是一个具有高可用和数据分片特性的MySQL Fabric架构,图中共有10个MySQL实例,其中一个运行连接器,另外九个是工作节点。每行的三个实例是一个HA组,每列的三个实例是一个数据分片。
CAP理论
CAP理论指的是任何一个分布式计算系统都不能同时保证如下三点:
Consistency(一致性):所有节点上的数据时刻保持同步。
Availability(可用性):每个请求都能接收到一个响应,无论响应成功或失败。
Partition tolerance(分区容错性):系统应该能持续提供服务,无论网络中的任何分区失效。
CA without P:如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但其实分区不是想不想的问题,而是终会存在。因此CA的系统更多的是允许分区后各子系统依然保持CA。传统关系型数据库大都是这种模式。
CP without A:如果不要求A(可用),相当于每个请求都需要在节点之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
AP wihtout C:要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
Hadoop数据仓库工具
当数据仓库应用的规模和数据量大到一定程度,关系数据库已经不再适用。
1.RDS和TDS
RDS是原始数据存储,其数据是从操作型系统抽取而来。它有两个作用,一是充当操作型系统和数据仓库之间的过渡区,二是作为细节数据查询的数据源。TDS是转换后的数据存储,也就是数据仓库,用于后续的多维分析或即席查询。
2.抽取过程
这里的抽取过程指的是把数据从操作型数据源抽取到RDS的过程。
Hadoop生态圈中的主要数据摄取工具是Sqoop和Flume。
Sqoop被设计成支持在关系数据库和Hadoop之间传输数据,而Flume被设计成基于流的数据捕获,主要是从日志文件中获取数据。使用这两个工具可以完成数据仓库的抽取。
3.转换与装载过程
转换与装载过程是将数据从RDS迁移到TDS的过程,期间会对数据进行一系列的转换和处理。经过了数据抽取步骤,此时数据已经在Hive表中了,因此Hive可以用于转换和装载。
Hive实际上是在MapReduce之上封装了一层SQL解释器,这样可以用类SQL语言书写复杂的MapReduce作业。
4.过程管理和自动化调度
ETL过程自动化是数据仓库成功的重要衡量标准,也是系统易用性的关键。
Hadoop生态圈中的主要管理工具是Falcon。Falcon把自己看作是数据治理工具,能让用户建立定义好的ETL流水线。除Falcon外,还有一个叫做Oozie的工具,它是一个Hadoop的工作流调度系统,可以使用它将ETL过程封装进工作流自动执行。
5.数据目录
数据目录存储的是数据仓库的元数据,主要是描述数据属性的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hadoop生态圈中主要的数据目录工具是HCatalog。HCatalog是Hadoop上的一个表和存储管理层。
通过HCatalog可以更加容易地读写集群中的数据。HCatalog引入“表”的抽象,把文件看做数据集。它展现给用户的是一个HDFS上数据的关系视图,可以轻松知道系统中有哪些表,表中都包含什么。
HCatalog默认支持多种文件格式的读写,如RCFile、SequenceFiles、ORC files、text files、CSV、JSON等。
6.查询引擎和SQL层
查询引擎和SQL层主要的职责是查询和分析数据仓库里的数据。
Hadoop生态圈中的主要SQL查询引擎有基于MapReduce的Hive、基于RDD的SparkSQL和Cloudera公司的Impala。
Hive可以在Tez、MapReduce和Spark(Storm上不行)上执行类SQL查询。
Impala提供SQL语义,最大特点是速度快,主要用于OLAP。
7.用户界面
Hadoop生态圈中比较知名的数据可视化工具是Hue和Zeppelin。Hue是一个开源的Hadoop UI系统,最早是由Cloudera Desktop演化而来,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,还可以用图形化的方式定义工作流。Hue默认支持的数据源有Hive和Impala。
Zeppelin提供了Web版的notebook,用于做数据分析和可视化。Zeppelin默认只支持SparkSQL。














 2338
2338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









