







异步加载
一.特殊的异步加载
有一些网页,显示在页面上的内容要经过多次异步请求才能得到。第1个AJAX请求返回的是第2个请求的参数,第2个请求的返回内容又是第3个请求的参数,只有得到了上一个请求里面的有用信息,才能发起下一个请求。(ajax-json在我的另一篇博客里)
这里介绍的是最常见、最简单的异步加载情况,但并非所有的异步加载都会向后台发送请求
我们还是按照之前的来练习:训练地址(链接: http://exercise.kingname.info/exercise_ajax_2.html.)
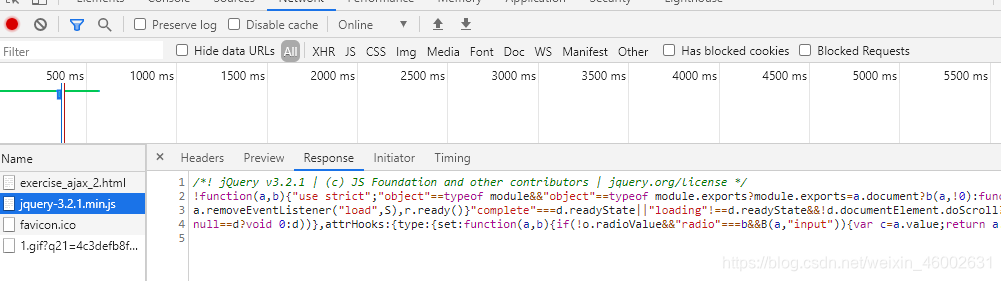
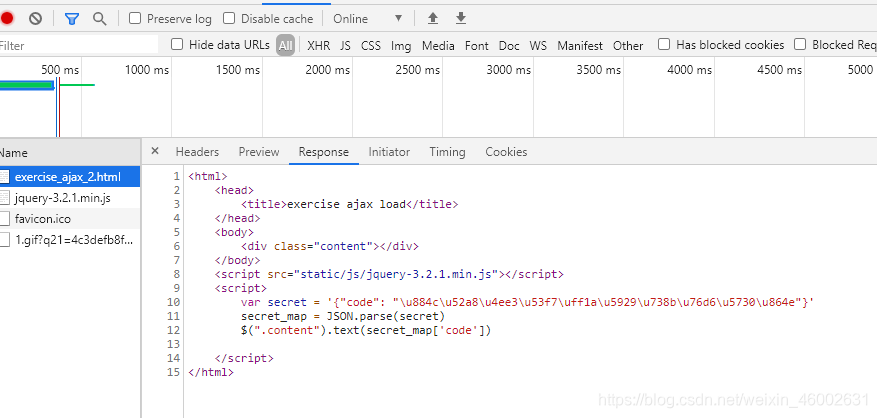
这里我们可以看到分析Chrome开发者工具的“Network”选项卡下面的内容,可以看到整个页面的打开过程并没有尝试请求后台的行为。其中的exercise_ajax_2.html就是这个页面自身,而jquery-3.2.1.min.js是jQuery的库,都不是对后台的请求。打开网页源代码可以看到,确实没有“天王盖地虎”这几个汉字
这里我们注意到,源代码最下面的JavaScript代码,其中有一段
‘{“code”: “\u884c\u52a8\u4ee3\u53f7\uff1a\u5929\u738b\u76d6\u5730\u864e”}’
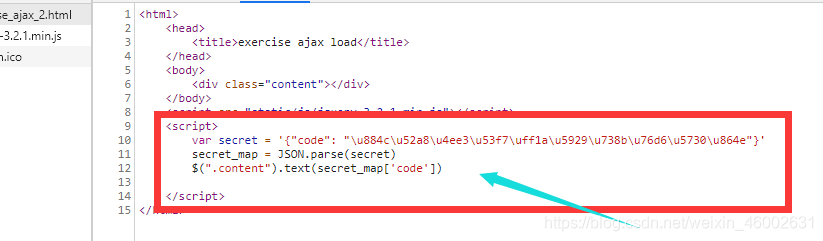
这种假的异步加载页面,其处理思路一般是使用正则表达式从页面中把数据提取出来,然后直接解析
#-*- cdoeing = utf-8 -*-
#@Time : 2020-12-15
#name : LBOcean
import json
import requests
import re
url = "http://exercise.kingname.info/exercise_ajax_2.html"
home = requests.get(url).content.decode()
code_json = re.search("secret = '(.*?)'", home, re.S).group(1)
code_dict = json.loads(code_json)
print(code_dict['code'])
二.多次请求的异步加载
还有一些网页,显示在页面上的内容要经过多次异步请求才能得到。第1个AJAX请求返回的是第2个请求的参数,第2个请求的返回内容又是第3个请求的参数,只有得到了上一个请求里面的有用信息,才能发起下一个请求。
我们还是按照之前的来练习:训练地址(链接: http://exercise.kingname.info/exercise_ajax_3.html.)
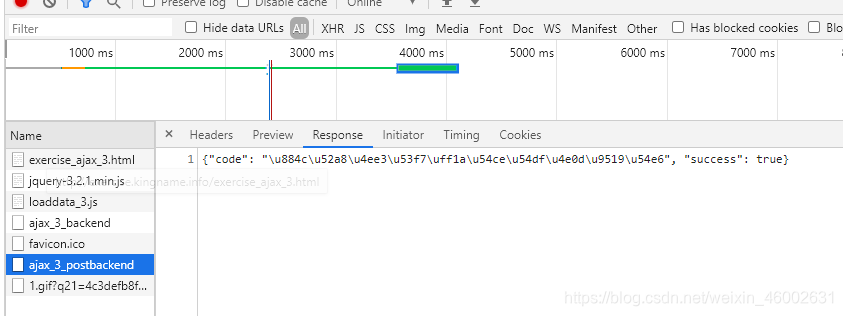
通过分析Chrome开发者工具的请求,不难发现这一条信息是通过向http://exercise.kingname.info/ajax_3_postbackend这个地址发送POST请求得到的
我们通过json数据解析可以得到如下字样
import json
code = '{"code": "\u884c\u52a8\u4ee3\u53f7\uff1a\u54ce\u54df\u4e0d\u9519\u54e6", "success": true}'
code_json = json.loads(code)
print(code_json)
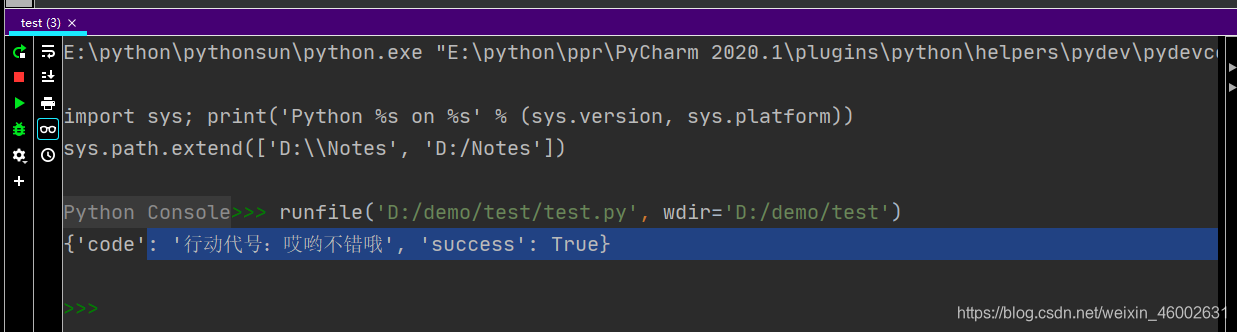
这里我们可以看到,这一段参数(下图)分析一下是做什么的
如果我们修改了参数,会怎么样呢?
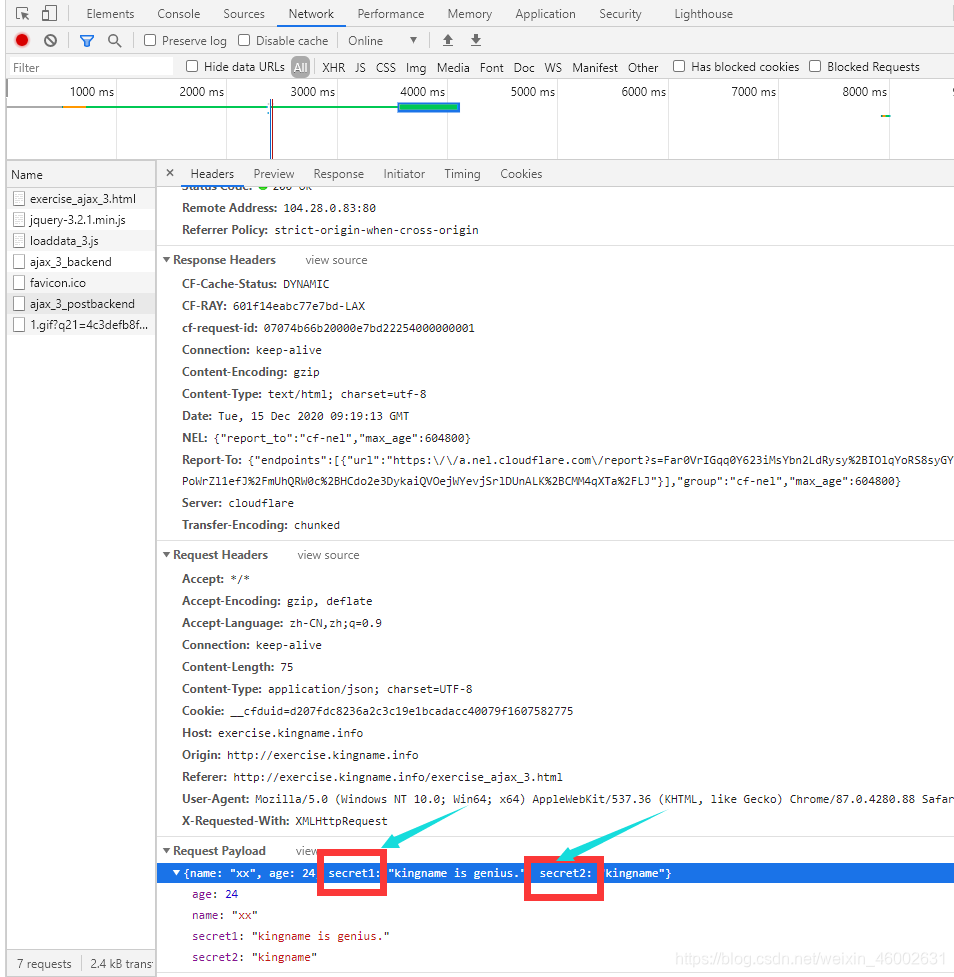
这里我们可以看到返回了两个参数问题(下图)
import json
import requests
url = "http://exercise.kingname.info/ajax_3_postbackend"
return_json = requests.post(url,json={'name': "LBOcean",
'age': 24,
'secret1': "110",
'secret2': "120"})
return_json_one = requests.post(url,json={"name" : "LBOcean" ,
"age" : 20})
json_data1=json.loads(return_json.content.decode())
json_data2=json.loads(return_json_one.content.decode())
print('乱写的secret1,secret2:',json_data1)
print('没写全:',json_data2)

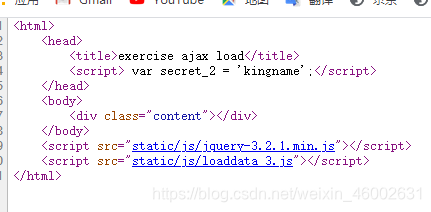
打开网页源代码我们可以看到,secret_2 = kingname的
对于这种多次请求才能得到数据的情况,解决办法就是逐一请求,得到返回结果以后再发起下一个请求。具体到这个例子中,那就是先从源代码里面获得secret2,再通过GET请求得到secret1,最后使用secret1和secret2来获取页面上显示的内容
#-*- cdoeing = utf-8 -*-
#@Time : 2020-12-15
#name : LBOcean
import json
import re
import requests
url = 'http://exercise.kingname.info/exercise_ajax_3.html'
first_url = 'http://exercise.kingname.info/ajax_3_backend'
second_url = 'http://exercise.kingname.info/ajax_3_postbackend'
home = requests.get(url).content.decode()
secret2 = re.search("secret_2 = '(.*?)'", home, re.S).group(1)
ajax_json1 = requests.get(first_url).content.decode()
ajax_json1_dict = json.loads(ajax_json1)
secret1 = ajax_json1_dict['code']
ajax_json2 = requests.post(second_url,json={"name" : "LBOcean",
"age" : 20,
"secret1" : secret1,
"secret2" : secret2}).content.decode()
ajax_json2_dict = json.loads(ajax_json2)
code = ajax_json2_dict['code']
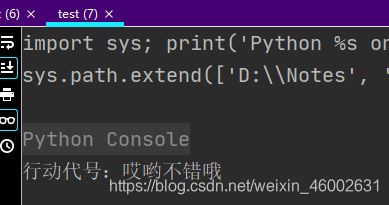
print(code)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









