







Redis基本数据结构
前言
Redis有几种基本数据结构?分别是什么?分别什么情况下会使用?redis总共有string,list,set,zset,hash(字典)五种数据结构
一、redis对象
redis.h
/*
* redis对象
*/
typedef struct redisObject {
// 对象的类型(取值范围:REDIS_STRING, REDIS_LIST, REDIS_HASH, REDIS_SET, REDIS_ZSET)
unsigned type:4;
// 对象的编码(取值范围:REDIS_ENCODING_INT, REDIS_ENCODING_EMBSTR, REDIS_ENCODING_RAW, REDIS_ENCODING_HT, REDIS_ENCODING_LINKEDLIST,REDIS_ENCODING_ZIPLIST,REDIS_ENCODING_INTSET,REDIS_ENCODING_SKIPLIST)
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
unsigned notused:2; /* Not used */
unsigned lru:22; /* lru time (relative to server.lruclock) */
int refcount;
} robj;
1 type-对象类型
每当我们在redis中新建一个键值对的时候,至少会创建两个对象,;一个是key,一个是value。key对象总是一个字符串类型的对象,而值对象则是5种对象类型中的任意一种。
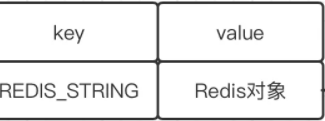
key:REDIS_STRING
value:REDIS_LIST
REDIS_HASH
REDIS_SET
REDIS_ZSET
REDIS_STRING
2 encoding-编码
prt指针指向底层实现数据结构,而这些数据结构由encoding属性决定。因为在不同场景下会用到不同类型的数据结构,因此需要选用不同的编码方式,从而优化某一场景下的效率。

二、基本数据结构
1.String
适用场景:缓存业务信息,且只是根据key直接获取缓存value,不需要排序,去重等功能。存储速度是最快的。字符串底层数据结构就是字符数组。
1.1 基本操作
赋值
set no_1 muse
获取值
get no_1
删除no_1
del no_1
设置no_1 10秒后过期
expire no_1 10
setex no_1 10 muse

1.2 应用场景
1、key和命令是字符串
2、普通的赋值
3、incr用于乐观锁
incr:递增数字,可用于实现乐观锁 watch(事务)
4、setnx用于分布式锁
当value不存在时采用赋值,可用于实现分布式锁
1.3内部实现
字符串可以使用int、raw、embstr这三种encoding。那么分别什么情况下会选择不同encoding呢?
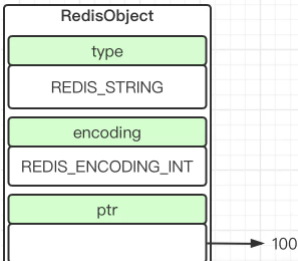
1.3.1 int
如果保存的是可以long类型表示的整数值,那么encoding为int。
1.3.2 embstr
保存的值小于40,则使用embstr;
embstr编码是专门用于保存短字符串的一种优化编码方法,**它与raw编码的区别是raw编码会调用两次内存分配函数来分别创建redisObject和sdshdr,而embstr编码则通过调用一次内存分配函数来分配一块连续的redisObject和sdshdr。**因为都是保存在同一个空间,所以embstr执行速度会更快。
数据结构如下:
1.3.3 raw
保存的值大于40,则使用raw(raw编码会调用两次内存分配函数来分别创建redisObject和sdshdr)

2.List
2.1 使用场景
1、作为栈或队列使用
列表有序可以作为栈和队列使用
2、可用于各种列表,比如用户列表、商品列表、评论列表等。
2.2 基本操作

2.3 内部实现
list实现的内部编码支持ziplist和linkedlist两种
2.3.1 ziplist
ziplist列表对象,采用压缩列表实现。每个列表节点保存一个列表中的元素。“rpush testlist a b c”

2.3.2 linkedlist
linked编码列表对象,采用双向链表作为底层实现,每个列表节点保存一个列表中的元素。
数据结构如下:

编码转换规则:列表中所有元素长度都小于66字节(zipllist),列表中元素个数小于512个(linklist)
3.Set
3.1 使用场景
存储有去重需求的数据,比如:针对一篇文章用户进行点赞操作;关注的用户,还可以通过spop进行随机抽奖,它的特点是内部元素无序不重复。它内部实现相当于一个特殊的字典,字典里的所有value指都为null。
3.2 基本操作

3.3 内部实现
3.3.1 inset
inset编码集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面。
数据结构如下:
3.3.2 hashtable
底层字典作为底层实现,每个键都是一个字符串对象,每个字符串对象都包含一个集合元素,而字典的值全部被设置为NULL。
数据结构如下:
编码转换规则:当集合中同时满足集合对象保存的所有元素都是整数值;集合对象保存的元素数量不超过512个使用intset,否则使用hashtable
4.ZSet
4.1 使用场景
存储去重且有序的数据,比如:学生高考成绩,适用于各种排行榜。比如:点击排行榜、销量排行榜、关注排行榜等。
4.2 基本操作

4.3 内部实现
有序集合编码的内部实现可以是ziplist或skiplist
4.3.1 ziplist
ziplist使用压缩列表作为底层实现,第一个节点保存元素的成员(member),而第二个节点则保存元素的分值(score)。压缩列表内的集合元素按分值从小到大进行排序。
数据结构如下:

4.3.2 skiplist
skiplist编码的有序集合采用zset结构作为底层实现,一个zset同时包含一个字典和一个跳跃表。

5.Hash
5.1 使用场景
存储无序字典的数据,比如:适合存储对象类型。比如猪肉价格。
内部采用的是数组+链表的结构,类似Java中hashmap。hash的key只能是字符串。将对象存储为hash结构可以针对需求来获取部分数据,而不是将整个对象获取。
5.2 基本操作

5.3 内部实现
5.3.1 ziplist
ziplist编码底层使用压缩列表实现,当有新的键值对要加入到哈希对象时,会先将key值从队尾推入压缩列表中,再将这个key对应的value值从队尾推入压缩列表中;所以,同一键值对的两个节点总是紧挨在一起的,key在前,value在后。
数据结构如下:

4.3.2 hashtable
数据结构如下:

编码转换规则:同时满足两个条件时是ziplist编码类型,否则是hashtable编码类型
条件1:哈希对象中所有键值对中,key和value的长度均小于46字节。
条件2:哈希对象中键值对的个数小于512个。
总结
以上就是今天要讲的内容,本文仅仅简单介绍了reidis基本数据结构及其使用。















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









