






前言:使用场景
在JMeter使用配置元件CSV Data Set Config进行参数化之时,该元件的配置项Sharing mode的设置往往令人迷惑不解.
1 配置解析
"Sharing mode"的中文意思是"线程共享模式",有三个可供选择的值:
1)All threads(所有现场)
2)Current thread group(当前线程组)
3)Current thread(当前线程)
其值的设置会影响到参数取值,为了使参数能获取正确的值来满足特定的业务需求,
有必要深入理解其对参数取值的影响,接下来逐一进行剖析.
1.1 All thread
是指在CSV Data Set Config配置元件作用域范围内的所有线程共享一个数据源文件.
也就是说在JMeter测试执行过程中,JMeter仅打开一次该数据源文件,每个线程读取的
是同一个数据源文件中的数据.
线程按照启动的先后顺序依次从数据源文件中获取一个值,不论该线程是否引用
CSV Data Set Config中定义的变量,每个线程都会分配一个值,这样可以保证每个线程
获取的是数据源文件中不同行的列值(在不循环取值的情况下).
1.2 Current thread group
在CSV Data Set Config配置元件作用域范围内的所有线程组,当JMeter执行测试时,
每一个线程组都单独打开一次数据源文件(可以是相同或不同的数据源文件).
每个线程组下的各个线程都是从数据源文件的起始处读取参数值.
若要线程组读取不同的数据源文件,可以对数据源文件的路径进行参数化.
这里需要使用${__threadGroupName}来获取线程组的名字.
假设有n个线程组:
tg1,tg2,...,tgn
每个线程组对应一个数据源文件,对应的文件名分别为:
tg1.csv,tg2.csv,...,tgn.csv
在配置时将"Filename"设置为".../${__threadGroupName}.csv"即可.
1.3 Current thread
在CSV Data Set Config配置元件作用域范围内的所有线程组,当JMeter执行测试时,
每一个线程都单独打开一次数据源文件(可以是相同或不同的数据源文件).
每个线程都是从数据源文件的起始处读取参数值.
若要线程组读取不同的数据源文件,可以对数据源文件的路径进行参数化.
这里需要使用${__threadNum}来获取线程编号.
假设有n个线程,线程编号为:1,2,...,n
每个线程对应一个数据源文件,对应的文件名分别为:
testdata1.csv,testdata2.csv,...,testdatan.csv
在配置时将"Filename"设置为".../testdata${__threadNum}.csv"即可.
2 案例说明
2.1 All thread案例
1)新建数据源文件testdata.csv,设置其值为:
h
1
2
3
4
5
6
2)配置"Test Plan",勾选"Run Thread Groups consecutively(i.e. one at a time),
保证线程组按顺序依次执行;
3)添加"CSV Data Set Config",其配置下图所示:

image
4)在"Test Plan"下添加线程组"tg1",设置线程数为5;
5)在"tg1"下添加HTTP取样器,HTTP请求中没有引用参数p,配置如下图所示:
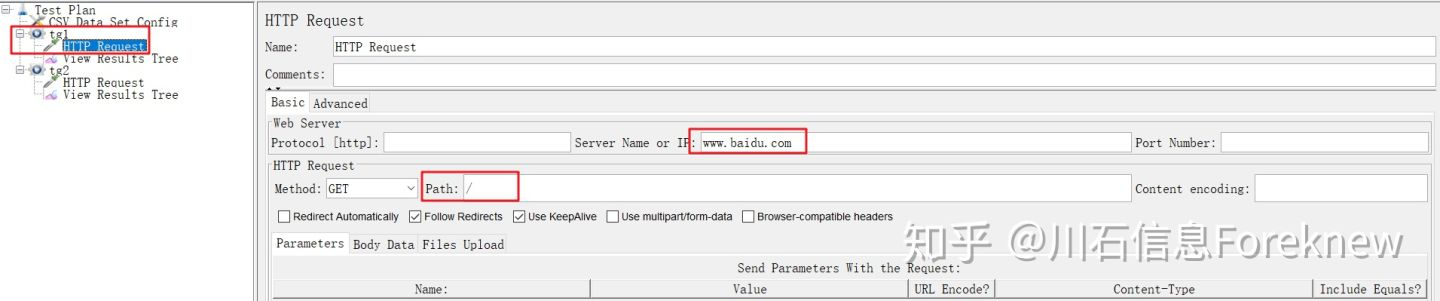
image
6)在"Test Plan"下添加线程组"tg2",设置线程数为2;
7)在"tg2"下添加HTTP取样器,HTTP请求中引用了参数p,配置如下图所示:

image
8)在"tg1","tg2"下分别添加"View Results Tree".
保存并执行测试,tg1,tg2的查看结果树内容分别如下图所示:
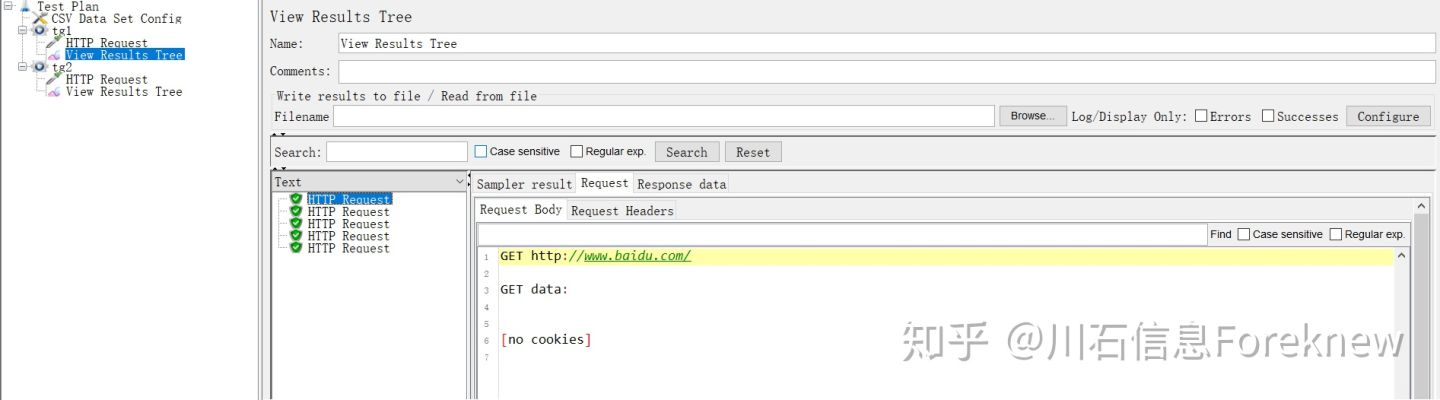
image
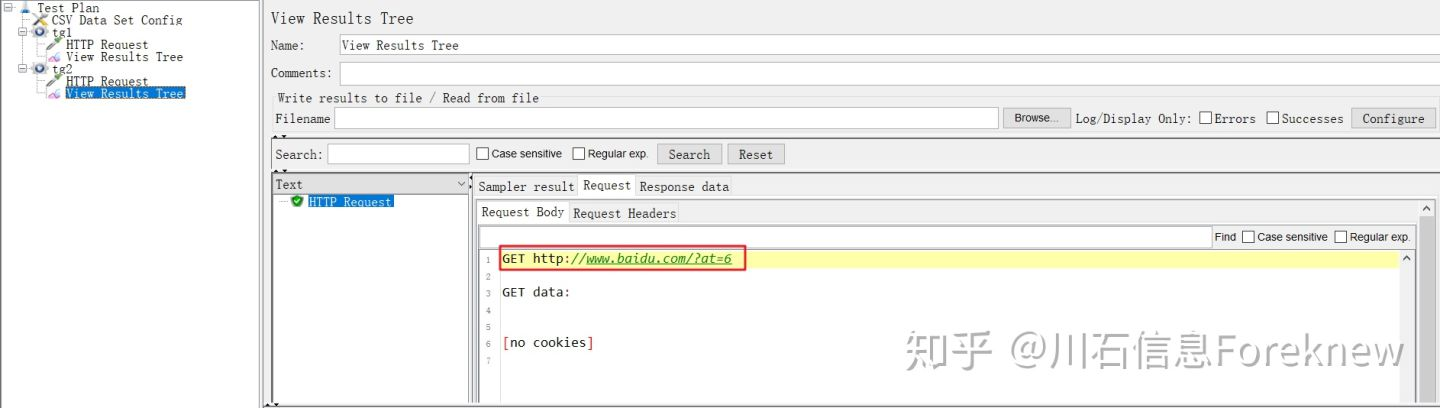
image
从结果可以看出,线程组"tg1"的5个线程即使没有引用参数p,也都各自分配了一个值,
线程组"tg1"先于线程组"tg2"启动,线程组"tg2"的2个线程,第一个线程获取了第6个
值"6",第二个线程获取不到值就停止了,所有只显示了一个取样器的结果.
进一步查看jmeter log,可以看出在测试执行过程中testdata.csv只打开一次:
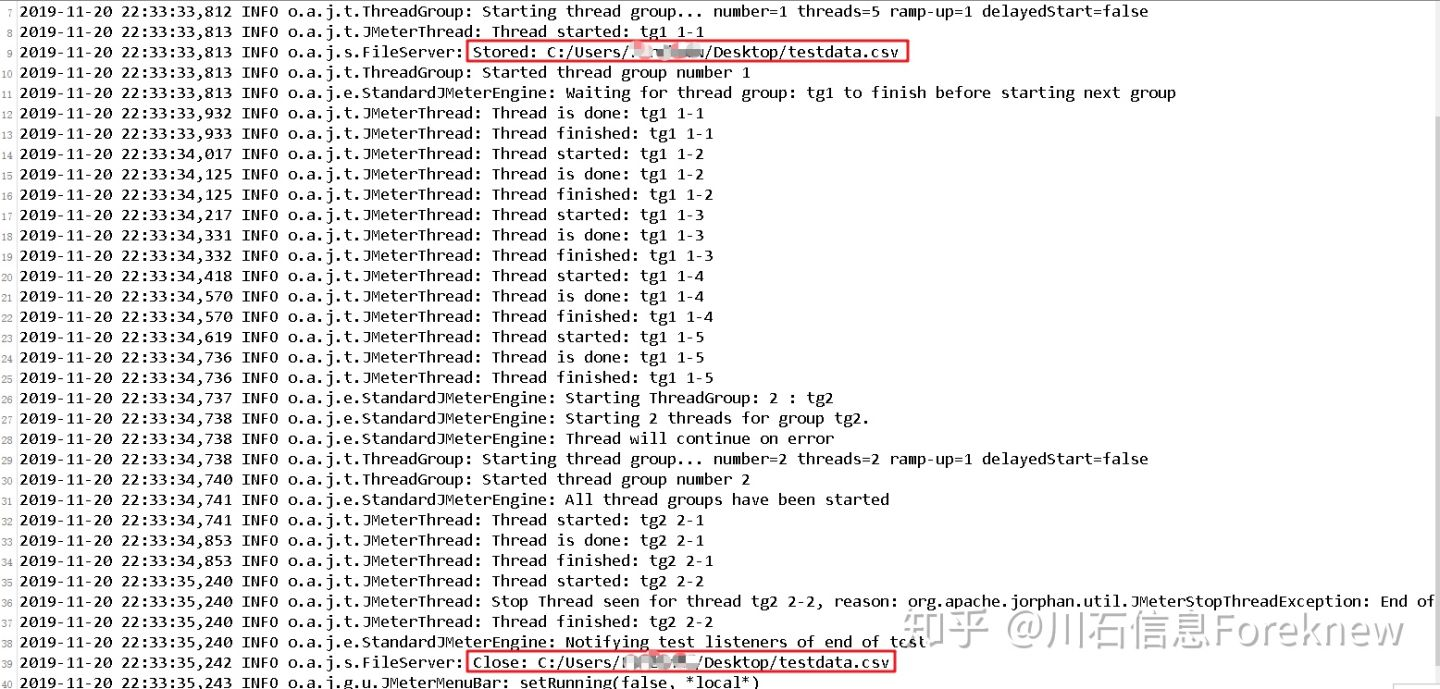
image
2.2 Current thread group案例
1)新建数据源文件tg1.csv,设置其值为:
h
111
222
333
444
555
666
2)新建数据源文件tg2.csv,设置其值为:
h
aaa
bbb
ccc
ddd
eee
3)配置"Test Plan",勾选"Run Thread Groups consecutively(i.e. one at a time),
保证线程组按顺序依次执行;
4)添加"CSV Data Set Config",其配置下图所示:
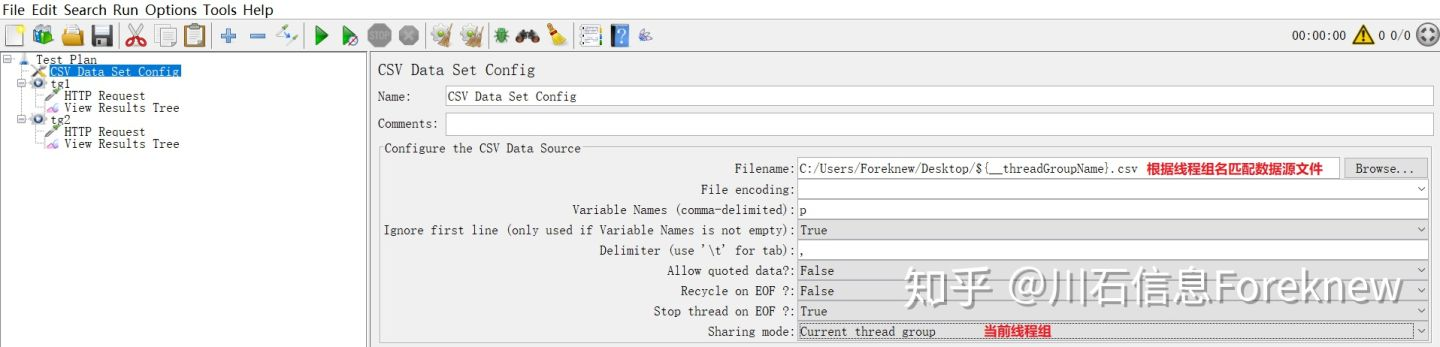
image
5)在"Test Plan"下添加线程组"tg1",设置线程数为5;
6)在"tg1"下添加HTTP取样器,HTTP请求中引用参数p,配置如下图所示:
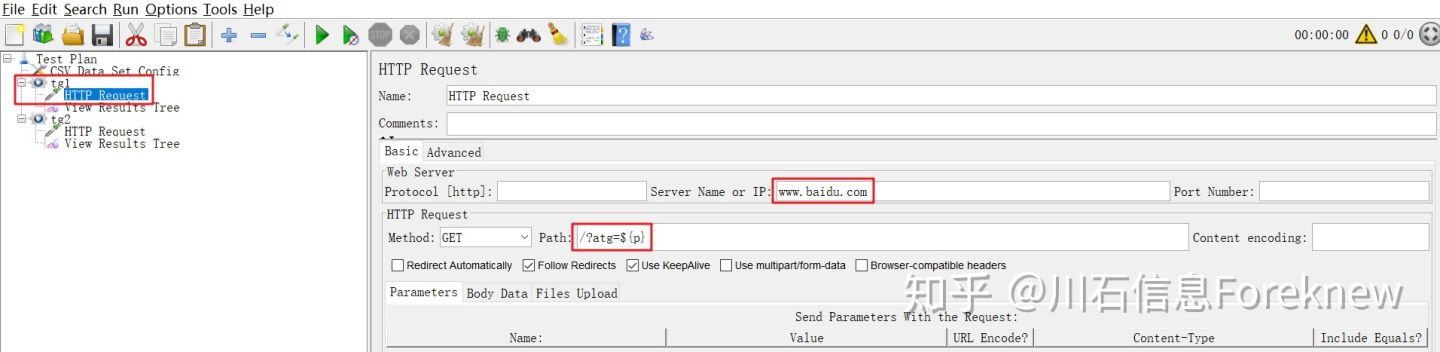
image
7)在"Test Plan"下添加线程组"tg2",设置线程数为2;
8)在"tg2"下添加HTTP取样器,HTTP请求中引用参数p,配置如下图所示:
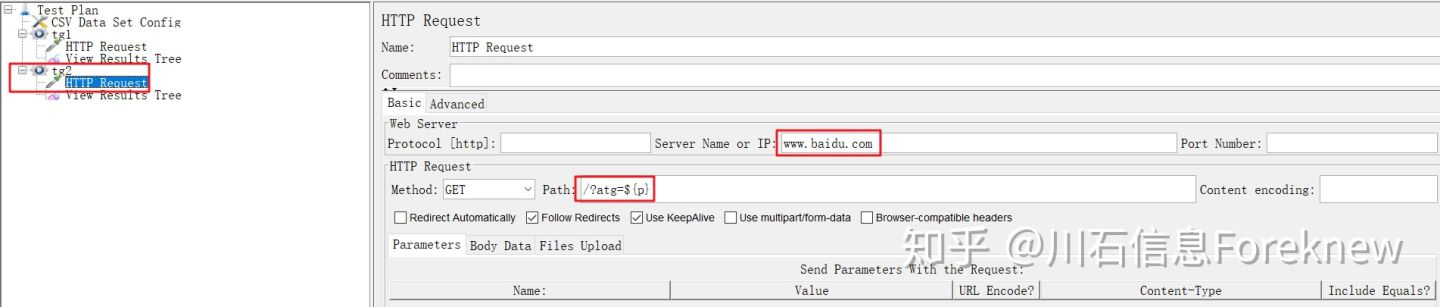
image
9)在"tg1","tg2"下分别添加"View Results Tree".
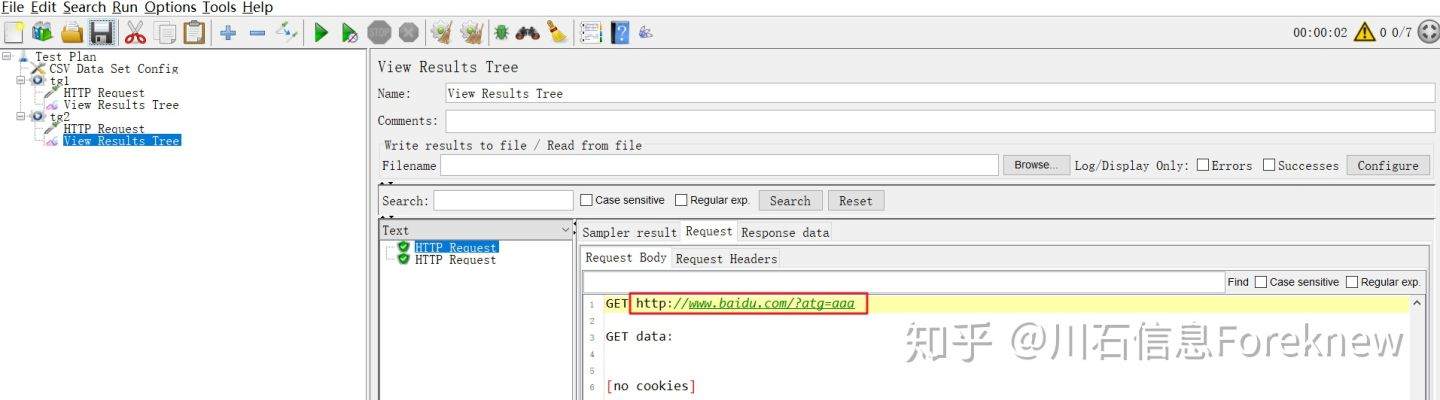
保存并执行测试,tg1,tg2的查看结果树内容分别如下图所示:
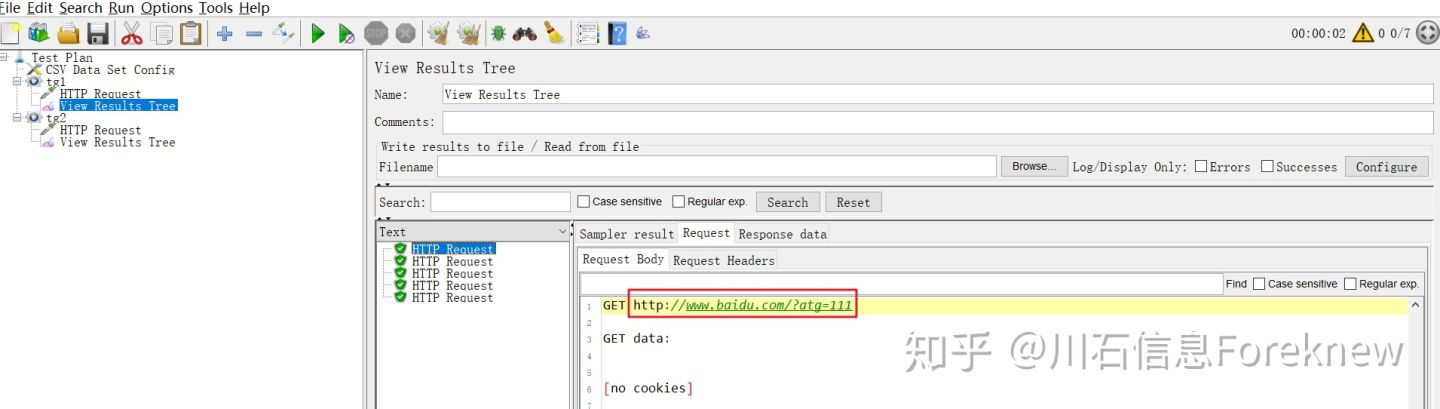
image
image
从结果可以看出,线程组"tg1"获取的是tg1.csv文件中的值,5个线程分别获取了
111,222,333,444,555;线程组"tg2"获取的是tg2.csv文件中的值,2个线程分别获取了
aaa,bbb.
进一步查看jmeter log,可以看出在测试执行过程中每个线程组都单独
打开了一次数据源文件:
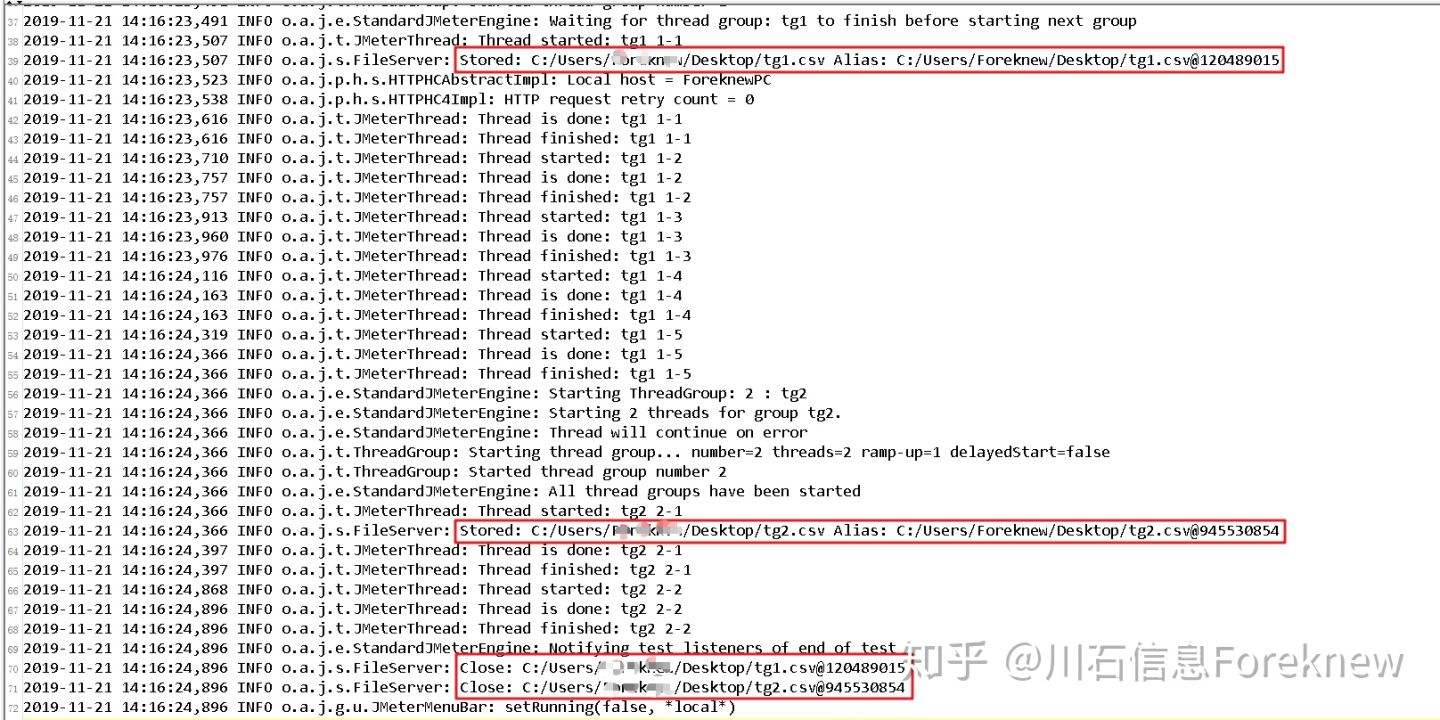
image
2.3 Current thread案例
1)新建5个数据源文件
testdata1.csv,testdata2.csv,testdata3.csv,testdata4.csv,testdata5.csv
设置其值分别设置为:

image
2)配置"Test Plan",勾选"Run Thread Groups consecutively(i.e. one at a time),
保证线程组按顺序依次执行;
3)添加"CSV Data Set Config",其配置下图所示:

image
4)在"Test Plan"下添加线程组"tg1",设置线程数为3;
5)在"tg1"下添加HTTP取样器,HTTP请求中引用参数p,配置如下图所示:
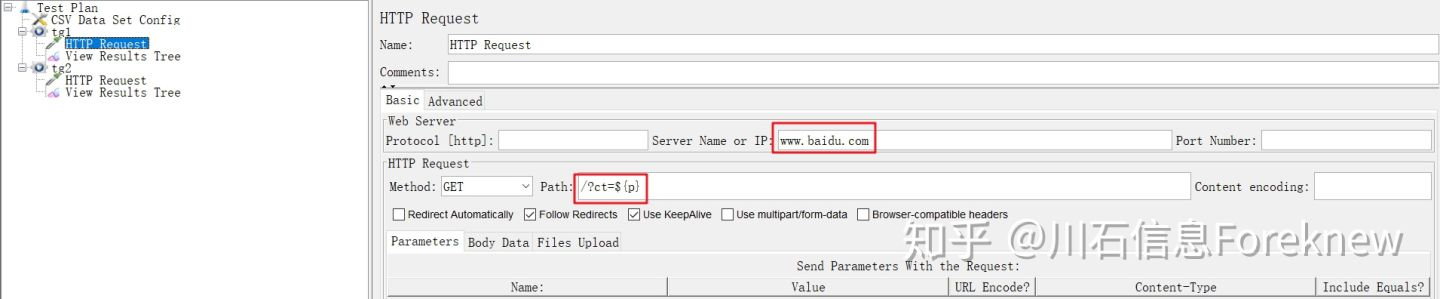
image
6)在"Test Plan"下添加线程组"tg2",设置线程数为2;
7)在"tg2"下添加HTTP取样器,HTTP请求中引用参数p,配置如下图所示:
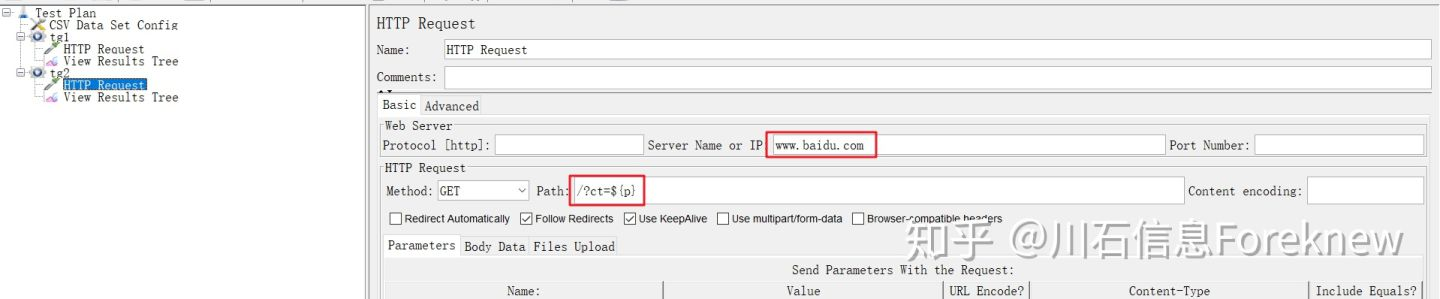
image
8)在"tg1","tg2"下分别添加"View Results Tree".
保存并执行测试,tg1,tg2的查看结果树内容分别如下图所示:
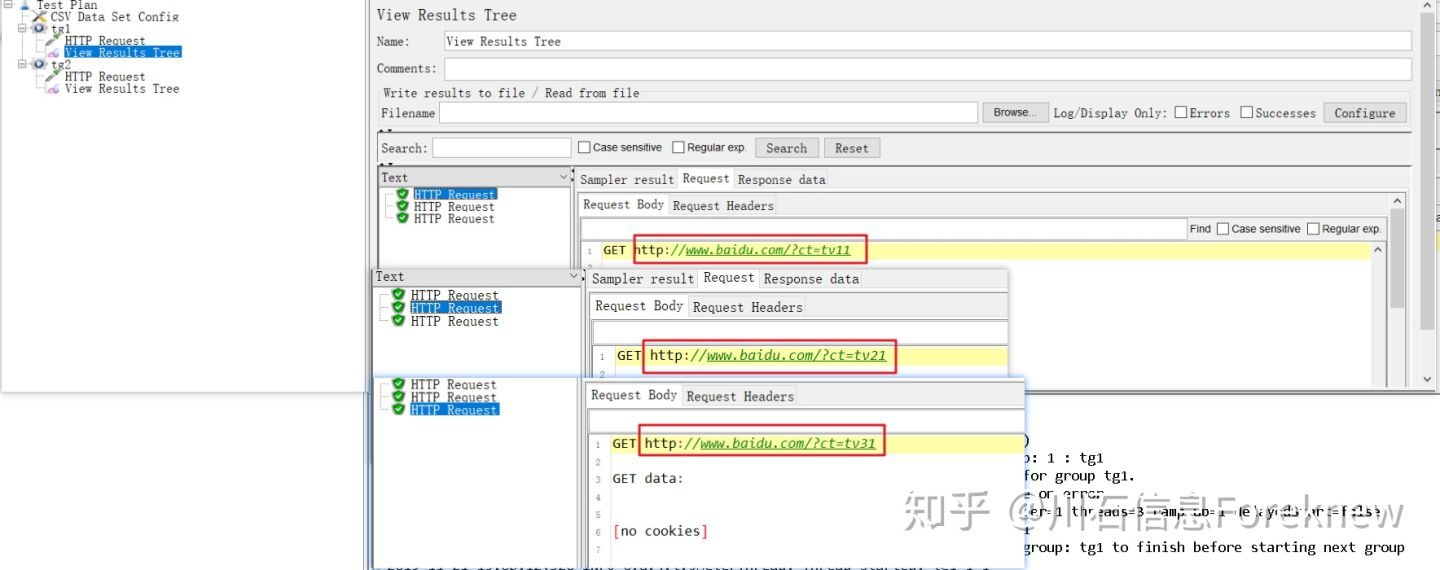
image
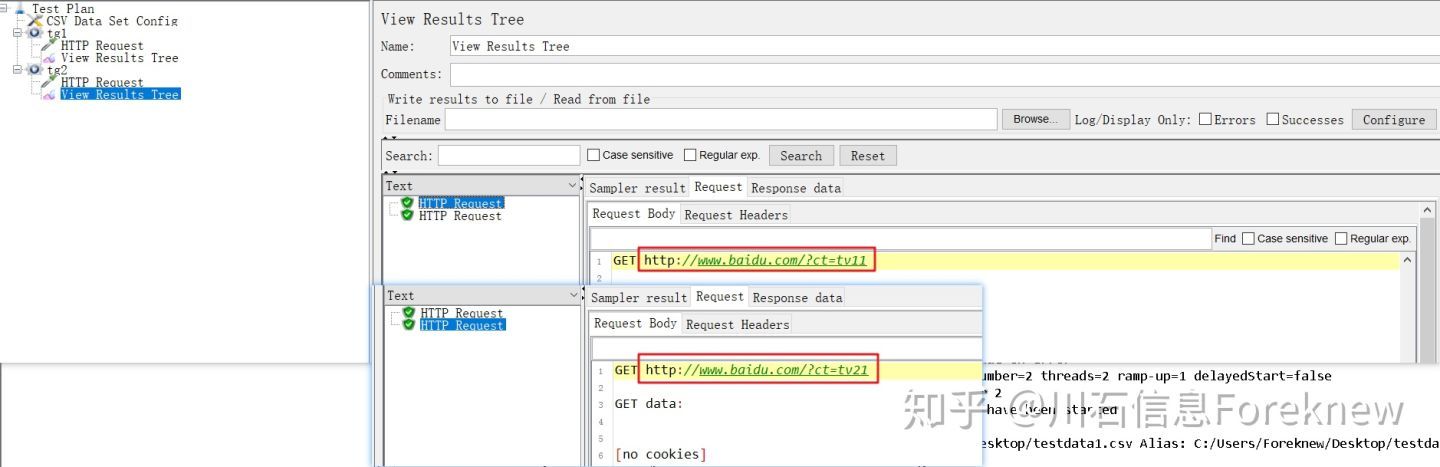
image
从结果可以看出,线程组"tg1"下的3个线程分别获取了获取了
testdata1.csv,testdata2.csv,testdata3.csv三个数据源文件的第二行的值:
tv11,tv21,tv31;
线程组"tg2"下的2个线程分别获取了testdata1.csv,testdata2.csv两个
数据源文件的第二行值:tv11,tv21;
没有获取testdata4.csv,testdata5.csv数据源文件
中的值.因为线程编号是对线程组下的各线程编号的,所以线程组"tg2"
下的线程也是从1开始编号的.
进一步查看jmeter log,可以看出在测试执行过程中每个线程都单独打开了一次数据源文件:
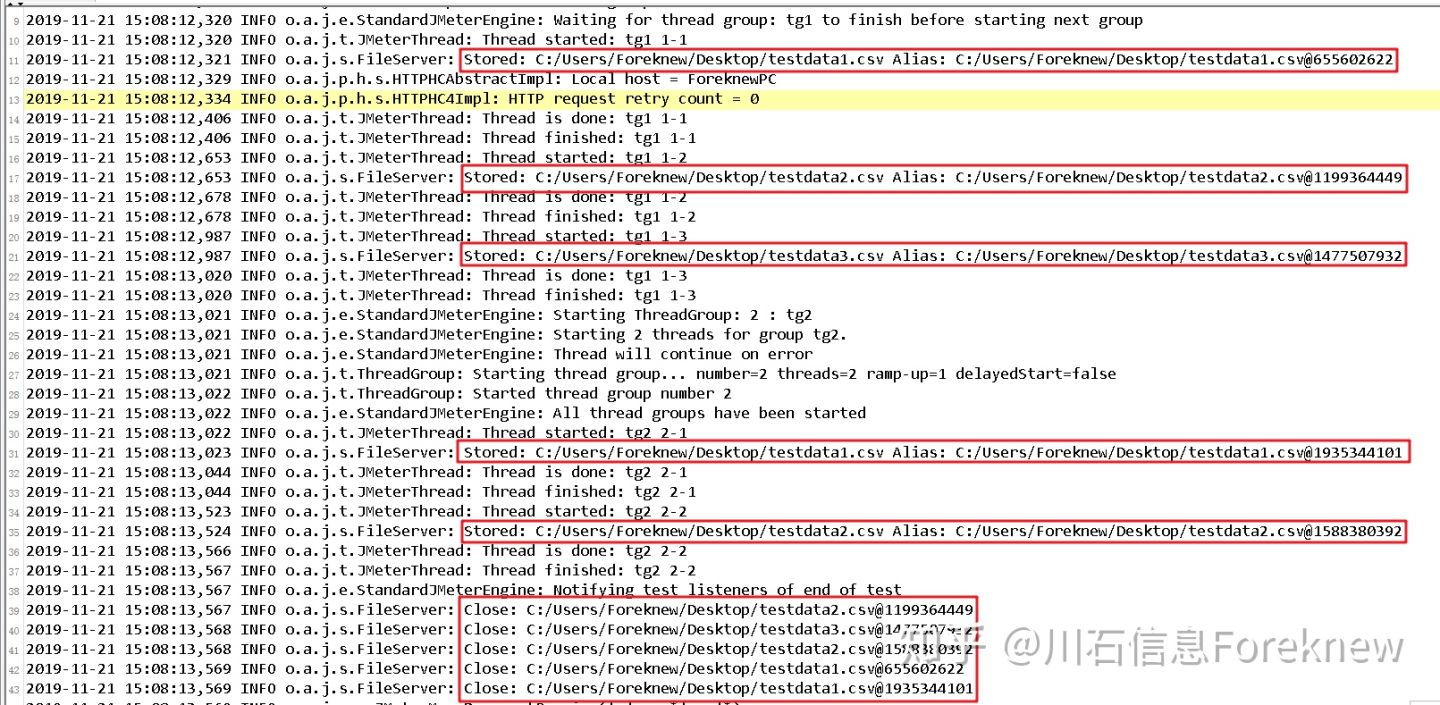
image
















 2230
2230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











