







编码
要点:
1.选择字符集编码的时候,最佳的选择(默认)是utf-8编码
2.编码和解码的字符要保持一致,否则会出现乱码的现象
3.不能使用ISO-8859-1编码保存中文,否则会出现编码黑洞,中文会变成 ’ ?’
4.UTF-8是Unicode的一种实现方案,一种变长的编码,最少1个字节(英文和数字),最多四个四个字节(表情),表示中文用3个字节
例子:
# gbk 一个中文对应两个字节
# utf-8 一个中文占三个字节
content4 = '我爱你中国love'
b = content4.encode('utf-8')
c = b.decode('utf-8')
print(b, c)
content5 = '🌂🍺'
b = content5.encode()
print(b)
print(b.decode())
运行结果:

base64编码
-
base64此编码方式可以让中文字或者图片也能在网路上顺利传输。
在 BASE64 编码后的字串只包含英文字母大小写、阿拉伯数字、加号与反斜线,共 64 个基本字元,不包含其它特殊的字元,因而才取名 BASE64。编码后的字串比原来的字串长度再加 1/3 左右。 -
具体转换步骤
第一步,将待转换的字符串每三个字节分为一组,每个字节占8bit,那么共有24个二进制位。
第二步,将上面的24个二进制位每6个一组,共分为4组。
第三步,在每组前面添加两个0,每组由6个变为8个二进制位,总共32个二进制位,即四个字节。
第四步,根据Base64编码对照表(见下图)获得对应的值。 -
注意事项
- 大多数编码都是由字符串转化成二进制的过程,而Base64的编码则是从二进制转换为字符串。与常规恰恰相反,
- Base64编码主要用在传输、存储、表示二进制领域,不能算得上加密,只是无法直接看到明文。也可以通过打乱Base64编码来进行加密。
- 中文有多种编码(比如:utf-8、gb2312、gbk等),不同编码对应Base64编码结果都不一样。
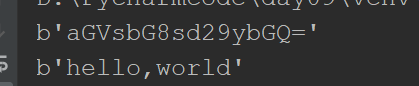
import base64
a = "hello,world"
b = a.encode() # 转换为二进制,默认utf-8
c = base64.b64encode(b) # 转换为base64编码
print(c)
d = base64.b64decode(c) # 转换为二进制
运行结果:














 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









