






ViT模型结构
ViT将输入图片分为多个patch(16×16),再将每个patch投影为固定长度的向量输入到Transformer中,后续的encoder的操作和NLP中的Transformer完全相同。但是因为对图片进行分类,因此在输入序列中加入一个特殊的cls_token,该token对应的输出即为最后的类别预测。(cls_token的作用在于它提供了一个集中的、全局的特征表示,使得模型能够基于整个图像的内容进行分类,而不是仅仅依赖于图像的某个局部区域)
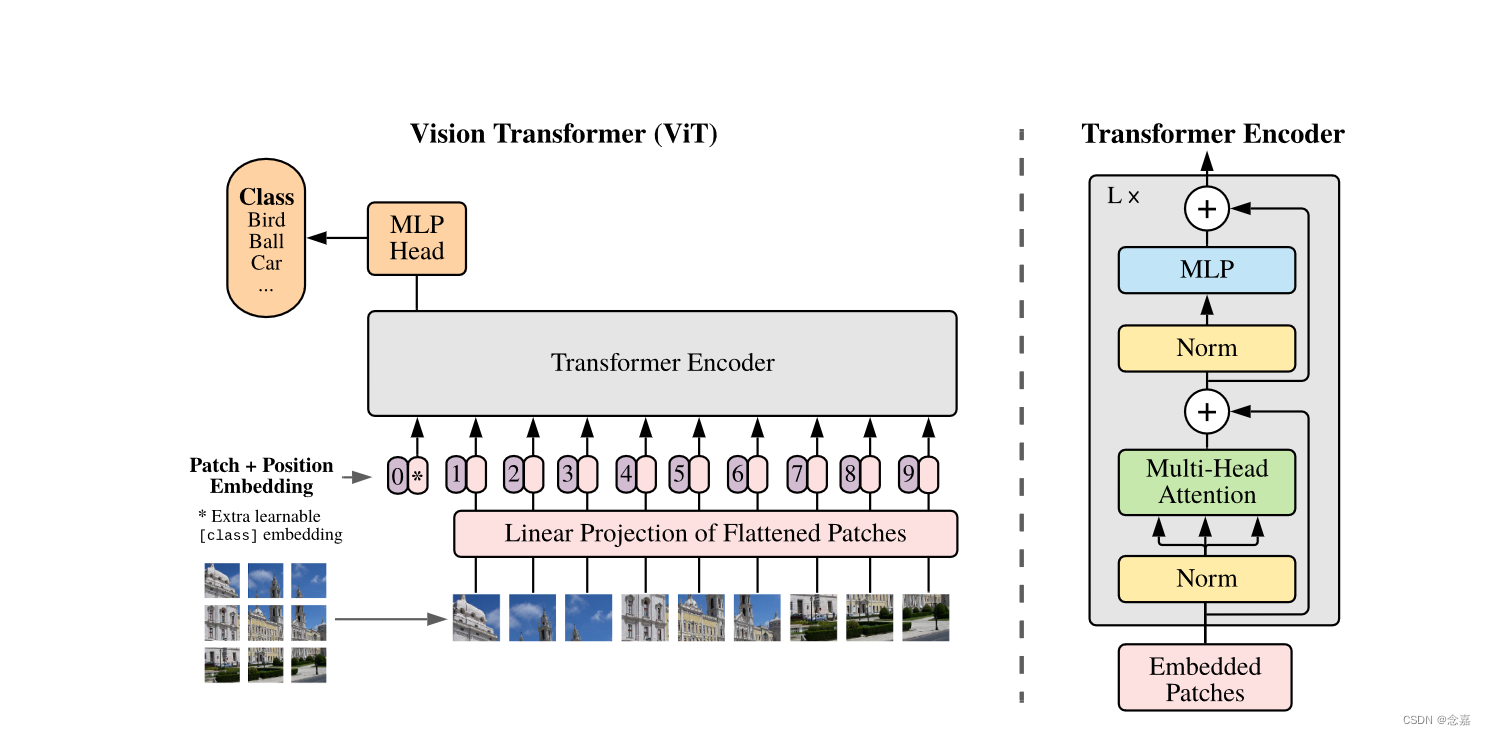
从图中可以看出,ViT模型主要由三部分组成:第一部分为Linear Projection of Flattened Patches,也被成为Embedding层,主要用于将输入的图片数据转换为适合Transformer结构处理的形式。第二部分为Transformer Encoder,它是整个ViT模型的核心部分,它主要由层归一化(Layer Norm)、多头注意力机制(Multi-Head Attention)、Dropout/DropPath、MLP Block四部分组成用于学习输入图像数据的特征。第三部分为MLP Head,它是最终用于分类的层结构。
1、Embedding部分
(1)patch embedding:输入的图片大小为224×224,将图片分为固定大小的patch,patch大小为16×16,则每张图片会生成224×224/16×16=14×14=196个patch,即输入序列长度为196,每个patch维度为16×16×3=768,通过线性投影层之后的维度为196×768(token:[token的数量,token的维度])。这里还需要加上cls_token这个特殊的字符,因此最终的维度是197×768。
(2)position embedding(standard learnable 1D position embeddings):ViT的位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同(197),每一行代表一个向量,向量的维度和输入序列的维度相同(768)。注意:位置编码的操作是sum,而不是concat。加入位置编码之后,维度依然是197×768。
2、Transformer Encoder部分
LN/Multi-Head Attention/LN:LN输出维度依然是197×768。多头注意力时,现将输入映射到q,k,v,如果只有一个头,qkv的维度都是197×768,如果有12个头(768/12=64),则qkv的维度是197×64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197×768,然后在过一层LN,维度依然是197×768。
3、MLP Head部分
将维度放大再缩小回去,197×768放大为197×3072,再缩小变为197×768
一个block之后维度依然和输入相同,都是197×768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出作为encoder的最终输出,代表最终的image presentation(另一种做法是不加cls字符,对所有的tokens的输出做一个平均),如下图公式,后面接一个MLP进行图片分类:
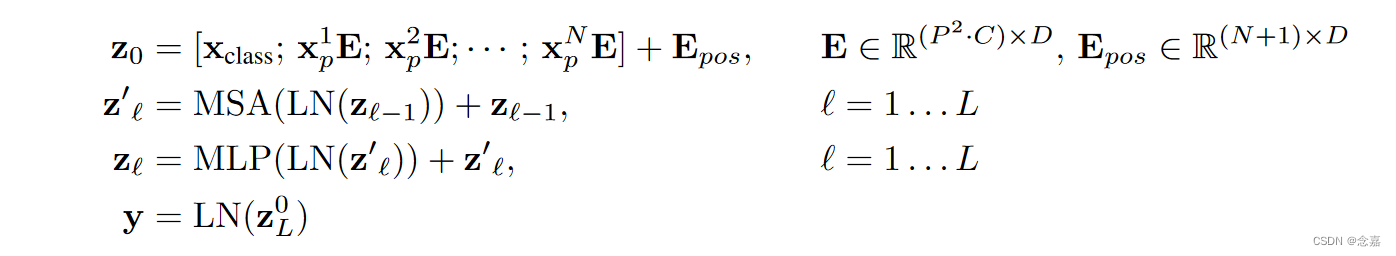
其中输入image ,2D patches
,C是通道数,P是patch大小,一共有N个patches,
。
本篇博客参考:
https://zhuanlan.zhihu.com/p/445122996
Vision Transformer模型架构详解-CSDN博客
关于self-Attention机制的部分可以参考:















 3769
3769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









