第1步:将导出的jar放入到Linux系统合适的位置(这里放在了hadoop下) 第2步:进入到hadoop目录下(例如:cd /usr/local/hadoop-2.8.5) 第3步:执行调用jar的hadoop命令(bin/hadoop jar DailyAccessCount.jar access_login.csv /output) DailyAccessCount.jar: 调用的jar(路径)名称 access.login.csv:输入文件的(路径)名称; /output1:输出的(路径)名称









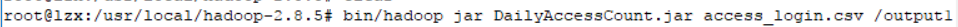















 2617
2617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






