







hadoop伪分布式安装教程
- 第一步:下载hadoop并上传到Linux(ubuntu)
- 第二步:安装hadoop(操作都是在最高权限下执行的)
- 第三步:配置hadoop相关文件
-
- 检查IP-主机映射文件
- 进入hadoop目录(按实际安装路径为准)
- 第四步:配置SSH无密码登录
- 第五步:格式化namenode,并启动进程查看结果
- 第六步:查看50070和8088
- 第七步:关闭进程(养成好习惯)
- 至此,hadoop的下载,安装,和配置就完成了
第一步:下载hadoop并上传到Linux(ubuntu)
Apache官网链接如下:
https://hadoop.apache.org/releases.html
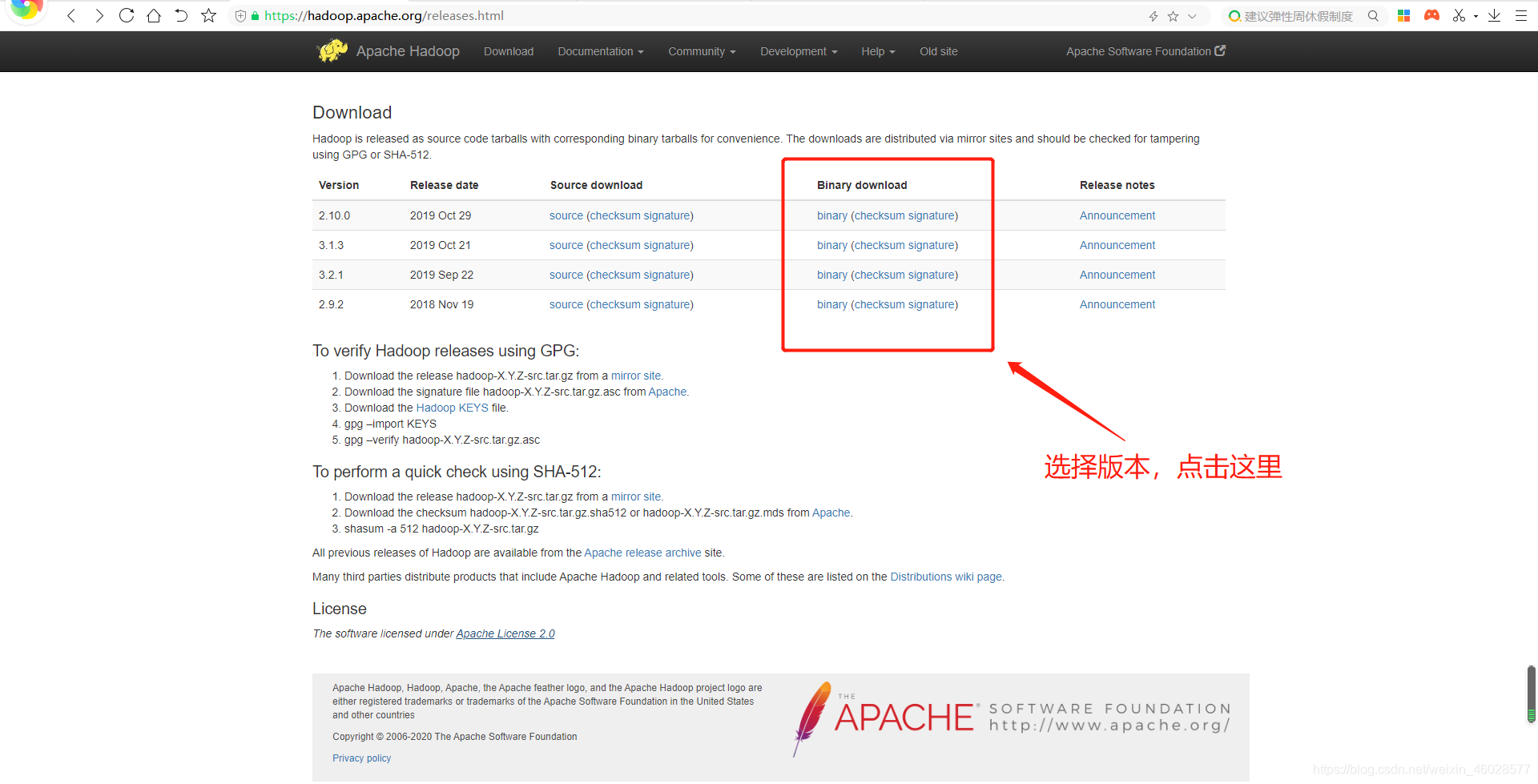
下载好后,使用WinSCP上传到Linux
如对WinSCP有疑问:可点击这里
https://blog.csdn.net/weixin_46028577/article/details/106275272
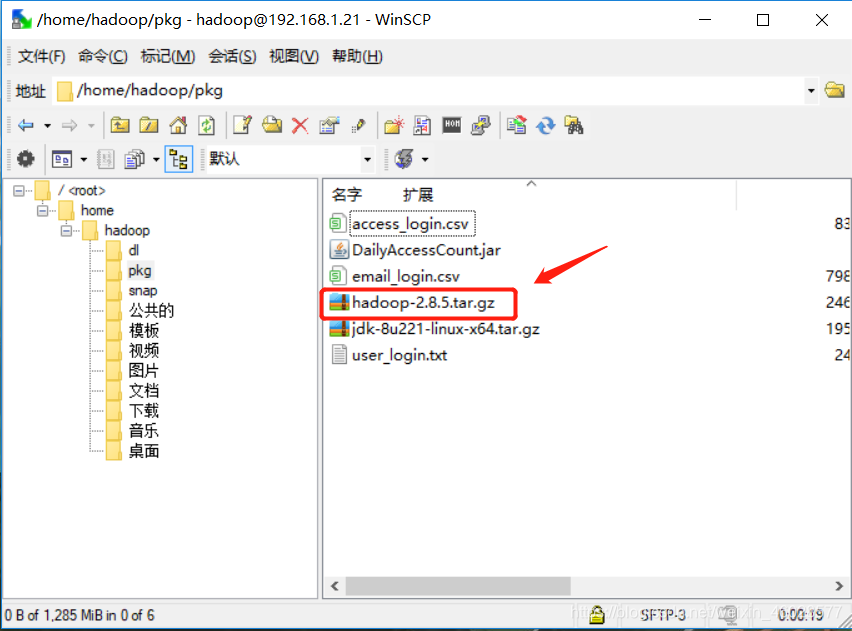
第二步:安装hadoop(操作都是在最高权限下执行的)
命令 :
tar -xzvf /home/hadoop/pkg/hadoop-2.8.5.tar.gz -C /usr/local

第三步:配置hadoop相关文件
检查IP-主机映射文件
vi /etc/hosts

ping 主机名(按Ctrl+C退出)

进入hadoop目录(按实际安装路径为准)
cd /usr/local/hadoop-2.8.5/etc/hadoop/
配置 hadoop-env.sh文件(vi hadoop-env.sh)
export JAVA_HOME=/usr/java/jdk1.8.0_221

若对Linux下安装jdk有疑问,可看如下教程:
https://blog.csdn.net/weixin_46028577/article/details/106268609
配置core-site.xml文件(vi core-site.xml)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://lzx:8020</value>
<description>NameNode与DataNode通讯端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
<description>Hadoop临时目录</description>
</property>
</configuration>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









