









论文 PDF 链接
https://arxiv.org/abs/2406.20083
CoRL 2024 页面链接
Website: https://poliformer.allen.ai

PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
https://www.corl.org/program/awards

文章目录
摘要
Abstract:
We present PoliFormer (Policy Transformer), an RGB-only indoor navigation agent trained end-to-end with reinforcement learning at scale that generalizes to the real-world without adaptation despite being trained purely in simulation.
我们介绍了 PoliFormer (Policy Transformer),一种仅 RGB 的室内导航代理agent,通过大规模的端到端强化学习进行训练,尽管纯粹是在模拟器中训练,但它可以推广到现实世界,而无需适应。
PoliFormer uses a foundational vision transformer encoder with a causal transformer decoder enabling long-term memory and reasoning.
PoliFormer 使用一个基本的视觉 transformer 编码器 和 一个因果 transformer 解码器,实现长期记忆和推理。
It is trained for hundreds of millions of interactions across diverse environments, leveraging parallelized, multi-machine rollouts for efficient training with high throughput.
它在不同的环境中进行了数亿次的交互训练,利用并行的多机器试运行来进行高吞吐量的高效训练。
PoliFormer is a masterful navigator, producing state-of-the-art results across two distinct embodiments, the LoCoBot and Stretch RE-1 robots, and four navigation benchmarks.
PoliFormer 是一个 masterful 导航仪,在两个不同的具身 LoCoBot 和 Stretch RE-1 机器人,以及四个导航基准 中产生最先进的结果。
It breaks through the plateaus of previous work, achieving an unprecedented 85.5% success rate in object goal navigation on the Chores- S \mathbb S S benchmark, a 28.5% absolute improvement.
它突破了以往工作的瓶颈,在 Chores- S \mathbb S S 基准上实现了前所未有的 85.5% 的 object goal navigation 成功率,绝对提升了 28.5%。 〔 成功率 还未达到 实用 级别 !!!有待提升 〕
PoliFormer can also be trivially extended to a variety of downstream applications such as object tracking, multi-object navigation, and open-vocabulary navigation with no finetuning.
PoliFormer 还可以轻松扩展到各种下游应用,如 object tracking、multi-object navigation 和 open-vocabulary navigation,而无需进行微调。
Keywords: Embodied Navigation, On-Policy RL, Transformer Policy
具身导航, 同策略On-Policy RL,Transformer 策略
1 引言
↓ 【 A: 强化学习 探索能力; A + C 存在不足】
Reinforcement Learning (RL) has been used extensively to train embodied robotic agents to complete a variety of indoor navigation tasks.
强化学习(RL)已被广泛用于训练具身机器人代理来完成各种室内导航任务。
Large-scale, on-policy, end-to-end RL training with DD-PPO [1] enables near-perfect PointNav performance when using a shallow GRU-based [2] architecture.
使用 DD-PPO[1] 进行大规模、同策略的端到端 RL 训练,可以在使用基于浅层 GRU 的[2]架构时实现近乎完美的 PointNav 性能。 【 A + C 的优点】
- 脚注 1 Point Goal Navigation is the task of navigating to a goal location using privileged GPS coordinates.
点目标导航是使用 特权privileged GPS 坐标 导航到目标位置的任务。However, this approach fails to result in the same breakthroughs for harder navigation problems like Object Goal Navigation (ObjectNav [3]) where an agent must explore its environment to locate and navigate to an object of the requested type. 【 A + C 的不足】
然而,对于更难的导航问题,如 Object Goal Navigation(ObjectNav[3]),这种方法无法带来同样的突破,其中代理必须探索其环境以定位和导航到请求类型的对象。
RL approaches for ObjectNav have generally not advanced beyond shallow GRU architectures due to challenges presented by training instability and unreasonably long training times with wider and deeper models, such as scaled-up transformers [4].
ObjectNav 的强化学习方法通常没有超越浅层 GRU 架构,这是由于训练不稳定以及使用更广泛和更深的模型(如按比例缩放的 transformers)进行不合理的长时间训练所带来的挑战[4]。
↓ 【B: 基于 transformer 的 SPOC 代理; B + D (模仿学习) 存在不足】
In a departure from on-policy RL, which is sample inefficient and often uses complex reward shaping and auxiliary losses [5], Imitation Learning (IL) has recently shown promise for ObjectNav.
与 同策略的强化学习不同,on-policy RL 是样本效率低下的,经常使用复杂的奖励设计 和 辅助损失[5],模仿学习(IL)最近在 ObjectNav 中显示出了希望。
Ehsani et al. (2023) [6] demonstrated that the transformer-based SPOC agent, when trained to imitate heuristic shortest-path planners, can be trained stably, is sample efficient, and is significantly more effective than prior RL approaches on their benchmark. 【 B + D 的 优点】
Ehsani 等人(2023)[6] 证明,当训练基于 transformer 的 SPOC 代理 模仿 启发式最短路径规划器时,可以稳定地训练,具有样本效率高,并且在其基准上比先前的强化学习方法明显更有效。
SPOC, however, ultimately falls short of mastery, plateauing at a success rate of ~57%. 【 B + D 的 不足 1】
然而,SPOC 最终未能达到精通,成功率稳定在约 57%。
Critically, as we show in our experiments, the performance of SPOC does not seem to improve significantly when further scaling up data and model depth; we suspect this is a consequence of insufficient state-space exploration as expert trajectory datasets frequently contain few examples of error recovery, which can lead to sub-optimal performance due to compounding errors [7] or non-trivial domain shifts during inference. 【 B + D 的 不足 2】
关键的是,正如我们在实验中所显示的,当进一步增加数据和模型深度时,SPOC 的性能似乎没有显著提高;
我们怀疑这是状态空间探索不足的结果,因为专家轨迹数据集经常包含很少的错误恢复示例,这可能导致由于复合误差[7]或推理过程中重要的域移位而导致的次优性能。
↓ 【 取优组合。B + A 】
In contrast to IL, RL requires that agents learn via interactive trial-and-error, allowing for deep exploration of the state space. 【 A 相比于 D 的优点 】
与 模仿学习IL 相比,强化学习RL 要求 agents 通过交互式试错来学习,使得对状态空间进行深度探索。
This exploration has the potential to produce agents that can learn behaviors that are superior to those in the expert demonstrations.
这种探索有可能产生能够学习优于专家演示的行为的代理。
This raises the question: can we bring together the modeling insights from SPOC-like architectures and the exploratory power of RL to train a masterful navigation agent?
这就提出了一个问题:我们能否将类似 SPOC 架构的建模见解和 强化学习RL 的探索能力结合起来,训练出一个 masterful 导航代理? 【 B + D ——> B + A 是否可行】
Unfortunately, this cannot be done naively due to RL’s sample inefficiency and complexities in using deep (transformer) architectures with RL algorithms.
不幸的是,由于 RL 的样本效率低下和在 RL 算法中使用深度(transformer)架构的复杂性,这不能天真地完成。
In this work, we develop an effective method for training large transformer-based architectures with RL,breaking through the plateaus of past work, and achieving SoTA results across four benchmarks.
在这项工作中,我们开发了一种有效的方法来训练基于 RL 的大型 transformer 架构,突破了过去工作的瓶颈,并在四个基准测试中获得了 SoTA 结果。
↓ 【 关键的 3 个 idea】
Our method, PoliFormer, is a transformer-based model trained with on-policy RL in the AI2THOR [8] simulator at scale, that can effectively navigate in the real world without any adaptation.
我们的方法 PoliFormer 是一种基于 transformer 的模型,在 AI2THOR[8] 模拟器中进行了大规模的同策略强化学习训练,可以在没有任何适应的情况下有效地在现实世界中导航。
We highlight three primary design decisions that make this result possible.
我们强调使这一结果成为可能的三个主要设计决策。
(i) Scale in Architecture: Building on the SPOC architecture, we develop a fully transformer-based policy model that uses a powerful visual foundation model (DINOv2 [9], a vision transformer), incorporates a transformer state encoder for improved state summarization, and employs a transformer decoder for explicit temporal memory modeling (Fig. 1, top-right).
架构上进行扩展:基于 SPOC 架构,我们开发了一个完全基于 transformer 的策略模型,该模型使用强大的 视觉基础模型(DINOv2[9],一个视觉 transformer),结合了一个 transformer 状态编码器来改进状态汇总,并使用一个 transformer 解码器来进行显式的时序记忆建模(图 1,右上)。
Importantly, our transformer decoder is causal and uses a KV-cache [10], which allows us to avoid huge computational costs during rollout collection and makes RL training affordable.
重要的是,我们的 transformer 解码器是因果的,并使用 KV-cache[10],这使我们能够避免在试运行收集期间的巨大计算成本,并使强化学习训练负担得起。
(ii) Scale in Rollouts: We leverage hundreds of parallel rollouts and large batch sizes, which leads to high training throughput and allows us to train using a huge number of environment interactions (Fig. 1, top-middle).
试运行Rollouts 上进行扩展:我们利用数百个并行试运行 和 大的 batch sizes,这导致了高训练吞吐量,使得我们能使用大量的环境交互进行训练(图 1,中上)。
(iii) Scale in Diverse Environment Interactions: Training PoliFormer with RL at scale in 150k procedurally generated ProcTHOR houses [11] using optimized Objaverse [12, 13, 14] assets results in steady validation set gains (Fig. 1, top-left).
在环境交互的差异性 上进行扩展:使用优化好的 Objaverse[12,13,14] 资源,在150k 个程序生成的 ProcTHOR 房屋[11]中大规模地训练 PoliFormer 和 RL,可以获得稳定的验证集增益(图1,左上角)。
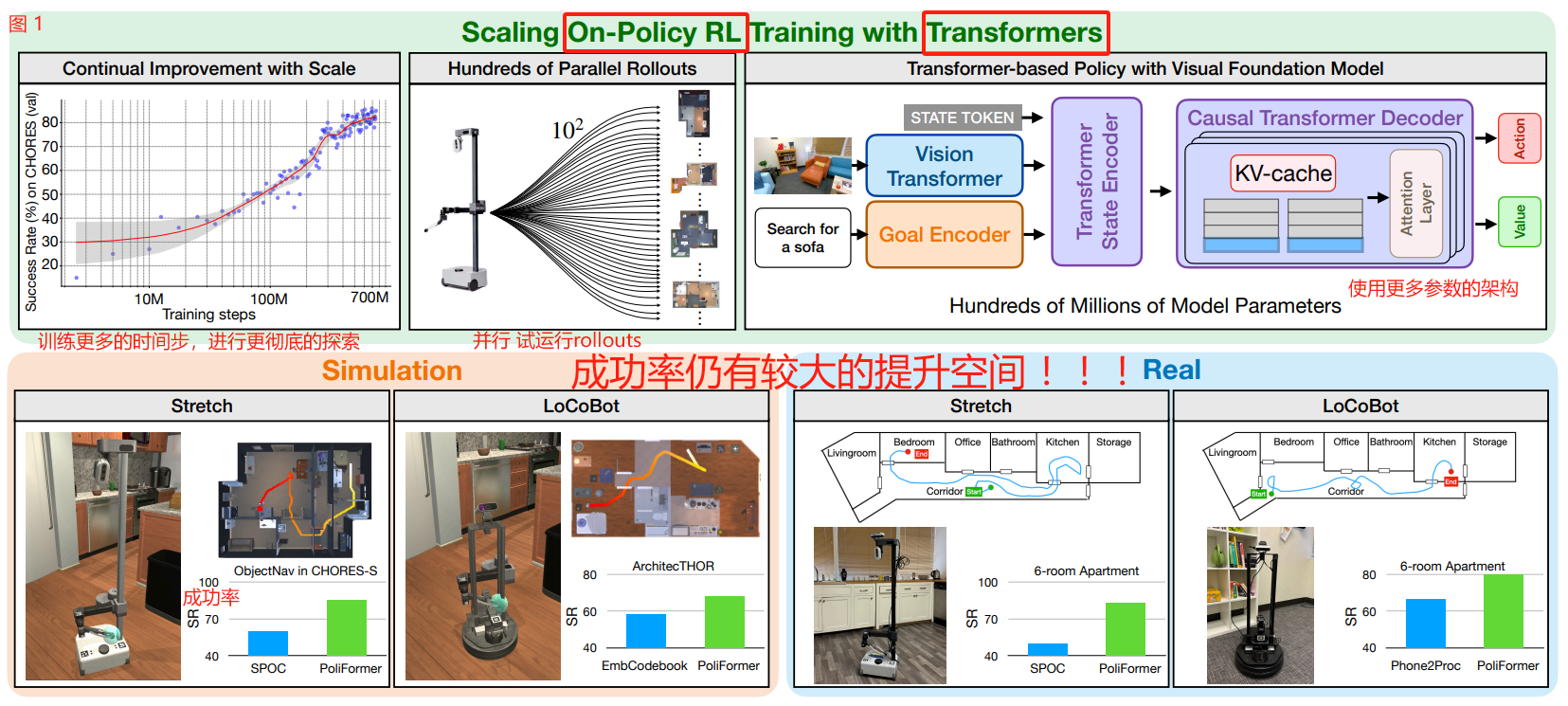
Figure 1: PoliFormer, a transformer-based policy trained using RL at scale in simulation,achieves significant performance improvements in simulation (bottom-left) and the real world(bottom-right), across two embodiments.
图 1: PoliFormer ,一个基于 transformer 的策略,在模拟器中使用 RL 进行大规模训练,在模拟器(左下)和 现实世界(右下)中实现了显著的性能改进,跨越两个具身实例。
SR denotes Success Rate. We scale on-policy RL training across multiple dimensions: (top-left) we observe continual performance improvement with scaling RL training; (top-middle) we leverage hundreds of parallel rollouts for higher throughput; (top-right)we develop a transformer-based policy scaling model parameters to hundreds of millions.
SR 表示成功率。我们在多个维度上扩展 on-policy RL 训练:(左上)我们观察到通过扩展强化学习训练的持续性能改进;(中上)我们利用数百个并行 rollouts 来提高吞吐量;(右上)我们开发了一个基于 transformer 的策略 scaling 模型参数到数亿。
↓ 【 PoliFormer 的评估结果: SOTA】
PoliFormer achieves excellent results across multiple navigation benchmarks in simulation.
PoliFormer 在模拟器中的多个导航基准测试中取得了优异的成绩。
On Chores- S \mathbb S S, it achieves an impressive 85.5% Success Rate, a higher than +28.5% absolute improvement over the previous SoTA model [6].
在 Chores- S \mathbb S S 上,它取得了令人印象深刻的 85.5% 的成功率,比之前的 SoTA 模型提高了 28.5%[6]。
Similarly, it also obtains SoTA Success Rates on ProcTHOR (+8.7%), ArchitecTHOR (+10.0%) and AI2-iTHOR (+6.9%).
同样,它也获得了 ProcTHOR (+8.7%), ArchitecTHOR (+10.0%)和 AI2-iTHOR(+6.9%)的 SoTA 成功率。
These results hold across two embodiments, LoCoBot [15] and Stretch RE-1 [16], with distinct action spaces (Fig. 1, bottomleft).
这些结果适用于两个具身,LoCoBot[15] 和 Stretch RE-1[16],它们具有不同的动作空间(图 1,左下角)。
In the real world (Fig. 1, bottom-right), it outperforms ObjectNav baselines in the sim-to-real zero-shot transfer setting using LoCoBot (+13.3%) and Stretch RE-1 (+33.3%).2
在现实世界中(图 1,右下),它在使用 LoCoBot(+13.3%)和 Stretch RE-1(+33.3%)的 sim-to-real zero-shot 迁移设置中优于 ObjectNav 基线。
- 脚注 2 PoliFormer even outperforms Phone2Proc [17], a baseline finetuned in 3D-reconstructed test scenes.
PoliFormer 甚至优于 Phone2Proc[17],后者是在 3D 重建的测试场景中微调的基线。
↓ 【 通用导航器:PoliFormer-BoxNav】
We further train PoliFormer-BoxNav that accepts a bounding box (e.g., from an off-the-shelf open-vocab object detector [18, 19] or VLMs [20, 21]) as its goal specification in place of a given category.
我们进一步训练 PoliFormer-BoxNav,它接受一个边界框(例如,来自一个现成的 open-vocab object 检测器[18,19] 或 VLMs[20,21])作为它的目标规范来代替给定的类别。
This abstraction makes PoliFormer-BoxNav a general purpose navigator that can be “prompted” by an external model akin to the design of Segment Anything [22].
这种抽象使 PoliFormer-BoxNav 成为一种通用的导航器,可以由类似于 Segment Anything 的设计的外部模型“提示”[22]。
It is extremely effective at exploring its environment and, once it observes a bounding box, beelines towards it.
它在探索环境方面非常有效,一旦它观察到一个边界框,就会径直朝它走去。
PoliFormer-BoxNav is a leap towards training a foundation model for navigation; with no further training, this general navigator can be used in the real world for multiple downstream tasks such as open vocabulary ObjectNav, multi-target ObjectNav, human following, and object tracking.
PoliFormer-BoxNav 是训练导航基础模型的一个飞跃;无需进一步训练,这个通用导航器可以在现实世界中用于多个下游任务,如开放词汇表 ObjectNav、多目标 ObjectNav、human following 和 object tracking。
↓ 【 3 点贡献: 策略 + 训练方式 + 通用导航器】
In summary, our contributions include:
总之,我们的贡献包括:
(i) PoliFormer , a transformer-based policy trained by RL at scale in simulation that achieves SoTA results over four benchmarks in simulation and in the real world across two different embodiments.
PoliFormer 是一种基于 transformer 的策略,通过 RL在模拟器中进行大规模训练,在模拟器和现实世界中跨两个不同具身实例的四个基准中达到 SoTA 结果。
(ii) A training recipe that enables effective end-to-end policy learning with large-scale neural models via on-policy RL.
一个训练配方,通过同策略强化学习实现大规模神经模型的有效端到端策略学习。
(iii) A general purpose navigator, PoliFormer -BoxNav, that can be used zero-shot for multiple downstream navigation tasks.
通用导航器 PoliFormer-BoxNav,可 zero-shot 用于多个下游导航任务。
2 相关研究
关于 具身导航 的 IL 和 RL

↓ 【 总结式阐述,引用在相应类别中】
IL and RL on Embodied Navigation.
Recent advancements include Point Goal Navigation [1],Object Goal Navigation [3, 23, 24, 25], Exploration [26, 27, 28], and Social Navigation [29], as well as successful sim-to-real transfer [6] and high performance in various downstream applications [16, 30, 31, 32, 33, 34, 35].
最近的进展包括 Point Goal Navigation、Object Goal Navigation、探索 和 Social Navigation ,以及成功的 sim-to-real 迁移 和 在各种下游应用中的高性能。
The prevalent approaches to building capable navigation agents include both end-to-end training [1, 6] and modular methods that leverage mapping [36, 37, 38] or off-the-shelf foundation models [39, 40, 41, 42, 43].
构建能干的导航代理的普遍方法包括 端到端训练 和 利用 mapping 或 现成基础模型 的模块化方法。
In these frameworks, the policy models are typically optimized via Imitation Learning (IL) using expert trajectories [44, 45, 46, 47, 48, 49, 50] or Reinforcement Learning (RL) within interactive environments [29, 51, 52, 53, 54, 55, 56, 57, 58, 59] and with carefully tuned reward shaping and auxiliary losses [5, 60, 61, 62, 63].
在这些框架中,策略模型通常通过 使用专家轨迹的模仿学习(IL)或 在交互环境中使用强化学习(RL)进行优化,并精心调整 奖励设计 和 辅助损失。
具身代理的基于 Transformer 的策略
↓ 【总述本段打算讲的内容 ( 使用基于 transformer 的架构作为具身代理 的研究现状) +
3 个 相关研究(方法 i + 关键 idea + 亮点贡献) + 本工作的处理方法】
Transformer-based Policies for Embodied Agents.
Recent works use transformer-based architectures for embodied agents.
最近的研究使用基于 transformer 的架构作为具身代理。
Decision Transformer (DT [64]) learns a policy offline, conditioning on previous states, actions, and future returns, providing a path for using transformers as sequential decision-making models.
Decision Transformer (DT [64]) 离线学习策略,基于先前的状态、动作和未来回报,为使用 transformers 作为序列决策模型提供了途径。
ODT [65] builds on DT and proposes to blend offline pretraining and online finetuning, showing competitive results in D4RL [66].
ODT[65] 基于 DT,提出混合离线预训练和 在线微调,在 D4RL 中显示出有竞争力的结果[66]。
More recently, MADT [67] shows few-shot online RL finetuning on the offline trained DT in multi-agent game environments.
最近,MADT[67] 显示了在 multi-agent 游戏环境中对离线训练好的 DT 进行 few-shot 在线 RL 微调。
The Skill Transformer [68] learns a policy via IL for mobile manipulation tasks.
Skill Transformer [68] 通过 IL 学习移动操作任务的策略。
While the focus of these works is control towards specific tasks (relying on IL pre-training), we train from scratch using pure RL targeting a navigation policy that can be used zero-shot for many downstream tasks.
虽然这些研究的重点是对特定任务的控制(依赖于 IL 预训练),但我们使用纯 RL 从头开始训练,目标是可以对许多下游任务使用 zero-shot 的导航策略。
↓ 【 总述本段打算讲的内容 (在提高 transformer 策略的规模和训练稳定性 方面的已有尝试/研究现状) +
7 个 相关研究(方法 i + 关键 idea) + 不足 + 本工作的处理方法】
There has been a huge effort on improving the scale and training stability of transformer policies.
在提高 transformer 策略的规模和训练稳定性方面已经做出了巨大的努力。
GTrXL [69] proposes to augment causal transformer policies with gating layers towards stable RL training in [70].
GTrXL[69] 提出在 [70] 中增加带有门控层的因果 transformer 策略,以实现稳定的强化学习训练。
PDiT [71] proposes to interleave perception and decision transformer-based blocks showing its effectiveness in fully-observed environments.
PDiT[71] 提出将基于 感知和决策 transformer 的块交织在一起,显示其在完全观察环境中的有效性。
GATO [72] learns a large-scale transformer-based policy on a diverse set of tasks, including locomotion and manipulation.
GATO[72] 在多种任务(包括运动和操作)上学习基于大型 transformer 的策略。
Performer-MPC [73] proposes learnable Model Predictive Control policies with low-rank attention transformers (Performer [74]) as learnable cost functions.
Performer-MPC [73] 提出了可学习的 Model Predictive Control 策略,该策略使用低阶注意力 transformers(Performer[74])作为可学习的 cost 函数。
SLAP [75] learns a policy for mobile manipulation based on a hybrid design.
SLAP[75] 学习了一种基于混合设计的移动操作策略。
Radosavovic et al. [76] learn a causal transformer using RL and IL for real-world humanoid locomotion.
Radosavovic 等人[76] 使用 RL 和 IL 学习真实世界 humanoid 运动的因果 transformer。
However, their input is proprioceptive state, without visual observations, and their learned policy is intended to be stationary (walking steadily in the real-world).
然而,他们的输入是本体感知状态,没有视觉观察,他们习得的策略是静止的(在现实世界中稳步行走)。
NavFormer [77] learns image-goal conditioned transformer policies using offline-RL for target navigation.
NavFormer[77] 使用离线 RL 学习图像目标条件 transformer 策略进行目标导航。
In contrast to existing approaches, we achieve efficient large-scale transformer based on-policy RL training for a partially-observed, long-horizon, navigation task using RGB sensor inputs and show that our policy can be seamlessly deployed in the real world.
与现有方法相比,我们使用 RGB 传感器输入,对可部分观察的、长视界的导航任务实现了高效的大规模基于 transformer 的同策略on-policy 强化学习训练,并证实我们的策略可以无缝地部署在现实世界中。
We accomplish this without complex inductive biases or multi-task dataset aggregation due to the sheer amount of procedural scene layouts and visual variety of objects in simulation.
我们在没有复杂的归纳偏差或多任务数据集聚合的情况下完成了这一点,因为模拟器中有大量的程序场景布局和 objects 的视觉多样性。
迈向导航基础模型
↓ 【 总述本段打算讲的内容 +
3 个 相关研究(方法 i + 关键 idea + 亮点优势) + 本工作的处理方法】
Toward Navigation Foundation Models.
Many recent works attempt to produce general-purpose “foundational” navigation models.
最近的许多研究都试图产生通用的“基础”导航模型。
The causal transformer for humanoid outdoor locomotion [76], relying on proprioceptive state, shows emergent behaviors like arm swinging and in-context adaptation.
humanoid 户外运动的因果 transformer [76] 依靠本体感知状态,表现出手臂摆动和情境适应等紧急行为。
GNM [78] trainsimage goal-conditioned policies (i.e., conditioning on an image at the desired goal location) by IL across various embodiments, which allows them to scale up the size of their training data and manages to generalize to controlling unseen embodiments.
GNM[78] 通过跨各种具身实例的 IL 训练图像目标条件策略(即,在期望的目标位置对图像进行条件调节),这使它们能够扩大训练数据的大小,并设法推广到控制没见过的具身实例。
NOMAD [79], which extends ViNT [80] uses a diffusion policy and also uses image goal conditioning.
NOMAD[79] 扩展了 ViNT[80],它使用了扩散策略,也使用了图像目标调节。
Unlike these works, we navigate from rich RGB image inputs and specify goals with natural-language text (or with bounding boxes), as such goals are far more easily available in real-world settings.
与这些研究不同,我们从丰富的 RGB 图像输入中导航,并使用具有自然语言文本(或 具有边界框)的指定目标,因为这样的目标在现实环境中更容易获得。
3 方法
RL, while effective and intuitive for training policies, has not yet been scaled in embodied AI to the same degree as in other domains.
强化学习虽然在训练策略方面是有效且直观的,但在具身 AI 还没有达到与其他领域相同的程度。
RL has primarily been applied to short-horizon tasks [81, 82], smaller environments [83, 84], or tasks utilizing privileged knowledge [1].
强化学习主要应用于短视界任务[81,82]、较小的环境[83,84]或利用 privileged 知识的任务[1]。
We scale learning in three directions;
我们将学习分为三个方向;
(i) Network Capacity, via PoliFormer’s deep, high-capacity, model architecture (Sec. 3.1);
网络容量,通过 PoliFormer 的深度,高容量,模型架构(第 3.1 节);
(ii) Parallelism and Batch size via our highly-parallelized training methodology that leverages large batch sizes for efficiency (Sec. 3.2), and
通过我们的高度并行化训练方法,利用大 batch sizes 来提高效率(第 3.2 节),实现并行性和 Batch size;
(iii) Training Environments via our optimization of the simulation environment to support high-speed training (Sec. 3.3).
训练环境通过我们的模拟环境优化,以支持高速训练(第 3.3 节)。
3.1 PoliFormer 的架构
We now detail PoliFormer’s transformer architecture (see Fig. 2), which is inspired by SPOC [6].
我们现在详细介绍 PoliFormer 的 transformer 架构(见图 2),其灵感来自 SPOC[6]。
While we make several subtle, but important, changes to the SPOC architecture (detailed below), our largPoliFormerest architectural difference is in the transformer decoder: we replace the standard transformer decoder block [4, 85] with the implementation used in the Llama 2 LLM [86].
虽然我们对 SPOC 架构进行了一些不易察觉但重要的更改(详见下文),但我们最大的架构差异在于 transformer 解码器:我们用 Llama 2 LLM[86] 中使用的实现取代了标准的 transformer 解码器块[4,85]。
This change has dramatic implications for training and inference speed.
这一变化对训练和推理速度有着巨大的影响。
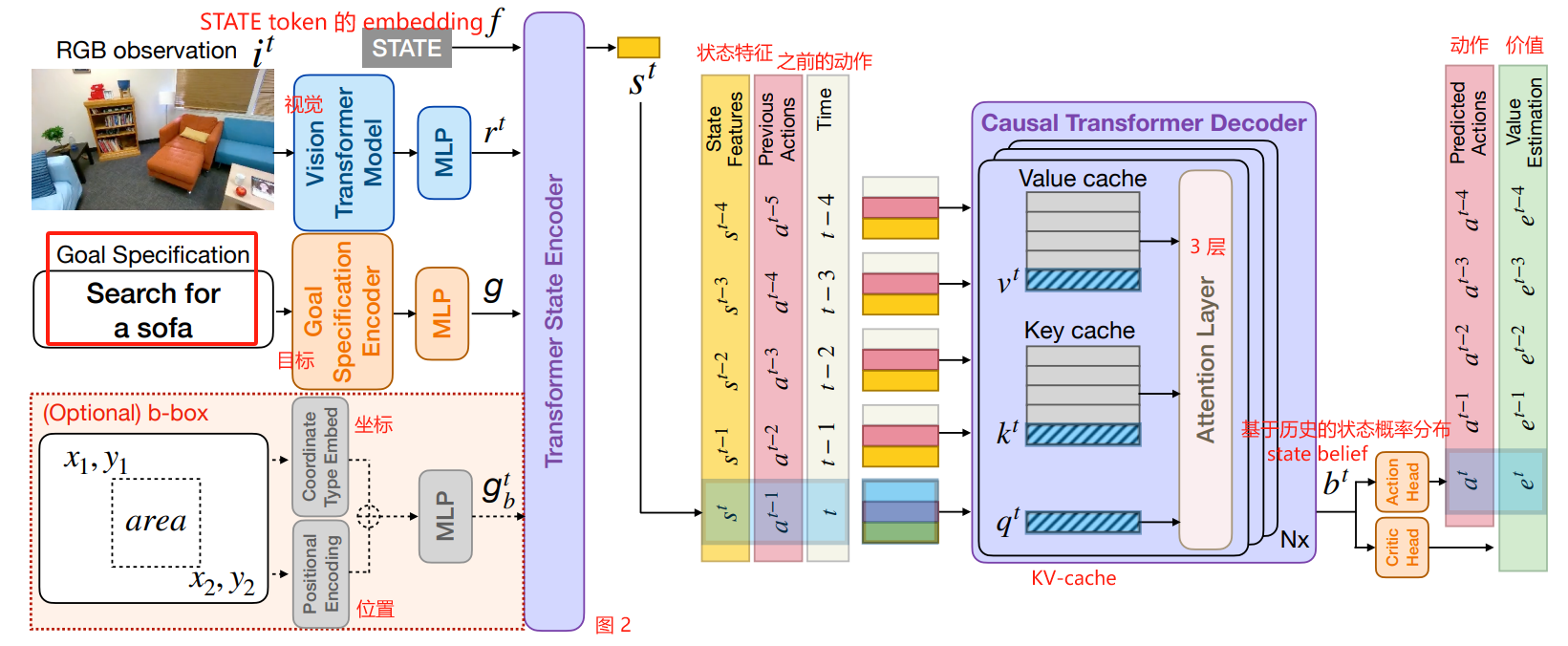
图 2: PoliFormer 是一个完全基于 transformer 的策略模型。
在每个时间步 t t t,它采用 ego-centric RGB 观察 i t i^t it,
使用视觉 transformer 模型提取视觉表征 r t r^t rt,
使用视觉表征和目标特征 g g g(以及可选检测到的边界 box 目标特征 g b t g_b^t gbt)进一步编码状态特征 s t s^t st,
使用因果 transformer 解码器随时间建模状态 belief b t b^t bt,
最后,分别通过线性 actor 和 critic 头部预测动作逻辑 a t a^t at 和 价值估计 e t e^t et。
对于 rollout 收集和推理,我们利用 KV-cache[10] 作为时序缓存策略,以防止在每个新的时间步重新计算所有先前时间步的正向传递,从而节省内存并加速训练和推理。
在每个时间步 t t t, PoliFormer 将 一个 ego-centric RGB 观察 i t i^t it 作为输入,并采用冻结视觉 transformer 模型来提取视觉表示 r t r^t rt。
该表示以及目标的 embedding g g g 由 transformer 状态编码器总结以产生状态表示 s t s^t st。
因果 transformer 解码器然后编码 状态特征 s t s^t st (以及 s 0 , ⋯ , s t − 1 s^0,\cdots,s^{t-1} s0,⋯,st−1 ) 得到 belief b t b^t bt
最后,线性 actor 和 critic 头部分别投影 b t b^t bt 来预测动作逻辑 a t a^t at 和 价值估计 e t e^t et。
视觉 Transformer 模型 Vision Transformer Model.
Vision Transformer Model.
Inspired by prior work [6, 87], we choose DINOv2 [9] as our visual foundation backbone, because of its remarkable dense prediction and sim-to-real transfer abilities.
受先前研究[6,87]的启发,我们选择 DINOv2[9] 作为我们的视觉基础 backbone,因为它具有出色的密集预测和 sim-to-real 迁移能力。
The visual backbone takes an ego-centric RGB observation i ∈ R H × W × 3 i \in {\mathbb R}^{H×W×3} i∈RH×W×3 as input and produces a patch-wise representation r ∈ R H 14 × W 14 × h r \in {\mathbb R}^{\frac{H}{14}\times\frac{W}{14}\times h} r∈R14H×14W×h, where H H H and W W W are the observation height and width, and h h h is the hidden dimension of the visual representation.
视觉 backbone 以一个 ego-centric RGB 观测 i ∈ R H × W × 3 i \in {\mathbb R}^{H×W×3} i∈RH×W×3 作为输入,并产生一个 patch-wise 表示 R ∈ R H 14 × W 14 × H R \in {\mathbb R}^{\frac{H}{14}\times\frac{W}{14}\times H} R∈R14H×14W×H,其中 H H H 和 W W W 是观测的高度和宽度, h h h 是视觉表示的隐藏维度。
We reshape the visual representation into a ℓ × h \ell \times h ℓ×h matrix, ℓ = H ⋅ W / 196 \ell = H · W/196 ℓ=H⋅W/196, and project the representation to produce v ∈ R ℓ × d v \in {\mathbb R}^{\ell \times d} v∈Rℓ×d, where d d d is the input dimension to the transformer state encoder.
我们将视觉表示 改成 ℓ × h \ell \times h ℓ×h 矩阵, ℓ = h ⋅ W / 196 \ell = h·W/196 ℓ=h⋅W/196,并投影表示得到 v ∈ R ℓ × d v \in {\mathbb R}^{\ell \times d} v∈Rℓ×d,其中 d d d 是 transformer 状态编码器的输入维数。
For effective sim-to-real transfer, it is important to keep the vision transformer model frozen when training in simulation.
为了实现有效的 sim-to-real 迁移,当在模拟器中训练时保持视觉 transformer 模型的冻结 是非常重要的。
目标编码器Goal Encoder.
Goal Encoder.
For fair comparison, when training agents on ObjectNav benchmarks using the LoCoBot, we follow EmbCLIP [39] and use a one-hot embedding layer to encode the target object category.
为了公平比较,当使用 LoCoBot 在 ObjectNav 基准上训练代理时,我们遵循 EmbCLIP[39],并 使用独热 embedding 层对目标 object 类别进行编码 。
On benchmarks using the Stretch RE-1 robot, we follow SPOC [6] and use a FLAN-T5 small [88, 89] model to encode the given natural language goal and use the last hidden state from the T5 model as the goal embedding.
在使用 Stretch RE-1 机器人的基准测试中,我们遵循 SPOC[6],并使用 FLAN-T5 小型[88,89]模型对给定的自然语言目标进行编码,并使用 T5 模型的最后一个隐藏状态作为目标 embedding。
Before passing the goal embedding to the transformer state encoder, we always project the embedding to the desired dimension d d d, resulting in g ∈ R 1 × d g \in {\mathbb R}^{1\times d} g∈R1×d
在将目标 embedding 传递给 transformer 状态编码器之前,我们总是将 embedding 投影到所需的维度 d d d,从而得到 g ∈ R 1 × d g \in {\mathbb R}^{1\times d} g∈R1×d

In select experiments (detailed in Sec. 4), we specify the goal object via a bounding box (b-box), either in addition to or as an alternative to text.
在选择实验中(详见第 4 节),我们通过边界框(b-box)指定目标物体,可以作为文本的补充,也可以作为文本的替代。
In this case, the goal encoder processes the b-box using both the sinusoidal positional encoding and the coordinate-type embeddings to embed the top-left, bottom-right b-box coordinates and its area (5 values in total), followed by an MLP to project the hidden feature to the desired dimension d d d, resulting in g b ∈ R 5 × d g_b \in {\mathbb R}^{5\times d} gb∈R5×d
在这种情况下,目标编码器使用正弦位置编码和坐标类型 embeddings 来处理 b-box,以 embed 左上,右下 的 b-box 坐标及其面积(总共 5 个值),然后使用 MLP 将隐藏特征投影到所需维度 d d d,从而得到 g b ∈ R 5 × d g_b \in {\mathbb R}^{5\times d} gb∈R5×d
Transformer State Encoder
Transformer State Encoder.
This module summarizes the state at each timestep as a vector s ∈ R d s \in {\mathbb R}^d s∈Rd.
这个模块将每个时间步的状态总结为一个向量 s ∈ R d s \in {\mathbb R}^d s∈Rd。
The input to this encoder includes the visual representation v v v, the goal feature g g g (and/or g b g_b gb), and an embedding f f f of a STATE token.
该编码器的输入包括视觉的表示 v v v,目标特征 g g g(和/或 g b g_b gb),以及 STATE token 的 embedding f f f。 〔 状态 最小语义单元 的 向量化表示 f f f〕
We concatenate these features together and feed them to a non-causal transformer encoder. 〔 non-causal transformer 和 causal transformer 有什么区别?〕 ——> 是否使用将来的数据,causal transformer 不接收未来的信息
我们将这些特征连接在一起,并将它们提供给非因果 transformer 编码器。
This encoder then returns the output corresponding to the STATE token as the state feature vector.
然后,该编码器返回与 STATE token 相应的输出作为状态特征向量。
Since the transformer state encoder digests both visual and goal features, the produced state feature vector can also be seen as a goal-conditioned visual state representation.
由于 transformer 状态编码器 提取 视觉和目标特征,因此产生的状态特征向量也可以被视为目标条件的视觉状态表示。


Causal Transformer Decoder
Causal Transformer Decoder.
We use a causal transformer decoder to perform explicit memory modeling over time.
我们使用因果 transformer 解码器随时间执行显式记忆建模。
This can enable both long-horizon (e.g., exhaustive exploration with back-tracking) and short-horizon (e.g., navigating around an object) planning.
这可以同时支持长视界(例如,带回溯的彻底探索)和 短视界(例如,围绕一个物体导航)规划。
Concretely, the causal transformer decoder constructs its state belief b t b^t bt using the sequence of state features s = { s j ∣ j = 0 j = t } {\bf s} =\Big\{s^j|_{j=0}^{j=t}\Big\} s={sj∣j=0j=t} within the same trajectories.
具体而言,因果 transformer 解码器使用相同轨迹内的状态特征序列 s = { s j ∣ j = 0 j = t } {\bf s} =\Big\{s^j|_{j=0}^{j=t}\Big\} s={sj∣j=0j=t} 构建其状态 belief b t b^t bt。
Unlike RNN-based causal decoders [90] which, during rollout collection, require only constant time to compute the representation at each timestep, standard implementations of causal transformers require t 2 t^2 t2 time to compute the representation at timestep t t t.
与基于 RNN 的因果解码器[90]不同,在 试运行rollout 收集过程中,在每个时间步只需要恒定的时间来计算表示,而因果 transformers 的标准实现需要 t 2 t^2 t2 时间来计算时间步 t t t 的表示。
This substantial computational cost makes large-scale on-policy RL with causal transformer models slow.
这种巨大的计算成本使得具有因果 transformer 模型的大型 on-policy RL 速度变慢。
To overcome this challenge, we leverage the KV-cache technique [10] to keep past feed-forward results in two cache matrices, one for Keys and one for Values.
为了克服这一挑战,我们利用 KV-cache 技术[10]将过去的前馈结果保存在两个缓存cache 矩阵中,一个用于键Keys,一个用于值Values。
With a KV-cache, our causal transformer decoder only performs feedforward computations with the most current state feature which results in computation time growing only linearly in t t t rather than quadratically.
使用 KV-cache,我们的因果 transformer 解码器仅对最新状态特征执行前馈计算,这导致计算时间 仅 关于 t t t 呈线性增长,而不是二次增长。
While this is still mathematically slower than the constant time required for RNN-based decoders, empirically, we found only a small difference between KV-cache-equipped causal transformers and RNNs in overall training FPS for our setting.
虽然这在数学上仍然比基于 RNN 的解码器所需的恒定时间要慢,但根据经验,我们发现在我们的设置中,配备 KV-cache 的因果 transformers 和 RNNs 在整体训练 FPS 方面只有很小的区别。
Compared to other temporal cache strategies, we found that KV-Cache offers the most significant speed improvements.
与其他时序缓存策略相比,我们发现 KV-Cache 提供了最显著的速度改进。
Please see App. B.3 and Fig. 5 for a discussion of the impact on training speed resulting from different cache strategies.
关于不同缓存策略对训练速度的影响的讨论,请参见 App. B.3 和图 5。
3.2 可扩展的强化学习训练方法
While KV-cache accelerates the causal transformer, this alone is not sufficient to enable efficient and fast RL training.
虽然 KV-cache 加速了因果 transformer,但仅凭这一点还不足以实现高效和快速的强化学习训练。
In this section, we describe the methodology we use to achieve faster training.
在本节中,我们描述了我们用来实现更快训练的方法。
Although each of these individual findings may have been discussed in other works, we emphasize the critical importance of these hyperparameters for efficient training and, consequently, stellar results.
虽然这些单独的发现可能已经在其它研究中讨论过,但我们强调这些超参数对有效训练的至关重要性,从而获得出色的结果。
We parallelize the training process using multi-node training, increasing the number of parallel rollouts by a factor of 4 compared to previous approaches [30, 59, 87] (we use 192 parallel rollouts for Stretch RE-1 agents and 384 for LoCoBot agents).
我们使用多节点训练来并行化训练过程,与之前的方法相比[30,59,87],并行 试运行rollouts 的数量增加了 4 倍(我们对 Stretch RE-1 agents 使用了 192 个并行 rollouts,对 LoCoBot agents 使用了 384 个并行 rollouts )。
We employ the DD-PPO [1] learning algorithm across 4 nodes, utilizing a total of 32 A6000 GPUs and 512 CPU cores.
我们在 4 个节点上使用 DD-PPO[1] 学习算法,总共使用 32 个 A6000 GPUs 和 512 个 CPU 内核。
This scaling accelerates the training speed by approximately 3.4x, a near-linear gain compared to single-node training; we train for ~4.5 days with 4 nodes, while this would have required 15.3 days with a single node.
这种 scaling 将训练速度提高了大约 3.4 倍,与单节点训练相比,这是一个近似线性的增益;我们用 4 个节点训练了大约 4.5 天,而用单个节点则需要 15.3 天。
Our batch size during training, in number of frames, is equal to the number of parallel rollouts ( R R R) multiplied by the length of these rollouts ( T T T) and thus, by increasing R as above, we multiplicatively increase the total batch size.
我们在训练期间的 batch size(以帧数为单位)等于 并行 rollouts 的数量( R R R ) 乘以 这些 rollouts 的长度( T T T),因此,通过如上所述增加 R R R,我们成倍地增加增加 总 batch size。 〔 batch size = 并行 rollouts 的数量 ( R R R ) × \times × rollouts 的长度( T T T)〕
We follow SPOC [6] and use a small constant learning rate of 2 ⋅ 1 0 − 4 2 · 10^{-4} 2⋅10−4 throughout the experiments.
我们遵循 SPOC[6],在整个实验中使用一个很小的恒定学习率 2 ⋅ 1 0 − 4 2·10^{-4} 2⋅10−4。
Instead of annealing the learning rate during training, we instead follow ProcTHOR [11] and increase the batch size by changing the rollout length from T = 32 T=32 T=32, to T = 64 T=64 T=64, and finally to T = 128 T=128 T=128 (resulting in a final batch size of 49,152 frames for LoCoBot agents).
我们没有在训练过程中退火学习率,而是遵循 ProcTHOR[11],通过从 T = 32 T=32 T=32 到 T = 64 T=64 T=64 ,最后到 T = 128 T=128 T=128 来改变 rollout 长度来增加 batch size(最终 LoCoBot 代理的 batch size 为 49,152 帧)。
We make these increases every 10M steps until we reach T = 128 T=128 T=128.
我们每 10M 步增加一次,直到达到 T = 128 T=128 T=128。
3.3 Scaling Environment Interactions
For the experiments on LoCoBot, we use the original ProcTHOR-10k houses for training for a fair comparison to baselines.
对于 LoCoBot 上的实验,我们使用原始的 ProcTHOR-10k 房屋进行训练,以便与基线进行公平的比较。
With the KV-cache technique, our training steps per second is ~2.3k for training PoliFormer, using 384 rollouts on 32 GPUs.
使用 KV-cache 技术,我们训练 PoliFormer 的每秒训练步数约为 2.3k,在 32 个 GPUs 上使用 384 个 rollouts。
For the experiments on Stretch, following [6], we use the ProcTHOR-150k houses with ~40k annotated Objaverse 3D assets.
对于 Stretch 上的实验,遵循 [6],我们使用 ProcTHOR-150k 房屋和 ~40k 注释的 Objaverse 3D assets。
As on-policy RL requires the agent to interact with the environment on-the-fly, we found the continuous physics simulation used by the Stretch RE-1 agent in AI2-THOR to be too slow to efficiently train at scale.
由于 on-policy RL 要求 agent 运行中与环境交互,我们发现 AI2-THOR 中 Stretch RE-1 代理 使用的连续物理模拟器太慢,无法有效地进行大规模训练。
To overcome this, we discretely approximate the agent’s continuous movement via a teleportation-with-collision-checks approach.
为了克服这个问题,我们通过带碰撞检查的传送方法离散地近似代理的连续运动。
In particular, to move the agent, we perform a physics cast using a capsule collider representing the agent along the desired movement direction.
特别地,为了移动代理,我们使用一个胶囊对撞机执行物理投射,代表 代理沿着期望的移动方向。
If the cast does not hit any object (suggesting no potential collisions), we teleport the agent to the target location, otherwise we let AI2-THOR simulate continuous movement as usual.
如果投射没有击中任何物体(表明没有潜在的碰撞),我们将代理传送到目标位置,否则我们让 AI2-THOR 像往常一样模拟连续移动。
For rotations, we first teleport the agent to the target rotation pose.
对于旋转,我们首先传送代理到目标旋转位姿。
If the agent’s capsule collides with any object, we teleport the agent back and let the AI2-THOR simulate the continuous rotation.
如果代理的胶囊与任何物体碰撞,我们将代理传送回来,让 AI2-THOR 模拟连续旋转。
For our tasks, these approximations increase simulation speed by ~40%.
对于我们的任务,这些近似将模拟速度提高了约 40%。
We also found that AI2-THOR scene loading and resetting was a significant bottleneck when using Objaverse assets.
我们还发现 AI2-THOR 场景加载和重置是使用 Objaverse assets 时的一个重要瓶颈。
We streamline AI2-THOR’s Objaverse 3D asset loading pipeline by saving objects in the Msgpack format (natively usable with Unity’s C# backend) as opposed to Python-only Pickle files.
我们简化了 AI2-THOR 的 Objaverse 3D asset 加载管道,通过将物体保存为 Msgpack 格式(可用于 Unity 的 C# 后端),而不是仅使用 Python 的 Pickle 文件。
This change dramatically decreases the loading time of a new scene from ~25s to ~8s.
这一改变极大地减少了新场景的加载时间,从 ~25 秒 到 ~8 秒。
With all these changes, our training steps per second increases from ~550 to ~950 using 192 rollouts on 32 GPUs for training Stretch RE-1 agent, reducing the training time by ~42%.
通过所有这些变化,我们每秒的训练步 从~550 增加到 ~950,在 32 个 GPUs 上使用 192 个 rollouts 来训练 Stretch RE-1 代理,将训练时间减少了 ~42%。
4 结果
↓ 【 本节大纲 】
We now present our experimental results.
现在我们介绍我们的实验结果。
In Sec. 4.1 we demonstrate that scaling RL with PoliFormer produces SoTA results on four simulation benchmarks across two embodiments (LoCoBot and Stretch RE-1).
在 4.1 节中,我们展示了使用 PoliFormer scaling RL 在两个具身实例 (LoCoBot 和 Stretch RE-1)的四个模拟基准上产生 SoTA 结果。
Then, in Sec. 4.2, we show that PoliFormer, despite being trained purely in simulation, transfers very effectively to the real world, outperforming previous work; we again show these results on the above two embodiments.
然后,在第 4.2 节中,我们展示了 PoliFormer,尽管纯粹是在模拟器中训练的,但非常有效地迁移到现实世界,优于之前的研究;我们在上述两个具身实例上再次证实这些结果。
In Sec. 4.3, we provide ablations for various design choices.
Finally, we qualitatively show that PoliFormer-BoxNav can be extended to a variety of downstream applications in a zero-shot manner in Sec. 4.4.
最后,在第 4.4 节中,我们定性地证明了 PoliFormer-BoxNav 可以以 zero-shot 方式扩展到各种下游应用。
Baselines. 基线
For our baselines, we chose a set of prior works in both imitation learning and reinforcement learning.
对于我们的基线,我们选择了一组模仿学习 和 强化学习方面的先前研究。
SPOC [6] is a supervised imitation learning baseline trained on shortest path expert trajectories in AI2THOR.
SPOC[6] 是 AI2THOR 中在最短路径专家轨迹上训练的有监督模仿学习基线。
SPOC* is similar to SPOC, but is trained on more expert trajectories (2.3M vs. 100k).
SPOC* 与 SPOC 类似,但在更专业的轨迹上进行训练(2.3M vs. 100k)。
We build this baseline to verify if SPOC easily scales with more data.
我们构建这个基线是为了验证 SPOC 是否可以轻松地扩展更多的数据。
EmbSigLIP [6] is an RL baseline also used by [6], but trained with comparable GPU hours with SPOC.
EmbSigLIP [6] 也是 [6] 使用 的一个 RL 基线,但与 SPOC 训练的 GPU 小时相当。
The baselines [11, 63, 87] for LoCoBot-embodiment are all trained by RL using the same training steps used by PoliFormer.
LoCoBot-embodiment 的基线[11,63,87]都是由 RL 使用与 PoliFormer 相同的训练步进行训练的。
We have three experiment configurations for our studies, specifying the goal as (a) natural language instruction text, (b) a b-box for the target object, and (c ) b-box & text.
我们的研究有三种实验配置,将目标指定为 (a) 自然语言指令文本,(b) 目标物体的 b-box,以 (c ) b-box & text。
Following [6], b-boxes in simulation are the ground-truth b-boxes, and so such models are not comparable fairly with RGB-only models.
遵循 [6],模拟器中的 b-boxes 是 ground-truth b-boxes,因此这种模型与纯 RGB 模型不具有公平的可比性。
In the real world we replace GT b-boxes with outputs from the open-vocabulary object detector Detic [18], which uses only RGB images as input, and so all comparisons are fair.
在现实世界中,我们用开放词汇物体检测器 Detic[18]的输出来替换 GT b-boxes,它只使用 RGB 图像作为输入,因此所有比较都是公平的。
Implementation Details. 实现细节
For LoCoBot benchmarks, we follow [87] to train our model and baselines on 10k training scenes in ProcTHOR houses for 435M training steps.
对于 LoCoBot 基准测试,我们遵循 [87] 在 ProcTHOR 房屋的 10k 训练场景上训练我们的模型和基线,训练的时间步为 435M。
The evaluation sets consist of 800 tasks in 20 scenes for AI2-iTHOR, 1200 tasks in 5 scenes for ArchitecTHOR, and 1500 tasks in 150 scenes for ProcTHOR-10k.
评估集包括 AI2-iTHOR 的 20 个场景中的 800 个任务,ArchitecTHOR 的 5 个场景中的 1200 个任务,ProcTHOR-10k 的 150 个场景中的 1500 个任务。
For Stretch-RE1, we train our model and baselines on 150k ProcTHOR houses populated with Objaverse assets processed by ObjaTHOR.
对于 Stretch-RE1,我们在 150k 个由 ObjaTHOR 处理的 Objaverse assets 填充的 ProcTHOR 房屋上训练我们的模型和基线。
Then, we evaluate on 200 tasks in 200 scenes as in [6].
然后,我们对 200 个场景中的 200 个任务进行评估,如 [6]。
Training takes 4.5 days on 32 GPUs.
在 32 个 GPUs 上训练需要 4.5 天。
Please see App. B for more details about training, inference, and environment setups.
有关训练、推理和环境设置的更多详细信息,请参阅 App. B。
4.1 PoliFormer 在 4 个基准上实现 SoTA
Table la shows that, on the Chores- S \mathbb S S benchmark, PoliFormer achieves 28.5% absolute gain in success rate over the previous best model.
表 1a 表明在 Chores- S \mathbb S S 基准中,PoliFormer 比之前的最佳模型获得了 28.5% 的绝对成功率增益。
EmbSigLIP baseline results are taken from [6]; we suspect that its poor performance is, in part, due to its training budget being limited to match the training budget of SPOC.
EmbSigLIP 基线结果取自 [6];我们怀疑其表现不佳的部分原因是由于其训练预算被限制以匹配 SPOC 的训练预算。

Table 1: Across four ObjectNav benchmarks, PoliFormer obtains SoTA performance.
表 1:在四个 ObjectNav 基准中,PoliFormer 获得了 SoTA 性能。
(a) Results on the Chores- S \mathbb S S ObjectNav benchmark, which uses the Stretch RE-1 embodiment, PoliFormer dramatically outperforms the previous SoTA, IL-trained SPOC.
在使用 Stretch RE-1 具身实例的 Chores- S \mathbb S S ObjectNav 基准测试中, PoliFormer 的性能显著优于之前的 SoTA, 模仿学习IL 训练的 SPOC。
(b) On three LoCoBot-embodiment test suites, PoliFormer outperforms all prior work (all trained using RL).
在三个 LoCoBot-embodiment 测试套件中,PoliFormer 优于所有先前的研究(全部使用 RL 训练)。
- 脚注 3 We report ProcTHOR results from [87] as these are the most up-to-date for recent AI2-THOR versions.
我们报告 [87] 的 ProcTHOR 结果,因为这些是最新的 AI2-THOR 版本。
PoliFormer works across embodiments.
Table 1b shows that the remarkable performance of PoliFormer is not limited to one embodiment.
表 1b 表明 PoliFormer 的卓越性能并不局限于一个具身实例。
The LoCoBot and Stretch-RE1 robots have different body sizes, action spaces, and camera configurations.
LoCoBot 和 Stretch-RE1 机器人有不同的身体尺寸、动作空间和摄像头配置。
Nevertheless, PoliFormer is able to achieve 8.7%, 10.0%, and 6.9% absolute gain over the best baseline on ProcTHOR-10k (val), ArchitecTHOR, and AI2-iTHOR.
尽管如此,PoliFormer 在 ProcTHOR-10k (val)、ArchitecTHOR 和 AI2-iTHOR 的最佳基线上能够获得 8.7%、10.0% 和 6.9% 的绝对增益。
4.2 PoliFormer 推广到 现实世界
We evaluated PoliFormer on two real-world benchmarks for two different embodiments to show its sim-to-real transfer capabilities.
我们在两个不同具身实例的两个现实世界基准上对 PoliFormer 进行了评估,以展示其 sim-to-real 的迁移能力。
We used the same evaluation set of 15 tasks for LoCoBot (3 different starting poses with 5 different targets), and 18 tasks for Stretch-RE1 (3 different starting poses with 6 different goal specifications), similar to [17] and [6], respectively.
我们对 LoCoBot 使用了相同的 15 个任务的评估集(3 个不同的起始位姿和 5 个不同的目标),对 Stretch-RE1 使用了相同的 18 个任务(3 个不同的起始位姿和 6 个不同的目标规格),分别类似于 [17] 和 [6]。
We do not use any real-world finetuning, and the testing houses were not seen during training.
我们没有使用任何现实世界的微调,并且在训练期间没有看到测试房屋。
In the text-only setting, PoliFormer achieves a remarkable improvement of 33.3% and 13.3% over the baselines for Stretch-RE1 and LoCoBot respectively (Tab. 2b).
在纯文本设置下,PoliFormer 在 Stretch-RE1 和 LoCoBot 的基线上分别取得了 33.3% 和 13.3% 的显著改进(表 2b)。
PoliFormer even outperforms Phone2Proc [17], a baseline that has access to privileged information about the layout of the environment for finetuning.
PoliFormer 甚至优于 Phone2Proc [17], Phone2Proc 是一个基线,可以访问有关环境布局的 privileged 信息以进行调优。

Table 2: We present (a) ablation studies on design choices for scaling up model capacity; and (b) the real-world results, on two different embodiements.
表 2:我们展示了 (a)对增大模型容量设计选择的消融研究;(b)现实世界的结果,在两个不同的具身实例上。
4.3 消融研究
The recipe for building the effective RL navigation model is the end product of several design decisions guided by experimentation, the combination resulting in our SoTA performance.
构建有效的 RL 导航模型的配方是由实验指导的几个设计决策的最终产物,这些设计决策的组合导致了我们的 SoTA 性能。
Table 2a,shows the process of scaling PoliFormer.
表 2a 显示了 scaling PoliFormer 的过程。
Row 1 vs. Row 2: Moving from the CLIP ResNet-50 visual encoder to the ViT-small DINOv2 improves the success rate by an average of 5.2%.
第 1 行与第 2 行:从 CLIP ResNet-50 视觉编码器移动到 ViT-small DINOv2,平均提高了 5.2% 的成功率。
Row 3 vs. Row 5: Using a 3-layer transformer decoder instead of 3-layer GRU increases the performance by 5.5%.
使用 3 层 transformer 解码器 代替 3 层 GRU,性能提高 5.5%。
Row 4 vs. Row 5: Increasing the number of decoder layers from 1 to 3 increases the performance by 4%.
将解码器层的数量从 1 层增加到 3 层,性能将提高 4%。
Row 5 vs. Row 6: Using a larger capacity visual encoder (ViT-b instead of ViT-s), results in a 3.2% gain.
使用容量更大的视觉编码器(ViT-b 而不是 ViT-s)可获得 3.2% 的增益。
In all, these changes result in a 13.6% absolute avg. improvement.
总的来说,这些变化带来了 13.6% 的绝对平均改善。
Has PoliFormer performance saturated? 性能饱和了吗?
Figure 1 (top-left) shows Chores- S \mathbb S S ObjectNav validation success rate as we train PoliFormer for ~700M environment steps.
图 1(左上)显示了我们训练 PoliFormer 约 700M 环境步 时的 Chores- S \mathbb S S ObjectNav 验证成功率。
As that plot shows,PoliFormer’s performance does not appear to have converged, and we expect that performance will continue to improve with more compute.
正如该图所示,PoliFormer 的性能似乎并没有收敛,我们预计随着计算量的增加,性能将继续提高。
This suggests that achieving near-perfect ObjectNav performance may only require further scaling our training approach.
这表明,实现近乎完美的 ObjectNav 性能可能只需要进一步 scaling 我们的训练方法。
4.4 Scaling PoliFormer 到日常任务
By specifying PoliFormer’s goal purely using b-boxes, we produce PoliFormer-BoxNav.
通过纯粹使用 b-boxes 指定 PoliFormer 的目标,我们生成了 PoliFormer - BoxNav。
While PoliFormer-BoxNav lacks the ability to leverage some helpful priors about where objects of certain types should reside (comparing rows 6 & 7 in Table la we see PoliFormer-BoxNav performs slightly worse than a model having both b-box and text goal specifications), this design decision makes PoliFormer-BoxNav a fully general-purpose, promptable, navigation system that can navigate to any goal specifiable using a b-box.
虽然 PoliFormer-BoxNav 缺乏利用一些有用的先验的能力, 这些先验可以确定特定类型的物体应该在哪里(比较表 1a 中的第 6 行和第 7 行,我们看到 PoliFormer-BoxNav 的表现比同时具有 b-box 和文本目标规范的模型略差),但这种设计决策使 PoliFormer-BoxNav 成为一个完全通用的、可提示的导航系统,可以导航到使用 b-box 指定的任何目标。
Figure 3 shows four qualitative examples where, by using an open-vocabulary object detector (Detic [18]) and a VLM (GPT-4o [91]), PoliFormer-BoxNav is able to, zero-shot, navigate to (1) a book with a particular title, (2) a given room type, (3) multiple objects sequentially, and (4) a toy car as the car is driven around an office building.
图 3 显示了四个定性示例,其中,通过使用开放词汇的物体检测器(Detic[18])和 VLM (GPT-4o [91]), PoliFormer-BoxNav 能够 zero-shot 导航到(1)具有特定标题的书,(2)给定房间类型,(3)顺序多个物体,以及(4)玩具汽车,该汽车在办公大楼周围行驶
Simply by specifying goals as b-boxes and leveraging off-the-shelf systems, we obtain complex navigation behaviors that would otherwise need to be trained for individually: a painful process requiring new reward functions or data collection.
通过简单地将目标指定为 b-boxes 并利用现成的系统,我们获得了复杂的导航行为,否则需要单独训练:这是一个需要新的奖励函数或数据收集的痛苦过程。
Finally, we encourage readers to visit our website to view more qualitative results presented in video format.
最后,我们鼓励读者访问我们的网站,观看更多以视频形式呈现的定性结果。

Figure 3: We use PoliFormer-BoxNav zero-shot to find a book with a particular title, navigate to a kitchen, navigate to multiple objects sequentially, and follow a toy car around an office building.
图 3:我们使用 PoliFormer-BoxNav zero-shot 来查找具有特定标题的书,导航到厨房,依次导航到多个物体,并在办公楼周围跟随玩具车。
5 讨论 (局限性 和 结论)
Limitations:
Training RL agents for long-horizon tasks with a large search space requires extensive compute and demands careful reward shaping.
训练具有大搜索空间的长视界任务的强化学习代理需要大量的计算和仔细的奖励设计。
While we believe PoliFormer is capable of scaling to other tasks, it requires crafting new reward models for novel tasks such as manipulation.
虽然我们相信 PoliFormer 能够扩展到其他任务,但它需要为操作等新任务制定新的奖励模型。
More discussion on limitations in App. E.
更多讨论 在 App. E 中的局限性。
Conclusion:
In this paper we provide a recipe for scaling RL for long-horizon navigation tasks.
在本文中,我们提供了一种 scaling RL 用于长视界导航任务的方法。
Our model, PoliFormer, achieves SoTA results on four simulation benchmarks and two real-world benchmarks across two different embodiments.
我们的模型 PoliFormer 在两个不同具身实例 的四个模拟基准和两个现实世界基准上实现了 SoTA 结果。
We also show that PoliFormer has remarkable potential for use in downstream everyday tasks.
我们还证实 PoliFormer 在下游日常任务中具有显著的潜力。
参考文献
附录
Appendices for PoliFormer: Scaling On-Policy RL with Transformers Results in Masterful Navigators
These appendices contain additional information about our:
- Zero-shot real-world applications (App. A),
zero-shot 现实世界的应用- Training procedure (App. B),
训练流程- Environment, benchmarks, and quantitative real-world experiments (App. C),
环境、基准和定量的真实世界实验- Simulation evaluations (App. D), and
模拟评估- Limitations (App. E).
局限性
Please find our project website (see the poliformer.allen.ai) that contains
- Six real-world qualitative videos where PoliFormer performs the everyday tasks Section 4.4 (recall also Figure 3), and
6 个真实世界的定性视频,其中 PoliFormer 执行 4.4 节的日常任务( 图 3)- Four qualitative videos in simulation showing our PoliFormer’s behavior in the four benchmark environments (CHORES, ProcTHOR, AI2-iTHOR, and ArchitecTHOR).
模拟器中的 4 个定性视频显示了我们的 PoliFormer 在四个基准环境(CHORES、ProcTHOR、AI2-iTHOR 和 ArchitecTHOR)中的行为。
A 使用 Open-Vocab Object Detector 和 VLM Zero-shot 到 现实世界下游应用 的细节
By specifying PoliFormer’s goal purely using b-boxes, we produce PoliFormer-BoxNav.
通过纯粹使用 b-boxes 指定 PoliFormer 的目标,我们生成了 PoliFormer- BoxNav。
PoliFormer-BoxNav is extremely effective at exploring its environment and, once it observes a bounding box, takes a direct and efficient path towards it.
PoliFormer-BoxNav 在探索环境方面非常有效,一旦它观察到一个边界框,就会采取直接而有效的路径。
We now describe how we utilize this behavior to apply PoliFormer-BoxNav zero-shot to a variety of downstream applications by leveraging an open vocabulary object detector (Detic [18]) and a VLM (GPT-4o [91]).
现在,我们描述如何利用这种行为,通过利用开放词汇物体检测器 (Detic[18])和 VLM (GPT-4o[91]),将 PoliFormer-BoxNav zero-shot 应用于各种下游应用。
Open Vocabulary ObjectNav.
Open Vocabulary ObjectNav.
To perform open vocabulary object navigation (i.e., where one must navigate to any given object type), we simply prompt the Detic object detector with the novel object type, for example, Bicycle.
要执行开放词汇表物体导航(即,必须导航到任何给定的物体类型),我们只需用新的物体类型提示 Detic 物体检测器,例如,Bicycle。
As PoliFormer-BoxNav relies on the b-box as its goal specification, it finds a bicycle in the scene smoothly.
由于 PoliFormer-BoxNav依赖于 b-box 作为其目标规范,因此它可以顺利地在场景中找到自行车。
Multi-target ObjectNav.
Multi-target ObjectNav.
To enable multi-target object goal navigation, we make a few simple modifications to the inputs and output of the Detic detector.
为了实现 multi-target object goal navigation,我们对 Detic 检测器的输入和输出进行了一些简单的修改。
On the input side, we query with multiple prompts simultaneously (one for each object type); for instance, HousePlant, Toilet, and Sofa, as shown in Fig. 3 (bottom-left).
在输入端,我们同时使用多个 prompt 进行查询(每种 object 类型一个);例如,HousePlant, Toilet, and Sofa,如图 3(左下)所示。
We then, on the output side, only return the b-box with the highest confidence score.
然后,在输出端,我们只返回具有最高置信度得分的 b-box。
Since the returned b-box also contains the predicted object type, we know what the target object the agent finds is when issuing a Done action.
由于返回的 b-box 还包含预测的 object 类型,因此我们知道代理在发出 Done 动作时找到的 target object 是什么。
Therefore, we remove the found target from the list of target types, and reset the PoliFormer’s KV-cache.
因此,我们从 target 类型列表中删除找到的 target,并重置 PoliFormer 的 KV-cache。
If the agent issues a Done action without a detected b-box, we terminate the episode and consider it a failure.
如果代理发出 Done 动作而没有检测到 b-box,我们将终止该回合并将其视为失败。
As a result, the agent is required to find all the targets from the list of target types to succeed in an episode.
因此,代理需要从 target 类型列表中找到所有 targets 才能成功完成一个回合。

Human Following.
Human Following.
We change the Detic prompt to Person.
我们将 Detic prompt 改为 Person。
Once a b-box is detected, PoliFormer drives the agent to approach it.
Our experiment participant continues to walk away, so the agent keeps approaching them to minimize the distance.
一旦检测到 b-box,PoliFormer 就会驱动代理靠近它。
我们的实验参与者继续走开,因此代理不断接近他们以最小化距离。
Object Tracking.
Object Tracking. In this example, we control a remote control car that moves in the environment, and prompt the agent to find the car.
在这个例子中,我们控制一辆在环境中移动的遥控车,并 prompt agent 找到这辆车。
Similar to Human Following, we change the prompt to Toy Truck in this example.
与 Human Following 类似,在本例中我们将 prompt 更改为 Toy Truck。
As a result, the agent keeps trying to move closer to the detected b-box of the RC car, while avoiding collisions with objects in the dynamic scene.
因此,agent 不断尝试向 RC 车检测到的 b-box 靠近,同时避免与动态场景中的物体发生碰撞。
室内导航Room Navigation.
Room Navigation. In this example, shown in Fig. 3 (middle-left), we provide no detections to the agent.
在这个例子中,如图 3(中左)所示,我们没有向代理提供任何检测。
As the agent sees no detections, it continuously explores the scene.
当 agent 没有发现任何检测时,它会不断探索这个场景。
As the agent explores, we query GPT-4o every 5 timesteps with the promptAm I in a Kitchen? Please return Yes or No. with the most recent visual observation.
随着 agent 的探索,我们每隔 5 个时间步查询 GPT-4o,prompt “我在厨房吗?”请根据最近的视觉观察返回 Yes 或 No 。
Once GPT-4o returns Yes, the agent issues a Done action to end the episode.
一旦 GPT-4o 返回 Yes,代理发出 Done 动作来结束回合。

实例描述导航Instance Description Navigation.
Instance Description Navigation.
In this example, shown in Fig. 3 (upper-left), the agent is prompted to find a specific book titled “Humans”.
在这个例子中,如图 3(左上)所示,agent 被提示查找一本名为 “Humans” 的特定书籍。
Detic can generate open-vocabulary bounding boxes using instance-level descriptions but we found that doing this alone leads to high false-positive rates.
Detic 可以使用实例级描述 生成 开放词汇边界框,但我们发现单独这样做会导致高误报率。
To reduce these errors, we use GPT4-o to filter positive detections from Detic.
为了减少这些误差,我们使用 GPT4-o 来过滤来自 Detic 的阳性检测。
In particular, a sample filtering prompt is"Is there a book titled "Humans" in this image? Please return Yes or No.".
特别地,一个示例过滤 prompt 是 “这张图片中是否有一本名为“人类”的书?”请返回 Yes 或 No。”
We find this combination works well in practice.
我们发现这种组合在实践中效果很好。
The agent, not GPT-4o, remains responsible for deciding when it has successfully completed its task, and in the Fig. 3 example sees many books in its search but perseveres and eventually finds the correct one.
agent,而不是 GPT-4o,仍然负责决定何时成功完成任务,在图 3 的例子中,它在搜索中看到许多书,但坚持不懈,最终找到了正确的那一本。

B 额外的训练细节
B.1 Reward Shaping
For reward shaping, we follow EmbCodebook [87] and ProcTHOR [11] and use the implementation in AllenAct [92]: R penalty + R success + R distance {\cal R}_\text{penalty} +{\cal R}_\text{success} +{\cal R}_\text{distance} Rpenalty+Rsuccess+Rdistance , where R penalty = − 0.01 {\cal R}_\text{penalty} = -0.01 Rpenalty=−0.01 encourages an efficient navigation, R success = 10 {\cal R}_\text{success}= 10 Rsuccess=10 when the agent successfully completes the task (= 0 otherwise), and R distance {\cal R}_\text{distance} Rdistance is the change of L2 distances from target between two consecutive steps.
对于 reward shaping,我们遵循 EmbCodebook[87] 和 ProcTHOR[11],并使用 AllenAct[92] 中的实现: R penalty + R success + R distance {\cal R}_\text{penalty} +{\cal R}_\text{success} +{\cal R}_\text{distance} Rpenalty+Rsuccess+Rdistance,
- 其中 R penalty = − 0.01 {\cal R}_\text{penalty} = -0.01 Rpenalty=−0.01鼓励高效导航,
- 当智能体成功完成任务时 R success = 10 {\cal R}_\text{success}= 10 Rsuccess=10 (否则 = 0),
- R distance {\cal R}_\text{distance} Rdistance 是两个连续步骤之间到 target 的 L2 距离的变化。
Note that we only provide a nonzero R distance {\cal R}_\text{distance} Rdistance if the new distance is less than previously seen in the episode.
注意,如果新的距离小于之前在回合中看到的距离,我们只提供一个非零的 R distance {\cal R}_\text{distance} Rdistance。 〔 直接用更小的值替换? 〕
We do not enforce a negative reward for increasing distance.
我们不会因为增加距离而强制执行负奖励。
This formulation encourages exploration.
这种形式鼓励探索。
B.2 回合式 注意 mask
During training, to ensure that the causal transformer decoder cannot access observations or states across different episodes, we construct the episodic attention mask to only allow the past experiences within the same episode to be attended.
在训练过程中,为了确保因果 transformer 解码器不能访问不同回合的观察或状态,我们构建了 回合式注意 mask,只允许待注意的同一回合中的过去经验。
In Fig. 4, we show a couple of possible rollouts collected during training.
在图 4 中,我们展示了在训练期间收集的几个可能的试运行rollouts。
With the episodic attention mask, observations and states in an episode can only attend to previous ones within the same episode, in contrast with a naive causal mask where they could also potentially attend to observations and states in previous episodes.
有了 episodic attention mask,一个回合中的观察和状态只能关注同一回合中之前的观察和状态,与简单因果 mask 相反,他们也可能关注之前回合中的观察和状态。
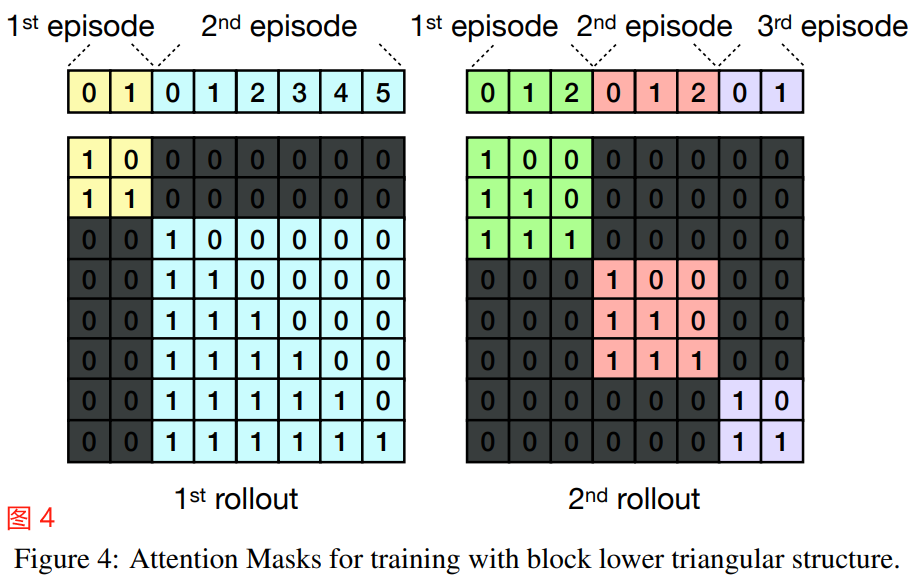
Figure 4: Attention Masks for training with block lower triangular structure.
图 4:块状下三角形结构训练 Attention Masks。
B.3 不同的时序 cache 策略
Besides the KV-Cache, in this subsection, we ablate four different temporal cache strategies (shown in Fig. 5 top):
除了 KV-Cache 之外,在本小节中,我们将介绍四种不同的时序缓存策略(如图 5 所示):
(i) No-Cache, we cache the raw frames (visual observation i t i^t it) to provide past experiences for the causal transformer decoder.
No-Cache,我们缓存原始帧(视觉观察 i t i^t it),为因果 transformer 解码器提供过去的经验。
Therefore, PoliFormer has to rerun the feedforward across all modules with the cached frames and the latest visual observation at each timestep.
因此,PoliFormer 必须在每个时间步用缓存的帧和最新的视觉观察在所有模块上重新运行前馈。
(ii) Feature-Cache, we cache the features, including visual representation v t v^t vt and goal embedding g t g^t gt (as well as g b t g_b^t gbt).
Feature-Cache,我们缓存特征,包括视觉表示 v t v^t vt 和 goal embedding g t g^t gt(以及 g b t g_b^t gbt)。
In this case, PoliFormer needs to recompute the transformer state encoder and causal transformer decoder with the cached features and the latest feature at each timestep.
在这种情况下,PoliFormer 需要在每个时间步用缓存的特征和最新的特征重新计算 transformer 状态编码器和因果 transformer 解码器。
(iii) State-Cache, we cache the state feature vector s t s^t st.
State-Cache,我们缓存状态特征向量 s t s^t st。
Since it is right before the causal transformer decoder, PoliFormer only requires to pass the cache state features and the latest state feature vector to the decoder, without recomputing the visual transformer model, goal encoder, and transformer state encoder.
由于它正好在因果 transformer 解码器之前,因此 PoliFormer 只需要将缓存状态特征和最新状态特征向量传递给解码器,而无需重新计算视觉 transformer 模型、目标编码器和 transformer 状态编码器。
(iv) KV-Cache, as described in Sec. 3.1, we cache the Keys and Values inside the causal transformer decoder, further reducing the required computation time for the transformer decoder from t 2 t^2 t2 to t t t theoretically.
KV-Cache,如 3.1 节所述,我们将 Keys 和 Values 缓存在因果 transformer 解码器中,进一步减少 transformer 解码器所需的计算时间,从理论上讲,从 t 2 t^2 t2 到 t t t。
In addition, since this strategy operates at very end, all the recomputations required by modules preceding causal transformer decoder can be saved.
此外,由于该策略在最后运行,因此可以节省因果 transformer 解码器之前模块所需的所有重新计算。
The speed profile results are shown in Fig. 5 bottom.
速度概况结果如图 5 底部所示。
It clearly shows that placing the cache closer to the causal transformer decoder improves the training efficiency significantly.
它清楚地表明,将缓存放置在离因果 transformer 解码器更近的地方可以显著提高训练效率。
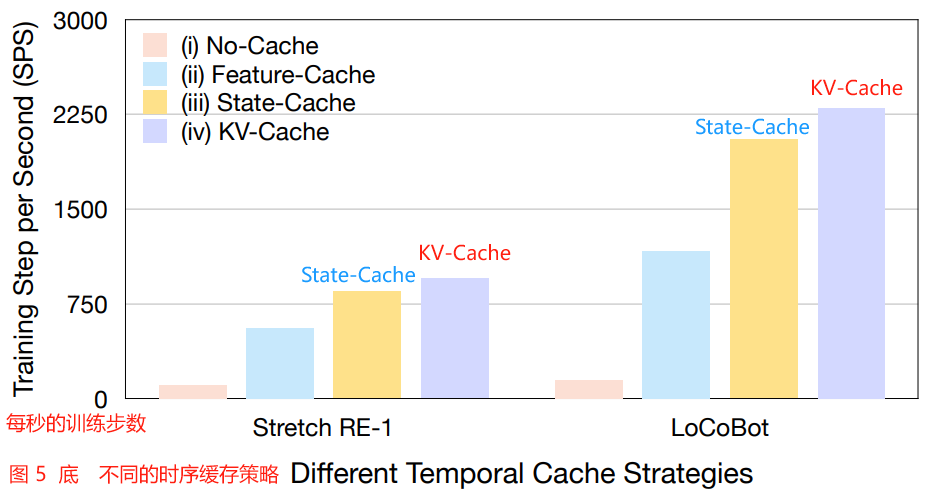
Figure 5: Different temporal cache strategies and their impact on the training speed. We ablate four different cache strategies, including (i) No-Cache, (ii) Feature-Cache, (iii) State-Cache, and (iv) KV-Cache, shown at top.
图 5:不同的时序缓存策略及其对训练速度的影响。
我们列出了四种不同的缓存策略,包括 (i) No-Cache, (ii) Feature-Cache, (iii) State-Cache 和(iv) KV-Cache,如图所示。
The bottom chart shows the training Step per Second (SPS) achieved by different strategies, on both LoCoBot and Stretch RE-1 agents.
下图显示了不同策略在 LoCoBot 和 Stretch RE-1 代理上实现的每秒训练步数。
B.4 用于训练的超参数
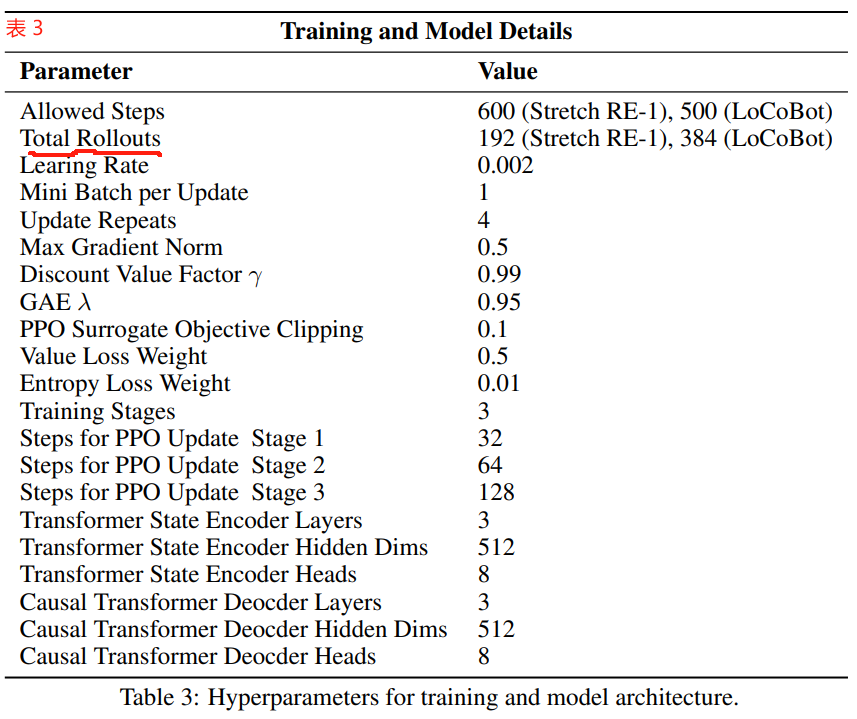
Tab. 3 lists the hyperparameters used in our training and model architecture design.
表 3 列出了我们在训练和模型架构设计中使用的超参数。
Please find more details such as scene texture randomization, visual observation augmentations, and goal specification randomization when using text instruction in our codebase.
在我们的代码库中使用文本指令时,请查找更多细节,如场景纹理随机化,视觉观察增强 和 goal specification 随机化。
C 关于环境、基准 和 现实世界实验的 额外细节
动作空间
Action Space.
Following prior work using AI2-THOR, we discretize the action space for both LoCoBot and Stretch RE-1.
遵循之前使用 AI2-THOR 的工作,我们离散了 LoCoBot 和 Stretch RE-1 的动作空间。
For LoCoBot, we discretize the action space into 6 actions, including {MoveAhead, RotateRight, RotateLeft, LookUp, LookDown, Done}, where MoveAhead moves the agent forward by 0.2 meters, RotateRight rotates the agent clockwise by 30° around the yawaxis, RotateLeft rotates the agent counter-clockwise by 30° around the yaw-axis, LookUp rotates agent’s camera clockwise by 30° around the roll-axis, LookDown rotates agent’s camera counterclockwise by 30° around the roll-axis, and Done indicates that the agent found the target and ends an episode.
对于 LoCoBot,我们将动作空间离散为 6 个动作,包括 {MoveAhead, RotateRight, RotateLeft, LookUp, LookDown, Done},
- 其中 MoveAhead 将 agent 向前移动 0.2 米,
- RotateRight 将 agent 沿 yaw 轴顺时针旋转 30°,
- RotateLeft 将 agent 沿 yaw 轴逆时针旋转 30°,
- LookUp 将 agent 的摄像头沿 roll 轴顺时针旋转 30°,
- LookDown 将 agent 的摄像头沿 roll 轴逆时针旋转 30°,
- Done 表示 agent 找到 target 并结束一个回合。
We follow previous works [11, 17, 87] to use the same action space for LoCoBot for a fair comparison.
我们遵循之前的工作 [11,17,87],为 LoCoBot 使用相同的动作空间进行公平的比较。
For Stretch RE-1, we remove the LookUp and LookDown camera actions, and add MoveBack, RotateRightSmall, and RotateLeftSmall to the action space, where MoveBack moves the agent backward by 0.2 meters, RotateRightSmall rotates the agent clockwise by 6° around the yaw-axis, and RotateLeftSmall rotates the agent counter-clockwise by 6° around the yaw-axis.
对于 Stretch RE-1,我们移除 LookUp 和 LookDown 相机动作,并在动作空间中添加 MoveBack、RotateRightSmall 和 RotateLeftSmall,
- 其中 MoveBack 将 agent 向后移动 0.2 米,
- RotateRightSmall 将 agent 沿 yaw 轴顺时针旋转 6°,
- RotateLeftSmall 将 agent 沿 yaw 轴逆时针旋转 6°。
Again, this action space is identical to the one used in prior work [6] for fair comparison.
同样,为了公平比较,这个动作空间与之前工作[6]中使用的动作空间相同。
成功的标准
Success Criteria.
We follow the definition ofObject Goal Navigationdefined in [3], where an agent must explore its environment to locate and navigate to an object of interest within an allowed number of steps n n n.
我们遵循 [3] 中定义的 Object Goal Navigation 的定义,其中 agent 必须探索其环境,以在允许的步数 n n n 内定位和导航到感兴趣的 object。
The agent has to issue the Done action to indicate it found the target.
agent 必须发出 Done 动作来指示它找到了 target。
The environment will then judge if the agent is within a distance d from the target and if the target can be seen in the agent’s view.
然后,环境将判断 agent 是否在 target 的一定距离内,以及 target 是否在 agent 的视野内。
An episode is also classified as failed if the agent runs more than n n n steps without issuing any Done action.
如果代理运行超过 n n n 步而没有发出任何 Done 动作,则该回合也被归类为失败。
Across different benchmarks, n n n and d d d vary depending on the scenes size and complexity and agent’s capabilities.
在不同的基准测试中, n n n 和 d d d 取决于场景的大小、复杂性和 agent 的能力。
We follow ProcTHOR [11] to use n = 500 n = 500 n=500 and d = 1 d = 1 d=1 meter for LoCoBot, and follow Chores- S \mathbb S S [6] to use n = 600 n = 600 n=600 and d = 2 d = 2 d=2 meters for Stretch RE-1.
我们遵循 ProcTHOR[11] 为 LoCoBot 使用 n = 500 n = 500 n=500 和 d = 1 d = 1 d=1 米,并遵循 Chores- S \mathbb S S [6] 为 Stretch RE-1 使用 n = 600 n = 600 n=600 和 d = 2 d = 2 d=2 米。
两个指标:路径长度加权的成功 (SPL) 和 回合长度加权的成功 (SEL)
SPL and SEL.
Success Weighted by Path Length (SPL)andSuccess Weighted by Episode Length (SEL)are two popular evaluation metrics to evaluate how efficient an agent is to find the target.
路径长度加权的成功 (SPL) 和 回合长度加权的成功 (SEL) 是两种常用的评估指标,用于评估 agent 找到 target 的效率。
SPL 定义为 1 N ∑ i = 1 N S i l i max ( l i , p i ) \frac{1}{N}\sum\limits_{i=1}^N S_i\frac{l_i}{\max(l_i,p_i)} N1i=1∑NSimax(li,pi)li,
- 其中 N N N 为总回合数, S i S_i Si 为回合 i i i 的二进制数成功指示
- l i l_i li 是到 target 的最短行程距离,
- p i p_i pi 是实际行程距离。
SEL 的定义类似: 1 N ∑ i = 1 N S i w i max ( w i , e i ) \frac{1}{N}\sum\limits_{i=1}^N S_i\frac{w_i}{\max(w_i,e_i)} N1i=1∑NSimax(wi,ei)wi,
- 其中 w i w_i wi 是找到 target 的最短步数,
- e i e_i ei 是 agent 使用的实际步数。
By definition, SPL focuses on how far the agent has traveled, while SEL focuses on how many steps the agent has used (which also penalizes excessive in-place rotation).
根据定义,SPL 关注代理移动了多远,而 SEL 关注代理使用了多少步(这也会惩罚过多的原地旋转)。
SPL can be derived by computing the geodesic distance between the agent’s starting location and the target’s location, while SEL needs a planner with privileged environment information to calculate the number of steps of expert trajectories.
SPL 可以通过计算 agent 起始位置和 target 位置之间的测地线距离来推导,SEL 需要一个具有特权环境信息的规划器来计算专家轨迹的步数。
Therefore, we follow ProcTHOR [11] to report SPL to evaluate the LoCoBot agent, since those benchmarks do not provide planner, while we follow Chores- S \mathbb S S [6] to report SEL, since expert trajectories are available.
因此,我们遵循 ProcTHOR[11] 报告 SPL 来评估 LoCoBot 代理,因为这些基准测试不提供规划器,而我们遵循 Chores- S \mathbb S S [6] 报告 SEL,因为专家轨迹是可用的。
现实世界实验设置
Real-world Experiment Setup.
For the experiments using LoCoBot, we follow Phone2Proc [17] to use the same five target object categories, including Apple, Bed, Sofa, Television, and Vase, and the three starting poses, shown in Fig. 6 (a).
对于使用 LoCoBot 的实验,我们遵循 Phone2Proc[17],使用相同的五个 target object 类别,包括苹果,床,沙发,电视和花瓶,以及三种启动位姿,如图 6 (a) 所示。
Among those target categories, Apple can be found in the Living room and Kitchen, Bed can only be found in the Bedroom, Sofa and Television can only be found in the Living room, and Vase can be found in the Livingroom, Corridor, Office, and Kitchen.
在这些 target 类别中,苹果可以在客厅和厨房找到,床只能在卧室找到,沙发和电视只能在客厅找到,花瓶可以在客厅,走廊,办公室和厨房找到。
For the experiments using Stretch RE-1, we follow SPOC [6] to use the same six target object categories, including Apple, Bed, Chair, HousePlant, Sofa, and Vase, and the three starting poses, shown in Fig. 6 (b).
对于使用 Stretch RE-1 的实验,我们遵循 SPOC[6],使用相同的六个 target object 类别,包括苹果、床、椅子、室内植物、沙发和花瓶,以及如图 6 (b) 所示的三种起始位姿。
Among the categories not mentioned above, Chair can be found in the Living room, Office, and Kitchen, and HousePlant can be found in the Living room, Office, Bathroom, and Kitchen.
在上面没有提到的类别中,椅子可以在客厅、办公室和厨房找到,而室内植物可以在客厅、办公室、浴室和厨房找到。
Note that we use the hardware design intorduced in SPOC [6] for Stretch RE-1.
请注意,我们为 Stretch RE-1 使用 SPOC[6] 中介绍的硬件设计。
Instead of using the off-the-shelf camera equipped on the Stretch RE-1 (due to its narrow field of view), we use an Intel RealSense 455 fixed camera, which has a vertical field of view of 59° and a resolution of 1280 x 720.
而不是使用配备在 Stretch RE-1 上的现成相机(由于其狭窄的视野),我们使用 Intel RealSense 455 固定相机,其垂直视野为 59°,分辨率为 1280 x 720。
The camera is mounted facing forward but pointing downward, with the horizon at a nominal angle of 30°. 〔 nominal angle: 一个理论上的角度值,用于描述物体之间的相对位置或方向,但实际上可能存在一定的误差。 〕
相机安装面朝前方,但指向下方,与地平线在一个标称角度为 30°。
Please find more details in App. C.1. in SPOC [6].
详情请参阅 SPOC[6] 中的 App. C.1。
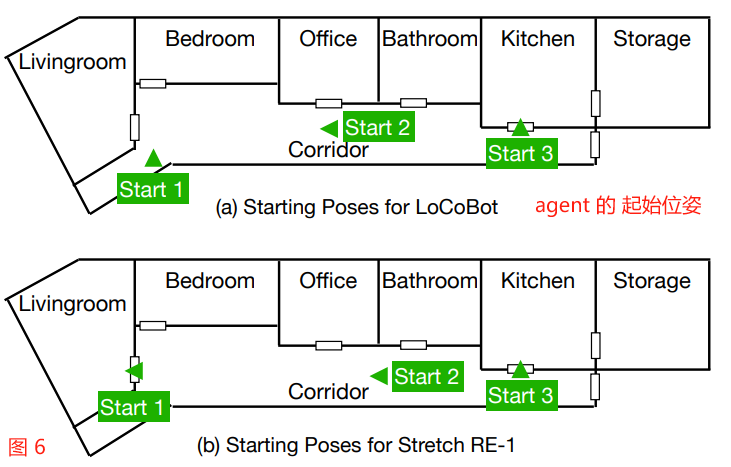
Figure 6: Starting Poses of (a) LoCoBot and (b) Stretch RE-1 used in the real world experiments.
图 6: (a) LoCoBot 和 (b) Stretch RE-1 在真实世界实验中的起始位姿。
The arrow direction indicates where the agent faces with.
箭头方向表示 agent 面对的位置。
关于不同基准的细节
First, during the training and testing stages, the possible target object types the agent is tasked with searching for include AlarmClock, Apple, BasketBall, Bed, Bowl, Chair, GarbageCan, HousePlant, Laptop, Mug, Sofa, SprayBottle, Television, Toilet, and Vase.
We then outline the differences between the environments.
首先,在训练和测试阶段,agent 被要求搜索的可能 target object 类型包括闹钟、苹果、篮球、床、碗、椅子、垃圾桶、室内植物、笔记本电脑、马克杯、沙发、喷雾瓶、电视、厕所和花瓶。
然后,我们概述了环境之间的差异。
————————————
(i) AI2-iTHOR: This environment consists of 60 training scenes, 20 validation scenes, and 20 test scenes, and our training and evaluation never touch the training scenes.
这个环境由 60 个训练场景、20 个验证场景和 20 个测试场景组成,我们的训练和评估从不触及测试场景。
All the scenes are created by human designers, including the structure, layout, and object placements, producing 750 episodes for validation and 800 episodes for testing.
所有场景都是由人类设计师创建的,包括结构、布局和 object 放置,制作 750 个回合用于验证,800 个回合用于测试。
Moreover, iTHOR has 4 different styles of scenes, including LivingRoom, Kitchen, Bathroom, and Bedroom, where each style contains the objects which are semantically associated with it.
此外,iTHOR 有 4 种不同风格的场景,包括客厅、厨房、浴室和卧室,每种风格都包含与之语义相关的 objects。
Since each iTHOR scene only contains a single room, it doesn’t require much exploration but rather focuses on recognition capability.
由于每个 iTHOR 场景只包含一个房间,所以它不需要太多的探索,而是专注于识别能力。
————————————
(ii) ArchitecTHOR: This environment consists of 10 high-quality large interactive houses designed by human designers, including 5 for validation and 5 for testing.
该环境由 10 个由人类设计师设计的高质量大型互动房屋组成,其中 5 个用于验证,5 个用于测试。
Both validation and testing scenes have 1, 200 episodes each.
验证和测试场景各有 1200 个回合。
It includes multiple rooms, larger navigable spaces, and more objects to explore.
它包括多个房间,更大的可导航空间,以及更多的探索 objects。
Since they are much larger than iTHOR scenes, they serve as a better benchmark to test the agent’s exploration ability.
由于它们比 iTHOR 场景大得多,因此它们可以作为测试 agent 探索能力的更好基准。
Since ArchitecTHOR is designed by human designers, it also conforms to human priors on room layout and object placement.
由于 ArchitecTHOR 是由人类设计师设计的,所以它也符合人类在房间布局和 object 放置方面的先验。
————————————
(iii) ProcTHOR-val: This environment contains 1, 550 episodes across 150 procedurally generated houses.
这个环境包含 1550 个回合,横跨 150 个程序生成的房子。
The way these houses are generated follows the same pipeline used in ProcTHOR.
这些房屋的生成方式与 ProcTHOR 中使用的管道相同。
Therefore, the distribution of layout styles, number of rooms, and object placements respects the ProcTHOR-10k training houses’ distribution, where our LoCoBot agent is trained.
因此,布局风格、房间数量和 object 放置的分布遵循 ProcTHOR-10k 训练屋的分布,我们的 LoCoBot 代理就是在那里训练的。
————————————
(iv) Chores- S \mathbb S S: This environment contains 200 episodes across 200 procedurally generated houses, using the same approach as ProcTHOR.
这个环境包含 200 个回合,横跨 200 个程序生成的房子,使用与 ProcTHOR 相同的方法。
However, it includes the Objaverse 3D assets, presented by SPOC, which introduced 41, 133 assets into the ProcTHOR-150k houses, creating a more diverse scene distribution.
然而,它包括由 SPOC 提出的 Objaverse 3D assets,它将 41,133 个 assets 引入 ProcTHOR-150k 房屋,创造了更多样化的场景分布。
Our Stretch Agent is trained on 80, 000 houses out of the ProcTHOR-150k training houses; the 200 Chores- S \mathbb S S test houses and episodes are not seen during training.
我们的 Stretch Agent 在 ProcTHOR-150k 训练房屋中的 8 万所房屋中进行了训练;200 个 Chores- S \mathbb S S 测试房屋和回合在训练期间看不到。
D 更多模拟器评估
性能方差
Performance Variance.
On Chores- S \mathbb S S, since we follow SPOC [6] to apply test-time data augmentation and non-deterministic action sampling, we found that performance varies even using the same checkpoint, especially given that we are only evaluating on 200 episodes.
在 Chores- S \mathbb S S 上,由于我们遵循 SPOC[6] 应用测试时间数据增强和非确定性动作抽样,我们发现即使使用相同的 checkpoint,性能也会有所不同,特别是考虑到我们只评估 200 个回合。
As a result, we re-evaluate our PoliFormer and SPOC*4 16 times and report mean success rate (mSR) and standard deviation (std).
因此我们重新评估 PoliFormer 和 SPOC ∗ \text{SPOC}^* SPOC∗ 4 16 次,并报告平均成功率(mSR)和 标准偏差(std)。
- 脚注 4 SPOC* is similar to SPOC but is trained on more expert trajectories (2.3M vs. 100k).
SPOC* 与 SPOC 类似,但在更专业的轨迹上进行训练(2.3M vs. 100k)。PoliFormer achieves 82.5% mSR with 1.897 std, while SPOC* achieves 56.7% mSR with 2.697 std.
PoliFormer 达到 82.5% 的mSR, std 为1.897,而 SPOC* 达到 56.7% 的 mSR, std 为 2.697。
This result indicates that PoliFormer not only achieves a higher mSR than SPOC*, but also exhibits more reliably consistent behavior, i.e. a lower std, when run on the same episodes multiple times.
这一结果表明,PoliFormer 不仅比 SPOC* 获得了更高的 mSR,而且在多次运行同一回合时,表现出更可靠的一致性行为,即更低的 std。
使用 Stretch RE-1 的更大规模的模拟器基准
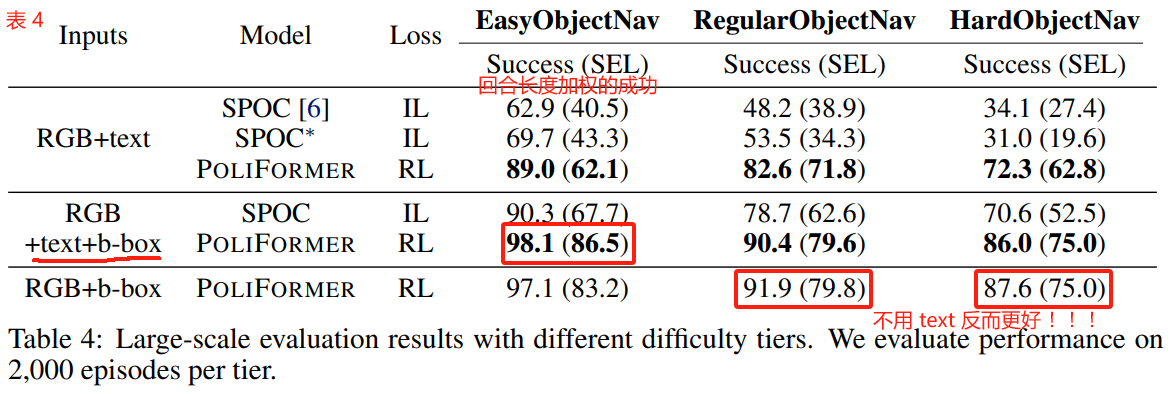
Larger Scale Simulation Benchmark using Stretch RE-1.
To further analyze PoliFormer’s performance through different difficulty settings, we construct 3 different levels of Object Goal Navigation benchmarks, EasyObjectNav, RegularObjectNav, and HardObjectNav, where each level contains 2k episodes, using Stretch RE-1.
为了进一步分析 PoliFormer 在不同难度设置下的表现,我们使用 Stretch RE-1 构建了 3 个不同级别的 Object Goal Navigation 基准,EasyObjectNav, RegularObjectNav 和 HardObjectNav,其中每个级别包含 2k 个回合。
We construct these differentiated tasks by ensuring the oracle expert path length between the agent and target is 1 to 3 meters long for EasyObjectNav, greater than 3 meters for RegularObjectNav, and larger than 10 meters for HardObjectNav.
我们通过确保 EasyObjectNav 中 代理和 target 之间的 oracle 专家路径长度为 1 到 3 米,RegularObjectNav 的长度大于 3 米,HardObjectNav 的长度大于 10 米来构建这些差异化任务。
The results are shown in Tab. 4.
结果如表 4 所示。
We observe that every model performs better as the agent is closer to the target at the episode start.
我们观察到,当 agent 在回合开始时离 target 更近时,每个模型的表现都更好。
In addition, on EasyObjectNav the agent barely needs explorationto find the target.
此外,在 EasyObjectNav 上,代理几乎不需要探索就能找到目标。
Thereby, we find that PoliFormer lagging behind PoliFormer-BoxNav by~9% could result from a Recognition Issue.
Moreover, the gap on HardObjectNav is widened to~13.7%, and it could result from an additional Exploration Issue.
因此,我们发现 PoliFormer 落后于 PoliFormer-BoxNav 约 9% 可能是由于识别问题。
此外,HardObjectNav 上的差距扩大到 ~13.7%,这可能是由于额外的探索问题。
The performance gap between HardObjectNav and EasyObjectNav could also support that an Exploration Issue exists, but not just the Recognition Issue.
HardObjectNav 和 EasyObjectNav 之间的性能差距也可能支持探索问题的存在,但不仅仅是识别问题。
平均碰撞率
Average Collision Rate.
As shown in Tab. 5. We measure the average collision rate achieved by PoliFormer using the LoCoBot agent in ProcTHOR-val, ArchitecTHOR, and AI2-iTHOR.
如图 5 所示。我们使用 ProcTHOR-val、ArchitecTHOR 和 AI2-iTHOR 中的 LoCoBot 代理来测量 PoliFormer 实现的平均碰撞率。
We compute the collision rate by # c o l l i s i o n # s t e p s \frac{\# ~ collision}{\#~steps } # steps# collision within an episode and we average the rate across all evaluation episodes to obtain an average collision rate.
我们在一个回合内通过 # c o l l i s i o n # s t e p s \frac{\# ~ collision}{\#~steps} # steps# collision 计算碰撞率,并对所有评估回合的碰撞率进行平均,以获得平均碰撞率。

PoliFormer 的 Robustness
Robustness of PoliFormer.
To evaluate the robustness of PoliFormer, we inject the gaussian noise into the action only at the evaluation stage.
为了评估 PoliFormer 的稳健性,我们只在评估阶段将高斯噪声注入动作中。
The results using LoCoBot across ProcTHOR-val, ArchitecTHOR, and AI2-iTHOR are shown in Tab. 6.
表 6 显示了在 ProcTHOR-val、ArchitecTHOR 和 AI2-iTHOR 之间使用 LoCoBot 的结果。
PoliFormer is robust to action noise even when experiencing substantial perturbations (3 × σ \sigma σ is a very large and unrealistic amount of noise).
PoliFormer 对动作噪声具有稳健性,即使在经历大量扰动时(3 × σ \sigma σ 是一个非常大且不切实际的噪声量)。
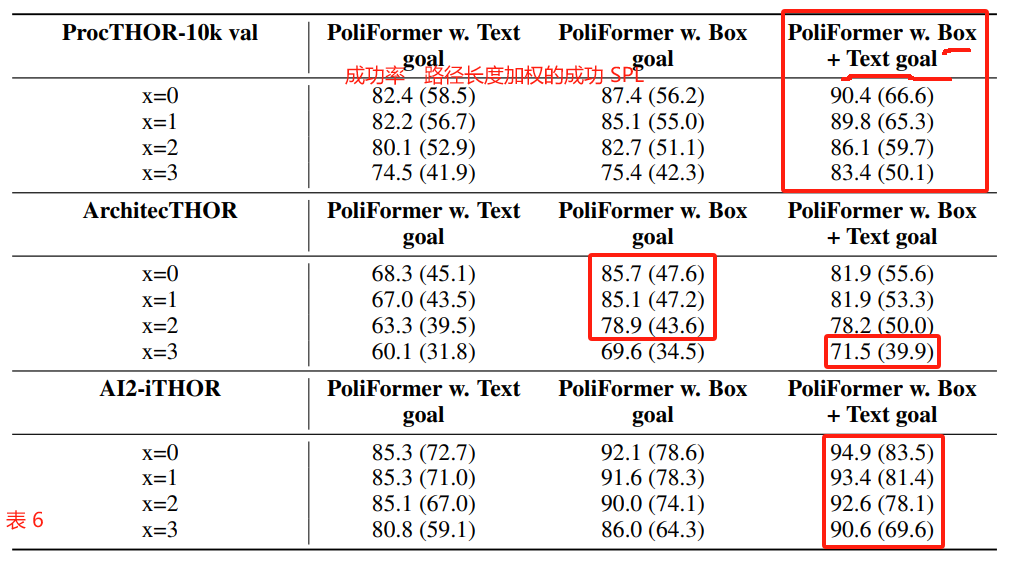
- 由表 6,PoliFormer 在基准 ArchitecTHOR 中的表现与其他基准中的不一致。
表 6:在不同基准中,PoliFormer 在不同噪声水平下的成功率和 SPL 〔 路径长度加权的成功 〕。
我们在动作中注入高斯噪声 G ( 0 , x ∗ σ ) G(0, x* \sigma) G(0,x∗σ),其中 x x x 是控制噪声 scale 的变量,移动的 σ = step size 3 \sigma=\frac{\text{step size}}{3} σ=3step size,旋转的 σ = rotation degree 3 \sigma=\frac{\text{rotation degree}}{3} σ=3rotation degree。
默认情况下,LoCoBot 代理的步长为 0.25 m,旋转角度为 30 度。
E 关于 局限性 的额外讨论
深度传感器
Depth Sensor. It is important to note that PoliFormer is not equipped with a depth sensor (which has been proven to be effective for manipulation).
值得注意的是,PoliFormer 没有配备深度传感器(这已被证明是有效的操作)。
While the lack of the depth sensor does not affect our agent’s performance on navigation, we acknowledge that integrating the depth sensor into our visual representation is an interesting direction for future work, especially when considering mobile-manipulation extensions.
虽然缺乏深度传感器不会影响我们的 agent 在导航上的性能,但我们承认,将深度传感器集成到我们的视觉表示中是未来工作的一个有趣方向,特别是在考虑 mobile-manipulation 扩展时。
离散的动作空间
Discretized Action Space.
To have a fair comparison with baselines, we use the same discretized action space in this work (see App. C).
为了与基线进行公平的比较,我们在这项工作中使用了相同的离散动作空间(见 App. C)。
The discretized action space might not be efficient and realistic in many real-world scenarios where the agent must act in a timely manner.
离散化的动作空间在许多真实世界的场景中可能不是有效的和逼真的,在这些场景中 agent 必须及时行动。
跨具身实例
Cross-embodiment. In this paper, we demonstrate that we can train PoliFormer using LoCoBot and Stretch RE-1.
在本文中,我们证明了我们可以使用 LoCoBot 和 Stretch RE-1 来训练 PoliFormer。
However, we have not yet explored training a single PoliFormer for both embodiments.
然而,我们还没有探索为两个具身实例训练单个 PoliFormer。
We leave this interesting research direction as future work.
我们把这个有趣的研究方向留给未来的工作。
进一步 Scaling
Further Scaling.
Our training and validation curves strongly suggest that even further scaling of model parameters and training time may lead to even more masterful models than those we have trained in this work.
我们的训练和验证曲线强烈地表明,即使进一步 scaling 模型参数和训练时间,也可能导致比我们在这项工作中训练的模型更精通的模型。
This perspective is exciting and we hope to enable further scaling with more computation resources and better visual foundation models in the near future.
这一前景令人兴奋,我们希望在不久的将来能够通过更多的计算资源和更好的视觉基础模型来实现进一步的扩展。
失败分析
Failure Analysis.
The main mode of failure for PoliFormer is the agent’s limited memory.
PoliFormer 的主要失败模式是 agent 有限的内存。
PoliFormer clearly demonstrates memorization capabilities and is able to perform long-horizon tasks by exploring large indoor scenes without access to explicit mapping.
PoliFormer 清楚地展示了记忆能力,并且能够通过探索大型室内场景来执行长期任务,而无需访问显式映射。
However, as the trajectories get longer (specifically after visiting more than 4 rooms in an environment), the agent’s recollection of the rooms it has explored deteriorates and the robot might re-visit rooms that it has explored previously.
然而,随着轨迹变长(特别是在一个环境中访问超过 4 个房间后),agent 对其探索过的房间的回忆会变差,机器人可能会重新访问之前探索过的房间。
GPUs 的广泛使用和大量的训练时间
Extensive Use of GPUs and Significant Training Time. We acknowledge that PoliFormer requires a large number of GPUs to train efficiently.
我们承认 PoliFormer 需要大量的 GPUs 来进行有效的训练。
Our main focus in this work is on pushing the performance of navigation agents to its limit without constraints on computing resources.
我们在这项工作中的主要重点是在不受计算资源限制的情况下将导航代理的性能推向极限。
Given the trend of GPU improvements over the last 10 years, we believe that the resources used in this work will become relatively commonplace in the near future.
考虑到过去 10 年 GPU 的改进趋势,我们相信在不久的将来,这项工作中使用的资源将变得相对普遍。
Empirically, we found that training with a smaller number of GPUs (e.g., 8 A6000 in a single host) could yield similar final performance, with the downside of slower training speed (~ 3.5x longer to train compared to 32 A6000 in four nodes).
根据经验,我们发现使用较少数量的 GPUs(例如,单个主机上的 8 个 A6000)进行训练可以产生类似的最终性能,缺点是训练速度较慢(与四个节点上的 32 个 A6000 相比,训练时间长 3.5 倍)。
Moreover, there are many interesting research directions in improving training speed/efficiency; for example, since our submission, we have found that removing the average pooling from PoliFormer’s visual encoder can increase convergence speed by up to 2x. E.g., for the LoCoBot agent, we keep the number of tokens (e.g., 256 tokens) from DINOv2, instead of spatially average pooling them to 7 × 7 (resulting in 49 tokens).
此外,在提高训练速度/效率方面有许多有趣的研究方向;例如,自从我们提交以来,我们发现从 PoliFormer 的视觉编码器中删除平均池化可以将收敛速度提高 2 倍。
例如,对于 LoCoBot 代理,我们保留来自 DINOv2 的 tokens 数量(例如,256 个 tokens),而不是将它们在空间上平均池化为 7 × 7(导致 49 个 tokens)。
This implies that a better visual encoder with a larger receptive view over the visual observation could even further speed up training.
这意味着一个更好的视觉编码器,在视觉观察上具有更大的接受视野,甚至可以进一步加快训练速度。
Furthermore, we believe that incorporating more advanced techniques such as mixed precision training, flash attention, and advanced GPUs optimized for transformer models could reduce the training resource requirements.
此外,我们认为,结合更先进的技术,如混合精度训练,flash attention,和先进的 GPUs 优化 transformer 模型可以减少训练资源的需求。
样本效率
Sample Efficiency. We hypothesize that an “IL pretraining +RL finetuning” paradigm could further improve sample efficiency.
我们假设 “IL 〔 模仿学习 〕预训练 + RL 〔 强化学习 〕微调”范式可以进一步提高样本效率。
Early in on-policy RL training, policies trained from scratch are effectively random and thus produce a vast amount of marginally useful experiences.
在 on-policy RL 训练的早期,从零开始训练的策略实际上是随机的,因此产生了大量无用的经验。
Pretraining with IL may improve sample efficiency by providing helpful priors on navigation and thus produce meaningful RL gradients faster.
使用 IL 进行预训练可以通过提供有用的导航先验来提高样本效率,从而更快地产生有意义的 RL 梯度。
While it is nontrivial to implement this two-stage pipeline, we hypothesize that training PoliFormer using IL on expert data (e.g., the shortest path trajectories from SPOC) first and finetuning using on-policy RL could be an option to improve the sample efficiency.
虽然实现这个两阶段的管道很重要,但我们假设首先使用 IL 〔 模仿学习 〕在专家数据(例如,来自 SPOC 的最短路径轨迹)上训练 PoliFormer,然后使用 on-policy RL 进行微调可能是提高样本效率的一种选择。
Since we focus on obtaining SoTA performance in this work, we believe that improving sample efficiency, by an IL+RL pipeline or with new RL algorithms such as SAPG [93], is an exciting research direction for future work.
由于我们在这项工作中专注于获得 SoTA 性能,我们认为通过 IL+ RL 管道或新的 RL 算法(如 SAPG[93])来提高样本效率是未来工作的一个令人兴奋的研究方向。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









